
Этот топик — ответ на топик "Пора завязывать использовать символы табуляции в коде".
Я хотел было ответить к комментариях, но в силу объема и желания независимости от исходного топика решил создать новый топик.
Итак, под катом — почему табы лучше пробелов, самые значительные заблуждения касательно табов и как ими правильно пользоваться.
Начнём с того, что большинство людей (по крайней мере на Хабре) предпочитают табы.
По ссылке есть очень классный комментарий от GreyCat:
На самом деле странно то, что многие до сих пор не отличают indentation и alignment. Ну, вот это — indentation:
for (int i = 0; i < 10; i++) { if (a[i] == 0) do_something(i); }
А вот это — alignment:
int some_variable = 0; int v1 = 0;
Первое можно делать и табами, и пробелами, но когда делаешь табами — каждый может подстроить ширину indent'а на свой вкус и ничего никуда не едет. А второе — строго пробелами.
В IDE есть опция Smart Tabs для этого:
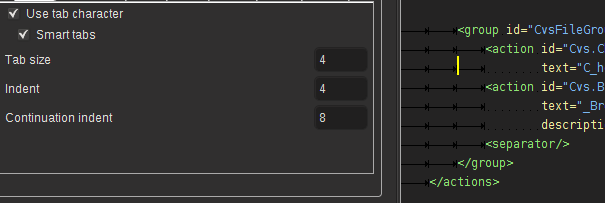
Если правильно использовать табы (а именно — только для indentation) — можно без проблем менять размер табов не нарушая стиль программирования.
2 пробела на таб:

5 пробелов на таб:

9 пробелов на таб:

Так каких проблем мы лишаемся?
1. Каждый программист может настроить длину табуляции под свой вкус. Всегда работает на практике. Когда код с большой вложенностью — можно поставить ширину табуляции в два пробела, иначе — в четыре.
2. Легче работать с посторонними библиотеками. Какие-то библиотеки поддерживают стиль с шириной таба в два пробела, какие-то с шириной в четыре пробела. Только использование табов не накладывает ограничение на стиль.
Процитирую пару мыслей из предыдущего топика:
Тяжело работать с проектами, где используются библиотеки, содержащие в тесте табуляции. Предположим, в одной библиотеке табуляция равна 3 символам, в другой 4 символам. А вы в проекте используете 2 символа. В результате какая-то часть кода у вас будет отображаться в редакторе со сбитым форматированием.
На самом деле в проектах, которые используют табуляцию таких проблем нету — так как табуляция безразмерна, а вот поддерживать одновременно пару библиотек с разным размером пробело-табуляции становится проблематичным, т.к. уже нельзя пользоваться tab (чтобы IDE заменяла табы на пробелы). Конечно, есть шанс решить такую проблему разными проектами с разными настройками, но это тот еще костыль, да и башку все-равно сносит от разных размеров вложенности.
Легко пустить козла в огород. Скажем у вас табуляция равна 4 пробелам. Кто-то что-то чуть-чуть поправил, используя другой размер табуляции или явно вставив пробелы. У него все смотрелось нормально, а у вас строчка кода куда-то уедет.
Аналогично, табуляция — безразмерная. Такая проблема есть только в проектах, которые используют пробелы. Там где используются табы — они могут быть хоть 2, хоть 10 символов шириной.
Надо постоянно настраивать различные редакторы под нужный вам размер табуляции. Даже если вам нужно просто посмотреть код не правя. Иначе все разъезжается. Особенно это не удобно, когда приходится что-то делать со своим кодом на сторонней машине.
Допустим, я открываю Kate, чтобы по-быстряку поправить код в каком-то файле. Оппа, размер табуляции два пробела. Надо лезть в конфиг. А в соседнем файле из другой либы — четыре пробела. Придётся пользоваться пробелом вместо таба для отступов, ужас. С табами такой проблемы нету.
Лишние сложности тем, кто работает одновременно с проектами, где по стандартам кодирования требуются разные отступы. Если стандарты требуют использование табуляции, то это ещё тот вечно ноющий зуб. В случае пробелов опять-таки все намного проще.
Как выше разобрали, такая проблема есть именно с проблемами, а не с табами.
А еще дополнительно у пробелов есть такие недостатки, как невозможность быстрого перемещения стрелочками клавиатуры (щёлкает каждый пробел, а не через блок), возможность допустить ошибку (поставить в одном месте 3 пробела вместо 4, чем порушить дальнейшую структуру), увеличение размера файла и куча всего ещё.
Вывод
У пробелов нету ни одного существенного преимущество по сравнению с табами, при этом мы не сковываем программиста в рамки и не заставляем его мучаться с слишком маленькими (или слишком большими) для него табами.
Главное
Не так важно, что именно вы используете. Важно, чтобы вы следили за порядком своего кода и всегда придерживались одного и того же стиля. Включите отображение табов/пробелов, иногда меняйте размер табуляции на другой и пробегайте глазами код, чтобы удостоверится, что у вас где-то не вставились пробелы вместо табов или табы вместо пробелов.
UPD: примечание согласно комментариев
Я давно хотел написать статью про табы. Но не про «Табы VS Пробелы», а именно про то, как пользоваться табами правильно. Комменты подтвердили, что многие не знали про indentation и alignment. Смысл этой статьи совершенно не в том, что правы все, кто использует табы. Есть стандарты кодирования, есть особенности языка, есть личные предпочтения.
Самое главное — знать правила расстановки отступов и уметь ими пользоваться. И никогда не смешивать два стиля. Заметьте — не «не смешивать табы и пробелы», а не смешивать два стиля.
Лично я рекомендую использовать подход, описанный в топике, но только в том случае, если стандарты кода, с котором вы работаете не подразумевают что-то другое.
