
Как-то друг попросил помочь с дипломной работой и дал ссылку на статью, в которой говориться о восстановлении изображения с помощью самоорганизующихся карт Кохонена. Почитав статью, я вначале решил, что это бред какой-то, и что нейросеть к восстановлению никаким боком не стыкуется. Но, я чуток ошибался, оказалось, что этот метод весьма увлекательный, и когда я его таки сделал, не мог набаловаться.
Как же это работает?
Карта Кохонена представляет из себя двухмерную сетку NXxNY, состоящую из нейронов. Каждый нейрон в сетке представляется квадратиком SxS — этот квадратик называется вектором веса, значения которого равны цвету соответствующего пикселя.
Для обучения в сеть подаются фрагменты изображения SxS, после чего сеть ищет самый похожий на этот фрагмент нейрон, так называемый BMU (best matching unit), и подгоняет его весовые коэффициенты таким образом, чтобы он еще больше был похож на поданный фрагмент. А потом еще тренирует соседей, но уже с меньшей интенсивностью. Чем дальше отстоит нейрон от BMU, тем меньший вклад на него оказывает поданный фрагмент. Так сеть обучается до тех пор, пока отклонения BMU для каждого поданного фрагмента достигнет некоторой минимальной величины.
Вот пару примеров, на первой картинке представлена сеть 120х120 с нейронами 3х3, а на втором рисунке сеть 24х24 с нейронами 15х15. Красота!
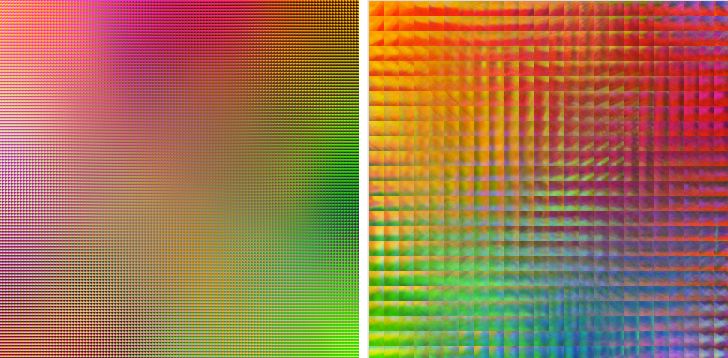
Восстановление происходит подобным образом, берется фрагмент SxS поврежденного изображения, и по не поврежденным пикселям ищется BMU, после чего поврежденные пиксели заменяются соответствующими значениями из вектора веса нейрона.
Как нейросеть «видит» картинку?
Чтобы посмотреть как нейросеть «видит» картинку, я придумал следующий метод. Берем обученную нейросеть, и для каждого пикселя в картинке создаем фрагмент SxS, подаем его в нейросеть, извлекаем из нее цвет центрального пикселя и записываем этот цвет по тем же координатам, но в новую картинку. Полученная в результате картинка отражает потенциал восстановления изображения данной нейросетью. Для экспирементов я использовал такую картинку

Благодаря этому методу я выявил несколько интересных свойств.
- Чем больше размер S — тем менее четким получается изображение
На рисунке показаны изображения созданные с нейронами 3х3 и 15х15. Как видно, 3х3 вообще мало чем отличается от оригинала. В 15х15 уже получается размазанным.


- Чем больше нейронов в сети, тем больше палитра цветов.
На первой картинке использовалась сетка 4х4, и 120х120 на второй. Как видно, в сети 4х4 переходы между цветами резкие.

- Чем больше итераций обучения, тем точнее восстановленные цвета соответствуют цветам реальной картинке и тем лучше видны детали. На первой картинке использовалась нейросеть 10x10, обученная на 10 фрагментах, а на второй на 10000 фрагментах.







Кстати, обратите внимание, восcтановление хорошо обученной сетью 10х10 и 120х120 визуально очень слабо отличаются, только если сильно присмотреться к деталям можно найти небольшие отличия.
Я оформил генератор в виде небольшого приложения, так что можно побаловаться самим (проверял на webkit и FF).
Восстановление небольших случайных повреждений
Небольшие случайные повреждения легко устраняются сетями с маленькими нейронами, например 3х3 или 5х5 вполне достаточно. Они работают быстро и качественно. Вот пример восстановление изображения в котором повреждено 25% пикселей, сетью 10x10 и нейронами 5х5


Для восстановления случайных повреждений также сделал отдельное приложение.
Восстановление крупных областей
Чтобы восстановить крупные поврежденные участки, нужно, чтобы размер нейрона S превышал размер поврежденной области. Соответственно, чем больше размер повреждений, тем более размазанным будет восстановленный участок.
На рисунке показано восстановление фрагмента 10х10 сетью с нейроном 15х15


Восстановление при <20% известных пикселей
К сожалению, по таким изображениям невозможно построить карту, поэтому увы, восстановить их напрямую не получится, но зато их можно восстановить если взять уже обученную сеть. На рисунке приведен пример восстановления изображения по 12% известных пикселей. Сеть тренировалась на оригиральном изображении.


По-моему весьма неплохо получилось, для такого объем повреждений.
UPD: о практическом применении, разработанных мною, приложений:
Целью моего исследования является проверить концепт, а не предоставить рабочее приложение на все случаи жизни, поэтому все разговоры о каком-либо серьезном практическом применении той версии, которая существует на сегодняшний день, не имеют никакого смысла.
