Вторая часть статьи.
Большинство современных вычислительных машин, будь то суперкомпьютер Fujitsu K, обычная персоналка или даже калькулятор, объединяет общий принцип работы, а именно модель вычислений, основанная на потоке управления (Controlflow). Однако, эта модель не является единственно возможной. В некотором роде ее противоположностью является модель вычислений, управляемая потоком данных, или просто Dataflow. О ней я и хочу сейчас рассказать.
Архитектуру потока управления часто называют фон-неймановской (в честь Джона фон Неймана). Это не совсем правильно, так как архитектура фон Неймана — лишь подмножество архитектур потока управления. Существуют не-неймановские архитектуры потока управления, например гарвардская, которую сейчас можно встретить разве что в микроконтроллерах.
В рамках архитектуры потока управления (controlflow) вычислительная машина состоит из двух основных узлов: процессора и памяти. Программа представляет собой набор инструкций, хранящихся в памяти в порядке выполнения. Данные, с которыми работает программа, также хранятся в памяти в виде набора переменных. Адрес инструкции, которая выполняется в настоящий момент, хранится в специальном регистре, в x86 он так и называется — Instruction Pointer (IP). Момент начала выполнения инструкции определяется моментом завершения предыдущей (мы сейчас рассматриваем упрощенную модель без всяких Out-of-Order). Система очень простая, понятная и знакомая большинству читателей. Так зачем же придумывать что-то еще?
Врожденные проблемы controlflow
Дело в том, что архитектура control flow имеет ряд врожденных недостатков, полностью избавиться от которых невозможно, так как они проистекают из самой организации вычислительного процесса, можно только уменьшить негативный эффект с помощью различных
- Перед выполнением инструкции ее операнды необходимо загрузить из памяти в регистры процессора, а после выполнения — выгрузить результат обратно в память. Шина процессор-память становится узким местом: процессор простаивает часть времени, ожидая загрузки данных. Проблема с переменным успехом решается при помощи упреждающей выборки и нескольких уровней кэш-памяти.
- Построение многопроцессорных систем сопряжено с рядом трудностей. Существуют две основные концепции таких систем: с общей и с распределенной памятью. В первом случае сложно физически обеспечить совместный доступ многих процессоров к одному ОЗУ. Во втором случае возникают проблемы когерентности данных и синхронизации. С ростом числа процессоров в системе все больше ресурсов тратится на обеспечение синхронизации и все меньше — на собственно вычисления [03].
- Никто не гарантирует, что на момент выполнения какой-либо инструкции ее операнды будут находиться в памяти по указанным адресам. Инструкция, которая должна записать эти данные, может оказаться, еще не выполнилась. В многопоточных приложениях существенная доля ресурсов
и нервов программистатратится на обеспечение синхронизации потоков.
Знакомьтесь — Dataflow
Нет устоявшегося русского перевода для термина Dataflow architecture. Можно встретить варианты «потоковая архитектура», «архитектура потока данных», «архитектура с управлением потоком данных» и подобные им.
В архитектурах с управлением потоком данных (Dataflow) [01] отсутствует понятие «последовательность инструкций», нет Instruction Pointer'а, отсутствует даже адресуемая память в привычном нам смысле. Программа в потоковой системе — это не набор команд, а вычислительный граф. Каждый узел графа представляют собой оператор или набор операторов, а ветви отражают зависимости узлов по данным. Очередной узел начинает выполняеться как только доступны все его входные данные. В этом состоит один из основных принципов dataflow: исполнение инструкций по готовности данных.
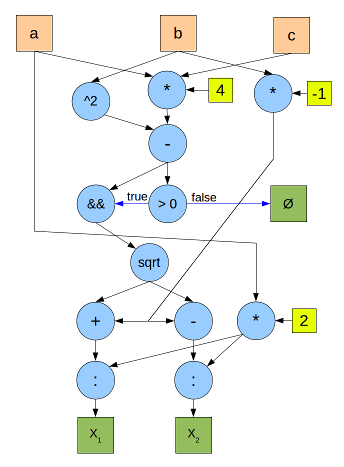
Вот для примера граф вычисления корней квадратного уравнения. Синие круги — операторы, оранжевые квадраты — входные данные, зеленые — выходные, желтые — константы. Черные стрелки обозначают передачу численных данных, синие — булевых.
Аппаратная реализация
В потоковых машинах данные передаются и хранятся в виде т.н. токенов (token). Токен — это структура, содержащая собственно передаваемое значение и метку — указатель узла назначения. Простейшая потоковая вычислительная система состоит из двух устройств: исполнительного (execution unit) и устройства сопоставления (matching unit) [11].
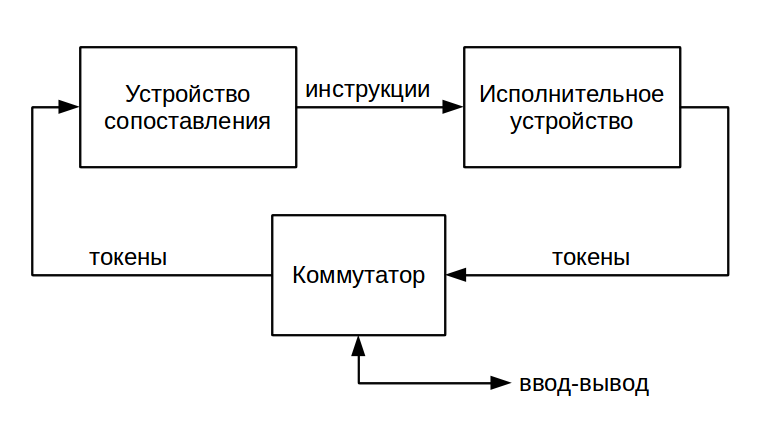
Исполнительное устройство служит для выполнения инструкций и формирования токенов с результатами операций. Как правило, оно включает в себя память команд, доступную только для чтения. Готовность входных данных узла определяется по наличию набора токенов с одинаковыми метками. Для поиска таких наборов и служит устройство сопоставления. Обычно оно реализуется на базе ассоциативной памяти. Используется либо «настоящяя», аппаратная ассоциативная память (CAM — content-addressable memory), либо структуры, работающие аналогично, например, хэш-таблицы.
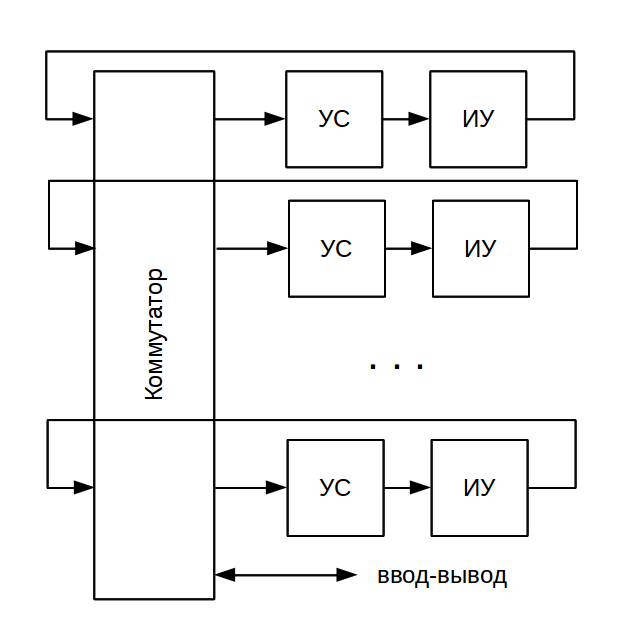
Одним из основных достоинств dataflow-архитектуры является ее масштабируемость: не составляет труда собрать систему, содержащую множество устройств сопоставления и исполнительных устройств. Устройства объедиянются простейшим коммутатором, причем для адресации токенов служат их метки. Весь диапазон номеров узлов просто распределяется равномерно между устройствами. Никаких дополнительных мер для синхронизации вычислительного процесса, в отличие от многопроцессорной controlflow-архитектуры, не требуется.
Статическая dataflow-архитектура
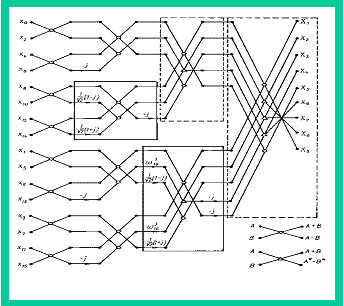
Описанная выше схема называется статической (static dataflow). В ней каждый вычислительный узел представлен в единственном экземпляре, число узлов заранее известно, также заранее известно число токенов, циркулирующих в системе. В качестве примера реализации статической архитектуры можно привести MIT Static Dataflow Machine [12] — потоковый компьютер, созданный в Массачусетском технологическом институте в 1974 году. Машина состояла из множества обрабатывающих элементов (Processing Element), связанных коммуникационной сетью. Схема одного элемента показана на рисунке:
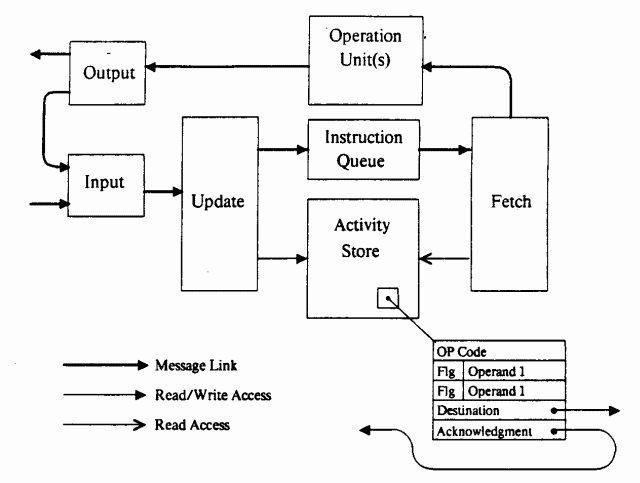
Роль устройства сопоставления здесь выполняла память взаимодействий (activity store). В ней хранились пары токенов вместе с адресом узла назначения, флагами готовности и кодом операции. Любой вычислительный узел в этой архитектуре имел только два входа и состоял из одного оператора. При обнаружении готовности обоих операндов устройство выборки (fetch unit) считывало код операции, и данные отправлялись на обработку в исполнительное устройство (operation unit).
Динамическая dataflow-архитектура
В динамической потоковой архитектуре (dynamic dataflow) каждый узел может иметь множество экземпляров. Для того, чтобы различать токены, адресованные в разные экземпляры одного узла, в структуру токена вводится дополнительное поле — контекст. Сопоставление токенов теперь ведется не только по меткам, но и по значениям контекста. По сравнению со статической архитектурой появляется целый ряд новых возможностей.
- Рекурсия. Узел может направлять данные в свою копию, которая будет отличаться контекстом (но при этом иметь ту же метку).
- Поддержка процедур. Процедурой в рамках данной модели вычислений будет последовательность узлов, связанных между собой и имеющая входы и выходы. Можно одновременно вызывать несколько экземпляров одной и той же процедуры, которые будут отличаться контекстом.
- Распараллеливание циклов. Если между итерациями цикла нет зависимости по данным, можно обрабатывать сразу все итерации одновременно. Номер итерации, как вы уже наверное догадались, будет содержаться в поле контекста.
Одной из первых реализаций динамической потоковой архитектуры была система Manchester Dataflow Machine (1980 год) [13]. Машина содержала аппаратные средства для организации рекурсий, вызова процедур, раскрытия циклов, копирования и объединения ветвей вычислительного графа. Также в отдельный модуль была вынесена память команд (instruction store unit). На рисунке показана схема одного элемента машины:
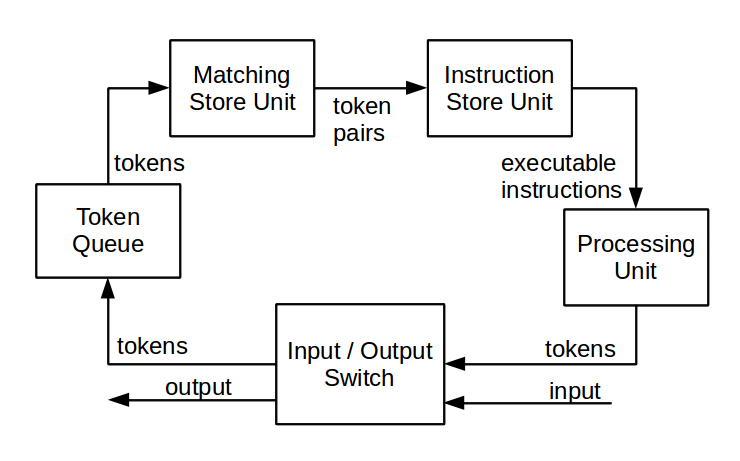
Динамическая dataflow-архитектура, по сравнению со статической, демонстрирует более высокую производительность, за счет лучшего параллелизма вычислений. Кроме того, она дает больше возможностей для программиста. С другой стороны, динамическая система сложнее по аппаратной реализации, особенно это касается устройств сопоставления и блоков формирования контекста токенов.
Продолжение следует
В следующей части статьи: почему dataflow архитектуры не настолько хороши, как здесь расписано? Как скрестить
Stay tuned…
Литература
Общие вопросы dataflow
[01] — Dataflow architectures, Jurij Silc
[02] — Баканов В.М. Потоковые (Dataflow) вычислители: управление интенсивностью обработки данных
[03] — Параллелизация обработки данных на вычислителях потоковой (Dataflow) архитектуры. Журнал «Суперкомпьютеры top50».
Аппаратные реализации
[11] — Dataflow architectures, Arvind David E. Culler
[12] — Preliminary Architecture for a Basic Data-Flow Processor, Jack B. Dennis and David P. Misunas
[13] — A Multilayered Data Flow Computer Architecture, J.R. Gurd, I. Watson.
