Классический подход предусматривает разработку структур баз данных, где все сущности информационной модели находятся на одном абстрактном уровне, являются однородными. Однако, сложные и слабо-структурированные предметные области приводят реляционную декомпозицию к комбинаторному взрыву, непропорциональному росту количества таблиц и связей. А динамические предметные области, в которых ежедневные изменения являются нормой жизненного цикла, требуют постоянного реинженеринга структуры реляционной базы данных.
В таких условиях, подъем уровня абстракции может решить задачу только частично, ведь переходя от конкретики к абстрактной модели теряется специфика предметной области. Следовательно, хранить в одной базе данных нужно два, логически связанных слоя абстракции. Логическую же связку должен выполнять мета-слой, определяющий параметры взаимно однозначного отображения одного абстрактного слоя модели в другой.
 (рис. 1)
(рис. 1)
Для простоты объяснений возьмем предметную область, понятную каждому (см. рис. 1). Желтым цветом обозначены сущности, а зеленым – перекрестные связи между ними (многие-ко-многим). Имеем две иерархии, организационная: компания, подразделение, отдел (мы можем расширить ее в дальнейшем, вводя новые уровни иерархии). А вторая иерархия классифицирует деятельность: отрасль, направление, специализация (ее мы тоже можем расширять). Но для упрощения мы ограничимся тремя звеньями в каждой иерархии, и уже при такой ограниченной информационной модели выявим необходимость в поднятии уровня абстракции.
Идеалистичная модель предметной области показана на рис. 1, однако, на практике, может оказаться, что специализации нужно привязывать не только к отделам, но и к подразделениям или даже к компаниям (в разных организациях это по-разному, структура крайне динамична и не стабильна при первоначальной кажущейся простоте). Таким образом, проанализировав и обобщив структуру нескольких десятков компаний, можно прийти к следующей диаграмме (см. рис. 2). Три сущности в одной иерархии могут связываться с тремя сущностями в другой, почти произвольно (всех комбинаций 9), одна связь в данном случае не применяется, и мы можем исключить ее, получив 8 типов связей многие-ко-многим. Ситуация усложняется когда каждая из связей должна иметь еще и несколько групп атрибутов, определяющих параметры количества должностных позиций, требования к сотрудникам, нормы сертификации и оклады (взято для примера, на самом деле информационная модель гораздо сложнее).
 (рис. 2)
(рис. 2)
На рисунке 2 мы видим, что даже ER-диаграмма такой модели становится сложной для понимания, а если каждая из связей получают еще по 3-5 групп параметров, то перекрестных таблиц становится порядка двух-четырех десятков, что вообще сложно отобразить на схеме. Кроме того, создавать программный код и интерфейсы пользователя для работы с базой данных такой сложности становится очень проблематично, а при необходимости вносить в них постоянные изменения, такой программный продукт получает огромную стоимость владения и организационные трудности в сопровождении.
Переход к более высокой степени абстракции позволяет нам выделить сущность высшего порядка “структурное подразделение” или “организационная иерархия”, которая отобразится в структуре базы данных в таблицу с рекурсивной ссылкой (сама на себя; поле обычно называемое ParentId или аналогично). Из такой таблицы мы можем развернуть иерархию, с неограниченной вложенностью. То же происходит и со второй иерархией, мы выделяем сущность более высокого порядка “классификация деятельности” (см. рис. 3). Таким образом, мы сделали свертку связей, превратив 8 отношений “многие-ко-многим” в одно такое отношение. Но в данном случае, при обобщении, была потеряна семантика, а именно: связь между компаниями и специализациями не нужна (в данном примере), а так как компании являются структурными подразделениями в “организационной иерархии”, а специализации входят в “классификацию деятельности”, то по диаграмме на рисунке 3, такая связь возможна. Однако, информационная система, должна запрещать пользователю создавать связь такого типа на логическом уровне, что является аспектом целостности информации и является обязательной функцией СУБД.
 (рис. 3)
(рис. 3)
Логический уровень обеспечивается метамоделью предметной области и интерпретируется динамически на уровне приложений, что вносит дополнительную гибкость в систему, так как, логика предметной области может быть изменена без модификации программного кода. Для разрешения или запрета определенного типа связи на логическом уровне, хватит всего лишь задания этого в формальных терминах метамодели.
 (рис. 4)
(рис. 4)
При введении параметров связей (даже нескольких групп параметров) мы должны модифицировать структуру рисунка 3, разбив связи на три. Причем, метаданные определяют логические ограничения на установку связей, чтобы отобразить семантику предметной области: каждая компания занимается отраслями и направлениями; подразделения и отделы могут заниматься отраслями, направлениями и специализациями; подразделения и отделы (но не компании) имеют определенные должности; компании и подразделения (но не отделы) направлены на удовлетворение спроса других субьектов рынка, принадлежащих отраслям и направлениям (но не специализациям). Таким образом, например, связь с группой атрибутов “должности” между компанией и специализацией логически запрещена. Перекрестные таблицы базы данных будут содержать только одну группу параметров для нескольких типов связей, как показано на рис. 4.
 (рис. 5)
(рис. 5)
Но возникает вопрос, где хранить атрибуты сущностей? Ведь в таблице “Организационная иерархия” может содержаться только группа атрибутов, общая для всех сущностей низшего порядка абстракции: компания, подразделение, отдел. А все не пересекающиеся атрибуты должны быть вынесены в отдельные таблицы, чтобы не создавать ненормализованную структуру с большим количеством “пустых” ячеек. Таким образом, мы приходим к необходимости иметь несколько таблиц более низкого уровня абстракции в одной базе с нашей иерархической таблицей. А связаны они будут с ней общим (точнее, одинаковым) первичным ключом во всей группе таблиц, объединенных связью “один-к-одному” с таблицей “организационная иерархия”. Такая связь (см. рис. 5) предусматривает наличие записи с соответствующим первичным ключом из “организационной иерархии” только в одной из четырех таблиц. Графическое изображение связи “один-к-одному-из” или “supertype-and-sybtype-discriminator” взята из нотации IDEF1, применяемой в большом количестве CASE-средств разработки информационных моделей баз данных (ErWin, Logic Works, Rational Rose, ER/Studio и д.р.).
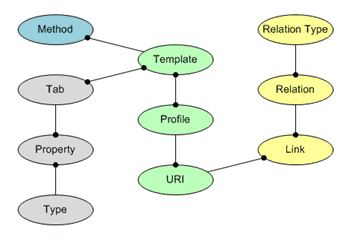 (рис. 6)
(рис. 6)
Описание элементов метамодели (на рис. 6):
Profile – сущность или профиль, является отображением второго порядка объекта предметной области. Профиль имеет сквозной идентификатор, использующийся для ссылок на него в рамках всей информационной системы, однако, для внешних ссылок используется URI.
Template – шаблон, аналог класса в объектной модели с поддержкой множественного наследования и непрямого наследования. Множественное заключается в том, что каждый профиль может наследовать от нескольких шаблонов, а непрямое наследование выражается в возможности прикрепления к шаблонам “табов” – групп свойств, при этом шаблоны могут не наследовать табы друг от друга, а получать табы от любого шаблона другой ветви классификации.
URI – уникальный идентификатор профиля, использующийся для внешних ссылок на объекты предметной области, свойства объектом, связи и методы. URI позволяет адресовать все элементы метамодели и все элементы информационной модели предметной области.
Relation Type – тип связи профилей.
Relation – связь между двумя или более профилями (на втором уровне абстракции) или двумя и более сущностями (на уровне реляционной модели).
Link – ссылка на профиль (сущность), позволяющая включать в связи несколько профилей.
Tab – группа свойств профиля, отображается в реляционную модель в виде таблицы базы данных.
Property – свойство профиля, отображается в реляционную модель, чаще всего, в виде поля базы данных, однако для справочников и классификаторов свойство может отображаться в “foreign key” или же в справочную таблицу и связь “многие-ко-многим” с табом профиля.
Type – тип данных, назначенный атрибуту профиля (сущности).
Method – метод или функция, реализует бизнес-логику профиля.
На втором уровне абстракции модели мы можем прийти к свертке реляционной структуры базы к еще большему обобщению (см. рис. 6). На рисунке мы видим элементы метамодели, где желтый и зеленый цвета, отвечают соответственно за сущности и связи, а группа серых таблиц отвечает за атрибуты сущностей. Такая структура подходит для подавляющего большинства предметных областей в сфере прикладных информационных систем. Это структура метаданных, которая описывает структуру таблиц в более обобщенных категориях, что позволяет программному обеспечению опираться не на структуру базы данных и не на метаданные, а на структуру метамодели, то есть на абстракцию второго порядка. Однако, метамодель не имеет достаточной конкретики для решения прикладных задач и нуждается в детализации, что и происходит на первом абстрактном уровне (см. рис. 4). Таким образом, мы имеем две структуры базы, на разных уровнях абстракции, хранящихся в одной БД параллельно. Связь же между ними происходить по сквозным уникальным идентификаторам, так как, Profile – это есть абстрактная сущность второго порядка, связанная со всеми сущностями первого порядка связью “один-к-одному-из” (или “supertype-and-sybtype-discriminator”, см. рис. 5 и объяснения выше).
Продолжение будет во второй части.
Для обсуждения добавляю еще одну схему, которая будет описана во второй части:
Спасибо за внимание.
В таких условиях, подъем уровня абстракции может решить задачу только частично, ведь переходя от конкретики к абстрактной модели теряется специфика предметной области. Следовательно, хранить в одной базе данных нужно два, логически связанных слоя абстракции. Логическую же связку должен выполнять мета-слой, определяющий параметры взаимно однозначного отображения одного абстрактного слоя модели в другой.
 (рис. 1)
(рис. 1)Для простоты объяснений возьмем предметную область, понятную каждому (см. рис. 1). Желтым цветом обозначены сущности, а зеленым – перекрестные связи между ними (многие-ко-многим). Имеем две иерархии, организационная: компания, подразделение, отдел (мы можем расширить ее в дальнейшем, вводя новые уровни иерархии). А вторая иерархия классифицирует деятельность: отрасль, направление, специализация (ее мы тоже можем расширять). Но для упрощения мы ограничимся тремя звеньями в каждой иерархии, и уже при такой ограниченной информационной модели выявим необходимость в поднятии уровня абстракции.
Идеалистичная модель предметной области показана на рис. 1, однако, на практике, может оказаться, что специализации нужно привязывать не только к отделам, но и к подразделениям или даже к компаниям (в разных организациях это по-разному, структура крайне динамична и не стабильна при первоначальной кажущейся простоте). Таким образом, проанализировав и обобщив структуру нескольких десятков компаний, можно прийти к следующей диаграмме (см. рис. 2). Три сущности в одной иерархии могут связываться с тремя сущностями в другой, почти произвольно (всех комбинаций 9), одна связь в данном случае не применяется, и мы можем исключить ее, получив 8 типов связей многие-ко-многим. Ситуация усложняется когда каждая из связей должна иметь еще и несколько групп атрибутов, определяющих параметры количества должностных позиций, требования к сотрудникам, нормы сертификации и оклады (взято для примера, на самом деле информационная модель гораздо сложнее).
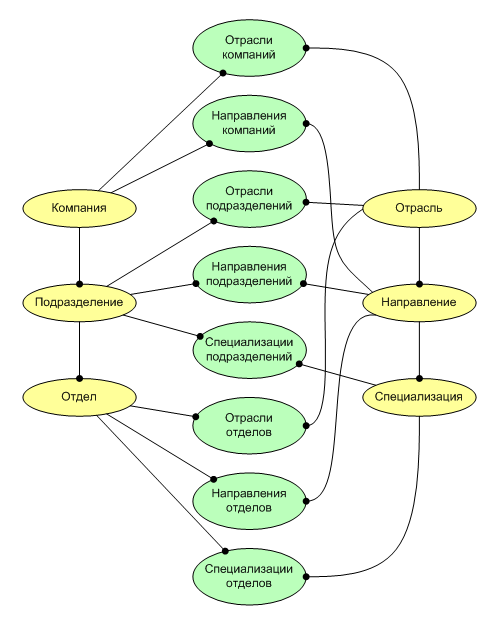 (рис. 2)
(рис. 2)На рисунке 2 мы видим, что даже ER-диаграмма такой модели становится сложной для понимания, а если каждая из связей получают еще по 3-5 групп параметров, то перекрестных таблиц становится порядка двух-четырех десятков, что вообще сложно отобразить на схеме. Кроме того, создавать программный код и интерфейсы пользователя для работы с базой данных такой сложности становится очень проблематично, а при необходимости вносить в них постоянные изменения, такой программный продукт получает огромную стоимость владения и организационные трудности в сопровождении.
Переход к более высокой степени абстракции позволяет нам выделить сущность высшего порядка “структурное подразделение” или “организационная иерархия”, которая отобразится в структуре базы данных в таблицу с рекурсивной ссылкой (сама на себя; поле обычно называемое ParentId или аналогично). Из такой таблицы мы можем развернуть иерархию, с неограниченной вложенностью. То же происходит и со второй иерархией, мы выделяем сущность более высокого порядка “классификация деятельности” (см. рис. 3). Таким образом, мы сделали свертку связей, превратив 8 отношений “многие-ко-многим” в одно такое отношение. Но в данном случае, при обобщении, была потеряна семантика, а именно: связь между компаниями и специализациями не нужна (в данном примере), а так как компании являются структурными подразделениями в “организационной иерархии”, а специализации входят в “классификацию деятельности”, то по диаграмме на рисунке 3, такая связь возможна. Однако, информационная система, должна запрещать пользователю создавать связь такого типа на логическом уровне, что является аспектом целостности информации и является обязательной функцией СУБД.
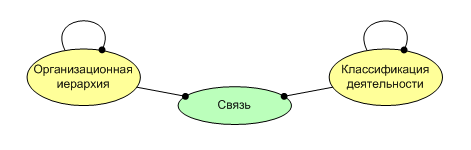 (рис. 3)
(рис. 3)Логический уровень обеспечивается метамоделью предметной области и интерпретируется динамически на уровне приложений, что вносит дополнительную гибкость в систему, так как, логика предметной области может быть изменена без модификации программного кода. Для разрешения или запрета определенного типа связи на логическом уровне, хватит всего лишь задания этого в формальных терминах метамодели.
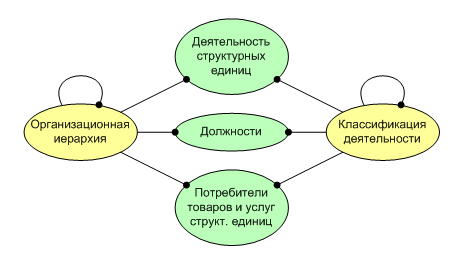 (рис. 4)
(рис. 4)При введении параметров связей (даже нескольких групп параметров) мы должны модифицировать структуру рисунка 3, разбив связи на три. Причем, метаданные определяют логические ограничения на установку связей, чтобы отобразить семантику предметной области: каждая компания занимается отраслями и направлениями; подразделения и отделы могут заниматься отраслями, направлениями и специализациями; подразделения и отделы (но не компании) имеют определенные должности; компании и подразделения (но не отделы) направлены на удовлетворение спроса других субьектов рынка, принадлежащих отраслям и направлениям (но не специализациям). Таким образом, например, связь с группой атрибутов “должности” между компанией и специализацией логически запрещена. Перекрестные таблицы базы данных будут содержать только одну группу параметров для нескольких типов связей, как показано на рис. 4.
 (рис. 5)
(рис. 5)Но возникает вопрос, где хранить атрибуты сущностей? Ведь в таблице “Организационная иерархия” может содержаться только группа атрибутов, общая для всех сущностей низшего порядка абстракции: компания, подразделение, отдел. А все не пересекающиеся атрибуты должны быть вынесены в отдельные таблицы, чтобы не создавать ненормализованную структуру с большим количеством “пустых” ячеек. Таким образом, мы приходим к необходимости иметь несколько таблиц более низкого уровня абстракции в одной базе с нашей иерархической таблицей. А связаны они будут с ней общим (точнее, одинаковым) первичным ключом во всей группе таблиц, объединенных связью “один-к-одному” с таблицей “организационная иерархия”. Такая связь (см. рис. 5) предусматривает наличие записи с соответствующим первичным ключом из “организационной иерархии” только в одной из четырех таблиц. Графическое изображение связи “один-к-одному-из” или “supertype-and-sybtype-discriminator” взята из нотации IDEF1, применяемой в большом количестве CASE-средств разработки информационных моделей баз данных (ErWin, Logic Works, Rational Rose, ER/Studio и д.р.).
 (рис. 6)
(рис. 6)Описание элементов метамодели (на рис. 6):
Profile – сущность или профиль, является отображением второго порядка объекта предметной области. Профиль имеет сквозной идентификатор, использующийся для ссылок на него в рамках всей информационной системы, однако, для внешних ссылок используется URI.
Template – шаблон, аналог класса в объектной модели с поддержкой множественного наследования и непрямого наследования. Множественное заключается в том, что каждый профиль может наследовать от нескольких шаблонов, а непрямое наследование выражается в возможности прикрепления к шаблонам “табов” – групп свойств, при этом шаблоны могут не наследовать табы друг от друга, а получать табы от любого шаблона другой ветви классификации.
URI – уникальный идентификатор профиля, использующийся для внешних ссылок на объекты предметной области, свойства объектом, связи и методы. URI позволяет адресовать все элементы метамодели и все элементы информационной модели предметной области.
Relation Type – тип связи профилей.
Relation – связь между двумя или более профилями (на втором уровне абстракции) или двумя и более сущностями (на уровне реляционной модели).
Link – ссылка на профиль (сущность), позволяющая включать в связи несколько профилей.
Tab – группа свойств профиля, отображается в реляционную модель в виде таблицы базы данных.
Property – свойство профиля, отображается в реляционную модель, чаще всего, в виде поля базы данных, однако для справочников и классификаторов свойство может отображаться в “foreign key” или же в справочную таблицу и связь “многие-ко-многим” с табом профиля.
Type – тип данных, назначенный атрибуту профиля (сущности).
Method – метод или функция, реализует бизнес-логику профиля.
На втором уровне абстракции модели мы можем прийти к свертке реляционной структуры базы к еще большему обобщению (см. рис. 6). На рисунке мы видим элементы метамодели, где желтый и зеленый цвета, отвечают соответственно за сущности и связи, а группа серых таблиц отвечает за атрибуты сущностей. Такая структура подходит для подавляющего большинства предметных областей в сфере прикладных информационных систем. Это структура метаданных, которая описывает структуру таблиц в более обобщенных категориях, что позволяет программному обеспечению опираться не на структуру базы данных и не на метаданные, а на структуру метамодели, то есть на абстракцию второго порядка. Однако, метамодель не имеет достаточной конкретики для решения прикладных задач и нуждается в детализации, что и происходит на первом абстрактном уровне (см. рис. 4). Таким образом, мы имеем две структуры базы, на разных уровнях абстракции, хранящихся в одной БД параллельно. Связь же между ними происходить по сквозным уникальным идентификаторам, так как, Profile – это есть абстрактная сущность второго порядка, связанная со всеми сущностями первого порядка связью “один-к-одному-из” (или “supertype-and-sybtype-discriminator”, см. рис. 5 и объяснения выше).
Продолжение будет во второй части.
Для обсуждения добавляю еще одну схему, которая будет описана во второй части:
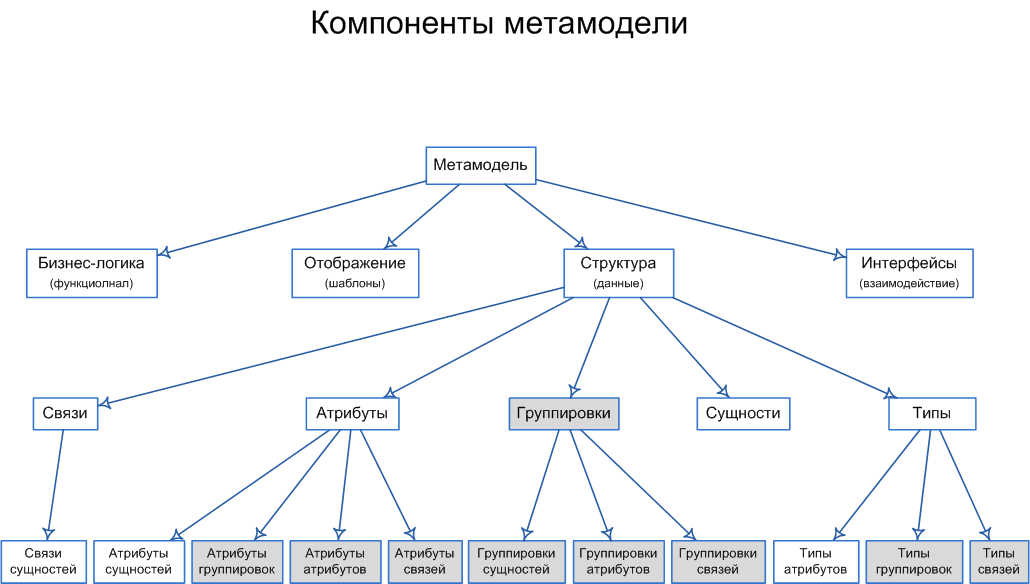
Спасибо за внимание.
