
События прошедшего лета, связанные с утечками конфиденциальных данных в поисковые системы, прямо или косвенно коснулись каждого, кто следит за новостями, любезно предоставляемыми СМИ. Под «системный нож» попали поисковые роботы и персональные данные гражданина РФ. Копнем немного глубже и выясним, каким образом частная жизнь может оказаться «у всех на виду».
В самый разгар летнего периода СМИ наперебой делились новостью об утечке информации с веб-страниц, содержащих тексты СМС пользователей одного из крупнейших сотовых операторов. Среди множества хитрозакрученных и более-менее адекватных версий, касающихся причин данного факта, наконец-то всплыла мысль, которая была подкреплена результатами исследования. Участник форума rdot.org под псевдонимом «C3~RET» опубликовал небольшую исследовательскую работу, которой, тем самым, задал еще один, довольно хороший вектор для новых публикаций в средствах массовой информации.
В то же время, пока исследователи отделяли «мух от котлет», диггеры составляли все больше и больше поисковых дорков, компрометирующих владельцев веб-ресурсов, которые обрабатывали персональные данные, а также владельцев поисковых систем, которые якобы эти данные нещадно консолидировали на своих серверах. Среди примеров подобных утечек можно привести попадание в кэш поисковых систем следующей информации:
1) персональных данных покупателей интим-магазинов;
2) документов, имеющих гриф «для служебного пользования»;
3) удаленных фотографий социальной сети «ВКонтакте»;
4) персональные данные покупателей РЖД-билетов.
Ситуация на поверхности
А был ли на самом деле инцидент? Прямое столкновение между веб-ресурсами и поисковой системой, красиво описанное «отделом пропаганды», на самом деле представляет собой лишь продемонстрированную широким массам технику «Google Hacking» только на примере другой поисковой системы.

Остро стал освещаться всем известный факт: документированный функционал поискового робота запрещает ему индексировать страницы, не содержащиеся в специальном файле «robots.txt» в корневой веб-ресурса или же имеющий специальный HTML-тег «noindex», который, кстати говоря, предложен компанией Яндекс. Однако если бы только «козел отпущения» в лице Яндекса использовал исключительно документированные средства индексации, то, возможно, шумиха быстро прекратилась бы, и данный материал не вышел бы в свет…
В поисках истины
Ключевые выводы исследователей и предварительная версия причин инцидента, связанного прежде всего с утечкой СМС в кэш поисковой системы, формулируются примерно так: на стороне клиента шлюза отправки коротких сообщений установленное расширение к браузеру от компании-разработчика поисковой системы провоцировало передачу всех данных пользователя на сторону этой самой поисковой системы. Беглый осмотр исходного кода веб-страницы СМС-шлюза, которую любезно предоставил кэш Google’a после того, как сотовый оператор временно закрыл доступ к шлюзу, позволил убедиться, что на указанной странице, с которой проводилась отправка сообщений, содержался JavaScript-код, являющийся частью сервиса «Яндекс.Метрика», представляющий собой инструмент для веб-мастеров и предназначенный для формирования статистических данных о посетителях веб-страницы. Таким образом, перед нами появляется еще один потенциальный канал утечки конфиденциальной информации в кэш поисковой системы «Яндекс».
Знакомство с пользовательским соглашением окончательно высаживает параноика на измену в следующем пункте:
«8. … Функция записи Сессий посещений работает полностью в автоматическом режиме и не умеет анализировать содержание и смысл информации размещённой на страницах и вводимой третьими лицами (посетителями) в поля на страницах сайта Пользователя, а записывает её полностью независимо от содержания. ...»
Другими словами: пользователь понимает, что скрипт Яндекс.Метрики записывает все без разбора. Наша задача, определить конкретно, что именно.
Для проверки этой гипотезы были созданы три страницы, содержащие упомянутый JavaScript и уникальный текст с целью последующей их идентификации в поисковой выдаче. Первая страница вида defeсtech.ru/p4ste3stOfYa являлась открытой для поискового Yandex-робота. Другая — defectech.ru/4tom1cprOfit занесена в файл robots.txt. Адреса страниц исключают возможность подбора ссылок, если данный функционал имеется в наличии поискового бота (что позволит нам рассуждать о том, имело ли место так называемое интеллектуальное сканирование в рассматриваемом инциденте). С целью более оперативного уведомления бота о появившейся публичной странице (defectech.ru/p4ste3stOfYa) ссылка на нее разместилась на корневой странице (defectech.ru).
Два дня спустя. Утешительные для нас результаты: размещение JS-кода никоим образом не отразилось на индексации закрытых для поисковых ботов страниц. Более того, индексация публичных страниц также не выполнена, что может говорить исключительно о крайне малых сроках присутствия тестовых страниц в периметре Всемирной Паутины, что не позволило поисковому роботу дотянуться до уникальных данных. Тем не менее, сам код аналитической системы для веб-разработчика не спровоцировал индексацию страниц, а значит, как минимум, на данном этапе он не может являться каналом утечки данных в поисковую систему. Согласно заявлению представителей Яндекс после выявления факта утечки в «Яндекс.Метрику» внесены соответствующие исправления (http://bit.ly/qFtSs5 — комментарии представителей поисковой системы). Детали не уточняются. Двигаемся дальше.
Не одним Яндексом полнится множество поисковых систем, по этой причине было принято решение о поверхностном осмотре действий аналогичного JS-кода от Google. Беглый осмотр логов снифера показал результаты активности данного скрипта, которая заключается в передачи на сервис Google Analytics статистической информации о действиях пользователя. Среди этой информации находится и адрес страницы, на которой размещен код, а это означает, что Google, как минимум «знает» о наличии данной страницы (код используется для формирования статистики, отображаемой Гуглом на веб-панели администратора ресурса, но кто знает, куда еще уходят данные).
Эффект газового разряда
В результате анализа поведения дополнительного программного обеспечения, предоставляемого разработчиками поисковых систем в виде расширений для браузеров, было выявлена сторонняя активность этих самых расширений, которая может привести к утечкам информации третьим лицам. Масштабы эффекта, инициализирующего канал утечки конфиденциальных данных, визуально можно представить, если провести аналогию с эффектом газового распада. Не залезая в дебри точных наук посмотрим на картинку, демонстрирующую процесс этого распада: под действием сторонней силы группа элементарных частиц сталкивается с группой других элементарных частиц; те, в свою очередь, совершают аналогичные столкновения и в результате мы видим лавинообразный эффект. В нашем случае, элементарными частицами выступает конфиденциальная информация или ее часть, которая по каналам утечки попадает в различные уголки сети и в итоге становится общедоступной в силу своей распространенности. Таким образом, обезличенные персональные данные в результате попадания в поисковые системы могут однозначно идентифицировать своего владельца.

Рассмотрим подробнее каналы утечки данных, которые открывают указанные выше расширения для пользовательских браузеров от разработчиков поисковых систем на примере «Яндекс.Бар» и «Google.Toolbar».
Исследуя активность Google Toolbar, в логах снифера можно также заметить строку, в которой на один из сервисов Гугла отправляется адрес текущей страницы пользователя. Более того, если не осуществлять никаких действий в браузере, можно заметить фоновую активность плагина: с определенной периодичность производится обращение к одному из сервисов Гугла с наводящим на мысль названием «safebrowsing». Периодичность обращений обусловлена тем, что плагин отправляет достаточно объемные данные.

Фоновая активность Google Toolbar.
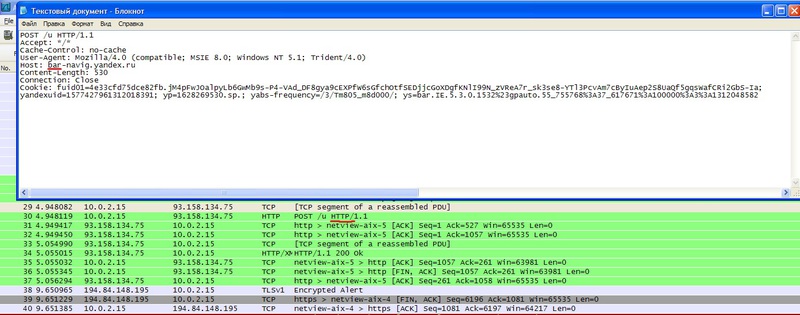
Яндекс.Бар параллельно передает данные по HTTP несмотря на передачу данных по HTTPS-соединению.
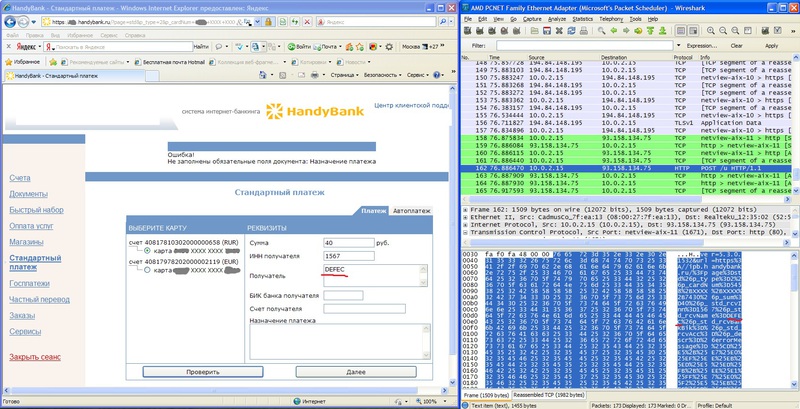
Переключаем свое внимание на аналогичный продукт от Яндекса. Чтобы результаты исследования были «погорячее», рассмотрим поведение плагина в боевых условиях: совершим платежную операцию в распространенной системе интернет банкинга «HandyBank», установленной у одного из крупных российских банков.
Классика жанра: плагин передает адрес страницы на сервис поисковой системы. Вводим детали платежной операции и жмем «Далее». Скрипт системы интернет-банкинга передает всю введенную информацию в GET-запросе и это провоцирует передачу конфиденциальной информации на сервис Яндекса. Косяк… Причем, со стороны вендора системы.
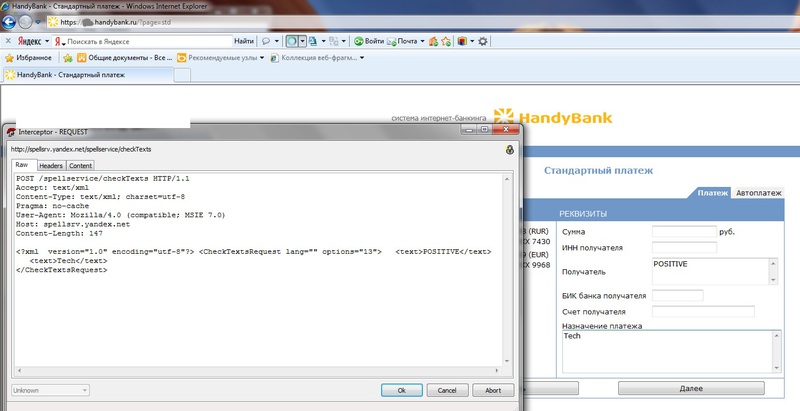
«Яндекс.Бар» помимо быстрого поиска предоставляет возможность проверки орфографии данных, введенных пользователем на текущей странице. Активируем данную опцию и что мы видим: плагин передает всю информацию о деталях платежной операции в специально составленном XML-файле на сервис проверки орфографии от Яндекса (структура этого файла хорошо видна на соответствующем скриншоте). И все это Я.Бар передает на свои сервера в обход HTTPS-соединения по незащищенному протоколу HTTP.
Глазами аналитика
Поисковые системы напоминают осьминога, пытающегося своими щупальцами достать до самых отдаленных хранилищ информации в пространстве Сети. Щупальца эти отнюдь не ограничиваются поисковыми ботами и представляют собой ничто иное, как различные плагины, инструменты веб-разработчика и прочие полезные сервисы, с одной стороны, любезно предоставляемые самими поисковыми системами с целью упростить жизнь конечным пользователям, а с другой ориентированными на упрощение процедуры индексации «всея Интернет».
Особое внимание к новости, которая послужила отправной точкой для наблюдения за деятельностью поисковых систем, вполне возможно косвенным образом вызвано событиями, развернувшимися вокруг ФЗ-152, изменения которого пошатнули российскую индустрию ИБ. Обнародованная СМС-переписка и поставленный в угол «Мегафон» — яркая демонстрация якобы плохой защищенности персональных данных, к которым, согласно обновленному определению, теперь относится почти любая информация, созданная существом человекоподобным. Но это уже другая история.
