Premier Developer Consultant Randy Patterson discusses the benefits of using the new Worker Service project template introduced in .NET Core 3.
.NET Core 3 introduced a new project template called Worker Service. This template is designed to give you a starting point for cross-platform services. As an alternate use case, it sets up a very nice environment for general console applications that is perfect for containers and microservices.
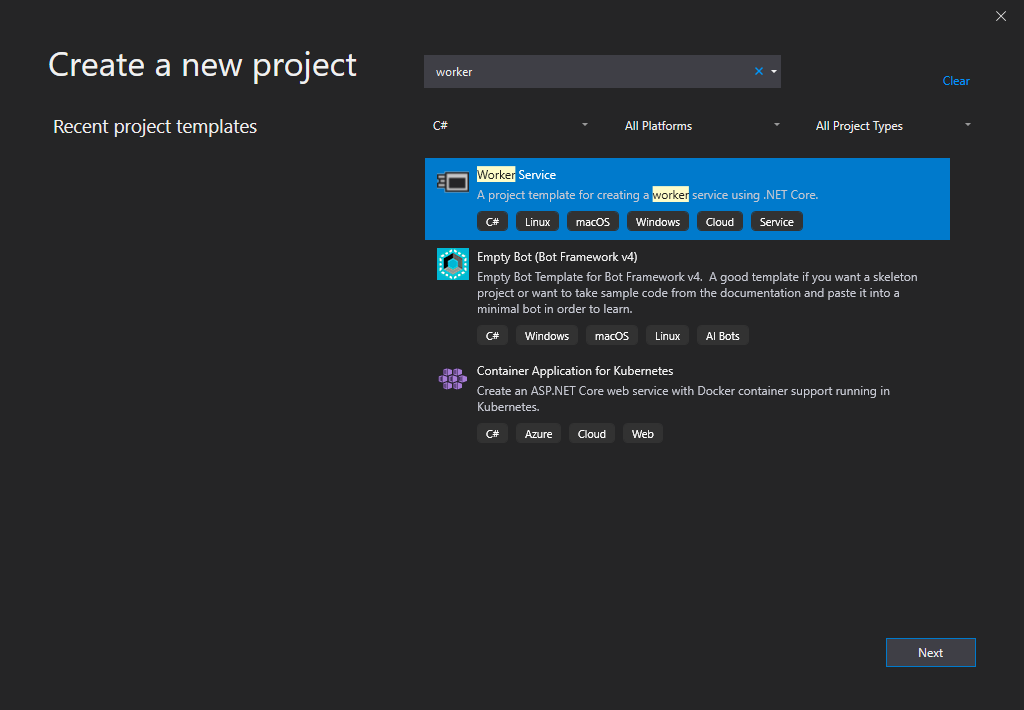
Some of the benefits of using this template include the following areas.

.NET Core 3 introduced a new project template called Worker Service. This template is designed to give you a starting point for cross-platform services. As an alternate use case, it sets up a very nice environment for general console applications that is perfect for containers and microservices.

Some of the benefits of using this template include the following areas.