В PHP есть две замечательные функции serialize и unserialize. Первая преобразует в строку практически любой набор данных, вторая производит обратное преобразование. Эти функции удобно использовать при организации кеширования или хранения сессий в базе данных. Я обнаружил, что время работы функции unserialize может оказаться неожиданно большим.
Не буду описывать как и почему мне потребовалось сериализовать и десериализовать большой массив данных, гораздо интереснее посмотреть на то, что я обнаружил.
30 секунд на десериализацию! Этот результат меня просто шокировал. Для начала я проверил, что file_get_contents не влияет на результат выполнения. Затем посмотрел на производительность json_encode и json_decode (JSON set time 0.270335912704 get time 1.30652809143). «Всё страньше и страньше», подумал я и решил построить график зависимости времени работы функции unserialize от длины десериализуемого массива.

На графике чётко видна квадратичная (!) зависимость времени выполнения функции от длины массива. Вот такая неожиданно медленная встроенная функция unserialize.
Ситуация, конечно, не критичная. Можно использовать другие способы сериализации и десериализации. Основная цель статьи — показать как зависит производительность функции unserialize от размера данных.
Исходные коды для проверки результатов можно взять по адресу http://alexxz.ru/habr/unserialize_benchmark.tar.gz
Используемый софт и железо PHP 5.3.2
Linux ubuntu 2.6.32–24-generic (10.4)
Intel® Core™2 CPU 6600 @ 2.40GHz
______________________
Не буду описывать как и почему мне потребовалось сериализовать и десериализовать большой массив данных, гораздо интереснее посмотреть на то, что я обнаружил.
- <?php
- ini_set('memory_limit', '512M');
- $file = '/tmp/1';
- $data = range(1,2000000);
-
- echo "Test serialize\n";
- $time0 = microtime(1);
- file_put_contents($file, serialize($data));
- $time1 = microtime(1);
- unserialize(file_get_contents($file));
- $time2 = microtime(1);
-
- $timeset = $time1-$time0;
- $timeget = $time2-$time1;
-
- echo "Serialize set time $timeset get time $timeget\n";
Test serialize Serialize set time 1.35619807243 get time 31.1126699448
30 секунд на десериализацию! Этот результат меня просто шокировал. Для начала я проверил, что file_get_contents не влияет на результат выполнения. Затем посмотрел на производительность json_encode и json_decode (JSON set time 0.270335912704 get time 1.30652809143). «Всё страньше и страньше», подумал я и решил построить график зависимости времени работы функции unserialize от длины десериализуемого массива.
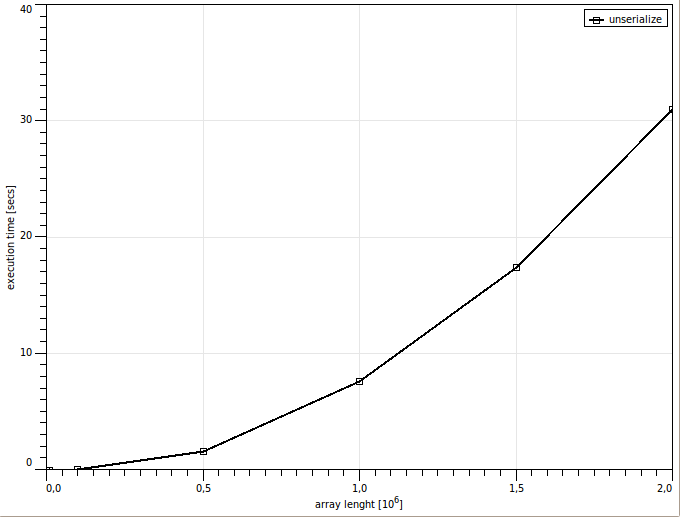
На графике чётко видна квадратичная (!) зависимость времени выполнения функции от длины массива. Вот такая неожиданно медленная встроенная функция unserialize.
Ситуация, конечно, не критичная. Можно использовать другие способы сериализации и десериализации. Основная цель статьи — показать как зависит производительность функции unserialize от размера данных.
Исходные коды для проверки результатов можно взять по адресу http://alexxz.ru/habr/unserialize_benchmark.tar.gz
Используемый софт и железо PHP 5.3.2
Linux ubuntu 2.6.32–24-generic (10.4)
Intel® Core™2 CPU 6600 @ 2.40GHz
______________________
