iptables — интерфейс к файрволу Linux (netfilter). При большом количестве правил iptables нагрузка может быть достаточно высокой и создавать проблемы. В этой заметке я постараюсь описать, что влияет на производительность iptables и как ее повысить.
Для начала: из-за чего вообще возникает нагрузка при большом количестве правил? Из-за того, что каждому сетевому пакету, обрабатываемому ядром, приходится проходить сравнение по всему списку правил каждой цепочки. Приведу схему, которая отражает цепочки netfilter и порядок прохождения по ним пакетов:
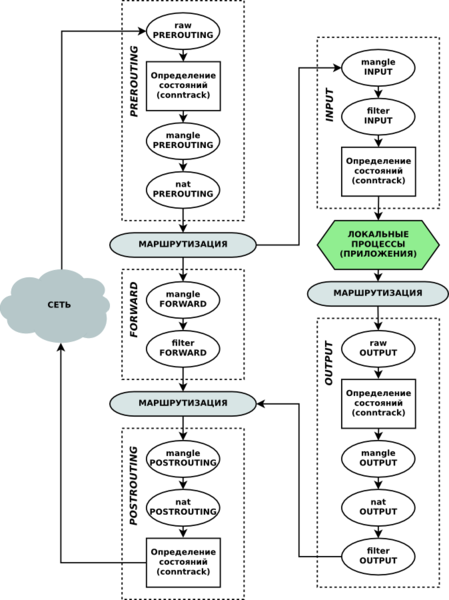
На схеме видно через какие цепочки пройдет тот или иной пакет и можно оценить нагрузку. Возьмем одно простейшее правило:
Это правило указывает файрволлу отбрасывать все пакеты с IP-адреса 10.1.1.1 на порт 25 локальной машины. Таблицу (-t) я не указываю, поэтому будет использоваться дефолтная (-t filter), что нам и нужно. Понятно, что действие DROP выполняется далеко не всегда. Однако, сравнение IP-адреса источника будет проходить любой входящий на локальную машину пакет. А если таких правил тысяча?
Теперь подумаем, как можно ускорить работу файрволла. Первый ответ очевиден — сокращать количество правил. Но вряд ли удастся серьезно оптимизировать записи, особенно если они изначально составлялись грамотно. Где-то вместо правил на несколько IP-адресов можно написать одно правило на подсеть. Где-то вместо правил на несколько портов можно использовать
А есть еще второй вариант — использование ветвлений правил. Суть его в том, что однотипные правила группируются в отдельную цепочку, а в основной цепочке остается одно правило, которое перенаправляет пакет в отдельную цепочку в зависимости от какого-то общего признака пакетов. Приведу пример. Имеются три правила:
Что объединяет эти правила? Одинаковый протокол — icmp. Вот по этому признаку и стоит сгруппировать правила. Вообще в данном случае эффективнее использовать ipset, но об этом дальше. Для группировки необходимо создать новую цепочку, а затем создать правило, которое будет отправлять пакеты в эту цепочку.
Создать цепочку PROT_ICMP:
Определить правила в этой цепочке:
Как видите, протокол (-p) в этой цепочке мы уже не проверяем, т.к. отправлять в эту цепочку будем только ICMP пакеты. И наконец отправить все пакеты ICMP в эту цепочку:
Теперь входящий пакет, если он не ICMP, будет проходить лишь через одно правило вместо трех.
А теперь предположим следующую ситуацию:
Несколько однотипных правил, но сгруппировать их или сделать дополнительную цепочку не представляется возможным. В таких случаях, когда необходимо делать проверку по большому количеству IP-адресов и/или портов, на помощь приходит ipset. ipset представляет из себя модуль ядра ip_set, ряд вспомогательных библиотек и утилиту ipset для задания параметров. Наверняка есть в репозиториях вашего дистрибутива, так что с установкой не должно быть проблем.
Используется следующим образом:
* Создается список:
dropips — название списка, iphash — тип списка. Типы списков можно посмотреть в man ipset, они есть на любой вкус — для работы с ip-адресами, подсетями, портами, mac-адресами. iphash служит для хранения IP-адресов, использование хэширования предотвращает добавление в список дублирующих IP-адресов.
* Добавляется IP-адрес в список:
* Создается правило для использования списка:
В статье я не стал описывать тюнинг сетевых параметров ядра, а сделал упор на рациональную организацию правил файрволла. Информации о тюнинге очень много можно найти в сети, это различные net.*mem*, в случае большого количества соединений и использования conntrack — параметры net.netfilter.nf_conntrack_max, net.netfilter.nf_conntrack*timeout и т.д.
Спасибо за внимание.
Спасибо ivlis за указание на опечатки.
Основная причина нагрузки
Для начала: из-за чего вообще возникает нагрузка при большом количестве правил? Из-за того, что каждому сетевому пакету, обрабатываемому ядром, приходится проходить сравнение по всему списку правил каждой цепочки. Приведу схему, которая отражает цепочки netfilter и порядок прохождения по ним пакетов:
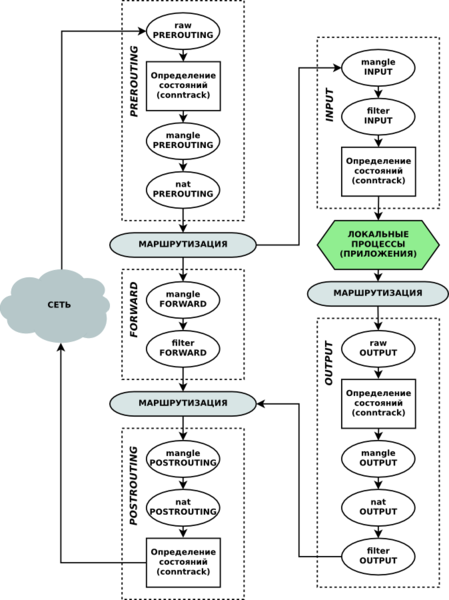
На схеме видно через какие цепочки пройдет тот или иной пакет и можно оценить нагрузку. Возьмем одно простейшее правило:
-A INPUT -s 10.1.1.1/32 -p tcp --dport 25 -j DROPЭто правило указывает файрволлу отбрасывать все пакеты с IP-адреса 10.1.1.1 на порт 25 локальной машины. Таблицу (-t) я не указываю, поэтому будет использоваться дефолтная (-t filter), что нам и нужно. Понятно, что действие DROP выполняется далеко не всегда. Однако, сравнение IP-адреса источника будет проходить любой входящий на локальную машину пакет. А если таких правил тысяча?
Что делать?
Теперь подумаем, как можно ускорить работу файрволла. Первый ответ очевиден — сокращать количество правил. Но вряд ли удастся серьезно оптимизировать записи, особенно если они изначально составлялись грамотно. Где-то вместо правил на несколько IP-адресов можно написать одно правило на подсеть. Где-то вместо правил на несколько портов можно использовать
-m multiport и --dports/--sports a,b,c (a,b,c — номера портов). И так далее.Ветвление правил, дополнительные цепочки
А есть еще второй вариант — использование ветвлений правил. Суть его в том, что однотипные правила группируются в отдельную цепочку, а в основной цепочке остается одно правило, которое перенаправляет пакет в отдельную цепочку в зависимости от какого-то общего признака пакетов. Приведу пример. Имеются три правила:
-A INPUT -s 10.1.1.1/32 -p icmp -j ACCEPT
-A INPUT -s 10.1.1.2/32 -p icmp -j ACCEPT
-A INPUT -s 10.1.1.3/32 -p icmp -j ACCEPTЧто объединяет эти правила? Одинаковый протокол — icmp. Вот по этому признаку и стоит сгруппировать правила. Вообще в данном случае эффективнее использовать ipset, но об этом дальше. Для группировки необходимо создать новую цепочку, а затем создать правило, которое будет отправлять пакеты в эту цепочку.
Создать цепочку PROT_ICMP:
iptables -N PROT_ICMPОпределить правила в этой цепочке:
-A PROT_ICMP -s 10.1.1.1/32 -j ACCEPT
-A PROT_ICMP -s 10.1.1.2/32 -j ACCEPT
-A PROT_ICMP -s 10.1.1.3/32 -j ACCEPTКак видите, протокол (-p) в этой цепочке мы уже не проверяем, т.к. отправлять в эту цепочку будем только ICMP пакеты. И наконец отправить все пакеты ICMP в эту цепочку:
-A INPUT -p icmp -g PROT_ICMPТеперь входящий пакет, если он не ICMP, будет проходить лишь через одно правило вместо трех.
ipset
А теперь предположим следующую ситуацию:
-A INPUT -s 10.1.1.1/32 -j DROP
-A INPUT -s 10.1.1.2/32 -j DROP
-A INPUT -s 10.1.1.3/32 -j DROPНесколько однотипных правил, но сгруппировать их или сделать дополнительную цепочку не представляется возможным. В таких случаях, когда необходимо делать проверку по большому количеству IP-адресов и/или портов, на помощь приходит ipset. ipset представляет из себя модуль ядра ip_set, ряд вспомогательных библиотек и утилиту ipset для задания параметров. Наверняка есть в репозиториях вашего дистрибутива, так что с установкой не должно быть проблем.
Используется следующим образом:
* Создается список:
ipset -N dropips iphashdropips — название списка, iphash — тип списка. Типы списков можно посмотреть в man ipset, они есть на любой вкус — для работы с ip-адресами, подсетями, портами, mac-адресами. iphash служит для хранения IP-адресов, использование хэширования предотвращает добавление в список дублирующих IP-адресов.
* Добавляется IP-адрес в список:
ipset -A dropips 10.1.1.1* Создается правило для использования списка:
iptables -A INPUT -m set --set dropips src -j DROP-m set указывает на использование модуля ipset, --set dropips указывает список IP-адресов, src указывает на то, что сверять нужно только IP-источника. Таким образом, будут отбрасываться все пакеты с IP-адресов, указанных в списке dropips.В статье я не стал описывать тюнинг сетевых параметров ядра, а сделал упор на рациональную организацию правил файрволла. Информации о тюнинге очень много можно найти в сети, это различные net.*mem*, в случае большого количества соединений и использования conntrack — параметры net.netfilter.nf_conntrack_max, net.netfilter.nf_conntrack*timeout и т.д.
Спасибо за внимание.
Спасибо ivlis за указание на опечатки.
