Речь пойдет о том, как был реализован быстрый поиск по большим объемам данных на этой страничке. Там можно искать пароль по хешу, для игрового сервера PvPGN, и генерировать эти же хеши.
Поиск написан на чистом PHP, без использования модулей и сторонней БД. В принципе, таким образом можно наращивать объемы до многих терабайт, было бы место — скорость от этого не сильно пострадает.
Далее от начала до конца описан весь процесс, который включает в себя брутфорс, создание хеш таблицы, её сортировка и, собственно, поиск.
Чтобы нельзя было составить хеш таблицу для поиска паролей, при создании пароль должен смешиваться с солью. Но, имея список хешей и зная, как добавляется соль, несложные пароли всё-равно можно найти полным перебором.
Хеш в PvPGN генерируется без соли, поэтому, и появилась идея сгенерировать большую таблицу ключ-значение (хеш-пароль).
Я приведу простейший пример брутфорса на C#, перебирающий пароли для поиска MD5 хеша. А генерация несортированной таблицы сводится к простому складыванию сгенерированных данных в файл вида CSV.
Пример с исходником по ссылке.
Запускать: BruteForce.exe [искомый_хеш] [длина_пароля] [символы_пароля]
Теперь нужно было отсортировать данные по хешу, поскольку итоге будет использоваться будет бинарный поиск, который работает только с сортированными данными.
Недолго думая я импортировал тестовые 5 гб данных в MySQL у себя на компе. Индекс не создавал, просто запросом запустил сортировку с экспортом в CSV:
Ему понадобилось 16 часов времени, а пока это делалось, в папке TEMP создались 2 файла: 16 и 25 гигабайт.
Но даже с индексом (который создавался пару часов) такой вариант всё-равно меня не устроил, хотя бы из-за поглощаемых гигабайтов при сортировке, т.к. при увеличении размера таблиц на моем диске просто не хватило бы места.
Я пробовал сделать таблицу в SQLite, но он не предназначен для больших объемов, поэтому работал очень медленно (в 1 гб поиск по хешу выполнялся около 6 секунд). MySQL быстрее, но в обоих вариантах не устраивал конечный размер, который был почти в 2 или более раз больше исходных данных (вместе с индексом).
Так как я ни разу не занимался сортировкой больших данных (без загрузки всего файла в память), то взял первый попавшийся алгоритм — "сортировка пузырьком" :). Написал небольшой код на C#, чтобы файл сортировался сам в себе, и запустил на ночь пробу на 500 мегабайтах. На следующий день файл всё ещё сортировался. Оно и понятно — ведь если самая меньшая запись находится в конце файла, то с таким алгоритмом она будет двигаться вниз по одной строчке, и для каждого такого сдвига нужно пройти весь файл от начала до конца!
Стал искать другие методы сортировки, подходящими оказались слияние и пирамида. Начал уже реализовывать их гибрид, но случайно нашел информацию об утилите sort, которая по-умолчанию идет с Windows, начиная с XP. Как оказалось, она идеально подходила под мою задачу! Не знаю, как она работает, но в описании написано, что сортирует файл за один проход (5 гб отсортировались за полчаса). В процессе сортировки утилита требует столько же дополнительного свободного места, сколько весит исходный файл (для временного файла).
Но и тут все было не все гладко. Когда сортировался файл 190 гб, ей понадобилось в 3 раза больше места, и я начал что-то искать и удалять, чтобы освободить место на диске. Помимо этого, в конечном файле появились непонятные «артефакты»:
Они оказались, примерно, в 10-ти в случайных частях файла. Я запускал сортировку несколько раз, ожидая каждый раз по 24 часа, но артефакты всё-равно появлялись. Я не понял, почему так произошло, у меня 12 гб ОЗУ, Win7 x64, на тот момент комп проработал неделю без выключения. Могу предположить, что память за это время «засорилась», т.к. после перезагрузки системы та же самая сортировка с первого раза прошла успешно.
Теперь это кажется глупо, но раньше мне всегда казалось, что поиск по файлам можно осуществлять только загрузив весь файл в память, либо читая весь файл построчно. Попробовав бинарный поиск в большом файле на практике, и увидев, насколько быстро это работает, да ещё и на PHP, — для меня это оказалось маленьким открытием. Такой поиск может работать столь же быстро с мега большими объемами данных, причем, не нагружая процессор и не съедая память.

Бинарный (он же двоичный) поиск работает по следующему принципу:
И, конечно же, главное условие бинарного поиска — массив должен быть отсортирован по поисковому ключу.
В файле бинарный поиск работает точно так же. Позицию смещения (offset) перемещаем в середину файла функцией fseek и корректируем позицию в начало строки (на случай, если попали в середину записи), затем полностью считать находящуюся там запись.
На этом можно было бы и остановиться, если бы не одно НО…
Поиск оказался невозможным по файлам, превышающих значение PHP_INT_MAX (2147483647 байт). Причем, иногда функция fseek возвращает -1, а иногда у нее все нормально, но смещение устанавливается непонятно куда. В итоге читается совсем не то, что нужно. Баг был неочевиден, но в процессе поиска проблемы нашел инфу в багтрекере. Ещё на сайте документации PHP к функции fseek есть комментарий как искать по файлам больше 2 гб (функция fseek64). Она сводится к чтению не с начала файла, а с текущего смещения, до необходимого места, итерацией. Но я проверил, это тоже не работает.
Пришлось разбивать файлы по частям. Я не нашел подходящей утилиты для разбивки файла (наверное, плохо искал, но на первой странице поиска были только сомнительные инсталляции). В арсенале Windows, как ни странно, такой утилиты нету. В тоталкомандере нельзя разбить по байтам, а мне нужна была точность.
Я написал на C# простенькую утилиту, читающую исходный файл по байтам и складывающую их последовательно в отдельные файлы заданного размера.
Может кому и понадобиться, качать с исходниками отсюда.
Запускать: Split.exe [файл] [размер_в_байтах]
Для начала, отсортированные данные я разделил в два отдельных файла: .hash, .pass, в которых хранятся хеши и пароли к ним, соответственно. Затем, все данные я просто «запаковал» в хекс. Числа легко пакуются таким образом до 2х раз, а так как длина каждого значения фиксированая, то в недостающий промежуток добавляется 0xF.
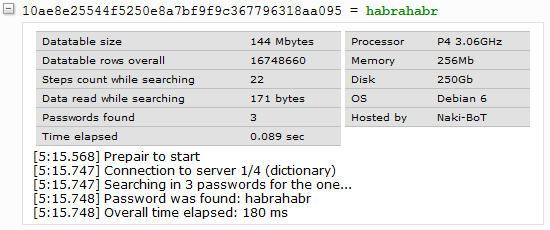
Каким образом сделано сжатие, и то, как происходит поиск, наглядно видно на следующем примере (ищем пароль для хеша 0dd5eac5b02376a456907c705c6f6fb0b5ff67cf):

Затем я разбил файл .pass по частям таким образом, чтобы пароли не обрезались в конце файла, и не выходили за границу PHP_INT_MAX: 2147483647 — (2147483647 % размерпароля) байт.
Максимальный размер файла .hash получился 185 мб, и его разбивать не пришлось.
Фактически, сейчас поиск осуществляется только в .hash файлах, а из .pass подгружаются только пароли (из определенной позиции в файле). Но это не отменяет главной темы этой статьи, я проверял на необработанных данных скорость была никак не ниже.
Все необработанные файлы весили 260 гб, а после сжатия получилось 70 гб. Этот размер включает в себя пароли от 1 до 6 символов из цифр с буквами, и от 7 до 10 символов — только цифры, всего около 13,5 млрд. паролей. Позже я добавил ещё 100 млн. словарных слов. В итоге, около 90% паролей с реального PvPGN сервера должны находиться (с моего бывшего сервера PvPGN нашлось 93,5%).
Один хороший человек портировал хеш функцию PvPGN'а с PHP на JavaScript (он же предоставил мне виртуальный сервер с 250 гб места под таблицы).
Я сделал замеры производительности разных реализаций хеша:

Реализации на разных языках доступны для загрузки harpywar.pvpgn.pl/?do=hash
Очевидно, что на Си быстрее всего. Во всех браузерах скорость примерно одинаковая, хотя Firefox подвисает на время выполнения скрипта.
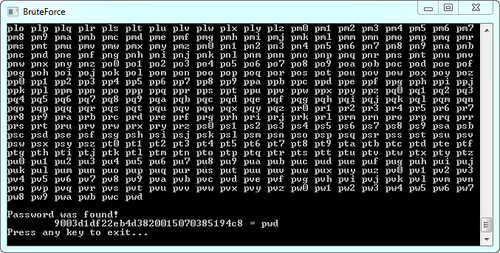
Оказалось, мой поиск притормаживал из-за PHP. Поэтому, сразу после тестирования, я решил отправлять клиенту в браузер эту ресурсоемкую задачу. Тем более, для клиента это будет совсем незаметно — в среднем сгенерировать требуется не более 1000 хешей за 1 поисковый запрос. Переделывать то, что уже было пришлось самую малость: найденные пароли нужно передавать клиенту в JSON массиве, а в браузере сделать итерацию паролей и генерацию из них хешей. Если сгенерированный хеш подходит под искомый, то пароль считается найденным.
Грубый, но наглядный пример того, как это работает, на скриншоте (на нем ещё несжатый файл):
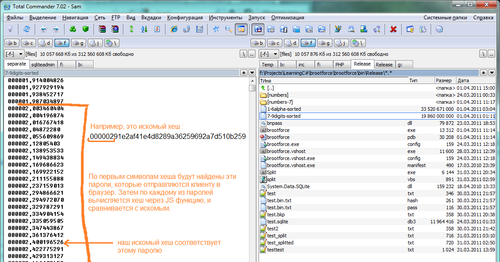
Вероятно, есть и другие способы поиска в больших массивах данных, или даже готовые решения. Но для конкретной задачи моя реализация получилась очень быстрой, и что очень важно — довольно компактной. Я потратил на это около недели, включая фоновую генерацию и сортировку таблиц.
Наверное, это не самый подходящий пример создания чего-либо, поскольку пароли с таким количеством символов перебираются относительно быстро, если код брутфорса распараллелить и портировать на GPU.
Но в процессе получил много знаний и экспириенса, чем и захотелось поделиться.
Update
— Выложил PHP исходники для интересующихся, но не имея файлов таблиц их изучение может быть неинтересным: index.php, hashcrack.class.php.
— Как пример, бинарный поиск в файле можно использовать для среза данных в больших логах (если нужно проанализировать статистику «от» и «до» определенной даты)
— С тоталкомандером я ошибся — с помощью него всё-таки можно точно по байтам разделить файл на части (подсказал Joshua5).
— Я не сильно знаком с особенностями различных БД, из-за чего поиск был долгим.
Alexey Pechnikov подсказывает, что на SQLite производительность может быть очень высокой, а для таблицы нужно было использовать «fts4». Вероятно, что-то похожее есть и в MySQL.
— Ниже в комментариях есть идеи, как можно было лучше организовать данные и поиск.
— Комментарий от webhamster полностью отражает то, что я хотел показать в этом топике
Поиск написан на чистом PHP, без использования модулей и сторонней БД. В принципе, таким образом можно наращивать объемы до многих терабайт, было бы место — скорость от этого не сильно пострадает.
Далее от начала до конца описан весь процесс, который включает в себя брутфорс, создание хеш таблицы, её сортировка и, собственно, поиск.
Bruteforce
Чтобы нельзя было составить хеш таблицу для поиска паролей, при создании пароль должен смешиваться с солью. Но, имея список хешей и зная, как добавляется соль, несложные пароли всё-равно можно найти полным перебором.
Хеш в PvPGN генерируется без соли, поэтому, и появилась идея сгенерировать большую таблицу ключ-значение (хеш-пароль).
Я приведу простейший пример брутфорса на C#, перебирающий пароли для поиска MD5 хеша. А генерация несортированной таблицы сводится к простому складыванию сгенерированных данных в файл вида CSV.
class Program
{
static bool _isFound = false;
static string _findHash;
static string _symbols;
static int _pass_lenght;
static void Main(string[] args)
{
_findHash = args[0]; // искомый хеш
_pass_lenght = int.Parse(args[1]); // длина взламываемого пароля
_symbols = args[2]; // набор символов в пароле
byte[] data = new byte[_symbols.Length];
Process(data, 0);
Console.ReadLine();
}
private static string hash;
private static byte[] data_trim;
private static string pass;
// рекурсивный метод
static void Process(byte[] data, int index)
{
// условие выхода из рекурсии
if (index == _pass_lenght)
{
data_trim = data.TakeWhile((v, idx) => data.Skip(idx).Any(w => w != 0x00)).ToArray(); // удалить в конце нули
pass = Encoding.ASCII.GetString(data_trim);
hash = GetHash(pass);
Console.Write("{0} ", pass);
if (hash == _findHash)
{
_isFound = true;
Console.WriteLine("\n\nPassword was found!\n\t{0} = {1}", hash, pass);
}
return;
}
// перебор всех вариантов
foreach (byte c in _symbols)
{
if (_isFound)
return;
data[index] = c;
Process(data, index + 1);
}
}
// возвращает md5 hash из пароля
static string GetHash(string value)
{
MD5 md5 = new MD5CryptoServiceProvider();
byte[] output = md5.ComputeHash(Encoding.ASCII.GetBytes(value));
return BitConverter.ToString(output).Replace("-", "").ToLower(); // hex string
}
}
Пример с исходником по ссылке.
Запускать: BruteForce.exe [искомый_хеш] [длина_пароля] [символы_пароля]

Сортировка
Теперь нужно было отсортировать данные по хешу, поскольку итоге будет использоваться будет бинарный поиск, который работает только с сортированными данными.
Недолго думая я импортировал тестовые 5 гб данных в MySQL у себя на компе. Индекс не создавал, просто запросом запустил сортировку с экспортом в CSV:
SELECT hash, pass INTO OUTFILE 'd:\\result.csv'
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY ''
LINES TERMINATED BY '\n'
FROM hashes ORDER BY hash
Ему понадобилось 16 часов времени, а пока это делалось, в папке TEMP создались 2 файла: 16 и 25 гигабайт.
Но даже с индексом (который создавался пару часов) такой вариант всё-равно меня не устроил, хотя бы из-за поглощаемых гигабайтов при сортировке, т.к. при увеличении размера таблиц на моем диске просто не хватило бы места.
Я пробовал сделать таблицу в SQLite, но он не предназначен для больших объемов, поэтому работал очень медленно (в 1 гб поиск по хешу выполнялся около 6 секунд). MySQL быстрее, но в обоих вариантах не устраивал конечный размер, который был почти в 2 или более раз больше исходных данных (вместе с индексом).
Так как я ни разу не занимался сортировкой больших данных (без загрузки всего файла в память), то взял первый попавшийся алгоритм — "сортировка пузырьком" :). Написал небольшой код на C#, чтобы файл сортировался сам в себе, и запустил на ночь пробу на 500 мегабайтах. На следующий день файл всё ещё сортировался. Оно и понятно — ведь если самая меньшая запись находится в конце файла, то с таким алгоритмом она будет двигаться вниз по одной строчке, и для каждого такого сдвига нужно пройти весь файл от начала до конца!
Стал искать другие методы сортировки, подходящими оказались слияние и пирамида. Начал уже реализовывать их гибрид, но случайно нашел информацию об утилите sort, которая по-умолчанию идет с Windows, начиная с XP. Как оказалось, она идеально подходила под мою задачу! Не знаю, как она работает, но в описании написано, что сортирует файл за один проход (5 гб отсортировались за полчаса). В процессе сортировки утилита требует столько же дополнительного свободного места, сколько весит исходный файл (для временного файла).
Но и тут все было не все гладко. Когда сортировался файл 190 гб, ей понадобилось в 3 раза больше места, и я начал что-то искать и удалять, чтобы освободить место на диске. Помимо этого, в конечном файле появились непонятные «артефакты»:
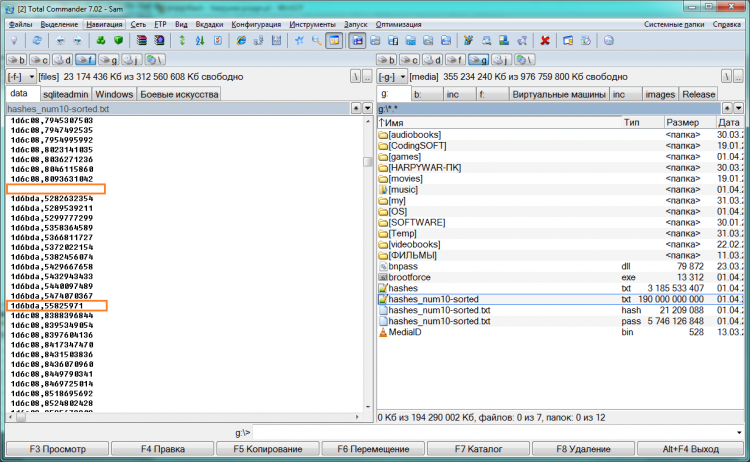
Они оказались, примерно, в 10-ти в случайных частях файла. Я запускал сортировку несколько раз, ожидая каждый раз по 24 часа, но артефакты всё-равно появлялись. Я не понял, почему так произошло, у меня 12 гб ОЗУ, Win7 x64, на тот момент комп проработал неделю без выключения. Могу предположить, что память за это время «засорилась», т.к. после перезагрузки системы та же самая сортировка с первого раза прошла успешно.
Поиск
Теперь это кажется глупо, но раньше мне всегда казалось, что поиск по файлам можно осуществлять только загрузив весь файл в память, либо читая весь файл построчно. Попробовав бинарный поиск в большом файле на практике, и увидев, насколько быстро это работает, да ещё и на PHP, — для меня это оказалось маленьким открытием. Такой поиск может работать столь же быстро с мега большими объемами данных, причем, не нагружая процессор и не съедая память.

Бинарный (он же двоичный) поиск работает по следующему принципу:
- Массив делится на 2 половины и позиция чтения перемещается в середину.
- Текущее значение, которое найдено посередине, сравнивается с искомым
- Если искомое > текущего, то берется вторая половина массива, если искомое < текущего — первая половина.
- Проделываем 1 по 3 шаг с данной половиной массива.
И, конечно же, главное условие бинарного поиска — массив должен быть отсортирован по поисковому ключу.
В файле бинарный поиск работает точно так же. Позицию смещения (offset) перемещаем в середину файла функцией fseek и корректируем позицию в начало строки (на случай, если попали в середину записи), затем полностью считать находящуюся там запись.
На этом можно было бы и остановиться, если бы не одно НО…
Деление
Поиск оказался невозможным по файлам, превышающих значение PHP_INT_MAX (2147483647 байт). Причем, иногда функция fseek возвращает -1, а иногда у нее все нормально, но смещение устанавливается непонятно куда. В итоге читается совсем не то, что нужно. Баг был неочевиден, но в процессе поиска проблемы нашел инфу в багтрекере. Ещё на сайте документации PHP к функции fseek есть комментарий как искать по файлам больше 2 гб (функция fseek64). Она сводится к чтению не с начала файла, а с текущего смещения, до необходимого места, итерацией. Но я проверил, это тоже не работает.
Пришлось разбивать файлы по частям. Я не нашел подходящей утилиты для разбивки файла (наверное, плохо искал, но на первой странице поиска были только сомнительные инсталляции). В арсенале Windows, как ни странно, такой утилиты нету. В тоталкомандере нельзя разбить по байтам, а мне нужна была точность.
Я написал на C# простенькую утилиту, читающую исходный файл по байтам и складывающую их последовательно в отдельные файлы заданного размера.
Может кому и понадобиться, качать с исходниками отсюда.
Запускать: Split.exe [файл] [размер_в_байтах]
Сжатие
Для начала, отсортированные данные я разделил в два отдельных файла: .hash, .pass, в которых хранятся хеши и пароли к ним, соответственно. Затем, все данные я просто «запаковал» в хекс. Числа легко пакуются таким образом до 2х раз, а так как длина каждого значения фиксированая, то в недостающий промежуток добавляется 0xF.
Каким образом сделано сжатие, и то, как происходит поиск, наглядно видно на следующем примере (ищем пароль для хеша 0dd5eac5b02376a456907c705c6f6fb0b5ff67cf):

0D D5 EA — первые 6 символов хеша. Таким образом будут повторяющиеся хеши, но их получается не так много. А поскольку пароли все сохранены, то даже из тысячи паролей можно очень быстро восстановить исходный хеш.70 FF — здесь запаковано число 70, это количество паролей, которое содержится в файле digits.pass для хешей, начинающихся на 0dd5ea59 99 95 68 FF FF — здесь запаковано число 59999568, это позиция начала чтения паролей в файле digits.pass11a19a90 — позиция, с которой начинается чтение 70-ти паролей в файле digits.pass; она вычисляется так: 59999568 * 5 (длина любого пароля, уже сжатого, в байтах) = 299997840 (переводим в hex)84 04 05 38 8F — здесь запаковано число 840405388, это и есть пароль, соответствующий искомому хешуЗатем я разбил файл .pass по частям таким образом, чтобы пароли не обрезались в конце файла, и не выходили за границу PHP_INT_MAX: 2147483647 — (2147483647 % размерпароля) байт.
Максимальный размер файла .hash получился 185 мб, и его разбивать не пришлось.
Фактически, сейчас поиск осуществляется только в .hash файлах, а из .pass подгружаются только пароли (из определенной позиции в файле). Но это не отменяет главной темы этой статьи, я проверял на необработанных данных скорость была никак не ниже.
Все необработанные файлы весили 260 гб, а после сжатия получилось 70 гб. Этот размер включает в себя пароли от 1 до 6 символов из цифр с буквами, и от 7 до 10 символов — только цифры, всего около 13,5 млрд. паролей. Позже я добавил ещё 100 млн. словарных слов. В итоге, около 90% паролей с реального PvPGN сервера должны находиться (с моего бывшего сервера PvPGN нашлось 93,5%).
Маленькая оптимизация
Один хороший человек портировал хеш функцию PvPGN'а с PHP на JavaScript (он же предоставил мне виртуальный сервер с 250 гб места под таблицы).
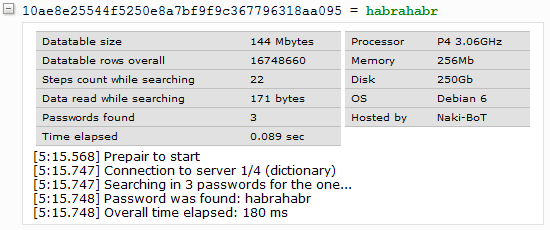
Я сделал замеры производительности разных реализаций хеша:

Реализации на разных языках доступны для загрузки harpywar.pvpgn.pl/?do=hash
Очевидно, что на Си быстрее всего. Во всех браузерах скорость примерно одинаковая, хотя Firefox подвисает на время выполнения скрипта.
Оказалось, мой поиск притормаживал из-за PHP. Поэтому, сразу после тестирования, я решил отправлять клиенту в браузер эту ресурсоемкую задачу. Тем более, для клиента это будет совсем незаметно — в среднем сгенерировать требуется не более 1000 хешей за 1 поисковый запрос. Переделывать то, что уже было пришлось самую малость: найденные пароли нужно передавать клиенту в JSON массиве, а в браузере сделать итерацию паролей и генерацию из них хешей. Если сгенерированный хеш подходит под искомый, то пароль считается найденным.
Грубый, но наглядный пример того, как это работает, на скриншоте (на нем ещё несжатый файл):
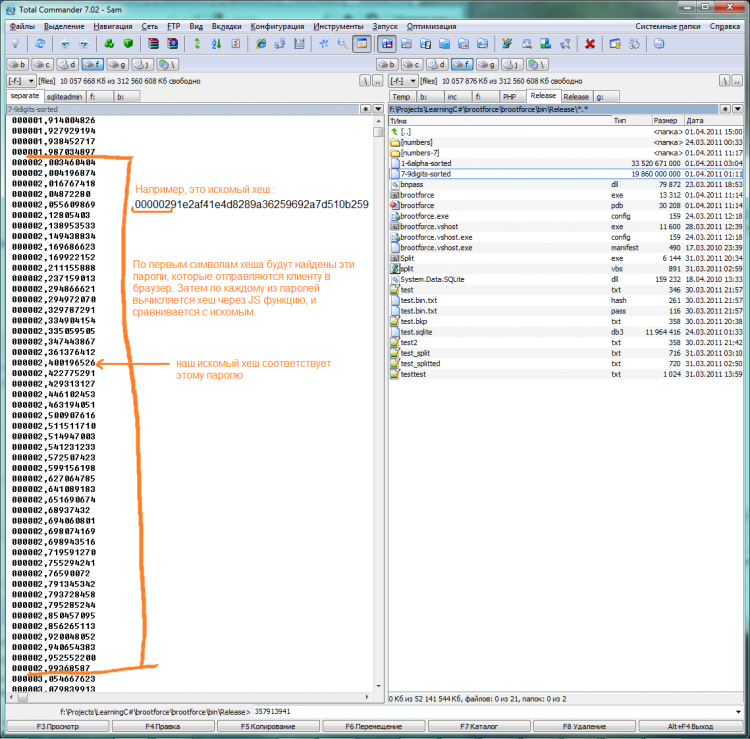
Итог
Вероятно, есть и другие способы поиска в больших массивах данных, или даже готовые решения. Но для конкретной задачи моя реализация получилась очень быстрой, и что очень важно — довольно компактной. Я потратил на это около недели, включая фоновую генерацию и сортировку таблиц.
Наверное, это не самый подходящий пример создания чего-либо, поскольку пароли с таким количеством символов перебираются относительно быстро, если код брутфорса распараллелить и портировать на GPU.
Но в процессе получил много знаний и экспириенса, чем и захотелось поделиться.
Update
— Выложил PHP исходники для интересующихся, но не имея файлов таблиц их изучение может быть неинтересным: index.php, hashcrack.class.php.
— Как пример, бинарный поиск в файле можно использовать для среза данных в больших логах (если нужно проанализировать статистику «от» и «до» определенной даты)
— С тоталкомандером я ошибся — с помощью него всё-таки можно точно по байтам разделить файл на части (подсказал Joshua5).
— Я не сильно знаком с особенностями различных БД, из-за чего поиск был долгим.
Alexey Pechnikov подсказывает, что на SQLite производительность может быть очень высокой, а для таблицы нужно было использовать «fts4». Вероятно, что-то похожее есть и в MySQL.
— Ниже в комментариях есть идеи, как можно было лучше организовать данные и поиск.
— Комментарий от webhamster полностью отражает то, что я хотел показать в этом топике
