Продолжение к посту модель Миллса.
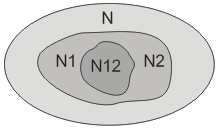
Данная модель требует тестирование программы двумя специалистами (или группами специалистов). Зато не требует внесение в программу искусственных ошибок. Итак, пусть программу тестируют независимо друг от друга две группы специалистов. Предположим, что в программе содержится N ошибок. Пусть первая группа нашла N1 ошибок, а вторая — N2. Часть ошибок обнаружена обеими группами. Пусть таких ошибок N12.
Эффективность работы групп оценим через процент обнаруженных ими ошибок:
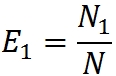
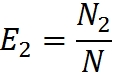
Обаружение всех ошибок считаем равновероятным (что, на мой взгляд, уменьшает доверие к этой модели, как и в случае с миллсовой). Тогда, в силу равновероятности нахождения любой из ошибок, любое случайным образом выбранное подмножество из N можно рассматривать как аппроксимацию всего множества N. Это значит, что если первая группа обнаружила 10% всех ошибок, она должна обнаружить примерно 10% из любого случайным образом выбранного подмножества.
В качестве такого случайным образом выбранного подмножества возьмём множество ошибок, найденных второй группой. Доля всех ошибок, найденных первой группой, равна N1/N. Доля ошибок, найденных первой группой среди тех ошибок, которые были найденны второй группой, равна N12/N2. Согласно такому рассуждению, эти две величины должны быть равны:
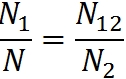
Отсюда количество ошибок в программе:

Количество нанайденных ошибок равно (N-N1-N2+N12).
Например, пусть первая группа нашла 8 ошибок, вторая 9. Обеими группами были найдены 3 ошибки. Тогда количество ошибок в программе N=(8*9/3)=24. Из них уже найденно (8+9-3)=14. Следовательно осталось найти 10 штук.
Данная модель появилась в процессе работы над OS/360 компанией IBM. Была использованна следущая формула для оценки числа ошибок: N=2*ИМ+23*МИМ. Здесь
N — полное число исправлений изза ошибок,
ИМ — количество исправляемых модулей,
МИМ — число многократно исправляемых модулей.
Многократно исправляемыми модулями считались модули, которые потребовали 10 или более исправлений. ИМ оценивалось как 90% новых модулей и 15% старых. МИМ — как 15% новых и 6% старых. При подстановке таких оценок в формулу получаем вид:
Nиспр=2*(0.9*Nнов. мод.+0.15*Nстар. мод.)+23*(0.15*Nнов. мод.+0.06*Nстар. мод.)
Таким образом, если в системе 140 модулей, а в процесее обновления предстоит добавить ещё 20, то количество ошибок, которое при этом будет обнаружено, оценивается следующим образом:
2*(0.9*20+0.15*140)+21*(0.15*20+0.06*140) = 2*(18+21)+23*(3+8.4) = 78+262.2 = 340.2
Можно ожидать 340 ошибок. В 18 из 20 новых модулей придется внести хотя бы одно исправление, в 3 модуля — не менее десятка. Из старых модулей хотя бы один раз придется исправить 21 модуль, а 8 или 9 модулей — не менее 10 раз.
Стоит иметь в виду, что такая модель разрабатывалась для конкретной системы. Не факт, что её можно напрямую применять в других случаях.
При написании статьи была использована методичка «Тестирование и отладка для «чайников» и не только для них» (М.А. Плаксин)
Парная оценка
Данная модель требует тестирование программы двумя специалистами (или группами специалистов). Зато не требует внесение в программу искусственных ошибок. Итак, пусть программу тестируют независимо друг от друга две группы специалистов. Предположим, что в программе содержится N ошибок. Пусть первая группа нашла N1 ошибок, а вторая — N2. Часть ошибок обнаружена обеими группами. Пусть таких ошибок N12.

Эффективность работы групп оценим через процент обнаруженных ими ошибок:
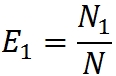
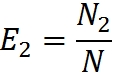
Обаружение всех ошибок считаем равновероятным (что, на мой взгляд, уменьшает доверие к этой модели, как и в случае с миллсовой). Тогда, в силу равновероятности нахождения любой из ошибок, любое случайным образом выбранное подмножество из N можно рассматривать как аппроксимацию всего множества N. Это значит, что если первая группа обнаружила 10% всех ошибок, она должна обнаружить примерно 10% из любого случайным образом выбранного подмножества.
В качестве такого случайным образом выбранного подмножества возьмём множество ошибок, найденных второй группой. Доля всех ошибок, найденных первой группой, равна N1/N. Доля ошибок, найденных первой группой среди тех ошибок, которые были найденны второй группой, равна N12/N2. Согласно такому рассуждению, эти две величины должны быть равны:
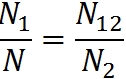
Отсюда количество ошибок в программе:

Количество нанайденных ошибок равно (N-N1-N2+N12).
Например, пусть первая группа нашла 8 ошибок, вторая 9. Обеими группами были найдены 3 ошибки. Тогда количество ошибок в программе N=(8*9/3)=24. Из них уже найденно (8+9-3)=14. Следовательно осталось найти 10 штук.
Исторический опыт
Данная модель появилась в процессе работы над OS/360 компанией IBM. Была использованна следущая формула для оценки числа ошибок: N=2*ИМ+23*МИМ. Здесь
N — полное число исправлений изза ошибок,
ИМ — количество исправляемых модулей,
МИМ — число многократно исправляемых модулей.
Многократно исправляемыми модулями считались модули, которые потребовали 10 или более исправлений. ИМ оценивалось как 90% новых модулей и 15% старых. МИМ — как 15% новых и 6% старых. При подстановке таких оценок в формулу получаем вид:
Nиспр=2*(0.9*Nнов. мод.+0.15*Nстар. мод.)+23*(0.15*Nнов. мод.+0.06*Nстар. мод.)
Таким образом, если в системе 140 модулей, а в процесее обновления предстоит добавить ещё 20, то количество ошибок, которое при этом будет обнаружено, оценивается следующим образом:
2*(0.9*20+0.15*140)+21*(0.15*20+0.06*140) = 2*(18+21)+23*(3+8.4) = 78+262.2 = 340.2
Можно ожидать 340 ошибок. В 18 из 20 новых модулей придется внести хотя бы одно исправление, в 3 модуля — не менее десятка. Из старых модулей хотя бы один раз придется исправить 21 модуль, а 8 или 9 модулей — не менее 10 раз.
Стоит иметь в виду, что такая модель разрабатывалась для конкретной системы. Не факт, что её можно напрямую применять в других случаях.
При написании статьи была использована методичка «Тестирование и отладка для «чайников» и не только для них» (М.А. Плаксин)
