Multimodality has led the pack in machine learning in 2021. Neural networks are wolfing down images, text, speech and music all at the same time. OpenAI is, as usual, top dog, but as if in defiance of their name, they are in no hurry to share their models openly. At the beginning of the year, the company presented the DALL-E neural network, which generates 256x256 pixel images in answer to a written request. Descriptions of it can be found as articles on arXiv and examples on their blog.
As soon as DALL-E flushed out of the bushes, Chinese researchers got on its tail. Their open-source CogView neural network does the same trick of generating images from text. But what about here in Russia? One might say that “investigate, master, and train” is our engineering motto. Well, we caught the scent, and today we can say that we created from scratch a complete pipeline for generating images from descriptive textual input written in Russian.
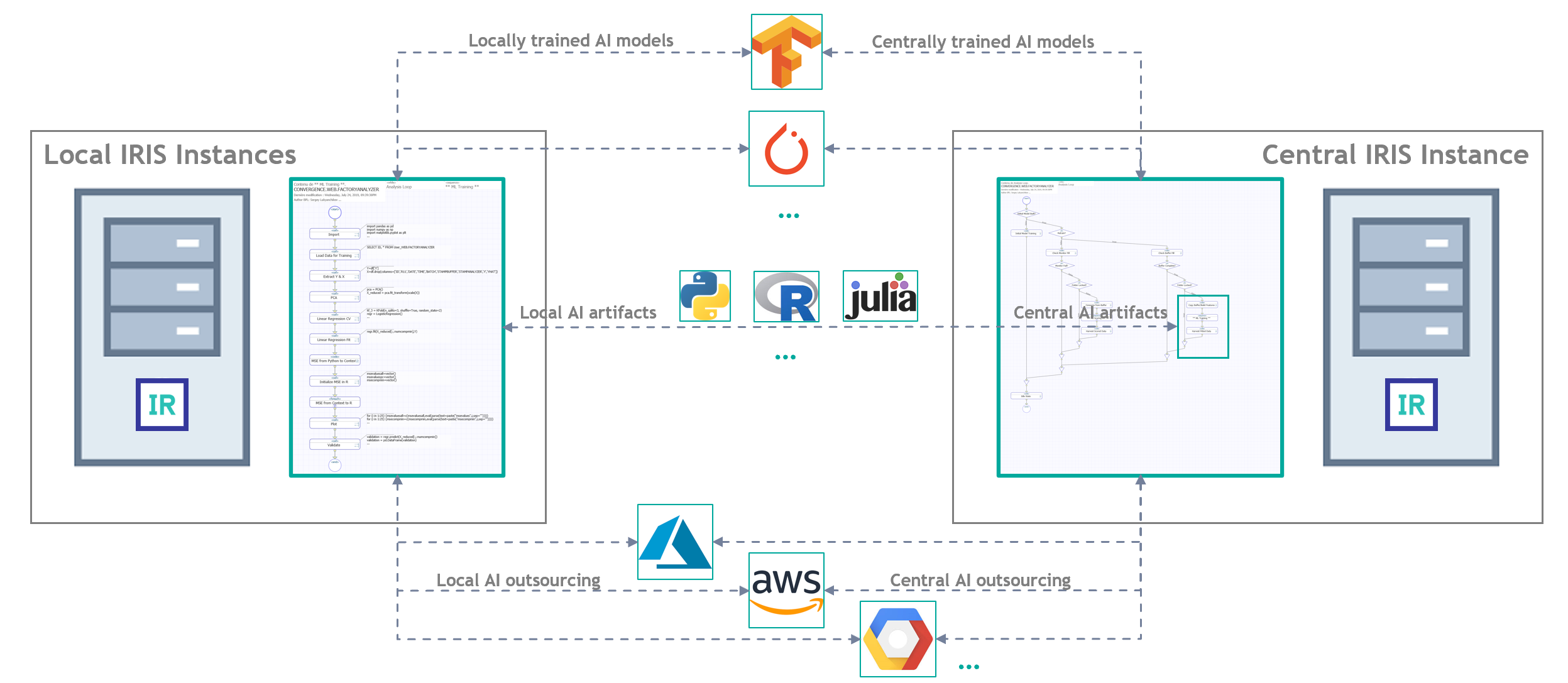
In this article we present the ruDALL-E XL model, an open-source text-to-image transformer with 1.3 billion parameters as well as ruDALL-E XXL model, an text-to-image transformer with 12.0 billion parameters which is available in DataHub SberCloud, and several other satellite models.