При попытке отредактировать этот старый пост слетело всё форматирование. Может быть я его когда-нибудь исправлю.
Я потратил несколько месяцев на борьбу с глюками Git-svn и обдумывание разных вариантов, прежде чем пришёл к этому методу организации рабочего процесса с сайтом — простому, гибкому и удобному в работе.
Основные преимущества:
Главная идея системы — создение на сервере двух репозиториев: пустого bare-репозитория и обычного репозитория с рабочей копией сайта. Эта пара связана парой простых хуков, которые автоматизируют push и pull изменений.
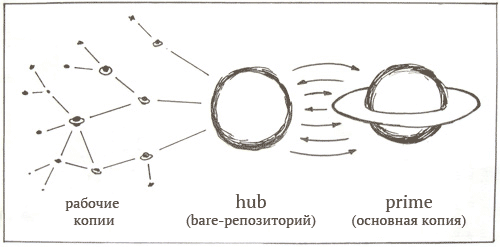
Итак, два репозитория:
Работа с двумя репозиториями простая и очень гибкая. Удалённые копии, имеющие ssh-доступ могут легко обновлять live-версию сайта просто выполнив push в Hub-репозиторий. Любые изменения, выполненные в live-версии на сервере мгновенно вливаются в Hub при коммите. В общем, всё работает очень просто — и неважно, где делаются изменения.
Естественно, в первую очередь нужно, что бы Git был установлен на сервере и на всех компах разработчиков. Если на вашем shared-хостинге не установлен Git — вы очень легко можете это исправить (en).
Если вы первый раз работаете с Git на своём сервере, не забудьте указать глобальные настройки. Я указываю особое значения для user.name, чтобы потом видеть в истории проекта изменения, выполненные на сервере:
В первую очередь создадим новый git-репозиторий в live-каталоге нашего сайта, а затем добавим и зафиксируем все файлы сайта. Это будет Prime-репозиторий и рабочая копия. Даже если уже есть история проекта в других местах, содержимое сайта будет базовой точкой, в которую потом будут слиты все остальные копии.
Поскольку мы сделали инициализацию репозитория в рабочей копии – нет нужды отключать сайт на обслуживание и повторно выкладывать все файлы, Git просто содаст репозиторий из имеющихся файлов.
Теперь, когда наш сайт уже находится в Git, создадим bare-репозиторий где-нибудь вне рабочего каталога сайта.
Ура! Снова вернёмся в рабочий каталог сайта и добавим Hub как удалённый репозиторий, а затем вольём в Hub содержимое ветки master из Prime-репозитория.
Как я уже упоминал в начале, Hub и Prime синхронизируются между собой, используя два простых скрипта.
Одно из основных правил при работе с Git — никогда не делайте push в репозтирий, у которого есть рабочая копия. Мы следуем этому правилу и создали репозиторий «Hub». Вместо того, чтобы делать push из Hub, который никак не повлияет на рабочую копию, мы будем использовать хук, который заставит Prime выполнить pull из Hub-репозитория.
Как только в Hub поступит новая порция изменений, сразу будет выполнен этот скрипт. Мы переходим в рабочий каталог Prime-репозитория, и вытягиваем измениния из Hub'а. Проталкивание изменений (push) не изменяет состояния рабочего каталога репозитория, поэтому и нужно делать pull, находясь в рабочем каталоге.
Этот скрипт запускается после каждого коммита в Prime-репозитории и проталкивает изменения в Hub. В идеальном мире, конечно, мы вообще никогда ничего не будем править прямо на сервере. Но в нашем несовершенном мире возможно всё, что угодно, поэтому давайте автоматизируем процесс проталкивания изменений, чтобы не разрушать историю проекта и избежать возможных конфликтов.
Итак, используя этот хук, мы сразу же получаем в Hub-репозитория все изменения, выполненные в master-ветке Prime-резпозитория. Прочие ветки также можно клонировать, но они не будут влиять на сайт. Поскольку все удалённые копии получают доступ через SSH-адрес к Hub, то выполнить push и запустить обновление сайта напрямую могут только пользователи, имеющие прямой доступ к shell'у.
«Положить» сайт при такой системе синхронизации двух репозиториев очень сложно. Каждое изменение, сделанное в Prime автоматически попадает в Hub и все конфликты будут сразу видны при попытке выполнить push из клонов репозитория.
Но всё же есть несколько ситуаций, при которых состояние Prime может отличаться от Hub'а, и для исправления ситуации потребуется выполнить несколько дополнительных телодвижений. Если мы что-то правим на Prime и не зафиксировали изменения, а в этот момент сработает post-update в Hub, то все завершится ошибкой с сообщением «Entry ‘foo’ not uptodate. Cannot merge.». Фиксация изменений в рабочем каталоге Prime позволит зачистить его состояние, и post-update хук сможет соединить все неотправленные изменения.
Также я обнаружил, что если конфликт возникает вследствие того, что изменения в Prime не могут быть объединены с Hub'ом, то наилучшим решением будет протолкнуть текущее состояние Prime'а в новую ветку на Hub. Эта команда, выполненная из рабочего каталога Prime создаст удалённую ветку «fixme», основанную на текущем стоянии Prime-репозитория.
Как только изменения окажутся в Hub'е, мы сможем получить ветку в любом из клонов, разрешить конфликт и смержить ветки. Попытка разрешить конфликт прямо на сервере почти наверняка приведёт к проблемам в работе сайте из-за появления маркеров конфликтных областей.
Каталог .git Prime-репозитория находится в корневом каталоге сайта, и, верояно, доступен для публичного доступа. Чтобы никто не смог сунуть свой нос, куда не следует, добавьте эти строки в файл .htaccess верхнего уровня:
Прим. переводчика: есть и другие способы закрыть доступ к каталогу на сервере.
Если при попытке выполнить push в репозиторий на сервере вы видите эту ошибку:
В этом случае просто добавьте
Я потратил несколько месяцев на борьбу с глюками Git-svn и обдумывание разных вариантов, прежде чем пришёл к этому методу организации рабочего процесса с сайтом — простому, гибкому и удобному в работе.
Основные преимущества:
- Делая push из удалённой копии мы автоматически обновляем live-копию сайта
- Правки файлов на сервере не будут разрушать историю коммитов
- Простота, не нужны особые правила выполнения коммитов
- Можно применить к уже запущенному сайту, без повторного деплоя или перемещения файлов
Обзор
Главная идея системы — создение на сервере двух репозиториев: пустого bare-репозитория и обычного репозитория с рабочей копией сайта. Эта пара связана парой простых хуков, которые автоматизируют push и pull изменений.
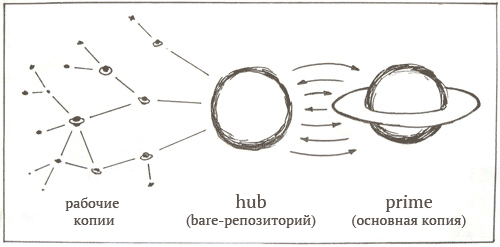
Итак, два репозитория:
- Hub — bare-репозиторий. Все репозитории разработчиков клонируются именно от него.
- Prime — обычный репозиторий. Сайт запускается из рабочего каталога этого репозитория.
Работа с двумя репозиториями простая и очень гибкая. Удалённые копии, имеющие ssh-доступ могут легко обновлять live-версию сайта просто выполнив push в Hub-репозиторий. Любые изменения, выполненные в live-версии на сервере мгновенно вливаются в Hub при коммите. В общем, всё работает очень просто — и неважно, где делаются изменения.
Небольшие приготовления перед стартом
Естественно, в первую очередь нужно, что бы Git был установлен на сервере и на всех компах разработчиков. Если на вашем shared-хостинге не установлен Git — вы очень легко можете это исправить (en).
Если вы первый раз работаете с Git на своём сервере, не забудьте указать глобальные настройки. Я указываю особое значения для user.name, чтобы потом видеть в истории проекта изменения, выполненные на сервере:
$ git config --global user.name "Джо, фигачу на сервере"
Поехали!
В первую очередь создадим новый git-репозиторий в live-каталоге нашего сайта, а затем добавим и зафиксируем все файлы сайта. Это будет Prime-репозиторий и рабочая копия. Даже если уже есть история проекта в других местах, содержимое сайта будет базовой точкой, в которую потом будут слиты все остальные копии.
$ cd ~/www
$ git init
$ git add .
$ git commit -m "Импорт всех существующих файлов сайта"
Поскольку мы сделали инициализацию репозитория в рабочей копии – нет нужды отключать сайт на обслуживание и повторно выкладывать все файлы, Git просто содаст репозиторий из имеющихся файлов.
Теперь, когда наш сайт уже находится в Git, создадим bare-репозиторий где-нибудь вне рабочего каталога сайта.
$ cd
$ mkdir site_hub.git
$ cd site_hub.git
$ git --bare init
Initialized empty Git repository in /home/joe/site_hub.gitУра! Снова вернёмся в рабочий каталог сайта и добавим Hub как удалённый репозиторий, а затем вольём в Hub содержимое ветки master из Prime-репозитория.
$ cd ~/www
$ git remote add hub ~/site_hub.git
$ git remote show hub
* remote hub
URL: /home/joe/site_hub.git
$ git push hub masterХуки
Как я уже упоминал в начале, Hub и Prime синхронизируются между собой, используя два простых скрипта.
Одно из основных правил при работе с Git — никогда не делайте push в репозтирий, у которого есть рабочая копия. Мы следуем этому правилу и создали репозиторий «Hub». Вместо того, чтобы делать push из Hub, который никак не повлияет на рабочую копию, мы будем использовать хук, который заставит Prime выполнить pull из Hub-репозитория.
Post-update — в Hub-репозитории
Как только в Hub поступит новая порция изменений, сразу будет выполнен этот скрипт. Мы переходим в рабочий каталог Prime-репозитория, и вытягиваем измениния из Hub'а. Проталкивание изменений (push) не изменяет состояния рабочего каталога репозитория, поэтому и нужно делать pull, находясь в рабочем каталоге.
#!/bin/sh
echo
echo "**** Вытягиваем изменения в Prime [Hub's post-update hook]"
echo
cd $HOME/www || exit
unset GIT_DIR
git pull hub master
exec git update-server-infoPost-commit — в Prime-репозитори
Этот скрипт запускается после каждого коммита в Prime-репозитории и проталкивает изменения в Hub. В идеальном мире, конечно, мы вообще никогда ничего не будем править прямо на сервере. Но в нашем несовершенном мире возможно всё, что угодно, поэтому давайте автоматизируем процесс проталкивания изменений, чтобы не разрушать историю проекта и избежать возможных конфликтов.
#!/bin/sh
echo
echo "**** pushing changes to Hub [Prime's post-commit hook]"
echo
git push hubИтак, используя этот хук, мы сразу же получаем в Hub-репозитория все изменения, выполненные в master-ветке Prime-резпозитория. Прочие ветки также можно клонировать, но они не будут влиять на сайт. Поскольку все удалённые копии получают доступ через SSH-адрес к Hub, то выполнить push и запустить обновление сайта напрямую могут только пользователи, имеющие прямой доступ к shell'у.
Конфликты
«Положить» сайт при такой системе синхронизации двух репозиториев очень сложно. Каждое изменение, сделанное в Prime автоматически попадает в Hub и все конфликты будут сразу видны при попытке выполнить push из клонов репозитория.
Но всё же есть несколько ситуаций, при которых состояние Prime может отличаться от Hub'а, и для исправления ситуации потребуется выполнить несколько дополнительных телодвижений. Если мы что-то правим на Prime и не зафиксировали изменения, а в этот момент сработает post-update в Hub, то все завершится ошибкой с сообщением «Entry ‘foo’ not uptodate. Cannot merge.». Фиксация изменений в рабочем каталоге Prime позволит зачистить его состояние, и post-update хук сможет соединить все неотправленные изменения.
Также я обнаружил, что если конфликт возникает вследствие того, что изменения в Prime не могут быть объединены с Hub'ом, то наилучшим решением будет протолкнуть текущее состояние Prime'а в новую ветку на Hub. Эта команда, выполненная из рабочего каталога Prime создаст удалённую ветку «fixme», основанную на текущем стоянии Prime-репозитория.
$ git push hub master:refs/heads/fixmeКак только изменения окажутся в Hub'е, мы сможем получить ветку в любом из клонов, разрешить конфликт и смержить ветки. Попытка разрешить конфликт прямо на сервере почти наверняка приведёт к проблемам в работе сайте из-за появления маркеров конфликтных областей.
Держим всё в чистоте
Каталог .git Prime-репозитория находится в корневом каталоге сайта, и, верояно, доступен для публичного доступа. Чтобы никто не смог сунуть свой нос, куда не следует, добавьте эти строки в файл .htaccess верхнего уровня:
# deny access to the top-level git repository:
RewriteEngine On
RewriteRule \.git - [F,L]Прим. переводчика: есть и другие способы закрыть доступ к каталогу на сервере.
Прочие проблемы
Если при попытке выполнить push в репозиторий на сервере вы видите эту ошибку:
git-receive-pack: command not found
fatal: The remote end hung up unexpectedly
В этом случае просто добавьте
export PATH=${PATH}:~/bin в ваш файл .bashrc, лежащий на сервере.