В своей предыдущей статье я вкратце коснулся темы создания High Availability решения на основе демона heartbeat. Однако, как выяснилось, что-то сложнее чем 2-х узловой кластер на нем делать не так уж удобно. Изучение проблемы вывело меня на след проекта Pacemaker. Его-то мы сейчас в кратце и рассмотрим.

Согласно официальной документации, Pacemaker — это менеджер ресурсов кластера со следующими основными фичами:
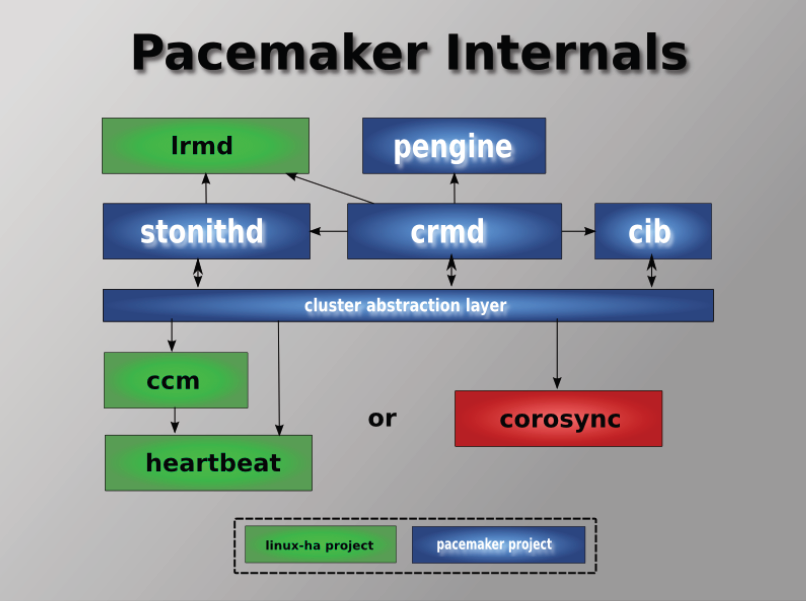
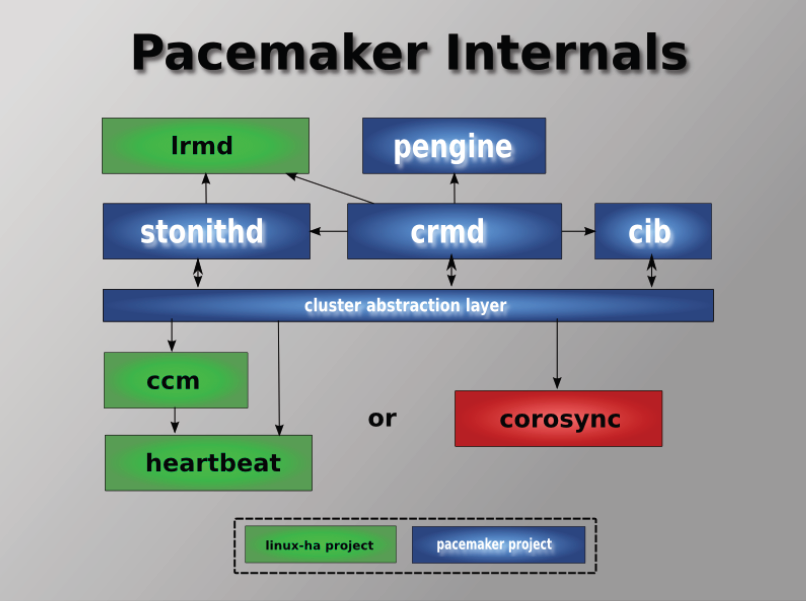
Проект кроме собственно своих демонов, поддерживающих конфиг кластера и указанный выше шелл, также использует сторонние, тот же heartbeat и corosync. Я лично (собственно авторы тоже) рекомендую использовать corosync. В общем-то он поддерживает скрипты от heartbeat, поэтому проблем возникнуть не должно.
На RHEL/CentOS нет ничего проще.
Затем редаектируем /etc/corosync/corosync.conf (там есть corosync.conf.sample) и стартуем.
Да, крайне необходимо иметь правильно настроенный DNS, чтобы резолвились в обе стороны все узлы.
Как добавить узлы? Нет ничего проще, ставим Pacemaker, копируем /etc/corosync/corosync.conf и /etc/ais/authkeys (если настраивали) и запускаем. Узел будет автоматически включен в кластер. Конфиг кластера будет также автоматически скопирован.
Если узел вышел из строя и вы заменили железо? Тоже самое, даем новому узлу то же имя, копируем конфиги и стартуем. Лепота.
Конфигурация кластера представляет собой простой XML. Однако вручную его править НЕЛЬЗЯ. Все изменения конфига подвергаются автоматическому версионированнию, узлы получают не весь конфиг разом, а только дельты от того, о чем они знают. Т.е. если узел вышел из строя, а в это время вы поменяли конфиг, то когда он вернется, он получит все изменения, которые вы сделали.
Для работы с конфигом можно использовать либо cibadmin, либо собственно сам шелл crm. Посмотреть конфиг можно например так:
Кроме собственно опций кластера, конфигурированию подлежат также:
Как добавлять узлы мы уже разобрались. Удаляются узлы не многим сложнее: останавливаем corosync на узле, а затем удаляем узел из конфига.
Не забывайте, что кворум достигается когда в строю более половины узлов. Поэтому если у вас кластер всего из 2-х, то эту опцию стоит отключить, иначе при падении любого из них, кластер будет считать себя развалившимся.
Что есть ресурс с точки зрения corosync? Все, что может быть заскриптовано! Обычно скрипты пишутся на bash, но ничто не мешает вам писать их на Perl, Python или даже на C. Все, что требуется от скрипта, это выполнять 3 действия: start, stop и monitor. В общем-то скрипты должны соответствовать LSB (Linux Standard Base) или OCF (Open Cluster Framework) — последнее несколько расширяет LSB, требуя также передачи параметров через переменные окружения с особым названием.
Как мы видим, довольно много уже готовых агентов (Resource Agents). Впрочем, написать самому новый тоже вряд ли составит большого труда.
При создании ресурса нам потребуется задать его класс, тип, провайдера и собственно имя с дополнительными параметрами. В списке выше: ocf — класс, heartbeat — провайдер, IPaddr — тип агента.
Ресурсы поддерживают множество дополнительных параметров, вроде привязки к узлу (resource-stickiness), роли по умолчанию (started, stoped, master) и т.д. Есть возможности по созданию групп ресурсов, клонов (работающих на нескольких узлах) и т.п.
Начнем с того, что любая связь имеет свой вес — целое число в пределах от -INFINITY до +INFINITY. При этом если вес связи ± INFINITY, то она считается жесткой, в противном случае — мягкой, т.е. если веса других связей окажутся выше, она может быть проигнорирована.
Связи определяют привязку ресурсов к узлу (location), порядок запуска ресурсов (ordering) и совместное их проживание на узле (colocation).
Здесь мы создали еще один ресурс — WebSite, задали совместное проживание его с ClusterIP (кстати, -INFINITY означало бы, что ресурсы НЕ должны находиться на одном узле), определили порядок запуска: сначала ClusterIP, потом WebSite, а потом задали, что WebSite очень желательно находиться на узле pcmk-1, с весом 50. При задании порядка также можно указать, можно ли стартовать ресурсы параллельно или делать это последовательно.
В общем таким образом можно строить довольно сложные цепочки зависимостей ресурсов. Все становиться еще интереснее, если учесть, что можно задавать более сложные правила (rules), срабатывающие, например, только в определенное время суток или в зависимости от состояния компонентов кластера.
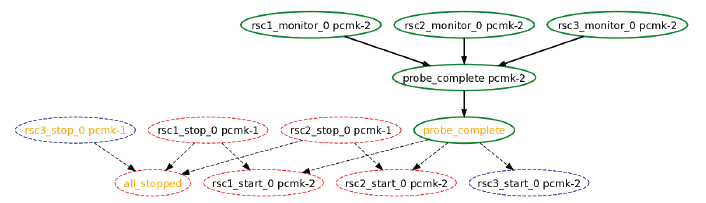
Кстати, для облегчения понимая авторы наделили Pacemaker возможностью строить графики в формате Graphviz — см. утилиту ptest.
Pacemaker прост и удобен, но при этом очень мощен и богат возможностями. После IBM HA MS вообще не могу нарадоваться на этот проект :). Чтобы не забивать пост излишними подробностями, да и для дальнейшего изучения вам понадобиться следующая литература:
Спасибо за внимание.
Pacemaker
Согласно официальной документации, Pacemaker — это менеджер ресурсов кластера со следующими основными фичами:
- Обнаружение и восстановление сбоев на уровне узлов и сервисов;
- Независимость от подсистемы хранения: общий диск не требуется;
- Независимость от типов ресурсов: все что может быть заскриптовано, может быть кластеризовано;
- Поддержка STONITH (Shoot-The-Other-Node-In-The-Head) — лекарства от Split-Brain ;);
- Поддержка кластеров любого размера;
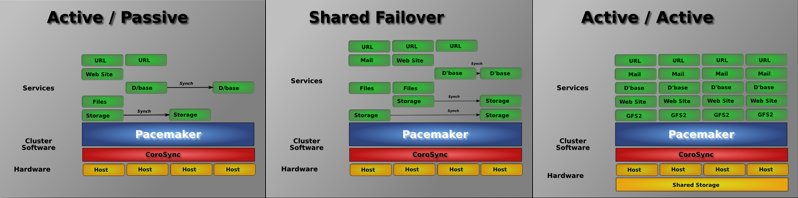
- Поддержка и кворумных и ресурсозависимых кластеров;
- Поддержка практически любой избыточной конфигурации;
- Автоматическая репликация конфига на все узлы кластера;
- Возможность задания порядка запуска ресурсов, а также их совместимости на одном узле;
- Поддержка расширенных типов ресурсов: клонов (запущен на множестве узлов) и с дополнительными состояниями (master/slave и т.п.);
- Единый кластерный шелл (crm), унифицированный, скриптующийся.
Проект кроме собственно своих демонов, поддерживающих конфиг кластера и указанный выше шелл, также использует сторонние, тот же heartbeat и corosync. Я лично (собственно авторы тоже) рекомендую использовать corosync. В общем-то он поддерживает скрипты от heartbeat, поэтому проблем возникнуть не должно.
Установка
На RHEL/CentOS нет ничего проще.
cd /etc/yum.repos.d
wget http://www.clusterlabs.org/rpm/epel-5/clusterlabs.repo
yum install pacemaker
Затем редаектируем /etc/corosync/corosync.conf (там есть corosync.conf.sample) и стартуем.
/etc/init.d/corosync start
Да, крайне необходимо иметь правильно настроенный DNS, чтобы резолвились в обе стороны все узлы.
Как добавить узлы? Нет ничего проще, ставим Pacemaker, копируем /etc/corosync/corosync.conf и /etc/ais/authkeys (если настраивали) и запускаем. Узел будет автоматически включен в кластер. Конфиг кластера будет также автоматически скопирован.
Если узел вышел из строя и вы заменили железо? Тоже самое, даем новому узлу то же имя, копируем конфиги и стартуем. Лепота.
# crm_mon
============
Last updated: Thu Aug 27 16:54:55 2009
Stack: openais
Current DC: pcmk-1 - partition with quorum
Version: 1.0.5-462f1569a43740667daf7b0f6b521742e9eb8fa7
2 Nodes configured, 2 expected votes
0 Resources configured.
============
Online: [ pcmk-1 pcmk-2 ]
Конфигурация
Конфигурация кластера представляет собой простой XML. Однако вручную его править НЕЛЬЗЯ. Все изменения конфига подвергаются автоматическому версионированнию, узлы получают не весь конфиг разом, а только дельты от того, о чем они знают. Т.е. если узел вышел из строя, а в это время вы поменяли конфиг, то когда он вернется, он получит все изменения, которые вы сделали.
Для работы с конфигом можно использовать либо cibadmin, либо собственно сам шелл crm. Посмотреть конфиг можно например так:
# crm configure show
node pcmk-1
node pcmk-2
property $id="cib-bootstrap-options" \
dc-version="1.0.5-462f1569a43740667daf7b0f6b521742e9eb8fa7" \
cluster-infrastructure="openais" \
expected-quorum-votes="2"
Кроме собственно опций кластера, конфигурированию подлежат также:
- Узлы (Nodes);
- Ресурсы (Resources);
- Связи (Constraints).
Узлы
Как добавлять узлы мы уже разобрались. Удаляются узлы не многим сложнее: останавливаем corosync на узле, а затем удаляем узел из конфига.
Не забывайте, что кворум достигается когда в строю более половины узлов. Поэтому если у вас кластер всего из 2-х, то эту опцию стоит отключить, иначе при падении любого из них, кластер будет считать себя развалившимся.
Ресурсы
Что есть ресурс с точки зрения corosync? Все, что может быть заскриптовано! Обычно скрипты пишутся на bash, но ничто не мешает вам писать их на Perl, Python или даже на C. Все, что требуется от скрипта, это выполнять 3 действия: start, stop и monitor. В общем-то скрипты должны соответствовать LSB (Linux Standard Base) или OCF (Open Cluster Framework) — последнее несколько расширяет LSB, требуя также передачи параметров через переменные окружения с особым названием.
# crm ra classes
heartbeat
lsb
ocf / heartbeat pacemaker
stonith
# crm ra list ocf heartbeat
AoEtarget AudibleAlarm ClusterMon Delay
Dummy EvmsSCC Evmsd Filesystem
ICP IPaddr IPaddr2 IPsrcaddr
LVM LinuxSCSI MailTo ManageRAID
ManageVE Pure-FTPd Raid1 Route
SAPDatabase SAPInstance SendArp ServeRAID
SphinxSearchDaemon Squid Stateful SysInfo
VIPArip VirtualDomain WAS WAS6
WinPopup Xen Xinetd anything
apache db2 drbd eDir88
iSCSILogicalUnit iSCSITarget ids iscsi
ldirectord mysql mysql-proxy nfsserver
oracle oralsnr pgsql pingd
portblock rsyncd scsi2reservation sfex
tomcat vmware
Как мы видим, довольно много уже готовых агентов (Resource Agents). Впрочем, написать самому новый тоже вряд ли составит большого труда.
При создании ресурса нам потребуется задать его класс, тип, провайдера и собственно имя с дополнительными параметрами. В списке выше: ocf — класс, heartbeat — провайдер, IPaddr — тип агента.
crm configure primitive ClusterIP ocf:heartbeat:IPaddr2 \
params ip=192.168.9.101 cidr_netmask=32 \
op monitor interval=30s
Ресурсы поддерживают множество дополнительных параметров, вроде привязки к узлу (resource-stickiness), роли по умолчанию (started, stoped, master) и т.д. Есть возможности по созданию групп ресурсов, клонов (работающих на нескольких узлах) и т.п.
Связи
Начнем с того, что любая связь имеет свой вес — целое число в пределах от -INFINITY до +INFINITY. При этом если вес связи ± INFINITY, то она считается жесткой, в противном случае — мягкой, т.е. если веса других связей окажутся выше, она может быть проигнорирована.
Связи определяют привязку ресурсов к узлу (location), порядок запуска ресурсов (ordering) и совместное их проживание на узле (colocation).
# crm configure primitive WebSite ocf:heartbeat:apache \
params configfile=/etc/httpd/conf/httpd.conf \
op monitor interval=1min
# crm configure colocation website-with-ip INFINITY: WebSite ClusterIP
# crm configure order apache-after-ip mandatory: ClusterIP WebSite
# crm configure location prefer-pcmk-1 WebSite rule 50: pcmk-1
Здесь мы создали еще один ресурс — WebSite, задали совместное проживание его с ClusterIP (кстати, -INFINITY означало бы, что ресурсы НЕ должны находиться на одном узле), определили порядок запуска: сначала ClusterIP, потом WebSite, а потом задали, что WebSite очень желательно находиться на узле pcmk-1, с весом 50. При задании порядка также можно указать, можно ли стартовать ресурсы параллельно или делать это последовательно.
В общем таким образом можно строить довольно сложные цепочки зависимостей ресурсов. Все становиться еще интереснее, если учесть, что можно задавать более сложные правила (rules), срабатывающие, например, только в определенное время суток или в зависимости от состояния компонентов кластера.
Кстати, для облегчения понимая авторы наделили Pacemaker возможностью строить графики в формате Graphviz — см. утилиту ptest.
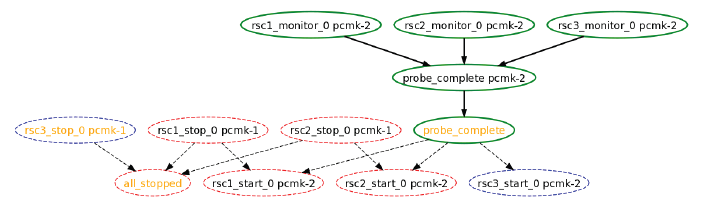
Заключение
Pacemaker прост и удобен, но при этом очень мощен и богат возможностями. После IBM HA MS вообще не могу нарадоваться на этот проект :). Чтобы не забивать пост излишними подробностями, да и для дальнейшего изучения вам понадобиться следующая литература:
- Cluster from Scratch — развернутый пример установки и настройки с краткими пояснениями;
- Pacemaker Explained — полное, исчерпывающее описание всех настроек с примерами;
- CRM command line interface — описание шелла crm;
- clusterlabs.org — собственно сайт проекта.
Спасибо за внимание.
