Прошлый топик, про оценку сложности алгоритмов был весьма положительно оценён хабрасообществом. Из этого я могу сделать вывод, что тема базовых алгоритмов весьма интересна. Сегодня я хочу представить вам часть, посвящённую алгоритмам сортировки. Про базовые алгоритмы писать для Хабра совсем несерьёзно, а вот про сортировки Шелла, пирамидальную и быструю рассказать всё-таки стоит. (Если кому-то интересно почитать про базовые методы, милости прошу сюда)
В 1959 году Шелл предложил способ ускорить сортировку простыми вставками. Сначала каждая группа элементов, отстоящих друг от друга на k1 элементов, сортируется отдельно. Это процесс называется k1-сортировкой. После первого прохода рассматриваются группы элементов, но уже отстоящих друг от друга на k2 (k2<k1) позиций, и эти группы тоже сортируются по отдельности. Этот процесс называется k2-сортировкой. Так проводится несколько итераций, и в конце шаг сортировки становится равным 1.
Встаёт резонный вопрос: не превысят ли возможную экономию затраты на выполнение нескольких проходов, в каждом из которых сортируются все элементы? Однако, каждая сортировка одной группы элементов либо имеет дело с относительно небольшим их числом, либо элементы уже частично отсортированы, так что нужно сделать сравнительно немного перестановок.
Очевидно, что метод приводит к отсортированному массиву, и нетрудно понять, что на каждом шаге нужно выполнить меньше работы благодаря предыдущим итерациям (т.к. каждая ki сортировка комбинирует две группы, отсортированные предыдущей ki-1 сортировкой). Очевидно также, что допустима любая последовательность расстояний, лишь бы последнее из них было равно единице. Не так очевидно, что метод работает лучше, если уменьшающиеся расстояния выбирать отличными от степени двойки.
Приведём алгоритм для произвольной последовательности расстояний. Всего будет T расстояний h1,h2,…,hT, удовлетворяющих условиям: hT=1, hi+1<hi.
Анализ этого алгоритма – сложная математическая задача, у которой до сих пор нет полного решения. В настоящий момент неизвестно, какая последовательность расстояний даёт наилучший результат, но известно, что расстояния не должны быть кратными друг другу. Это необходимо, чтобы очередной проход не объединял две последовательности, до того никак не пересекавшиеся. На самом деле желательно, чтобы последовательности пересекались как можно чаще. Это связано со следующей теоремой: если последовательность после ki сортировке подвергается ki+1 сортировке, то она при этом остаётся ki сортированной.
Кнут предлагает в качестве последовательно уменьшающихся расстояний использовать одну из следующих последовательностей (приведены в обратном порядке): 1,4,13,40,121,…, где hi-1=3*hi+1 или 1,3,7,15,31,…, где hi-1=2*hi+1. В последнем случае математическое исследование показывает, что при сортировке N элементов алгоритмом Шелла затраты пропорциональны N1.2. Хотя это гораздо лучше, чем N2, мы не будем углубляться в этот метод, так как есть ещё более быстрые алгоритмы.
Простая сортировка выбором основана на повторном выборе наименьшего ключа среди N элементов, затем среди оставшихся N-1 элементов и т.д. Очевидно, для того, чтобы найти наименьший ключ среди n элементов нужно N-1 сравнений, среди N-1 элементов нужно N-2 сравнений и т.д. Очевидно, что сумма первых N-1 натуральных чисел равна (N2-N)/2. Эту сортировку можно улучшить, только если после каждого просмотра сохранять больше информации, чем всего лишь об одном наименьшем элементе. Например, N/2 сравнений позволяют определить меньший ключ в каждой паре, ещё N/4 сравнений дадут меньший ключ в каждой паре из уже найденных меньших ключей и т.д. Рассмотрим массив 12,18,42,44,55,67,94,6. Сделав n-1 сравнений, мы можем построить дерево выбора, причём в корне будет наименьший ключ.
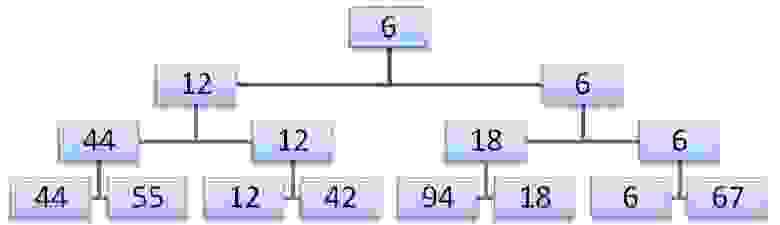
Второй шаг состоит в спуске по пути, соответствующему наименьшему ключу и его замене на пустую позицию в листе дерева, либо на элемент из другой ветви в промежуточных узлах.
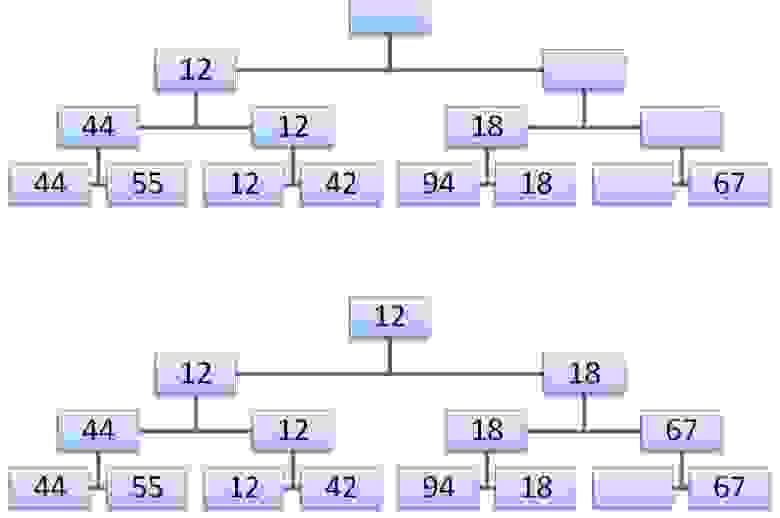
Теперь элементом в корне дерева будет очередной наименьший ключ. Теперь можно удалить его. После N таких шагов в дереве не останется ни одного узла с ключом, и процесс сортировки на этом завершится. Очевидно, что на каждом из N шагов требуется log(N) сравнений, поэтому вся процедура требует порядка N*log(N) элементарных операций (помимо тех N шагов, которые нужны для построения дерева). Это значительное улучшение не только по сравнению с простыми методами, требующими N2 шагов, но и с сортировкой Шелла, требующей N1.2 шагов. Естественно, сложность элементарных шагов в этом алгоритме выше: чтобы сохранить всю информацию с предыдущего шага необходимо использовать некоторое дерево. Теперь нам необходимо найти способ эффективно организовать эту информацию.
В первую очередь надо избавиться от необходимости хранить пустые значения, которые, в конце концов, заполнят всё дерево и приведут к большому числу лишних сравнений. Затем надо найти способ сделать так, чтобы дерево занимало в памяти N единиц, вместо 2*N-1, как это происходит на рисунках. Обе цели были достигнуты в алгоритме HeapSort, названном так его изобретателем Вильямсом. Этот алгоритм является радикальным улучшением обычной турнирной сортировки.
Пирамидой (heap) называется последовательность ключей hL,hL+1,…,hR (L≥0), такая, что hi<h2i+1 и hi<h2i+2, для i=L…R/2-1. Получается, что любое двоичное дерево можно представить массивом, так, как показано на рисунке (при этом вершина пирамиды будет её наименьшим элементом).
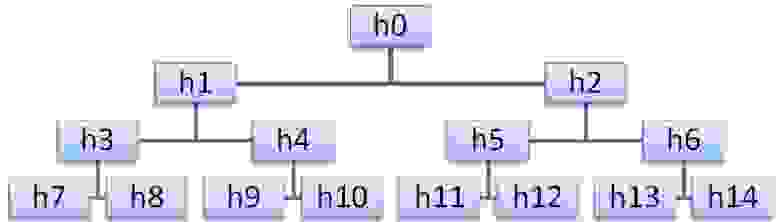
Алгоритм расширения пирамиды довольно прост. Новая пирамида получается так: сначала добавляемый элемент x ставится на вершину пирамиды, а потом просеивается вниз, меняясь местами с наименьшим из двух потомков, который, соответственно, передвигается вверх.
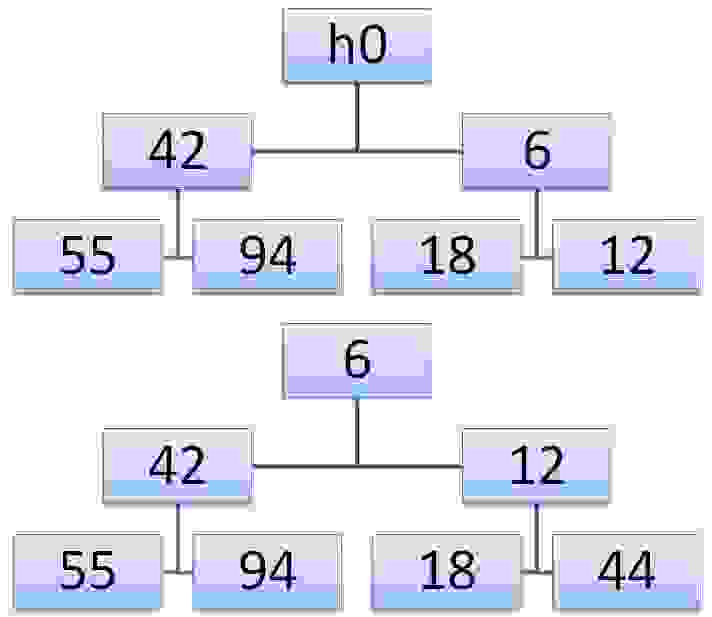
В нашем примере мы расширим пирамиду числом h0=44. Сначала ключ 44 меняется местами с 6, а затем с 12. В итоге получаем искомое дерево. Мы сформулируем алгоритм просеивания в терминах пары индексов i,j, соответствующих элементам, которые обмениваются на каждом шаге просеивания.
Метод, который мы рассмотрим, и был предложен Флойдом. Основа метода процедура sift (просеивание). Если у нас есть массив h1…hN, то его элементы с номерами от m=N div 2 до N уже образуют пирамиду (т.к. в этих элементах нет таких пар i,j, чтобы j=2*i+1 или j=2*i+2). Эти элементы будут образовывать нижний ряд пирамиды. Заметим, что в нижнем ряду никакое упорядочивание не требуется. Затем начинается процесс расширения пирамиды. Причём за один шаг в неё будет включаться только один элемент, и этот элемент будет ставиться на своё место с помощью процедуры просеивания, которую мы сейчас рассмотрим.
Процесс получения пирамиды можно описать следующим образом:
Пирамида, которую мы получим, характеризуется тем, что в её вершине будет храниться наибольший (а не наименьший) ключ. Кроме того, полученный массив будет упорядочен не полностью. Для того, чтобы добиться полной упорядоченности нужно выполнить ещё N просеиваний и после каждого из них снимать с вершины очередной элемент. Возникает вопрос, где хранить снимаемые с вершины элементы. Существует довольно красивое решение этой задачи: нам необходимо взять последний элемент пирамиды (будем называть его x), записать элемент с вершины пирамиды в позицию, освободившуюся из под x, а элемент x поставить в правильную позицию очередным просеиванием. Этот процесс можно описать следующим образом:
Таким образом, алгоритм пирамидальной сортировки можно представить следующим кодом:
В этом алгоритме большие элементы сначала просеиваются влево, и только потом занимают окончательные позиции в правой части отсортированного массива. Из-за этого может показаться, что эффективность пирамидальной сортировки не очень высока. Действительно, для сортировки небольшого числа элементов лучше воспользоваться другими алгоритмами, но для больших N эта сортировка очень эффективна.
В худшем случае фаза создания пирамиды требует N/2 шагов просеивания, причём на каждом шаге элементы просеиваются через log(N/2),log(N/2+1),…,log(N-1) позиций. Затем фаза сортировки требует n-1 просеиваний с не более чем log(N-1),log(N-2),…,1 пересылок. Кроме того потребуется n-1 пересылок для того, чтобы поставить элементы с вершины пирамиды на свои места. Получается, что даже в наихудшем случае пирамидальная сортировка требует N*log(N) пересылок. Это свойство является важнейшей отличительной особенностью данного алгоритма.
Наилучшей производительности можно ожидать, если элементы изначально стоят в обратном порядке. Тогда фаза создания пирамиды не потребует пересылок. Среднее число пересылок равно N/2*log(N), а отклонения от этого значения довольно малы.
Два предыдущих метода были основаны на принципах вставки и выбора. Пришло время рассмотреть третий, основанный на принципе обмена. Пузырьковая сортировка оказалась наихудшей среди всех трёх простых алгоритмов, однако усовершенствование обменной сортировки даёт лучший из известных методов сортировки массивов.
Построение быстрой сортировки исходит из того, что для достижения максимальной эффективности желательно выполнять обмены между максимально удалёнными позициями. Пусть у нас есть N элементов, расставленных в обратном порядке. Можно отсортировать их всего лишь за N/2 обменов, сначала обменяв крайний левый и крайний правый элементы, а потом постепенно продвигаясь внутрь массива с обеих сторон. Разумеется, этот метод сработает, только если элементы в массиве упорядочены в обратном порядке. Но тем не менее именно на этой идее построен рассматриваемый метод.
Попробуем реализовать такой алгоритм: случайно выберем любой элемент (назовём его x). Будем просматривать массив слева, пока не найдём элемент ai>x, а затем справа, пока не найдём элемент. aj<x Затем выполним обмен двух найденных элементов и будем продолжать такой процесс, пока оба просмотра не встретятся где-то в середине массива. В результате получим массив, разделённый на две части: левую, с ключами меньшими (или равными) x, и правую с ключами большими (или равными) x. Сформулируем процесс разделения в виде процедуры:
Теперь вспомним, что наша цель не просто разделить массив, но и отсортировать его. На самом деле от разделения до сортировки всего один небольшой шаг: после разделения массива нужно применить тот же процесс к обеим получившимся частям, затем к частям частей и т.д., пока каждая часть не будет состоять из одного элемента.
Чтобы изучить эффективность быстрой сортировки, нужно сначала исследовать поведение процесса разделения. После выбора разделяющего значения x просматривается весь массив, поэтому выполнится точно N сравнений. Если нам везёт, и в качестве границы всегда выбирается медиана (средний элемент массива), то каждая итерация разбивает массив пополам, и число необходимых проходов равно log(N). Тогда полное число сравнений равно N*log(N), а полное число обменов равно N*log(N)/6.
Конечно, нельзя ожидать, что с выбором медианы всегда будет так везти. Строго говоря, вероятность этого 1/N. Но показано, что ожидаемая эффективность быстрой сортировки хуже оптимальной только на множитель 2*ln(2).
Даже у алгоритма быстрой сортировки есть недостатки. При малых N его производительность можно оценить как удовлетворительную, но его преимущество заключается в лёгкости подключения простого метода для обработки сегментов. Ещё остаётся проблема наихудшего случая. Предположим, что каждый раз в качестве разделяющего элемента выбирается наибольшее значение в разделяемом сегменте. Тогда каждый шаг будет разделять фрагмент из N элементов на две последовательности из 1 и N-1 элементов, соответственно. Очевидно, что в наихудшем случае поведение оценивается величиной N2. Чтобы избежать наихудшего случая, было предложено выбирать элемент x, как медиану из трёх значений разделяемого сегмента. Такое дополнение не ухудшает алгоритм в общем случае, но сильно улучшит его поведение в наихудшем случае.
Эффективные методы сортировки
Сортировка вставками с уменьшающимся расстоянием (сортировка Шелла)
В 1959 году Шелл предложил способ ускорить сортировку простыми вставками. Сначала каждая группа элементов, отстоящих друг от друга на k1 элементов, сортируется отдельно. Это процесс называется k1-сортировкой. После первого прохода рассматриваются группы элементов, но уже отстоящих друг от друга на k2 (k2<k1) позиций, и эти группы тоже сортируются по отдельности. Этот процесс называется k2-сортировкой. Так проводится несколько итераций, и в конце шаг сортировки становится равным 1.
Встаёт резонный вопрос: не превысят ли возможную экономию затраты на выполнение нескольких проходов, в каждом из которых сортируются все элементы? Однако, каждая сортировка одной группы элементов либо имеет дело с относительно небольшим их числом, либо элементы уже частично отсортированы, так что нужно сделать сравнительно немного перестановок.
Очевидно, что метод приводит к отсортированному массиву, и нетрудно понять, что на каждом шаге нужно выполнить меньше работы благодаря предыдущим итерациям (т.к. каждая ki сортировка комбинирует две группы, отсортированные предыдущей ki-1 сортировкой). Очевидно также, что допустима любая последовательность расстояний, лишь бы последнее из них было равно единице. Не так очевидно, что метод работает лучше, если уменьшающиеся расстояния выбирать отличными от степени двойки.
Приведём алгоритм для произвольной последовательности расстояний. Всего будет T расстояний h1,h2,…,hT, удовлетворяющих условиям: hT=1, hi+1<hi.
- procedure ShellSort;
- const
- T=5;
- var
- i,j,k,m: longint;
- x: longint;
- h: array [1..5] of integer;
- begin
- h[1]:=31; h[2]:=15; h[3]:=7; h[2]:=3; h[1]:=1;
- for m:=1 to T do
- begin
- k:=h[m];
- for i:=k to N do
- begin
- x:=a[i];
- j:=i-k;
- while (j>=k) and (x<a[j]) do
- begin
- a[j+k]:=a[j];
- j:=j-k;
- end;
- if (j>=k) or (x>=a[j]) then
- a[j+k]:=x
- else
- begin
- a[j+k]:=a[j];
- a[j]:=x;
- end;
- end;
- end;
- end;
Анализ этого алгоритма – сложная математическая задача, у которой до сих пор нет полного решения. В настоящий момент неизвестно, какая последовательность расстояний даёт наилучший результат, но известно, что расстояния не должны быть кратными друг другу. Это необходимо, чтобы очередной проход не объединял две последовательности, до того никак не пересекавшиеся. На самом деле желательно, чтобы последовательности пересекались как можно чаще. Это связано со следующей теоремой: если последовательность после ki сортировке подвергается ki+1 сортировке, то она при этом остаётся ki сортированной.
Кнут предлагает в качестве последовательно уменьшающихся расстояний использовать одну из следующих последовательностей (приведены в обратном порядке): 1,4,13,40,121,…, где hi-1=3*hi+1 или 1,3,7,15,31,…, где hi-1=2*hi+1. В последнем случае математическое исследование показывает, что при сортировке N элементов алгоритмом Шелла затраты пропорциональны N1.2. Хотя это гораздо лучше, чем N2, мы не будем углубляться в этот метод, так как есть ещё более быстрые алгоритмы.
Пирамидальная сортировка (турнирная сортировка)
Простая сортировка выбором основана на повторном выборе наименьшего ключа среди N элементов, затем среди оставшихся N-1 элементов и т.д. Очевидно, для того, чтобы найти наименьший ключ среди n элементов нужно N-1 сравнений, среди N-1 элементов нужно N-2 сравнений и т.д. Очевидно, что сумма первых N-1 натуральных чисел равна (N2-N)/2. Эту сортировку можно улучшить, только если после каждого просмотра сохранять больше информации, чем всего лишь об одном наименьшем элементе. Например, N/2 сравнений позволяют определить меньший ключ в каждой паре, ещё N/4 сравнений дадут меньший ключ в каждой паре из уже найденных меньших ключей и т.д. Рассмотрим массив 12,18,42,44,55,67,94,6. Сделав n-1 сравнений, мы можем построить дерево выбора, причём в корне будет наименьший ключ.
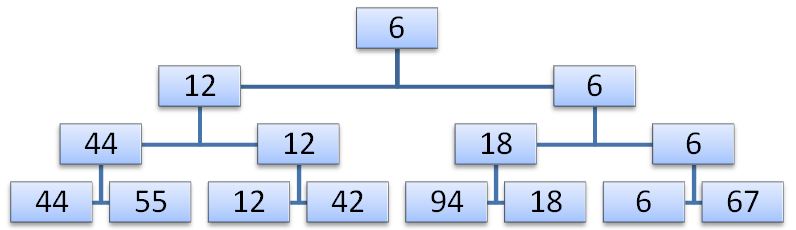
Второй шаг состоит в спуске по пути, соответствующему наименьшему ключу и его замене на пустую позицию в листе дерева, либо на элемент из другой ветви в промежуточных узлах.
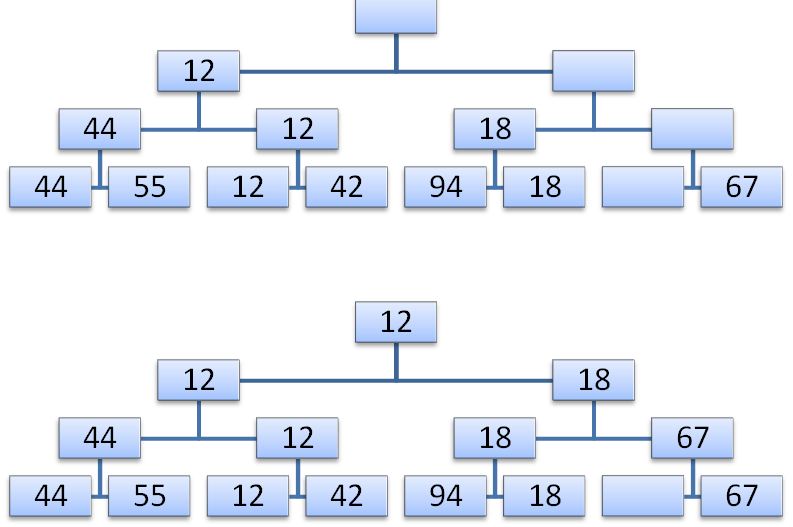
Теперь элементом в корне дерева будет очередной наименьший ключ. Теперь можно удалить его. После N таких шагов в дереве не останется ни одного узла с ключом, и процесс сортировки на этом завершится. Очевидно, что на каждом из N шагов требуется log(N) сравнений, поэтому вся процедура требует порядка N*log(N) элементарных операций (помимо тех N шагов, которые нужны для построения дерева). Это значительное улучшение не только по сравнению с простыми методами, требующими N2 шагов, но и с сортировкой Шелла, требующей N1.2 шагов. Естественно, сложность элементарных шагов в этом алгоритме выше: чтобы сохранить всю информацию с предыдущего шага необходимо использовать некоторое дерево. Теперь нам необходимо найти способ эффективно организовать эту информацию.
В первую очередь надо избавиться от необходимости хранить пустые значения, которые, в конце концов, заполнят всё дерево и приведут к большому числу лишних сравнений. Затем надо найти способ сделать так, чтобы дерево занимало в памяти N единиц, вместо 2*N-1, как это происходит на рисунках. Обе цели были достигнуты в алгоритме HeapSort, названном так его изобретателем Вильямсом. Этот алгоритм является радикальным улучшением обычной турнирной сортировки.
Пирамидой (heap) называется последовательность ключей hL,hL+1,…,hR (L≥0), такая, что hi<h2i+1 и hi<h2i+2, для i=L…R/2-1. Получается, что любое двоичное дерево можно представить массивом, так, как показано на рисунке (при этом вершина пирамиды будет её наименьшим элементом).
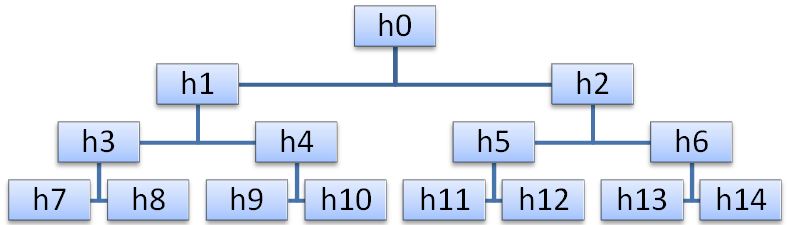
Алгоритм расширения пирамиды довольно прост. Новая пирамида получается так: сначала добавляемый элемент x ставится на вершину пирамиды, а потом просеивается вниз, меняясь местами с наименьшим из двух потомков, который, соответственно, передвигается вверх.
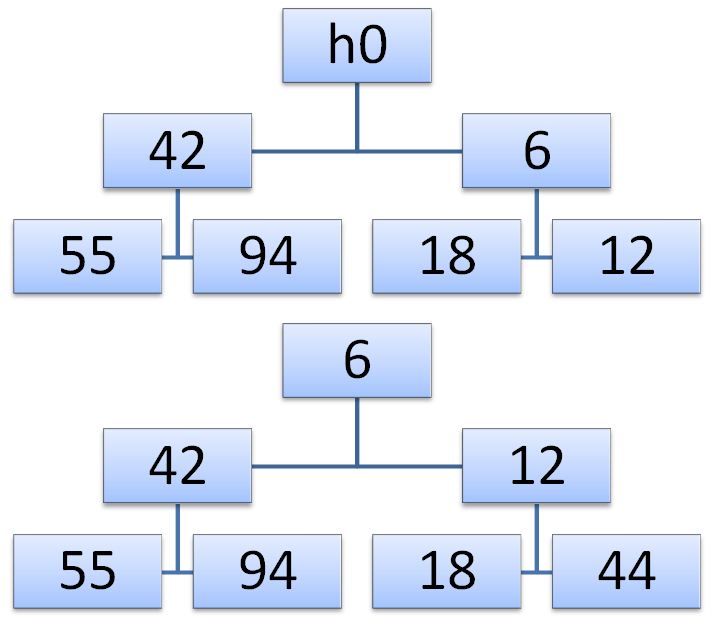
В нашем примере мы расширим пирамиду числом h0=44. Сначала ключ 44 меняется местами с 6, а затем с 12. В итоге получаем искомое дерево. Мы сформулируем алгоритм просеивания в терминах пары индексов i,j, соответствующих элементам, которые обмениваются на каждом шаге просеивания.
Метод, который мы рассмотрим, и был предложен Флойдом. Основа метода процедура sift (просеивание). Если у нас есть массив h1…hN, то его элементы с номерами от m=N div 2 до N уже образуют пирамиду (т.к. в этих элементах нет таких пар i,j, чтобы j=2*i+1 или j=2*i+2). Эти элементы будут образовывать нижний ряд пирамиды. Заметим, что в нижнем ряду никакое упорядочивание не требуется. Затем начинается процесс расширения пирамиды. Причём за один шаг в неё будет включаться только один элемент, и этот элемент будет ставиться на своё место с помощью процедуры просеивания, которую мы сейчас рассмотрим.
- procedure sift(L,R: integer);
- var
- i,j: integer;
- x: longint;
- begin
- i:=L;
- j:=2*i;
- x:=a[i];
- if (j<R) and (a[j]<a[j+1]) then
- j:=j+1;
- while (j<=R) and (x<a[j]) do
- begin
- a[i]:=a[j];
- i:=j;
- j:=2*j;
- if (j<R) and (a[j]<a[j+1]) then
- j:=j+1;
- end;
- a[i]:=x;
- end;
Процесс получения пирамиды можно описать следующим образом:
- L:=(N div 2)+1;
- R:=N;
- while L>1 do
- begin
- L:=L-1;
- sift(L,R);
- end;
Пирамида, которую мы получим, характеризуется тем, что в её вершине будет храниться наибольший (а не наименьший) ключ. Кроме того, полученный массив будет упорядочен не полностью. Для того, чтобы добиться полной упорядоченности нужно выполнить ещё N просеиваний и после каждого из них снимать с вершины очередной элемент. Возникает вопрос, где хранить снимаемые с вершины элементы. Существует довольно красивое решение этой задачи: нам необходимо взять последний элемент пирамиды (будем называть его x), записать элемент с вершины пирамиды в позицию, освободившуюся из под x, а элемент x поставить в правильную позицию очередным просеиванием. Этот процесс можно описать следующим образом:
- while R>1 do
- begin
- x:=a[1];
- a[1]:=A[R];
- A[R]:=x;
- R:=R-1;
- sift(L,R);
- end;
Таким образом, алгоритм пирамидальной сортировки можно представить следующим кодом:
- procedure HeapSort;
- procedure sift(L,R: integer);
- var
- i,j: integer;
- x: longint;
- begin
- i:=L;
- j:=2*i;
- x:=a[i];
- if (j<R) and (a[j]<a[j+1]) then
- j:=j+1;
- while (j<=R) and (x<a[j]) do
- begin
- a[i]:=a[j];
- i:=j;
- j:=2*j;
- if (j<R) and (a[j]<a[j+1]) then
- j:=j+1;
- end;
- a[i]:=x;
- end;
- var
- L,R: integer;
- x: longint;
- begin
- L:=(N div 2)+1;
- R:=N;
- while L>1 do
- begin
- L:=L-1;
- sift(L,R);
- end;
- while R>1 do
- begin
- x:=a[1];
- a[1]:=A[R];
- A[R]:=x;
- R:=R-1;
- sift(L,R);
- end;
- end;
В этом алгоритме большие элементы сначала просеиваются влево, и только потом занимают окончательные позиции в правой части отсортированного массива. Из-за этого может показаться, что эффективность пирамидальной сортировки не очень высока. Действительно, для сортировки небольшого числа элементов лучше воспользоваться другими алгоритмами, но для больших N эта сортировка очень эффективна.
В худшем случае фаза создания пирамиды требует N/2 шагов просеивания, причём на каждом шаге элементы просеиваются через log(N/2),log(N/2+1),…,log(N-1) позиций. Затем фаза сортировки требует n-1 просеиваний с не более чем log(N-1),log(N-2),…,1 пересылок. Кроме того потребуется n-1 пересылок для того, чтобы поставить элементы с вершины пирамиды на свои места. Получается, что даже в наихудшем случае пирамидальная сортировка требует N*log(N) пересылок. Это свойство является важнейшей отличительной особенностью данного алгоритма.
Наилучшей производительности можно ожидать, если элементы изначально стоят в обратном порядке. Тогда фаза создания пирамиды не потребует пересылок. Среднее число пересылок равно N/2*log(N), а отклонения от этого значения довольно малы.
Быстрая сортировка
Два предыдущих метода были основаны на принципах вставки и выбора. Пришло время рассмотреть третий, основанный на принципе обмена. Пузырьковая сортировка оказалась наихудшей среди всех трёх простых алгоритмов, однако усовершенствование обменной сортировки даёт лучший из известных методов сортировки массивов.
Построение быстрой сортировки исходит из того, что для достижения максимальной эффективности желательно выполнять обмены между максимально удалёнными позициями. Пусть у нас есть N элементов, расставленных в обратном порядке. Можно отсортировать их всего лишь за N/2 обменов, сначала обменяв крайний левый и крайний правый элементы, а потом постепенно продвигаясь внутрь массива с обеих сторон. Разумеется, этот метод сработает, только если элементы в массиве упорядочены в обратном порядке. Но тем не менее именно на этой идее построен рассматриваемый метод.
Попробуем реализовать такой алгоритм: случайно выберем любой элемент (назовём его x). Будем просматривать массив слева, пока не найдём элемент ai>x, а затем справа, пока не найдём элемент. aj<x Затем выполним обмен двух найденных элементов и будем продолжать такой процесс, пока оба просмотра не встретятся где-то в середине массива. В результате получим массив, разделённый на две части: левую, с ключами меньшими (или равными) x, и правую с ключами большими (или равными) x. Сформулируем процесс разделения в виде процедуры:
- procedure partition;
- var
- i,j: integer;
- w,x: integer;
- begin
- i:=1;
- j:=n;
- // выбрать наугад значение x
- REPEAT
- while a[i]<x do
- i:=i+1;
- while x<a[j] do
- j:=j-1;
- if i<=j then
- begin
- w:=a[i];
- a[i]:=a[j];
- a[j]:=w;
- i:=i+1;
- j:=j-1;
- end;
- UNTIL i>j;
- end;
Теперь вспомним, что наша цель не просто разделить массив, но и отсортировать его. На самом деле от разделения до сортировки всего один небольшой шаг: после разделения массива нужно применить тот же процесс к обеим получившимся частям, затем к частям частей и т.д., пока каждая часть не будет состоять из одного элемента.
- procedure sort(L,R: integer);
- var
- i,j: integer;
- w,x: longint;
- begin
- i:=L;
- j:=R;
- x:=a[(L+R) div 2];
- REPEAT
- while a[i]<x do
- i:=i+1;
- while x<a[j] do
- j:=j-1;
- if i<=j then
- begin
- w:=a[i];
- a[i]:=a[j];
- a[j]:=w;
- i:=i+1;
- j:=j-1;
- end;
- UNTIL i>j;
- if L<j then
- sort(L,j);
- if i<R then
- sort(i,R);
- end;
- procedure QuickSort;
- begin
- sort(1,N);
- end;
Чтобы изучить эффективность быстрой сортировки, нужно сначала исследовать поведение процесса разделения. После выбора разделяющего значения x просматривается весь массив, поэтому выполнится точно N сравнений. Если нам везёт, и в качестве границы всегда выбирается медиана (средний элемент массива), то каждая итерация разбивает массив пополам, и число необходимых проходов равно log(N). Тогда полное число сравнений равно N*log(N), а полное число обменов равно N*log(N)/6.
Конечно, нельзя ожидать, что с выбором медианы всегда будет так везти. Строго говоря, вероятность этого 1/N. Но показано, что ожидаемая эффективность быстрой сортировки хуже оптимальной только на множитель 2*ln(2).
Даже у алгоритма быстрой сортировки есть недостатки. При малых N его производительность можно оценить как удовлетворительную, но его преимущество заключается в лёгкости подключения простого метода для обработки сегментов. Ещё остаётся проблема наихудшего случая. Предположим, что каждый раз в качестве разделяющего элемента выбирается наибольшее значение в разделяемом сегменте. Тогда каждый шаг будет разделять фрагмент из N элементов на две последовательности из 1 и N-1 элементов, соответственно. Очевидно, что в наихудшем случае поведение оценивается величиной N2. Чтобы избежать наихудшего случая, было предложено выбирать элемент x, как медиану из трёх значений разделяемого сегмента. Такое дополнение не ухудшает алгоритм в общем случае, но сильно улучшит его поведение в наихудшем случае.
