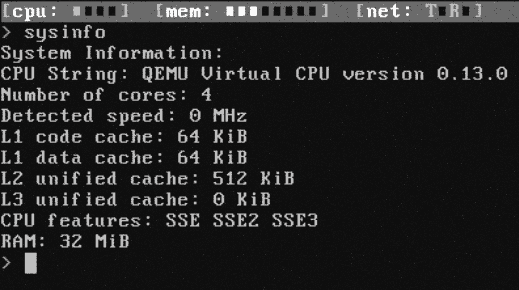
Разработчики из канадской компании Return Infinity специализируются на низкоуровневом программировании и экспериментальных разработках. На днях они выкатили новую версию BareMetal, 64-битной операционной системы, написанной полностью на ассемблере. Цель этого проекта — избавиться от неэффективного машинного кода, который генерируют компиляторы высокоуровневых языков вроде C/C++ и Java. Если изначально писать на ассемблере, то код получается более производительным и компактным. Вся ОС занимает 16384 байт, а программка “Hello World!” компилируется в файл 31 байт.
Теоретически, это идеальная система для высокопроизводительных систем и встроенных приложений. BareMetal поддерживает выполнение приложений на ассемблере и C/C++. В будущем планируется улучшить поддержку C/C++ и добавить базовый стек TCP/IP.
В комплекте с BareMetal идёт минималистский загрузчик Pure64 и кластерная платформа BareMetal Node. На видео показано, как кластер ищет простые числа.
Исходный код BareMetal опубликован под лицензией BSD, он максимально прост и документирован. По мнению авторов программы, даже начинающим программистам его будет легко изучать.
Проект создан под впечатлением от MikeOS, 16-битной ОС на ассемблере.
