В октябре на хабре появилась замечательная статья про работу HashMap. Продолжая данную тему, я собираюсь рассказать о реализации java.util.concurrent.ConcurrentHashMap.
Итак, как же появился ConcurrentHashMap, какие у него есть преимущества и как он был реализован.
До появления в JDK 1.5 реализации ConcurrentHashMap, существовало несколько способов описания хэш-таблиц.
Первоначально в JDK 1.0 был клас Hashtable. Hashtable — потокобезопасная и легкая в использовании реализация хэш-таблицы. Проблема HashTable заключалась, в первую очередь, в том, что при доступе к элементам таблицы производилась её полная блокировка. Все методы Hashtable были синхронизированными. Это являлось серьёзным ограничением для многопоточной среды, поскольку плата за блокировку всей таблицы была очень большой.
В JDK 1.2 на помощь Hashtable пришёл HashMap и его потокобезопасное представление — Collections.synchronizedMap. Причин для такого разделения было несколько:
Таким образом, c JDK 1.2 список вариантов реализации хэш-карт в Java пополнился ещё двумя способами. Однако эти способы не избавили разработчиков от появления в их коде race conditions, которые могли привести к появлению ConcurrentModificationException. В данной статье подробнее рассказано о возможных причинах их появления в коде.
И вот, в JDK 1.5 наконец появляется более производительный и масштабируемый вариант.
К моменту появления ConcurrentHashMap Java-разработчики нуждались в следующей реализации хэш-карты:
Doug Lea представляет вариант реализации такой структуры данных, которая включается в JDK 1.5.
Какие же основные идеи реализации ConcurrentHashMap?
В отличие от элементов HashMap, Entry в ConcurrentHashMap объявлены как volatile. Это важная особенность, также связанная с изменениями в JMM. Ответ Doug Lea о необходимости использования volatile и возможных race condition можно прочитать здесь.
В ConcurrentHashMap также используется улучшенная функция хэширования.
Напомню, какой она была в HashMap из JDK 1.2:
Версия из ConcurrentHashMap JDK 1.5:
В чём необходимость усложнения хэш-функции? Таблицы в хэш-карте имеют длину, определяемую степенью двойки. Для хэш-кодов, двоичные представления которых не различаются в младшей и старшей позиции, мы будем иметь коллизии. Усложнение хэш-функции как раз решает данную проблему, уменьшая вероятность коллизий в карте.
Карта делится на N различных сегментов (16 по умолчанию, максимальное значение может быть 16-битным и представлять собой степень двойки). Каждый сегмент представляет собой потокобезопасную таблицу элементов карты.
Между хэш-кодами ключей и соответствующими им сегментами устанавливается зависимость на основе применения к старшим разрядам хэш-кода битовой маски.
Вот как в карте хранятся элементы:
Рассмотрим, что же представляет из себя класс сегмента:
Учитывая псевдослучайное распределение хэшей ключей внутри таблицы, можно понять, что увеличение количества сегментов будет способствовать тому, что операции модификации будут затрагивать различные сегменты, что уменьшит вероятность блокировок во время выполнения.
Данный параметр влияет на использование картой памяти и количество сегментов в карте.
Посмотрим на создание карты и на то, как влияет заданный в качестве парамента конструктора concurrencyLevel:
Количество сегментов будет выбрано как ближайшая степень двойки, большая чем concurrencyLevel. Ёмкость каждого сегмента, соответственно, будет определяться как отношение округлённого до ближайшей большей степени двойки значения ёмкости карты по умолчанию, к полученному количеству сегментов.
Очень важно понимать две следующие вещи. Занижение concurrencyLevel ведёт к тому, что более вероятны блокировки потоками сегментов карты при записи. Завышение показателя ведёт к неэффективному использованию памяти.
Если лишь один поток будет изменять карту, а остальные будут производить чтение — рекомендуется использовать значение 1.
Необходимо помнить, что resize таблиц для хранения внутри карти — опреация, требующая дополнительного времени (и, зачастую, выполняемая не быстро). Поэтому при создании карты требуется иметь некоторые приблизительные оценки по статистике выполнения возможных операций чтения и записи.
На javamex можно найти статью о сравнении масштабируемости synchronizedMap и ConcurrentHashMap:
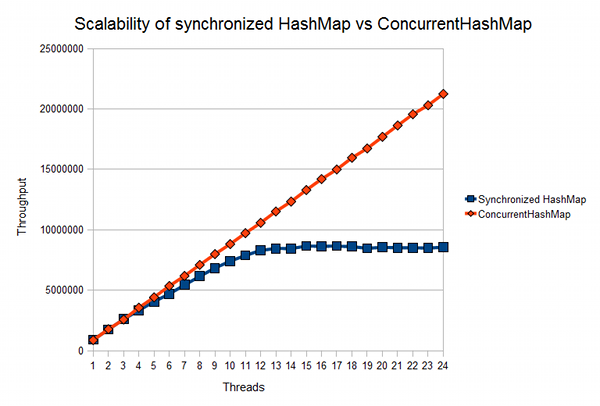
Как видно из графика, между 5 и 10 миллионами операций доступа к карте заметно серьёзное расхождение, что обуславливает эффективность применения ConcurrentHashMap в случае с высоким количеством хранимых данных и операций доступа к ним.
Итак, основные преимущества и особенности реализации ConcurrentHashMap:
В заключение хотелось бы сказать, что ConcurrentHashMap должен применяться грамотно, с предварительной оценкой соотношения чтения и записи в карту. Также по-прежнему имеет смысл использовать HashMap в программах, где нет множественного доступа от нескольких потоков к хранимой карте.
Спасибо за ваше внимание!
Полезные ресурсы по параллельным коллекциям в Java и, в частности, по работе ConcurrentHashMap:
Итак, как же появился ConcurrentHashMap, какие у него есть преимущества и как он был реализован.
Предпосылки к созданию ConcurrentHashMap
До появления в JDK 1.5 реализации ConcurrentHashMap, существовало несколько способов описания хэш-таблиц.
Первоначально в JDK 1.0 был клас Hashtable. Hashtable — потокобезопасная и легкая в использовании реализация хэш-таблицы. Проблема HashTable заключалась, в первую очередь, в том, что при доступе к элементам таблицы производилась её полная блокировка. Все методы Hashtable были синхронизированными. Это являлось серьёзным ограничением для многопоточной среды, поскольку плата за блокировку всей таблицы была очень большой.
В JDK 1.2 на помощь Hashtable пришёл HashMap и его потокобезопасное представление — Collections.synchronizedMap. Причин для такого разделения было несколько:
- Не каждый программист и не каждое решение нуждались в использовании потокобезопасной хэш-таблицы
- Программисту необходимо было дать выбор, какой вариант ему удобно использовать
Таким образом, c JDK 1.2 список вариантов реализации хэш-карт в Java пополнился ещё двумя способами. Однако эти способы не избавили разработчиков от появления в их коде race conditions, которые могли привести к появлению ConcurrentModificationException. В данной статье подробнее рассказано о возможных причинах их появления в коде.
И вот, в JDK 1.5 наконец появляется более производительный и масштабируемый вариант.
ConcurrentHashMap
К моменту появления ConcurrentHashMap Java-разработчики нуждались в следующей реализации хэш-карты:
- Потокобезопасность
- Отсутствие блокировок всей таблицы на время доступа к ней
- Желательно, чтобы отсутствовали блокировки таблицы при выполнении операции чтения
Doug Lea представляет вариант реализации такой структуры данных, которая включается в JDK 1.5.
Какие же основные идеи реализации ConcurrentHashMap?
1. Элементы карты
В отличие от элементов HashMap, Entry в ConcurrentHashMap объявлены как volatile. Это важная особенность, также связанная с изменениями в JMM. Ответ Doug Lea о необходимости использования volatile и возможных race condition можно прочитать здесь.
static final class HashEntry<K, V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K, V> next;
HashEntry(K key, int hash, HashEntry<K, V> next, V value) {
this .key = key;
this .hash = hash;
this .next = next;
this .value = value;
}
@SuppressWarnings("unchecked")
static final <K, V> HashEntry<K, V>[] newArray(int i) {
return new HashEntry[i];
}
}
2. Хэш-функция
В ConcurrentHashMap также используется улучшенная функция хэширования.
Напомню, какой она была в HashMap из JDK 1.2:
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
Версия из ConcurrentHashMap JDK 1.5:
private static int hash(int h) {
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
В чём необходимость усложнения хэш-функции? Таблицы в хэш-карте имеют длину, определяемую степенью двойки. Для хэш-кодов, двоичные представления которых не различаются в младшей и старшей позиции, мы будем иметь коллизии. Усложнение хэш-функции как раз решает данную проблему, уменьшая вероятность коллизий в карте.
3. Сегменты
Карта делится на N различных сегментов (16 по умолчанию, максимальное значение может быть 16-битным и представлять собой степень двойки). Каждый сегмент представляет собой потокобезопасную таблицу элементов карты.
Между хэш-кодами ключей и соответствующими им сегментами устанавливается зависимость на основе применения к старшим разрядам хэш-кода битовой маски.
Вот как в карте хранятся элементы:
final Segment<K, V>[] segments;
transient Set<K> keySet;
transient Set<Map.Entry<K, V>> entrySet;
transient Collection<V> values;
Рассмотрим, что же представляет из себя класс сегмента:
static final class Segment<K, V> extends ReentrantLock implements
Serializable {
private static final long serialVersionUID = 2249069246763182397L;
transient volatile int count;
transient int modCount;
transient int threshold;
transient volatile HashEntry<K, V>[] table;
final float loadFactor;
Segment(int initialCapacity, float lf) {
loadFactor = lf;
setTable(HashEntry.<K, V> newArray(initialCapacity));
}
...
}
Учитывая псевдослучайное распределение хэшей ключей внутри таблицы, можно понять, что увеличение количества сегментов будет способствовать тому, что операции модификации будут затрагивать различные сегменты, что уменьшит вероятность блокировок во время выполнения.
4. ConcurrencyLevel
Данный параметр влияет на использование картой памяти и количество сегментов в карте.
Посмотрим на создание карты и на то, как влияет заданный в качестве парамента конструктора concurrencyLevel:
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0
|| concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
segmentShift = 32 - sshift;
segmentMask = ssize - 1;
this .segments = Segment.newArray(ssize);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = 1;
while (cap < c)
cap <<= 1;
for (int i = 0; i < this .segments.length; ++i)
this .segments[i] = new Segment<K, V>(cap, loadFactor);
}
Количество сегментов будет выбрано как ближайшая степень двойки, большая чем concurrencyLevel. Ёмкость каждого сегмента, соответственно, будет определяться как отношение округлённого до ближайшей большей степени двойки значения ёмкости карты по умолчанию, к полученному количеству сегментов.
Очень важно понимать две следующие вещи. Занижение concurrencyLevel ведёт к тому, что более вероятны блокировки потоками сегментов карты при записи. Завышение показателя ведёт к неэффективному использованию памяти.
Как же выбрать concurrencyLevel?
Если лишь один поток будет изменять карту, а остальные будут производить чтение — рекомендуется использовать значение 1.
Необходимо помнить, что resize таблиц для хранения внутри карти — опреация, требующая дополнительного времени (и, зачастую, выполняемая не быстро). Поэтому при создании карты требуется иметь некоторые приблизительные оценки по статистике выполнения возможных операций чтения и записи.
Оценки масштабируемости
На javamex можно найти статью о сравнении масштабируемости synchronizedMap и ConcurrentHashMap:
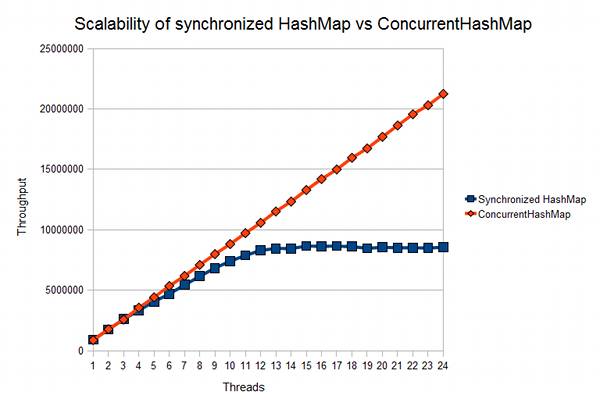
Как видно из графика, между 5 и 10 миллионами операций доступа к карте заметно серьёзное расхождение, что обуславливает эффективность применения ConcurrentHashMap в случае с высоким количеством хранимых данных и операций доступа к ним.
Итого
Итак, основные преимущества и особенности реализации ConcurrentHashMap:
- Карта имеет схожий с hashmap интерфейс взаимодействия
- Операции чтения не требуют блокировок и выполняются параллельно
- Операции записи зачастую также могут выполняться параллельно без блокировок
- При создании указывается требуемый concurrencyLevel, определяемый по статистике чтения и записи
- Элементы карты имеют значение value, объявленное как volatile
В заключение хотелось бы сказать, что ConcurrentHashMap должен применяться грамотно, с предварительной оценкой соотношения чтения и записи в карту. Также по-прежнему имеет смысл использовать HashMap в программах, где нет множественного доступа от нескольких потоков к хранимой карте.
Спасибо за ваше внимание!
Полезные ресурсы по параллельным коллекциям в Java и, в частности, по работе ConcurrentHashMap: