Давно хотел рассказать про MapReduce, а то как ни взгляшешь на подобное — такая заумь, что просто ужас берет, а на самом деле очень простой и полезный подход для многих целей. И реализовать самому — не так уж и сложно.
Сразу скажу — топик — для тех, кто не разобрался что такое MapReduce. Для тех, кто разобрался — полезного тут ничего не будет.
Начнем с того как собственно родилась лично у меня идея MapReduce (хотя я и не знал, что он так называется, и, разумеется, пришла она мне куда позже чем Гугловсцам).
Сначала опишу как она рождалась (подход был неправильный), а потом как надо правильно делать.
А родилась она, как и, наверное, везде — для подсчета частоты слов, когда обычной памяти не хватает (подсчет частоты всех слов в Википедии). Вместо слова «частота» тут скорее должно быть «количество вхождений», но для простоты оставлю «частота».
В самом простом случае мы можем завести хеш (dict, map, hash, ассоциативный массив, array() в PHP) и считать в нем слова.
Но что делать когда память под хеш кончится, а мы посчитали только одну сотую всех слов?
Я решил эту проблему тем, что считал часть слов, пока не кончится память, делал сохранение хеша на диск. То есть прямо построчно в файл:
Возникла проблема — а как объединять-то эти файлы? Ведь каждый из них занимает всю оперативку.
Сначала была идея брать только самые популярные 1 000 000 слов из каждого файла и объединить их — это влезет в оперативку и посчитает хотя бы верхнюю часть списка (самые популярные слова). Это, конечно, сработало, но получилось что миллионы нижних слов терялись, а их было куда больше.
Пришла идея сортировать файлы.
Берем потом 20 сортированных файлов, читаем из каждого них первые 1000 строк, они будут примерно про одни и те же слова (отсортированные же файлы). Суммируем и формируем новый хеш, в нем будут только слова, начинающиеся на «aaa...» и подобные, сохраняем в новые файлы. Читаем следующие 1000 строк, все то же. Там примерно во всех файлах будут слова «aab...»
Таким образом формируется новый файл уже куда меньшего размера. Однако в нем все равно будут повторяться слова. Опять сортируем его, читаем его по 1000 строк, суммируем. Получится почти правильный файл (некоторые слова все же могут находится за гранью 1000 строк), еще пару раз повторяем… в конце концов получаем файл, в котором очень мало ошибок (но они есть).
Муторно, долго, но лучше варианта в голову не пришло.
В этом подходе было одно слабое место — а именно — объединение первоначальных 20 файлов. Как его сделать лучше?
Проблема возникает из того, что некоторых слов не будет в каких-то файлах или они будут в разных блоках по 1000 строк. То есть если бы я мог из всех 20 файлов брать не первые 1000 строк, а только по одной строке, но с одним и тем же словом — я бы смог все 20 файлов объединять за один проход.
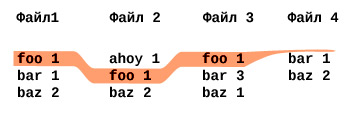
Как это сделать? Вообще это ↑ последний шаг алгоритма MergeSort — объединение сортированных списков. Если знаете — пропускайте.
Берем по первой строке из всех 20 файлов, ищем минимальный первый элемент (слово) — он будет самый минимальный вообще во всем, поскольку у нас файлы отсортированы. Допустим это будет слово «aardvark» Берем из всех 20 строк, что мы прочитали только те, которые относятся к этому слову «aardvark». А оттуда, откуда мы его изымаем — только в тех файлах читаем вторую строку. Опять ищем минимальную среди этих 20. По аналогии — дальше, пока конца всех файлов не достигнем.
Собственно, вот я почти и изобрел для себя то, что Google изобрело до меня десятилетие назад и назвало MapReduce.
Изобретение велосипедов продолжается и по сей день.
Итак есть строка:
Надо получить на выходе:
Шаг первый, берем строку, разбиваем на слова и выдаем вот такие массивы (ну или вернее: «tuples» — «кортежи»):
(Дальше буду скобочки и кавычки опускать там, где и так будет понятно)
Берем их, сортируем:
Замечаем, что bar идет два раза подряд, так что объединяем в такой вид:
Дальше просто складываем вторые элементы массивов. Получаем:
Именно то, что и хотели.
Главный вопрос — нафига козе баян… или что мы тут вообще делали и зачем?
Если представить что у нас компьютер в который влезает только 2 строки и он может выполнять только одну операцию со строкой в минуту. (Отставить хихикать! После того как хотя бы раз посчитаете все слова в Википедии — будете иметь право смеяться над поставленными ограничениями памяти, все равно не влезет, хоть у Вас сколько гигов будет, а если влезет — считайте во всем Интернете :) ).
Мы можем (из
У нас в памяти по две строки — все в порядке, уложились в ограничения по памяти.
Теперь используя шаг из MergeSort, мы можем объединять построчно эти файлы:
При этом в памяти каждый раз у нас только две строки хранятся из 2 файлов — больше и не надо.
Собственно, то, что мы сделали — это уже MapReduce.
Тот шаг, который из слов выдает массивы с единичками (
Тот шаг, который суммирует
Остальные шаги сделает сам алгоритм (сортировку и объединение через MergeSort).
Сами эти шаги не обязательно заключаются в том, чтобы выдавать единички в случае «Map» или складывать в случае «Reduce». Это просто функции, которые могут что-то принять и что-то выдать. В зависимости от цели.
В данном случае «Map» — это написанная Вами функция, которая берет отдельное слово и выдает
А «Reduce» — это написанная Вами функция, которая берет массив
Проще говоря в Python:
или PHP:
Итак, мы обошли ограничение по памяти, но как обойти ограничение по скорости?
Представим что у нас два таких компьютера. Каждому из них мы даем исходную строку и говорим первому (точнее MapReduce говорит): считай только слова на нечетных местах, а второму — считай слова только на четных местах.
Первый выдает:
Второй выдает:
Мы (точнее MapReduce) забираем результаты у обоих, сортируем, потом прогоняем через MergeSort, как и выше:
Ровно тот же результат, как и когда считал один компьютер!
Теперь это мы (MapReduce) раздаем опять двум компьютерам: первому даем только нечетные строки, второму — четные и просим каждый компьютер делать шаг Reduce (сложить вторые цифры).
Собственно, понятно, что эти строки друг от друга не зависят, так что результат будет опять же тем, что нужно.
Главное в том, что два компьютера работали в параллель и следовательно — в два раза быстрее, чем один из них (если не считать потери времени на передачу данных от одного к другому).
Фуф! Итак MapReduce — он нужен для того, чтобы считать что-то, что либо нужно делать быстрее, либо на что не хватает памяти (либо и то, и то).
Допустим мы хотим посчитать количество слов в Википедии и одновременно построить список в обратном порядке их популярности — от самых популярных, к самым непопулярным.
Ясно, что все слова википедии не влезут в память, да и для обратной сортировки потом этот массив гигантский не влезет в память. Нам понадобится каскад MapReduce'ов — результат работы первого MapReduce будет поступать на вход второго MapReduce.
Если честно — я не знаю является ли слово «каскад» правильным, применимо именно к MapReduce. Это слово я использую для себя, потому что оно как никакое другое объясняет что надо сделать (результат одного водопада слов падает в MapReduce и каскадом перетекает сразу же во второй MapReduce).
Ладно, как посчитать слова — мы уже знаем:
«foo bar baz foo»
Написанный нами шаг Map выдает:
Дальше MapReduce объединяет (сам, не Вы, как программист) их в:
А написанный нами шаг Reduce выдает:
Теперь представим, что считали мы всю Википедию и этот массив содержит миллиарды и миллиарды слов. Отсортировать его в памяти не получится. Возмем еще один MapReduce, в этот раз Map будет делать такой фокус:
Для чего это надо?
MapReduce, перед тем как пойдет в Ваш Reduce, — отсортирует все эти массивы по первому элементу массива (который равен отрицательному числу). MapReduce сможет отсортировать даже если весь объем данных не влезет в память все — в этом и прелесть. Для всех слов Wikipedia Вы просто не сможете сделать
Почему минус перед цифрами?
Потому что MapReduce отсортирует всегда по возрастанию, а нам надо по убыванию. Как же используя сортировку только по возрастанию отсортировать числа в порядке уменьшения? Умножить на минус один перед сортировкой и опять на минус один после.
По возрастанию положительные числа:
По возрастанию отрицательные числа:
На вход Reduce придет такая штука:
Прелесть, но у нас два слова имели «частоту» 15 и их сгруппировал MergeSort. Будем исправлять.
Теперь нам в нашем Reduce остается только умножить первое число на -1, а затем выдать для первой строки один массив, а для второй — два массива, для третьей — опять один.
На самом деле, в зависимости от того какое воплощение MapReduce будете использовать — Вам может и не удастся в шаге Reduce выдать два массива, потому что будет требоваться только один массив на выходе — тогда просто после шага Reduce это делайте уже в своей программе.
Получаем:
Красота! То, что было надо.
Опять же помните, что главное что мы тут обходили — это то, что пример-то из четырех строк, а в Википедии миллиарды слов, которые в память не влезают.
На PHP: простейший пример.
На Python простейший пример (см. ниже про Python версию).
В коде я указал что и где должно быть, чтобы сделать более-менее полноценный MapReduce с блекдж… в смысле с файлами и MergeSort'ом. Однако это так сказать эталонная реализация, который позволит поигаться и понять как MapReduce работает. Это все еще MapReduce, просто конкретно эта реализация с точки зрения памяти ничем не выгоднее обычного хеша.
Я выбрал PHP, хотя он не самый разумный для этих целей, потому что прочитать PHP может почти любой программист, а перевести на нужный язык — это уже проще будет.
Да, в файлы я рекомендую сохранять построчно JSON представление массивов (json_encode) — меньше будет проблем с пробелами в словах, с юникодом, числами и типами данных, то есть так:
Подсказка — в Python последний шаг MergeSort уже реализован — это
То есть чтобы соединить 10 файлов с JSON представлениями достаточно:
В PHP с реализацией MergeSort, подозреваю надо возиться в полсотни строк. Если конечно в комментах никто лучше варианта не подскажет.
В Python
Осторожно — такой метод не совсем классический для MapReduce и его трудно будет распараллеливать на много машин (однако довольно тривиально в этом методе сделать работу с объемами данных больше чем доступно памяти). Метод
Воплощение MapReduce на Hadoop — самое популярное решение. (Я его не пробовал, просто знаю что самое популярное).
Так что вот, надеюсь мой рассказ о «MapReduce без зауми» придется полезным.
MapReduce — очень полезная штука для всяких больших масштабов расчетов. Практически любой SQL запрос, даже на несколько таблиц — не очень сложно раскладывается на MapReduce + join_iterator (об этом в другой раз).
Если будут силы — в следующем топике опишу как с помощью MapReduce считать более интересные задачки, чем банальные слова — как, например, считать ссылки в интернете, частоту слов в контексте других слов, людей в городах, товары по прайсам сотен фирм и т.п.
Да, всем ахтунг сюда! MapReduce запатентован Google, но скорее в защитных целях — тому же Hadoop они официально разрешили использовать этот метод. Так что — handle with care.
Часть вторая: более продвинутые примеры.
Йои Хаджи,
Вид, как всегда, с Хабра,
2010
(когда-нибудь я научусь объяснять кратко....)
Сразу скажу — топик — для тех, кто не разобрался что такое MapReduce. Для тех, кто разобрался — полезного тут ничего не будет.
Начнем с того как собственно родилась лично у меня идея MapReduce (хотя я и не знал, что он так называется, и, разумеется, пришла она мне куда позже чем Гугловсцам).
Сначала опишу как она рождалась (подход был неправильный), а потом как надо правильно делать.
Как посчитать все слова в Википедии (неправильный подход)
А родилась она, как и, наверное, везде — для подсчета частоты слов, когда обычной памяти не хватает (подсчет частоты всех слов в Википедии). Вместо слова «частота» тут скорее должно быть «количество вхождений», но для простоты оставлю «частота».
В самом простом случае мы можем завести хеш (dict, map, hash, ассоциативный массив, array() в PHP) и считать в нем слова.
$dict['word1'] += 1Но что делать когда память под хеш кончится, а мы посчитали только одну сотую всех слов?
Я решил эту проблему тем, что считал часть слов, пока не кончится память, делал сохранение хеша на диск. То есть прямо построчно в файл:
aardvark | 5
aachen | 2Возникла проблема — а как объединять-то эти файлы? Ведь каждый из них занимает всю оперативку.
Сначала была идея брать только самые популярные 1 000 000 слов из каждого файла и объединить их — это влезет в оперативку и посчитает хотя бы верхнюю часть списка (самые популярные слова). Это, конечно, сработало, но получилось что миллионы нижних слов терялись, а их было куда больше.
Пришла идея сортировать файлы.
Берем потом 20 сортированных файлов, читаем из каждого них первые 1000 строк, они будут примерно про одни и те же слова (отсортированные же файлы). Суммируем и формируем новый хеш, в нем будут только слова, начинающиеся на «aaa...» и подобные, сохраняем в новые файлы. Читаем следующие 1000 строк, все то же. Там примерно во всех файлах будут слова «aab...»
Таким образом формируется новый файл уже куда меньшего размера. Однако в нем все равно будут повторяться слова. Опять сортируем его, читаем его по 1000 строк, суммируем. Получится почти правильный файл (некоторые слова все же могут находится за гранью 1000 строк), еще пару раз повторяем… в конце концов получаем файл, в котором очень мало ошибок (но они есть).
Муторно, долго, но лучше варианта в голову не пришло.
Слабое место неправильного подхода
В этом подходе было одно слабое место — а именно — объединение первоначальных 20 файлов. Как его сделать лучше?
Проблема возникает из того, что некоторых слов не будет в каких-то файлах или они будут в разных блоках по 1000 строк. То есть если бы я мог из всех 20 файлов брать не первые 1000 строк, а только по одной строке, но с одним и тем же словом — я бы смог все 20 файлов объединять за один проход.

Как это сделать? Вообще это ↑ последний шаг алгоритма MergeSort — объединение сортированных списков. Если знаете — пропускайте.
Берем по первой строке из всех 20 файлов, ищем минимальный первый элемент (слово) — он будет самый минимальный вообще во всем, поскольку у нас файлы отсортированы. Допустим это будет слово «aardvark» Берем из всех 20 строк, что мы прочитали только те, которые относятся к этому слову «aardvark». А оттуда, откуда мы его изымаем — только в тех файлах читаем вторую строку. Опять ищем минимальную среди этих 20. По аналогии — дальше, пока конца всех файлов не достигнем.
MapReduce в простейшем виде
Собственно, вот я почти и изобрел для себя то, что Google изобрело до меня десятилетие назад и назвало MapReduce.
Изобретение велосипедов продолжается и по сей день.
Итак есть строка:
"foo bar baz bar". Надо получить на выходе:
{ foo: 1, bar: 2, baz: 1 }. Шаг первый, берем строку, разбиваем на слова и выдаем вот такие массивы (ну или вернее: «tuples» — «кортежи»):
[ 'foo', 1 ]
[ 'bar', 1 ]
[ 'baz', 1 ]
[ 'bar', 1 ](Дальше буду скобочки и кавычки опускать там, где и так будет понятно)
Берем их, сортируем:
bar, 1
bar, 1
baz, 1
foo, 1Замечаем, что bar идет два раза подряд, так что объединяем в такой вид:
bar, (1,1)
baz, (1)
foo, (1)(1,1) — это как бы вложенный массив, то есть технически — это так: ["bar", [1,1]].Дальше просто складываем вторые элементы массивов. Получаем:
bar, 2
baz, 1
foo, 1Именно то, что и хотели.
Главный вопрос — нафига козе баян… или что мы тут вообще делали и зачем?
Назад в прошлое
Если представить что у нас компьютер в который влезает только 2 строки и он может выполнять только одну операцию со строкой в минуту. (Отставить хихикать! После того как хотя бы раз посчитаете все слова в Википедии — будете иметь право смеяться над поставленными ограничениями памяти, все равно не влезет, хоть у Вас сколько гигов будет, а если влезет — считайте во всем Интернете :) ).
Мы можем (из
"foo bar baz bar") сделать два файла таким образом:file1.txt
[ 'bar', 1 ]
[ 'foo', 1 ]
file2.txt
[ 'bar', 1 ]
[ 'baz', 1 ]
У нас в памяти по две строки — все в порядке, уложились в ограничения по памяти.
Теперь используя шаг из MergeSort, мы можем объединять построчно эти файлы:
bar, (1,1)
baz, (1)
foo, (1)При этом в памяти каждый раз у нас только две строки хранятся из 2 файлов — больше и не надо.
Собственно, то, что мы сделали — это уже MapReduce.
Тот шаг, который из слов выдает массивы с единичками (
слово, 1) — этот шаг называется «Map». Тот шаг, который суммирует
(1,1) — это шаг «Reduce». Остальные шаги сделает сам алгоритм (сортировку и объединение через MergeSort).
Map, Reduce? Что это?
Сами эти шаги не обязательно заключаются в том, чтобы выдавать единички в случае «Map» или складывать в случае «Reduce». Это просто функции, которые могут что-то принять и что-то выдать. В зависимости от цели.
В данном случае «Map» — это написанная Вами функция, которая берет отдельное слово и выдает
(слово, 1). А «Reduce» — это написанная Вами функция, которая берет массив
(слово, (1,1)) и выдает (слово, 2).Проще говоря в Python:
words = ["foo", "bar", "baz"] def map1(word): return [word, 1] arr = ["foo", [1,1]] def reduce1(arr): return [ arr[0], sum(arr[1]) ]
или PHP:
$words = array("foo", "bar", "baz")
function map1($word) {
return array($word, 1);
}
arr = array("foo", array(1,1))
function reduce1(arr) {
return array( $arr[0], array_sum($arr[1]) );
}Итак, мы обошли ограничение по памяти, но как обойти ограничение по скорости?
Представим что у нас два таких компьютера. Каждому из них мы даем исходную строку и говорим первому (точнее MapReduce говорит): считай только слова на нечетных местах, а второму — считай слова только на четных местах.
Первый выдает:
"foo bar baz bar":
foo, 1
baz, 1Второй выдает:
"foo bar baz bar":
bar, 1
bar, 1Мы (точнее MapReduce) забираем результаты у обоих, сортируем, потом прогоняем через MergeSort, как и выше:
bar, (1,1)
baz, (1)
foo, (1)Ровно тот же результат, как и когда считал один компьютер!
Теперь это мы (MapReduce) раздаем опять двум компьютерам: первому даем только нечетные строки, второму — четные и просим каждый компьютер делать шаг Reduce (сложить вторые цифры).
Собственно, понятно, что эти строки друг от друга не зависят, так что результат будет опять же тем, что нужно.
Главное в том, что два компьютера работали в параллель и следовательно — в два раза быстрее, чем один из них (если не считать потери времени на передачу данных от одного к другому).
Преждевременный вывод
Фуф! Итак MapReduce — он нужен для того, чтобы считать что-то, что либо нужно делать быстрее, либо на что не хватает памяти (либо и то, и то).
Более интересный пример — сортировка по популярности (каскады)
Допустим мы хотим посчитать количество слов в Википедии и одновременно построить список в обратном порядке их популярности — от самых популярных, к самым непопулярным.
Ясно, что все слова википедии не влезут в память, да и для обратной сортировки потом этот массив гигантский не влезет в память. Нам понадобится каскад MapReduce'ов — результат работы первого MapReduce будет поступать на вход второго MapReduce.
Если честно — я не знаю является ли слово «каскад» правильным, применимо именно к MapReduce. Это слово я использую для себя, потому что оно как никакое другое объясняет что надо сделать (результат одного водопада слов падает в MapReduce и каскадом перетекает сразу же во второй MapReduce).
Ладно, как посчитать слова — мы уже знаем:
«foo bar baz foo»
Написанный нами шаг Map выдает:
foo, 1
bar, 1
baz, 1
foo, 1Дальше MapReduce объединяет (сам, не Вы, как программист) их в:
bar, (1)
baz, (1)
foo, (1,1)А написанный нами шаг Reduce выдает:
bar, 1
baz, 1
foo, 2Теперь представим, что считали мы всю Википедию и этот массив содержит миллиарды и миллиарды слов. Отсортировать его в памяти не получится. Возмем еще один MapReduce, в этот раз Map будет делать такой фокус:
[слово, 15] -> map() возвращает -> [-15, слово][слово2, 15] -> map() возвращает -> [-15, слово2][слово3, 120] -> map() возвращает -> [-120, слово3][слово4, 1] -> map() возвращает -> [-1, слово4]Для чего это надо?
MapReduce, перед тем как пойдет в Ваш Reduce, — отсортирует все эти массивы по первому элементу массива (который равен отрицательному числу). MapReduce сможет отсортировать даже если весь объем данных не влезет в память все — в этом и прелесть. Для всех слов Wikipedia Вы просто не сможете сделать
arsort($words), а MapReduce сможет.Почему минус перед цифрами?
Потому что MapReduce отсортирует всегда по возрастанию, а нам надо по убыванию. Как же используя сортировку только по возрастанию отсортировать числа в порядке уменьшения? Умножить на минус один перед сортировкой и опять на минус один после.
По возрастанию положительные числа:
1, 15, 120По возрастанию отрицательные числа:
-120, -15, -1 (то что нам надо, только со знаком минус, который потом просто уберем, умножив на -1)На вход Reduce придет такая штука:
-120, (слово3)
-15, (слово, слово2) <-- два слова на строке - MergeSort же сгруппировал все по первому ключу!
-1, (слово4)Прелесть, но у нас два слова имели «частоту» 15 и их сгруппировал MergeSort. Будем исправлять.
Теперь нам в нашем Reduce остается только умножить первое число на -1, а затем выдать для первой строки один массив, а для второй — два массива, для третьей — опять один.
На самом деле, в зависимости от того какое воплощение MapReduce будете использовать — Вам может и не удастся в шаге Reduce выдать два массива, потому что будет требоваться только один массив на выходе — тогда просто после шага Reduce это делайте уже в своей программе.
Получаем:
120, слово3
15, слово,
15, слово2
1, слово4Красота! То, что было надо.
Опять же помните, что главное что мы тут обходили — это то, что пример-то из четырех строк, а в Википедии миллиарды слов, которые в память не влезают.
Как сделать простейший MapReduce чтобы поиграться?
На PHP: простейший пример.
На Python простейший пример (см. ниже про Python версию).
В коде я указал что и где должно быть, чтобы сделать более-менее полноценный MapReduce с блекдж… в смысле с файлами и MergeSort'ом. Однако это так сказать эталонная реализация, который позволит поигаться и понять как MapReduce работает. Это все еще MapReduce, просто конкретно эта реализация с точки зрения памяти ничем не выгоднее обычного хеша.
Я выбрал PHP, хотя он не самый разумный для этих целей, потому что прочитать PHP может почти любой программист, а перевести на нужный язык — это уже проще будет.
Хинты и читы
Да, в файлы я рекомендую сохранять построчно JSON представление массивов (json_encode) — меньше будет проблем с пробелами в словах, с юникодом, числами и типами данных, то есть так:
["foo", 1]
["bar", 1]
["foo", 1]Подсказка — в Python последний шаг MergeSort уже реализован — это
heapq.merge(*iterables). То есть чтобы соединить 10 файлов с JSON представлениями достаточно:
items = list(itertools.imap(json.loads, open(filename)) for filename in files) for item in heapq.merge(*items): # ....reduce(item)....
В PHP с реализацией MergeSort, подозреваю надо возиться в полсотни строк. Если конечно в комментах никто лучше варианта не подскажет.
В Python
yield и __iter__ для MapReduce — позволят сделать очень интересные вещи! Например такие:x = MapReduce() for word in "foo bar bar".split(): x.send((word, 1)) for word, ones in x: print word, sum(ones)
class MapReduce — придется написать Вам самим (Я уложился в 24 строки в простейшем работающем виде, можно и меньше — упростив iter_group — это аналог функции group_tuples_by_first_element из примера для PHP). Осторожно — такой метод не совсем классический для MapReduce и его трудно будет распараллеливать на много машин (однако довольно тривиально в этом методе сделать работу с объемами данных больше чем доступно памяти). Метод
map_reduce(source_data, map1, reduce1), где map1 и reduce1 — это функции — более правильный.Воплощение MapReduce на Hadoop — самое популярное решение. (Я его не пробовал, просто знаю что самое популярное).
Послесловие
Так что вот, надеюсь мой рассказ о «MapReduce без зауми» придется полезным.
MapReduce — очень полезная штука для всяких больших масштабов расчетов. Практически любой SQL запрос, даже на несколько таблиц — не очень сложно раскладывается на MapReduce + join_iterator (об этом в другой раз).
Если будут силы — в следующем топике опишу как с помощью MapReduce считать более интересные задачки, чем банальные слова — как, например, считать ссылки в интернете, частоту слов в контексте других слов, людей в городах, товары по прайсам сотен фирм и т.п.
Да, всем ахтунг сюда! MapReduce запатентован Google, но скорее в защитных целях — тому же Hadoop они официально разрешили использовать этот метод. Так что — handle with care.
Часть вторая: более продвинутые примеры.
Йои Хаджи,
Вид, как всегда, с Хабра,
2010
(когда-нибудь я научусь объяснять кратко....)
