Несмотря на то, что большинство из изучающих Node.js в какой-то мере знают JavaScript и имеют опыт использования его в контексте браузеров, при обсуждении практических моментов многие встречаются с трудностями в понимании работы стандартной библиотеки и механизмов обеспечения асинхронного выполнения кода, содержащего множество вложенных коллбеков. Также часто возникает недопонимание, Я постараюсь вкратце описать порядок работы event loop в Node.js и рассказать, на какие моменты стоит обратить внимание при написании качественного асинхронного кода. Думаю, что статья будет полезна и тем, кто занимается написанием производительных фреймворков для браузеров.
Как уже много раз было написано, в основе Node.js лежит цикл событий, реализуемый библиотекой libev. На каждом витке цикла происходит следующее: в первую очередь идёт выполнение функций, установленных на предыдущем витке цикла с помощью process.nextTick(). Далее идёт обработка событий libev, в частности событий таймеров. В последнюю очередь идёт опрос libeio для завершения операций ввода/вывода и выполнения установленных для них коллбеков. В случае, если при прохождении цикла оказалось, что ни одна функция не установлена с помощью process.nextTick(), нет ни одного таймера и очереди запросов в libev и libeio пусты, то node завершает работу. Если вы хотите подробнее узнать порядок работы event loop, собетую пролистать презентацию www.slideshare.net/jacekbecela/introduction-to-nodejs.
Таким образом, если сервер содержит мало логики и занимается в основном малозатратной по времени обработкой приходящих данных, то цикл выполняется очень часто. Однако, если обработка данных происходит долго, то целесообразно разделить этот процесс на отдельные части, между которыми возвращать управление в цикл событий для возможности запуска обслуживания нового соединения или обработки асинхронно читаемых с диска данных. Рассмотрим пример HTTP-сервера: при обращению к нему он читает из текущей папки файл с именем, соответствующим строке запроса и возвращает определённую хеш-сумму от его содержимого.
Пример сервера содержит синхронное чтение файла с диска, которое блокирует выполнение до завершения чтение, и последующее вычисление значение двух функций, которые могут долго выполняться при большом размере файла. При этом если чтение занимает Tread секунд, а вычисление суммы Tcalc секунд, то такой блокирующий сервер сможет обслужить меньше чем 1/(Tread + Tcalc) запросов в секунду. Как можно улучшить наш сервер, позволив ему обрабатывать большее количество соединений? В первую очередь, использовать неблокирующее чтение файла.
>За счёт использование асинхронного чтения мы можем добиться ускорение обработки каждого запроса за счёт того, что во время вычислений в фоном режиме будет происходить чтение файла для другого запроса. <strikeТаким образом, время обработки будет равняться min(Tread, Tcalc), а не (Tread + Tcalc), как в случае синхронного сервера. Таким образом, при поступлении двух запросов в синхронном случае время их обслуживания будет равняться Tread1 + Tcalc1 + Tread2 + Tcalc2, а при асинхронном чтении оно может достигать Tread1 + Tread2 + min(Tcalc1, Tcalc2).
Это уже хорошо. Но что делать, если время обработки файла сильно больше времени чтения файла и кроме того сильно флуктуирует? В этом случае за время вычисления суммы для одного файла могут успеть прочитаться несколько других файлов меньшего размера, которые впоследствии быстро обработаются. Кроме того, в приведённом пример клиенты получат результат практически в том же порядке, в котором были посланы запросы к серверу. Однако логично желание вернуть результат раньше тем клиентам, которые запрашивают меньшие файлы или файлы, требующие меньше времени на обработку. Для этого при использовании длинной цепи вложенных функций обработки необходимо каким-то образом после вычисления func1() вернуть управление в основной поток, а на следующем витке цикла вычислить func2() и вернуть результат клиенту. За счёт этого в промежутке между вычислением func1() и func2() для одного запроса может произойти принятие нового соединения и создания задания на чтение другого файла, или обработка уже считанного файла меньшего размера.
Как в таком случае поступают новички в Node.js (на самом деле их стоит называть новичками в JavaScript, потому что это касается использования языка в любой из распространённых JavaScript VM)? Так как асинхронные функции ввода/вывода из стандартной библиотеки возвращают выполнение в основной поток сразу же после вызова, то многие считают, что достаточно написать функцию, принимающую коллбек, и она будет обеспечивать в месте своего вызова разрыв в основном потоке выполнения.
Что же произойдёт на самом деле? Никакой магии, конечно же, нет. Разница будет заключаться только в том, что чисто императивный код вычисления сумм мы заменили кодом с двумя вложенными функциями-коллбеками, которые будут последовательно вызывать друг друга и немного увеличат время вычисления сумм за счёт лишних вызовов функций, что в конечном счёте только ухудшит производительность нашего сервера.
Для того, чтобы передать управление в основной поток выполнения и при этом поставить на будущее задачу дальнейшей обработки суммы после вычисления func1(), можно использовать старое проверенное средство, доступное в JavaScript: setTimeout(fn, 0). Именно эту функцию стоило бы использовать, если бы мы программировали для браузеров. Но, как я уже писал выше, в Node.js есть функция process.nextTick(fn), которая эффективнее и переданная в неё функция будет выполнена гарантированно раньше, чем функции, установленные с помощью таймеров или являющиеся обработчиками событий от сокетов или файловой системы. Таким образом, код сервера readFile-and-sync-chain.js можно переписать следующим образом:
Этот результат и является конечным вариантом сервера, который выполняет все операции асинхронно и содержит минимальное количество участков кода, блокирующих цикл событий.
Всё, о чём говорится выше, по большей части рассуждения о правильной архитектуре. На деле производительность того или иного варианта может зависеть от того, какой размер читаемого файла и время его обработки, от нелинейности зависимости вермени обработки от размера файла и от того, наскольок разнообразные запросы обрабатывает сервер. Тем не менее, тесты показали, что в любом случае использования более правильных с точки зрения архитектуры решений даже в худшем случае не замедляет сервер больше, чем на 10%.
Для сравнения использовались файлы размером от 128 байт до 1 Мб и сервер нагружался с помощью Apache Bench:
Результаты приведены на графиках:
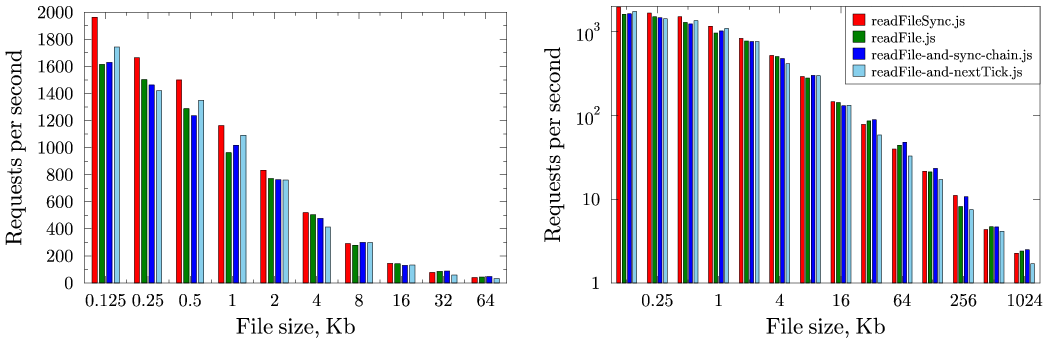
Как видно, использование асинхронного чтение действитьно улучшает производительность сервера при больших размерах файла. Это связано с тем, что при чтении маленьких файлов накладные расходы на создания различных структур для асинхронного чтения превышают время чтения файлов, тем более что они читаются из кеша ФС. Как и ожидалось, использование обычных вложенных функций в не улучшает производительность. А вот использование асинхронных коллбеков при поэтапной обработке файла принесла свои результаты, которые хорошо видны для небольших размеров файлов.
Однако следует отметить, что результаты теста сильно зависят от размера запрашиваемого файла как в лучшую, так и в худшую сторону, а также от разнообразия поступающих серверу запросов. Надеюсь, у меня найдётся время на расширенное тестирование с несколькими файлами и различным количеством запросов для них. Также я намерено не рассматриваю проблемы, связанные с неполной реализацией асинхронного ввода/вывода в некоторых ОС и ограничением на количество потоков, используемых libeio для эмуляции асинхронных операций для таких систем.
P.S. Спасибо nodejs-новичкам с forum.nodejs.ru за поднятие этого вопроса.
Лирическое отступление: Цикл событий, лежащий в основе Node.js
Как уже много раз было написано, в основе Node.js лежит цикл событий, реализуемый библиотекой libev. На каждом витке цикла происходит следующее: в первую очередь идёт выполнение функций, установленных на предыдущем витке цикла с помощью process.nextTick(). Далее идёт обработка событий libev, в частности событий таймеров. В последнюю очередь идёт опрос libeio для завершения операций ввода/вывода и выполнения установленных для них коллбеков. В случае, если при прохождении цикла оказалось, что ни одна функция не установлена с помощью process.nextTick(), нет ни одного таймера и очереди запросов в libev и libeio пусты, то node завершает работу. Если вы хотите подробнее узнать порядок работы event loop, собетую пролистать презентацию www.slideshare.net/jacekbecela/introduction-to-nodejs.
Таким образом, если сервер содержит мало логики и занимается в основном малозатратной по времени обработкой приходящих данных, то цикл выполняется очень часто. Однако, если обработка данных происходит долго, то целесообразно разделить этот процесс на отдельные части, между которыми возвращать управление в цикл событий для возможности запуска обслуживания нового соединения или обработки асинхронно читаемых с диска данных. Рассмотрим пример HTTP-сервера: при обращению к нему он читает из текущей папки файл с именем, соответствующим строке запроса и возвращает определённую хеш-сумму от его содержимого.
Синхронная версия тестового сервера
// readFileSync.js
var
http = require('http'),
fs = require('fs');
function func1(str) {
var res = '';
for (var i = 0, l = str.length; i < l; i++) {
res += str.charCodeAt(i);
}
return res;
}
function func2(str) {
var res = 0;
for (var i = 0, l = str.length; i < l; i++) {
res += Math.sin(str.charCodeAt(i));
}
return '' + res;
}
http.createServer(function (req, res) {
// Very simple and dangerous check
var filename = req.url.replace(/\?.*/, '').replace(/(\.\.|\/)/, '');
// Read file from disk
try {
var filecontent = fs.readFileSync(filename, 'utf8');
} catch (e) {
res.writeHead(404, {'Content-Type': 'text/plain'});
res.end('File ' + filename + ' doesn\'t exist');
return;
}
// Calculate checksum
var hash = func2(func1(filecontent));
// Write response
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end(hash);
}).listen(8124, "127.0.0.1");Пример сервера содержит синхронное чтение файла с диска, которое блокирует выполнение до завершения чтение, и последующее вычисление значение двух функций, которые могут долго выполняться при большом размере файла. При этом если чтение занимает Tread секунд, а вычисление суммы Tcalc секунд, то такой блокирующий сервер сможет обслужить меньше чем 1/(Tread + Tcalc) запросов в секунду. Как можно улучшить наш сервер, позволив ему обрабатывать большее количество соединений? В первую очередь, использовать неблокирующее чтение файла.
Асинхронное чтение файла и попытка использовать коллбеки
// readFile.js
var
http = require('http'),
fs = require('fs');
function func1(str) {
var res = '';
for (var i = 0, l = str.length; i < l; i++) {
res += str.charCodeAt(i);
}
return res;
}
function func2(str) {
var res = 0;
for (var i = 0, l = str.length; i < l; i++) {
res += Math.sin(str.charCodeAt(i));
}
return '' + res;
}
http.createServer(function (req, res) {
// Very simple and dangerous check
var filename = req.url.replace(/\?.*/, '').replace(/(\.\.|\/)/, '');
// Read file from disk
fs.readFile(filename, 'utf8', function (err, filecontent) {
if (err) {
res.writeHead(404, {'Content-Type': 'text/plain'});
res.end('File ' + filename + ' doesn\'t exist');
return;
}
// Calculate checksum
var hash = func2(func1(filecontent));
// Write response
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end(hash);
});
}).listen(8124, "127.0.0.1");>За счёт использование асинхронного чтения мы можем добиться ускорение обработки каждого запроса за счёт того, что во время вычислений в фоном режиме будет происходить чтение файла для другого запроса. <strikeТаким образом, время обработки будет равняться min(Tread, Tcalc), а не (Tread + Tcalc), как в случае синхронного сервера. Таким образом, при поступлении двух запросов в синхронном случае время их обслуживания будет равняться Tread1 + Tcalc1 + Tread2 + Tcalc2, а при асинхронном чтении оно может достигать Tread1 + Tread2 + min(Tcalc1, Tcalc2).
Это уже хорошо. Но что делать, если время обработки файла сильно больше времени чтения файла и кроме того сильно флуктуирует? В этом случае за время вычисления суммы для одного файла могут успеть прочитаться несколько других файлов меньшего размера, которые впоследствии быстро обработаются. Кроме того, в приведённом пример клиенты получат результат практически в том же порядке, в котором были посланы запросы к серверу. Однако логично желание вернуть результат раньше тем клиентам, которые запрашивают меньшие файлы или файлы, требующие меньше времени на обработку. Для этого при использовании длинной цепи вложенных функций обработки необходимо каким-то образом после вычисления func1() вернуть управление в основной поток, а на следующем витке цикла вычислить func2() и вернуть результат клиенту. За счёт этого в промежутке между вычислением func1() и func2() для одного запроса может произойти принятие нового соединения и создания задания на чтение другого файла, или обработка уже считанного файла меньшего размера.
Как в таком случае поступают новички в Node.js (на самом деле их стоит называть новичками в JavaScript, потому что это касается использования языка в любой из распространённых JavaScript VM)? Так как асинхронные функции ввода/вывода из стандартной библиотеки возвращают выполнение в основной поток сразу же после вызова, то многие считают, что достаточно написать функцию, принимающую коллбек, и она будет обеспечивать в месте своего вызова разрыв в основном потоке выполнения.
// readFile-and-sync-chain.js
var
http = require('http'),
fs = require('fs');
function func1(str) {
var res = '';
for (var i = 0, l = str.length; i < l; i++) {
res += str.charCodeAt(i);
}
return res;
}
function func2(str) {
var res = 0;
for (var i = 0, l = str.length; i < l; i++) {
res += Math.sin(str.charCodeAt(i));
}
return '' + res;
}
function func1_cb(str, cb) {
var res = func1(str);
cb(res);
}
function func2_cb(str, cb) {
var res = func2(str);
cb(res);
}
http.createServer(function (req, res) {
// Very simple and dangerous check
var filename = req.url.replace(/\?.*/, '').replace(/(\.\.|\/)/, '');
// Read file from disk
fs.readFile(filename, 'utf8', function (err, filecontent) {
if (err) {
res.writeHead(404, {'Content-Type': 'text/plain'});
res.end('File ' + filename + ' doesn\'t exist');
return;
}
// Calculate checksum
func1_cb(filecontent, function (str) {
func2_cb(str, function (hash) {
// Write response
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end(hash);
});
});
});
}).listen(8124, "127.0.0.1");Что же произойдёт на самом деле? Никакой магии, конечно же, нет. Разница будет заключаться только в том, что чисто императивный код вычисления сумм мы заменили кодом с двумя вложенными функциями-коллбеками, которые будут последовательно вызывать друг друга и немного увеличат время вычисления сумм за счёт лишних вызовов функций, что в конечном счёте только ухудшит производительность нашего сервера.
Асинхронное чтение файла и правильная асинхронная обработка
Для того, чтобы передать управление в основной поток выполнения и при этом поставить на будущее задачу дальнейшей обработки суммы после вычисления func1(), можно использовать старое проверенное средство, доступное в JavaScript: setTimeout(fn, 0). Именно эту функцию стоило бы использовать, если бы мы программировали для браузеров. Но, как я уже писал выше, в Node.js есть функция process.nextTick(fn), которая эффективнее и переданная в неё функция будет выполнена гарантированно раньше, чем функции, установленные с помощью таймеров или являющиеся обработчиками событий от сокетов или файловой системы. Таким образом, код сервера readFile-and-sync-chain.js можно переписать следующим образом:
// readFile-and-nextTick.js
var
http = require('http'),
fs = require('fs');
function func1(str) {
var res = '';
for (var i = 0, l = str.length; i < l; i++) {
res += str.charCodeAt(i);
}
return res;
}
function func2(str) {
var res = 0;
for (var i = 0, l = str.length; i < l; i++) {
res += Math.sin(str.charCodeAt(i));
}
return '' + res;
}
function func1_cb(str, cb) {
var res = func1(str);
process.nextTick(function () {
cb(res);
});
}
function func2_cb(str, cb) {
var res = func2(str);
process.nextTick(function () {
cb(res);
});
}
http.createServer(function (req, res) {
// Very simple and dangerous check
var filename = req.url.replace(/\?.*/, '').replace(/(\.\.|\/)/, '');
// Read file from disk
fs.readFile(filename, 'utf8', function (err, filecontent) {
if (err) {
res.writeHead(404, {'Content-Type': 'text/plain'});
res.end('File ' + filename + ' doesn\'t exist');
return;
}
// Calculate checksum
func1_cb(filecontent, function (str) {
func2_cb(str, function (hash) {
// Write response
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end(hash);
});
});
});
}).listen(8124, "127.0.0.1");Этот результат и является конечным вариантом сервера, который выполняет все операции асинхронно и содержит минимальное количество участков кода, блокирующих цикл событий.
Сравнение производительности рассмотренных вариантов
Всё, о чём говорится выше, по большей части рассуждения о правильной архитектуре. На деле производительность того или иного варианта может зависеть от того, какой размер читаемого файла и время его обработки, от нелинейности зависимости вермени обработки от размера файла и от того, наскольок разнообразные запросы обрабатывает сервер. Тем не менее, тесты показали, что в любом случае использования более правильных с точки зрения архитектуры решений даже в худшем случае не замедляет сервер больше, чем на 10%.
Для сравнения использовались файлы размером от 128 байт до 1 Мб и сервер нагружался с помощью Apache Bench:
ab2 -n 1000 -c 100 http://127.0.0.1:8124/filenameРезультаты приведены на графиках:

Как видно, использование асинхронного чтение действитьно улучшает производительность сервера при больших размерах файла. Это связано с тем, что при чтении маленьких файлов накладные расходы на создания различных структур для асинхронного чтения превышают время чтения файлов, тем более что они читаются из кеша ФС. Как и ожидалось, использование обычных вложенных функций в не улучшает производительность. А вот использование асинхронных коллбеков при поэтапной обработке файла принесла свои результаты, которые хорошо видны для небольших размеров файлов.
Однако следует отметить, что результаты теста сильно зависят от размера запрашиваемого файла как в лучшую, так и в худшую сторону, а также от разнообразия поступающих серверу запросов. Надеюсь, у меня найдётся время на расширенное тестирование с несколькими файлами и различным количеством запросов для них. Также я намерено не рассматриваю проблемы, связанные с неполной реализацией асинхронного ввода/вывода в некоторых ОС и ограничением на количество потоков, используемых libeio для эмуляции асинхронных операций для таких систем.
P.S. Спасибо nodejs-новичкам с forum.nodejs.ru за поднятие этого вопроса.