Привет всем еще раз! Я решил сразу попробовать выпустить две статьи, практически в одно время, чтобы не прерывать цепь повествования, т.к. начало данной статьи очень важно!
Итак, многие ждали примеры моей программы и объяснения ее работы с точки зрения написания кода. Я же рассказываю последовательно, чтобы каждый смог ее повторить у себя на компьютере. Обращайте внимание побольше на обильные комментарии в коде, в них сила! И не бойтесь мега-мелкого скролла, т.к. информации много. Передислоцируйтесь в место с хорошим интернетом, в статье много схем и фотографий!
В результате, в предыдущей части, был разработан шаблон проекта с подключенными нужными заголовками и с подцепленной библиотекой OpenCV. Давайте же посмотрим, какой тип работ предстоит еще сделать и как его сделать.
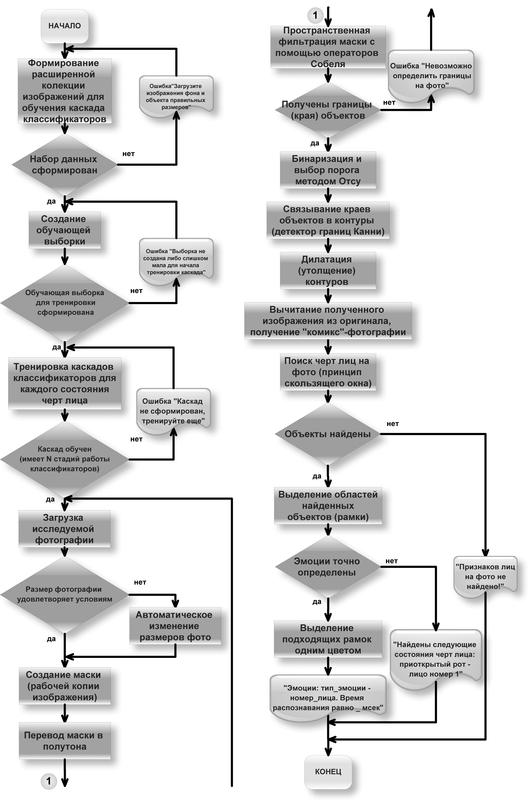
Также, по горячим следам, выяснилось, что можно набросать приблизительные схемы работ
стандартного
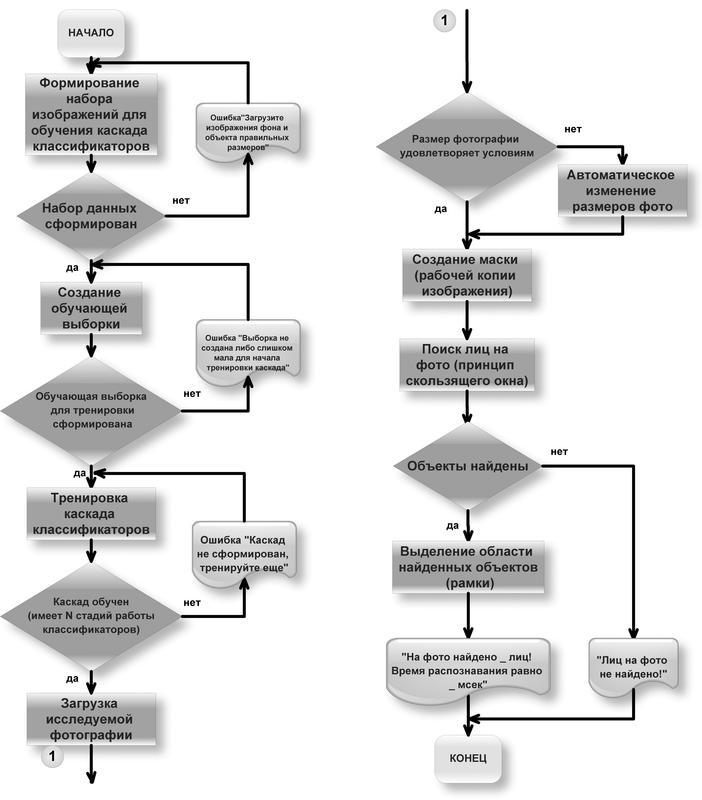
и модифицированного метода Виолы-Джонса по работе с фотографией.
Так как в модуле распознавания эмоций используются классификаторы, разработана последовательность действий по их обучению и тренировке.
Итак, для того чтобы обучить классификатор, потребуется:
• Подготовка средства разработки, подключение библиотеки OpenCV;
• Подготовка данных. Для использования пригодны:
— Тестовые наборы «позитивных» и «негативных» изображений (positive and negative images). «Позитивные» изображения содержат объект интереса (лицо, рот, нос и так далее),
«Негативные» изображения содержат только фон (background);
— .vec-файл, легко дополняемый, содержащий те же наборы изображений, только в уменьшенном размере;
— Базы уже готовых изображений, их много. К примеру, FERET, используемая разработчиками OpenCV;
• Обрезка позитивных изображений до искомой части, склеивание в ряд;
• Подготовка натуральных тестовых изображений в виде «интересующий объект на фоне»;
• Выделение на данном наборе натуральных тестовых изображений областей интереса (regions of interest, ROI), по сути, установка координат того места, где расположен интересующий объект;
• Сохранение в новый набор данных;
• Создание образцов (обучающих выборок);
• Обучение. На данной стадии:
— Обучение классификатора Хаара;
— Создание XML-файла.
Собранные наборы изображений собираются в папку data, а в папку haarcascades складываются результаты обучения каскадов в виде классификаторов Хаара в XML-формате.
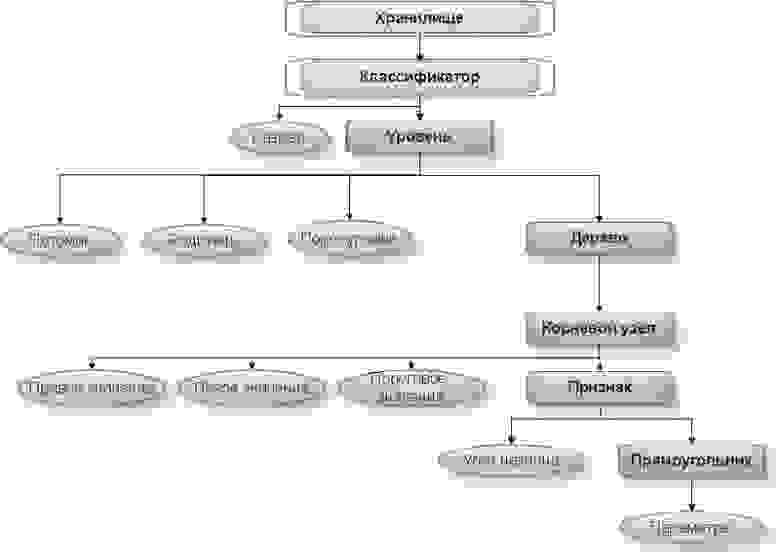
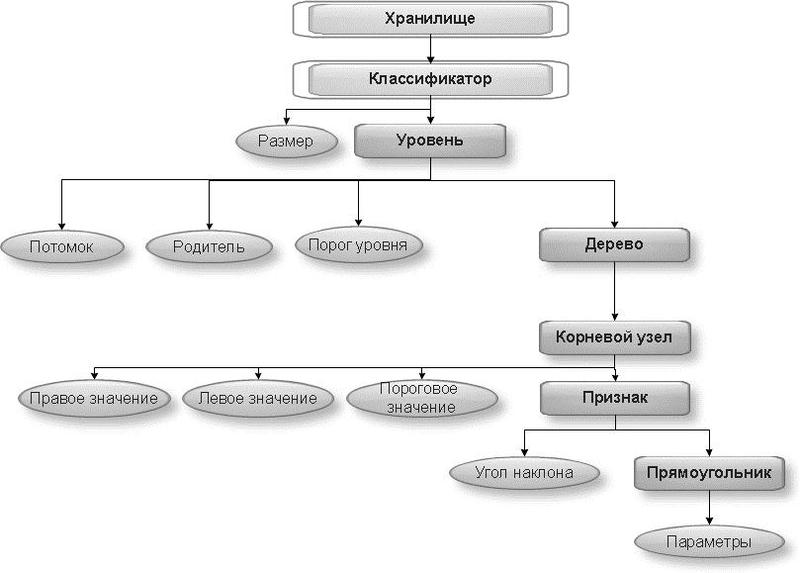
Для каждого классификатора, выраженного как сущность с подчиненными атрибутами надо создать отдельное XML-хранилище. DOM (Document Object Model), или по-русски, объектная модель документа такого классификатора в общем виде представлена ниже. Корневым элементом является Хранилище, длина самого дерева равна 7.
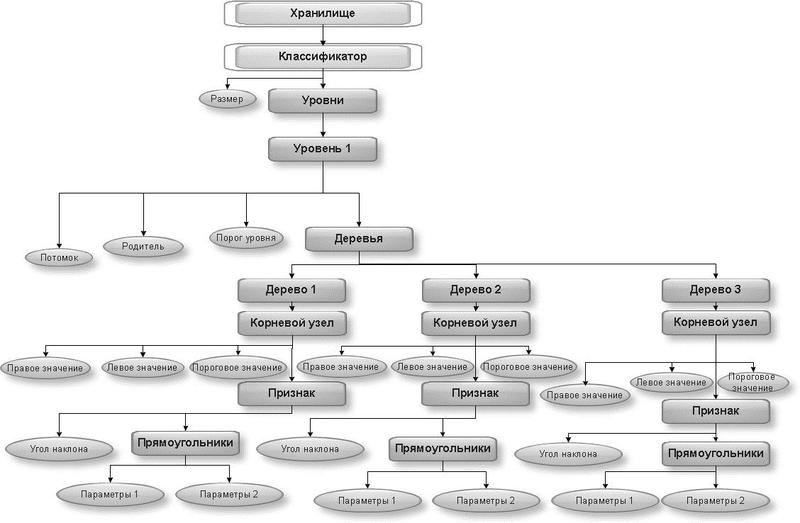
В каскаде существует много уровней — это видно на примере первого уровня классификатора:
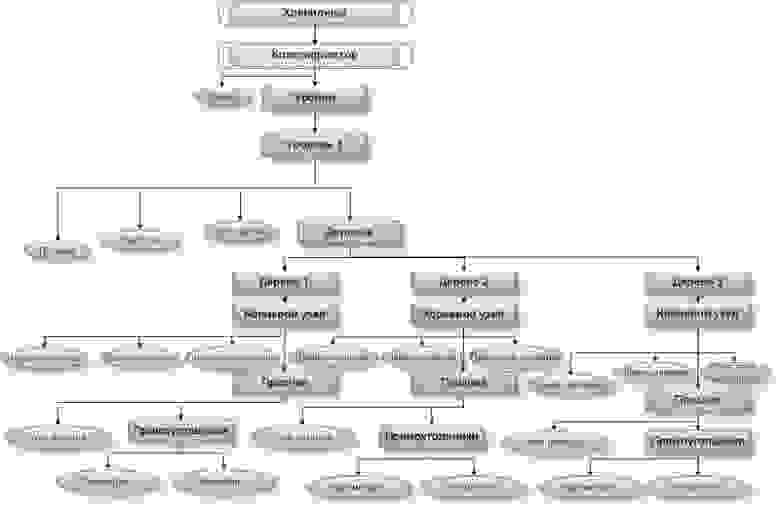
На данном примере видно, какая информация хранится в используемых XML. Это информация о классификаторе (haarcascade) и его размерах (size), об используемом уровне (stage), предшественнике, или родителе данного уровня (parent), следующем уровне, или последователе(next), выстраиваемом дереве (tree) и его корневом узле (root node) с параметрами (threshold, left, right). Далее выстраивается информация о самих признаках (features) в узлах этого дерева, которые задаются прямоугольниками с параметрами (rects) с определенным углом наклона (tilted). В более конкретном примере надо разбивать по уровням и деревьям в общем смысле, поэтому длина такого дерева равна 9.
В результате работы алгоритма программы на выходе должны получаться xml-файлы со структурой, показанной в листинге ниже. Все xml-файлы будут идентичны по строению и по DOM-модели.
Для того, чтобы тренировать классификатор, нужны большие наборы изображений «позитивных», и большие наборы изображений «негативных», грубо говоря, искомый объект и его фон. Важно, чтобы наборы были одного размера, так как происходит склейка и указываются те координаты, где находится объект, то есть те координаты, которые запоминает классификатор, и тем самым обучается. При склейке получается новый набор изображений. Пример такого «склеенного» изображения из моей базы:

Создание таких образцов происходит с помощью файла createsamples.cpp, который в свою очередь подгружает для работы cvhaartrainig.h. Я их взял из стандартной библиотеки OpenCV и «допилил» для своих нужд. Указываемых параметров при создании таких образцов много, представленные в следующем листинге используются мной, но это далеко не все параметры:
В результате создается сразу и .dat-файл, где мы можем посмотреть такую информацию: полученному изображению для дальнейшей обработки присваивается имя по координатам отмеченных признаков. Цифры в примере означают, что количество найденных объектов равно 5 и найдены экземпляры объекта в прямоугольнике с координатами {30, 49}, и шириной и высотой 469 и 250:
Создание возможно и через .vec-файл, который применяется в OpenCV, и который используют для представления изображений, содержит имя файла и его можно расширять с помощью дополнительного кода. Можно сделать такое добавление информации через addVec в vec-файл:
Следующим этапом после создания образцов является этап обучения классификатора, при этом параметры мной задаются такие:
Результатом данного этапа являются готовые для использования, натренированные классификаторы. В разрабатываемом мной модуле будет применено очень много классификаторов (для каждой отличительной для данной эмоции черты лица), которые я заранее подготовил, т.к. классификаторы обучаются долго. Я их обучал на разных компьютерах. На каждый классификатор уходит порядка трех дней при неслабых вычислительных мощностях компьютера! Так что советую, если есть дедлайн, то беритесь за работу уже сейчас:
Как только доступно исходное изображение, модуль автоматически распознает на нем искомые объекты. Сама последовательность действий выглядит очень простой, но за этим скрываются сложности реализации данных этапов.
Разберем функцию init(), где происходит загрузка изображений, инициализация ресурсов, подключение к базе данных и подготовка изображения для последующей обработки:
Затем изображение попадает в основной цикл модуля. Основная работа моего разработанного метода распознавания разбита по функциям, которые идут в таком порядке:
Для проверки эффективности работы и быстродействия алгоритма были проведены тестовые испытания с наполненной базой данных EmotionDB (15 изображений – больше для теста не понадобится) и простым массивом изображений в локальной директории (10 изображений). Данные изображения в базе и в массиве имеют разный размер, есть цветные, а есть и черно-белые фотографии, с разным количеством человек на них.
Для тестов использован встроенный файл OpenCV performance.cpp, где ведется подсчет всех данных и выстраивание ROC-кривой. Пример подсчета этапов или стадий классификатора:
Несмотря на то, что в тестируемом наборе изображений есть наклоненные лица, алгоритм не пропускает и идентифицирует такие лица, но обнаружение работает с более низкой скоростью, чем возможно в простом случае с не наклоненным лицом. В условиях недостаточного освещения и большого слияния с фоном искомых объектов, а также мешающего зашумления и помех на изображении, модуль работает медленнее, чем с нормальными изображениями, наравне со стандартным алгоритмом Виолы-Джонса.
В условиях плохой видимости объекта (смешение с фоном) модуль справляется с распознаванием лучше за счет использования предложенного механизма предварительной обработки изображения.
В таблице представлены результаты тестирования алгоритма, а также сравнения точности работы алгоритма Виолы-Джонса с базовым набором из библиотеки OpenCV и модифицированного Виолы-Джонса с натренированным набором для распознавания черт лица:
Результаты сравнения алгоритмов
Cкорость работы разработанного алгоритма при обнаружении лица человека совсем ненамного, но превышает скорость работы базового алгоритма, хотя на разных тестовых наборах фотографий выдаются разные результаты. В таблице приведены усредненные значения. К сожалению, не в промышленном масштабе, а на довольно стареньких компьютерах и ноутбуке полное тестирование не удастся воспроизвести, как бы этого не хотелось.
По программе: много времени кушается на предобработку фотографии (~250-300 ms), но надо отрефакторить код. Детекция признаков занимает порядка 400 ms в среднем. Само определение эмоции занимает мало времени, так как функция определяет типы сработавших классификаторов и выдает молниеносно результат.
Всем спасибо! Читайте больше! С Новым Годом и всех благ! Это был SkyNoName
P.S. Жду Вашей критики и вопросов по сабжу! Ну или Вашего «Спасибо», если материал хоть как-то Вам помог…
Итак, многие ждали примеры моей программы и объяснения ее работы с точки зрения написания кода. Я же рассказываю последовательно, чтобы каждый смог ее повторить у себя на компьютере. Обращайте внимание побольше на обильные комментарии в коде, в них сила! И не бойтесь мега-мелкого скролла, т.к. информации много. Передислоцируйтесь в место с хорошим интернетом, в статье много схем и фотографий!
Разработка проекта
В результате, в предыдущей части, был разработан шаблон проекта с подключенными нужными заголовками и с подцепленной библиотекой OpenCV. Давайте же посмотрим, какой тип работ предстоит еще сделать и как его сделать.
Также, по горячим следам, выяснилось, что можно набросать приблизительные схемы работ
стандартного
и модифицированного метода Виолы-Джонса по работе с фотографией.

Предварительное обучение классификаторов
Так как в модуле распознавания эмоций используются классификаторы, разработана последовательность действий по их обучению и тренировке.
Итак, для того чтобы обучить классификатор, потребуется:
• Подготовка средства разработки, подключение библиотеки OpenCV;
• Подготовка данных. Для использования пригодны:
— Тестовые наборы «позитивных» и «негативных» изображений (positive and negative images). «Позитивные» изображения содержат объект интереса (лицо, рот, нос и так далее),
«Негативные» изображения содержат только фон (background);
— .vec-файл, легко дополняемый, содержащий те же наборы изображений, только в уменьшенном размере;
— Базы уже готовых изображений, их много. К примеру, FERET, используемая разработчиками OpenCV;
• Обрезка позитивных изображений до искомой части, склеивание в ряд;
• Подготовка натуральных тестовых изображений в виде «интересующий объект на фоне»;
• Выделение на данном наборе натуральных тестовых изображений областей интереса (regions of interest, ROI), по сути, установка координат того места, где расположен интересующий объект;
• Сохранение в новый набор данных;
• Создание образцов (обучающих выборок);
• Обучение. На данной стадии:
— Обучение классификатора Хаара;
— Создание XML-файла.
Собранные наборы изображений собираются в папку data, а в папку haarcascades складываются результаты обучения каскадов в виде классификаторов Хаара в XML-формате.
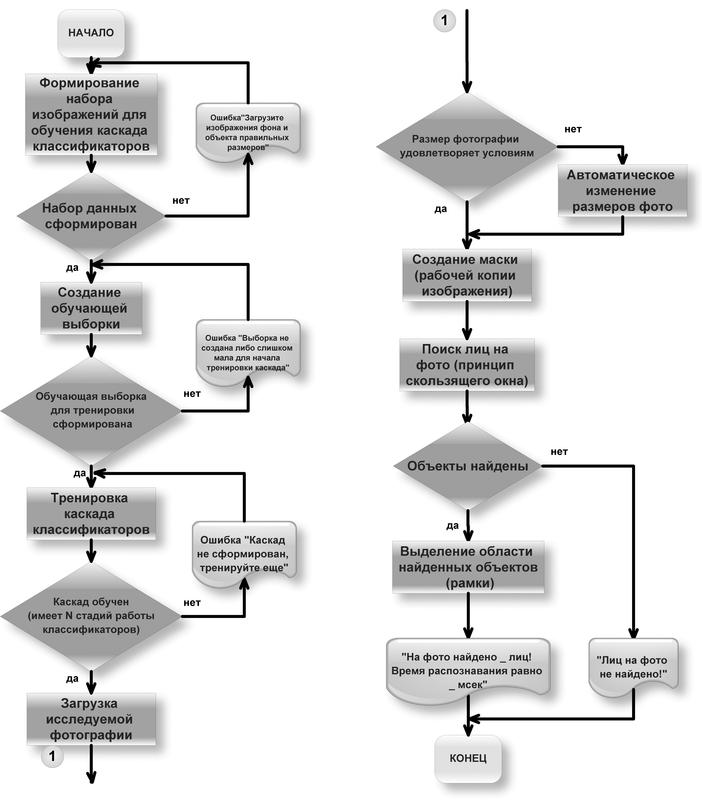
Для каждого классификатора, выраженного как сущность с подчиненными атрибутами надо создать отдельное XML-хранилище. DOM (Document Object Model), или по-русски, объектная модель документа такого классификатора в общем виде представлена ниже. Корневым элементом является Хранилище, длина самого дерева равна 7.
В каскаде существует много уровней — это видно на примере первого уровня классификатора:
На данном примере видно, какая информация хранится в используемых XML. Это информация о классификаторе (haarcascade) и его размерах (size), об используемом уровне (stage), предшественнике, или родителе данного уровня (parent), следующем уровне, или последователе(next), выстраиваемом дереве (tree) и его корневом узле (root node) с параметрами (threshold, left, right). Далее выстраивается информация о самих признаках (features) в узлах этого дерева, которые задаются прямоугольниками с параметрами (rects) с определенным углом наклона (tilted). В более конкретном примере надо разбивать по уровням и деревьям в общем смысле, поэтому длина такого дерева равна 9.
Структура файла классификатора
В результате работы алгоритма программы на выходе должны получаться xml-файлы со структурой, показанной в листинге ниже. Все xml-файлы будут идентичны по строению и по DOM-модели.
<storage>
<classifier1>
<size></size>
<stages>
<_><!-- #of stage -->
<trees>
<_><!-- #of tree -->
<_><!-- root node -->
<feature>
<rects><_></_><_></_></rects>
<tilted></tilted>
</feature>
<threshold></threshold>
<left_val></left_val>
<right_val></right_val>
</_></_></trees>
<stage_threshold></stage_threshold>
<parent></parent>
<next></next>
…
</_></stages>
<_></classifier1>
</storage>
Подготовка новых наборов данных
Для того, чтобы тренировать классификатор, нужны большие наборы изображений «позитивных», и большие наборы изображений «негативных», грубо говоря, искомый объект и его фон. Важно, чтобы наборы были одного размера, так как происходит склейка и указываются те координаты, где находится объект, то есть те координаты, которые запоминает классификатор, и тем самым обучается. При склейке получается новый набор изображений. Пример такого «склеенного» изображения из моей базы:

Создание таких образцов происходит с помощью файла createsamples.cpp, который в свою очередь подгружает для работы cvhaartrainig.h. Я их взял из стандартной библиотеки OpenCV и «допилил» для своих нужд. Указываемых параметров при создании таких образцов много, представленные в следующем листинге используются мной, но это далеко не все параметры:
void сreateTrainingSamples(
const char* filename,// имя выходного файла, содержащего правильные наборы изображений, уже готовые для применения в обучении
const char* imgfilename,//изображение с искомым объектом
int bgcolor, // цвет изображения
int bgthreshold,// порог цветности, или прозрачности 8-битового изображения
const char* bgfilename, //изображение с фоном
int count,
int invert = 20,//поворот изображения с объектом в градусах
int maxintensitydev = 40,//максимальное отклонение интенсивности пикселей образцов с исходным элементом
double maxxangle = 1.1,//максимальный угол поворота в радианах по X
double maxyangle = 1.1, //максимальный угол поворота в радианах по Y
double maxzangle = 0.5, //максимальный угол поворота в радианах по Z
int showsamples = 0,//если не ноль, то каждый сделанный образец будет показан
int winwidth = 24,//такая ширина в пикселях будет у конечного образца
int winheight = 24//такая высота в пикселях будет у конечного образца
);
В результате создается сразу и .dat-файл, где мы можем посмотреть такую информацию: полученному изображению для дальнейшей обработки присваивается имя по координатам отмеченных признаков. Цифры в примере означают, что количество найденных объектов равно 5 и найдены экземпляры объекта в прямоугольнике с координатами {30, 49}, и шириной и высотой 469 и 250:
../../ kalian2.png/0005_0030_0049_0469_0250.jpg 5 30 49 469 250Создание возможно и через .vec-файл, который применяется в OpenCV, и который используют для представления изображений, содержит имя файла и его можно расширять с помощью дополнительного кода. Можно сделать такое добавление информации через addVec в vec-файл:
addVec (oldvecname, newvecname, samplwidth, samplheight);//функция добавления информации к существующему вектору, через newvecname добавляется еще одно имя внешнего файла, содержащего сгенерированные образцы, к информации oldvecname, и добавляется единая ширина и высота данных сгенерированных образцов.
Параметры и стадии обучения классификатора
Следующим этапом после создания образцов является этап обучения классификатора, при этом параметры мной задаются такие:
void сreateCascadeClassifier(
const char* dirname,//имя директории, в которой создается и хранится классификатор
const char* vecfilename,//имя vec-файла с изображениями объекта если такой есть
const char* bgfilename, //изображение с файлом, описывающим фон
int npos,//количество позитивных образцов
int nneg, //количество негативных образцов
int nstages,//количество этапов или стадий обучения
int numprecalculated,//количество признаков, которые должны быть прегенерированы
int numsplits,//количество слабых классификаторов, используемых на каждой стадии обучения: 1 – отросток, 2 и более - деревья
float minhitrate = 0.995F,//минимальный желаемый коэффициент успеха на каждой стадии обучения классификатора
float maxfalsealarm = 0.5F,//максимальный желаемый результат ложных обнаружений на каждой стадии
float weightfraction = 0.95F,//указывает параметр используемого веса, для хорошо работающего классификатора наиболее оптимальным будет параметр 90
int mode = 3,//используемый алгоритм, устанавливает набор типов признаков Хаара, использующихся во время обучения. 0, или BASIC – это базовый, то есть используется алгоритм Виолы-Джонса, использует только вертикальные признаки, в то время как 2, или ALL использует все варианты признаков, повернутые на 45 градусов, а параметр 3 означает сочетание стандартного набора типов признаков и предложенных новых признаков Хаара
int symmetric = 1,//параметр определяет, будет ли искомый объект иметь вертикальную симметрию или нет, если не равен 0, то вертикальная симметрия принимается
int equalweights = 1,//если параметр не равен 0, это означает что начальные веса всех образцов будут одинаковыми
int winwidth = 24,//размеры образцов
int winheight = 24,//размеры образцов
int boosttype = 3,//выбор типа алгоритма бустинга, где 0 – Discrete AdaBoost, 1 – Real AdaBoost, 2 – LogitBoost, 3 – Gentle AdaBoost
int stumperror = 0 );//тип указываемой ошибки, если применяется алгоритм Discrete AdaBoost
Результатом данного этапа являются готовые для использования, натренированные классификаторы. В разрабатываемом мной модуле будет применено очень много классификаторов (для каждой отличительной для данной эмоции черты лица), которые я заранее подготовил, т.к. классификаторы обучаются долго. Я их обучал на разных компьютерах. На каждый классификатор уходит порядка трех дней при неслабых вычислительных мощностях компьютера! Так что советую, если есть дедлайн, то беритесь за работу уже сейчас:
• face_identify_classifier.xml – для нахождения лица,
• eyes_identify_classifier.xml – для нахождения глаз,
• eyebrows_identify_classifier.xml – для нахождения бровей,
• mouth_identify_classifier.xml – для нахождения рта,
• nose_identify_classifier.xml – для нахождения носа,
...
• happysmile_kalian_classifier.xml – для распознавания счастливой улыбки,
• happyeyes_kalian_classifier.xml – для распознавания глаз, выражающих счастье,
• happyeyebrows_kalian_classifier.xml – для распознавания немного смыкающихся бровей,
• surprisingeyes_kalian_classifier.xml – для распознавания немного выпученных глаз, зрачки которых четко видны,
• openingmouth_kalian_classifier.xml – для распознавания достаточно широко открытого рта,
• surprisingeyebrows_kalian_classifier.xml – для распознавания «удивленных» бровей (находятся относительно на большом расстоянии от глаз и немного разведены)
Аппарат автоматического распознавания эмоций
Как только доступно исходное изображение, модуль автоматически распознает на нем искомые объекты. Сама последовательность действий выглядит очень простой, но за этим скрываются сложности реализации данных этапов.
Разберем функцию init(), где происходит загрузка изображений, инициализация ресурсов, подключение к базе данных и подготовка изображения для последующей обработки:
- Первоначально с помощью специальной функции cvLoad() загружаются созданные классификаторы для детектирования и распознавания, они у меня расположены в папке haarcascades моего проекта (…\haarcascades\). Далее следует создание хранилища памяти:
storage = cvCreateMemStorage(0);:
//инициализация баз данных, хранилищ памяти, фото и функций, их обрабатывающих void init(){//загрузка баз данных, обученных на детектирование лиц и признаков лица// каскады находятся в директории haarcascades cascade = (CvHaarClassifierCascade*)cvLoad( "haarcascades/mouth_disugst_classifier.xml" );//определение рта //cascade1 = (CvHaarClassifierCascade*)cvLoad( "haarcascades/ eyes_identify_classifier.xml" );//определение глаз cascade1 = (CvHaarClassifierCascade*)cvLoad( "haarcascades/face_identify_classifier.xml" );//полностью лицо cascade7 = (CvHaarClassifierCascade*)cvLoad( "haarcascades/haarcascade_frontalface_alt_tree.xml" );//последовательность лиц cascade2 = (CvHaarClassifierCascade*)cvLoad( "haarcascades/haarcascade_eye.xml" );//два глаза по отдельности //cascade3 = (CvHaarClassifierCascade*)cvLoad( "haarcascades/haarcascade_mcs_nose.xml" );//определение носа cascade3 = (CvHaarClassifierCascade*)cvLoad( "haarcascades/haarcascade_kalian_nose.xml" );//определение носа cascade4 = (CvHaarClassifierCascade*)cvLoad( "haarcascades/haarcascade_profileface.xml" );//полностью лицо//в профиль cascade5 = (CvHaarClassifierCascade*)cvLoad( "haarcascades/smiled_01.xml" );//улыбка1 cascade8 = (CvHaarClassifierCascade*)cvLoad( "haarcascades/smiled_02.xml" );//улыбка2 cascade9 = (CvHaarClassifierCascade*)cvLoad( "haarcascades/smiled_03.xml" );//улыбка3 cascade10 = (CvHaarClassifierCascade*)cvLoad( "haarcascades/smiled_04.xml" );//улыбка4 cascade6 = (CvHaarClassifierCascade*)cvLoad( "haarcascades/haarcascade_mcs_eyepair_big.xml" );//переносица ... //Создание хранилища памяти storage = cvCreateMemStorage(0);
- С помощью функции
cvNamedWindow();вырисовывается окно, в котором и будут появляться результаты операций с изображением и на изображении. - Если используем камеру, то понадобится код для захвата с камеры:
// получаем любую подключённую камеру CvCapture* capture = cvCreateCameraCapture(CV_CAP_ANY); //cvCaptureFromCAM( 0 ); assert( capture ); //cvSetCaptureProperty(capture, CV_CAP_PROP_FRAME_WIDTH, 640);//1280); //cvSetCaptureProperty(capture, CV_CAP_PROP_FRAME_HEIGHT, 480);//960); // узнаем ширину и высоту кадра double width = cvGetCaptureProperty(capture, CV_CAP_PROP_FRAME_WIDTH); double height = cvGetCaptureProperty(capture, CV_CAP_PROP_FRAME_HEIGHT); printf("[i] %.0f x %.0f\n", width, height ); IplImage* frame=0; cvNamedWindow("capture", CV_WINDOW_AUTOSIZE); printf("[i] press Enter for capture image and Esc for quit!\n\n"); int counter=0; char filename[512]; while(true){ // получаем кадр frame = cvQueryFrame( capture ); // показываем cvShowImage("capture", frame); char c = cvWaitKey(33); if (c == 27) { // нажата ESC break; } else if(c == 13) { // Enter // сохраняем кадр в файл sprintf(filename, "Image%d.jpg", counter); printf("[i] capture... %s\n", filename); cvSaveImage(filename, frame); counter++; } - Программа входит цикл, в котором последовательно выполняется загрузка изображения или массива изображений в память:
image = cvLoadImage( array_1[j], 1 ); printf("\n[i] Image loaded\n", image); assert( image!= 0 );
Если данные хранятся в базе данных, то на данном этапе делается подключение нужного заголовка mysql.h к БД, предварительное подключение и загрузка данных из БД в память при необходимости:
#include <mysql.h> … // Прототип функции обработки ошибок void comlinePrint(char *); … // Дескриптор соединения MYSQL conn; // Дескриптор результирующей таблицы MYSQL_RES *res; // Массив полей текущей строки MYSQL_ROW row; // Получаем дескриптор соединения if(!mysql_init(&conn)) comlinePrint("Error: не создается MySql - дескриптор\n"); // Устанавливаем соединение с базой данных if(!mysql_real_connect(&conn,"localhost","kalian","","user",0,NULL,0)) comlinePrint("Error: невозможно подконнектиться к SQL серверу\n"); // Устанавливаем кодировку соединения, чтобы предотвратить // искажения русского текста if(mysql_query(&conn, "SET NAMES 'cp1251'") != 0) { // Если кодировку установить невозможно - выводим // сообщение об ошибке comlinePrint ("Error: невозможно установить кодировку\n"); exit(1); } // Добавляем нового пользователя if(mysql_query(&conn,"INSERT INTO `user` VALUES(NULL, 'Николай', 'Наумов',’Николаевич’, 22, ‘м’, ‘Россия’,’Москва’) ") != 0) { // Если добавить запись не получилось - выводим // сообщение об ошибке comlinePrint ("Error: в данный момент нельзя добавить пользователя\n"); exit(1); } void comlinePrint(char * str) { printf(stderr, str); exit(1); } // Закрываем соединение с сервером базы данных mysql_close(&conn);} - Далее производится изменение размеров изображения. Проверяются ширина и высота картинки и в зависимости от условий изображение увеличивается либо уменьшается в n раз:
if(image->width>700 && image->height>700){ resPic = cvCreateImage( cvSize(image->width/1.5, image->height/1.5), image->depth, image->nChannels ); cvResize(image, resPic, 1); cvShowImage("resizing", resPic); printf ("\n[i] Image has been resized", image); comlinePrint(); else if(image->width<200 && image->height<200){ resPicMal = cvCreateImage( cvSize(image->width*2, image->height*2), image->depth, image->nChannels ); cvResize(image, resPicMal, 1); cvShowImage("resizing", resPicMal);
Затем изображение попадает в основной цикл модуля. Основная работа моего разработанного метода распознавания разбита по функциям, которые идут в таком порядке:
- imageGray();//преобразование исходного изображения в полутоновое
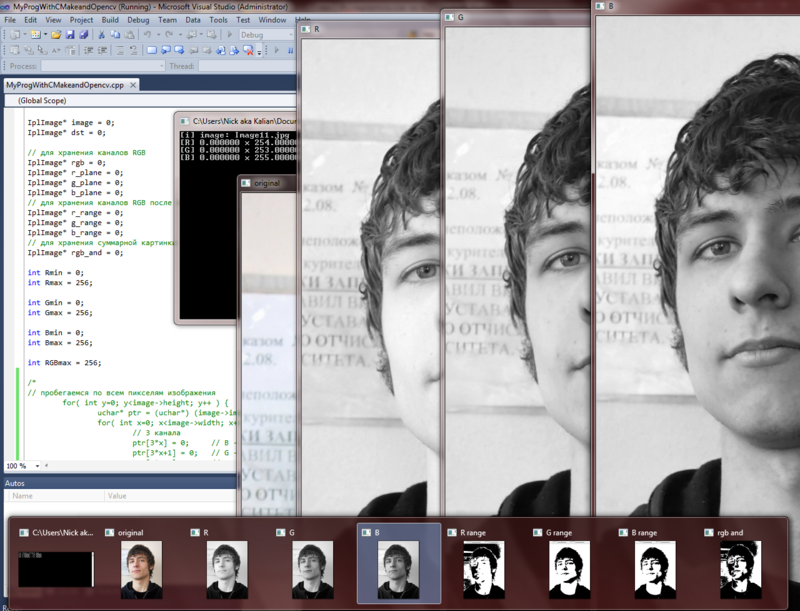
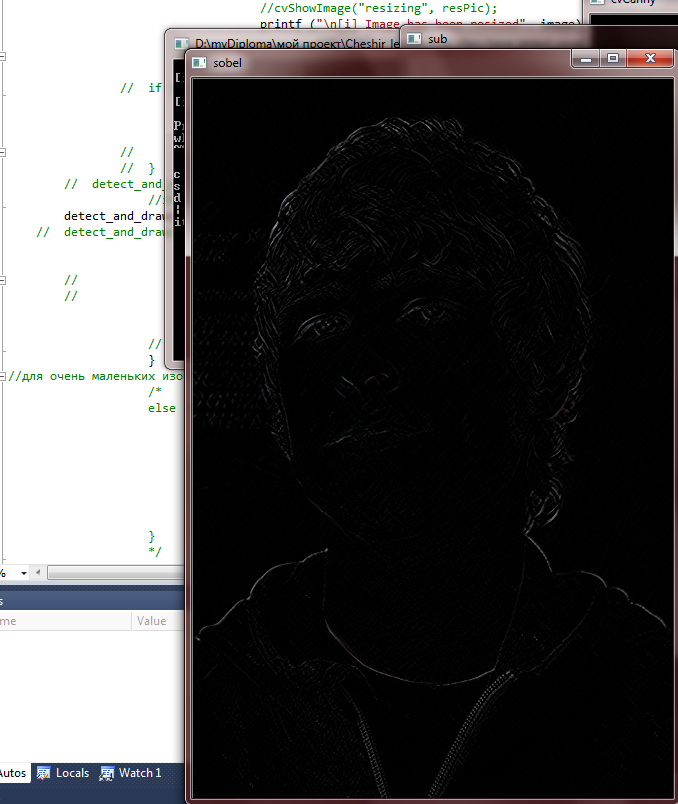
- SobelPreparation(resPic, dst2);//первоначальная обработка оператором Собеля
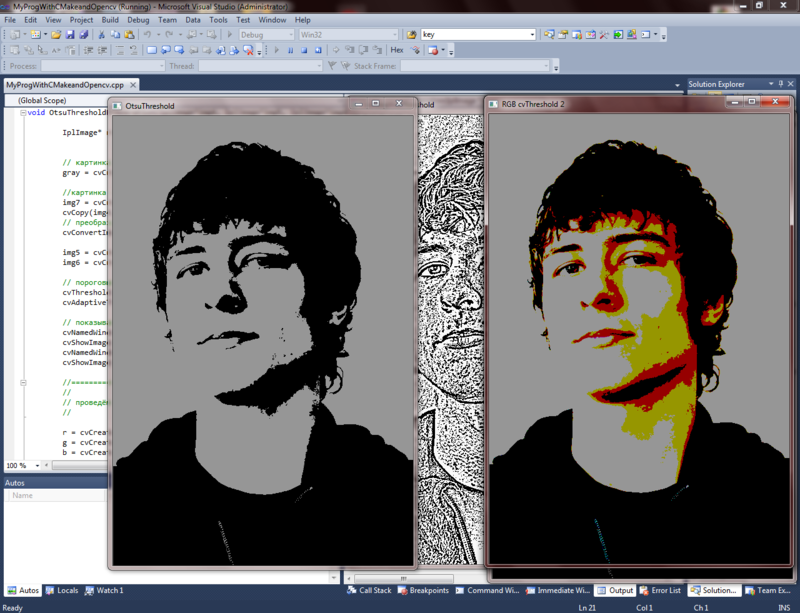
- OtsuThresholdPreparation(resPic, ots1, ots2);//бинаризация методом Отсу
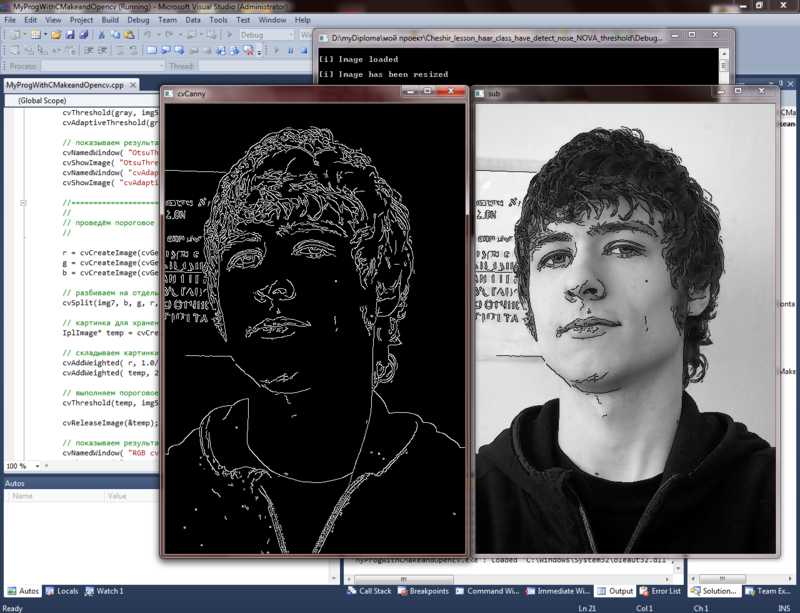
- ImageCannyPreparation(resPic, dst);//выделение границ детектором Канни (результат показан на скриншоте с cvSub)
- dilate();//утолщение найденных границ* — можно не использовать, по результатам тестов программы с помощью данной функции в большинстве случаев результаты не улучшаются, а иногда и вовсе еще хуже, чем без нее
- cvSub(gray,img1, img1);//вычитание бинарника из оригинала
- detect_and_draw(resPic);//идентификация лица и его черт на изображении
- recognizeResult(resPic);//вычисление эмоции
- cvShowImage(&resPic);//результат распознавания
- (cvWaitKey(1000));//ожидание нажатия клавиши
- cvReleaseImage( &resPic )//освобождение ресурсов памяти




Настраиваемые параметры детектирования лиц и их черт
- Функции подготовки изображений Я уверен Вы напишете без проблем сами, т.к. реализующие функции в OpenCV имеют такие же названия, как и названия используемых алгоритмов, поэтому даны только скриншоты работы программы на каждом из этапов. Хотя может и приложу код в самом конце.
- Поиск искомых объектов в модуле осуществляется с помощью функции detect_and_draw(resPic), в теле которой первоначально задается массив, в котором содержатся цвета для прямоугольников, которыми будут выделяться лица и черты. Затем, с использованием функции cvHaarDetectObjects() в последовательность objects возвращаются все участки на картинке, которые соответствуют лицам и чертам лиц людей. В коде это выглядит так:
CvSeq* objects1 = cvHaarDetectObjects( img, cascade1, storage, 1.1, 4, 0|CV_HAAR_DO_CANNY_PRUNING, cvSize( 10, 20 ));//лица /* нотация к CvSeq: CvSeq* cvHaarDetectObjects( const CvArr* image,//целевое изображение, к которому применяется каскад CvHaarClassifierCascade* cascade,//натренированный каскад CvMemStorage* storage,//используемое хранилище памяти double scale_factor = 1.1,//коэффициент увеличения масштаба int min_neighbors = 4,//минимальный соседний порог int flags = 0|CV_HAAR_DO_CANNY_PRUNING,//пропускать маловероятные области CvSize min_size = cvSize(0,0)//использовать значение масштаба ); */
Работа функции, да и результат работы всего модуля зависит от параметров cvHaarDetectObjects():
Минимальный соседний порог – это то, с какой интенсивностью находится каждая часть лица. Надо настраивать вручную, так как без порога детектор генерирует много одних и тех же распознаваний в одном месте. Обычно изолированные обнаружения являются ложными, так что имеет смысл отказаться от них. Также имеет смысл объединить несколько обнаружений для каждой лицевой области в единую сущность.
OpenCV делает эти оба условия перед возвратом перечня обнаруженных объектов.
Шаг слияния сначала группирует прямоугольники, которые содержат большое количество перекрытий, а затем находит усредненный прямоугольник для группы.
Далее происходит замена всех прямоугольников в группе на вычисленный средний прямоугольник.
Между изолированными прямоугольниками и большими группами существуют маленькие группы, которые могут являться как лицами, так и ложными обнаружениями.
Минимальный соседний порог устанавливает уровень отсечения для отбрасывания или сохранения групп прямоугольников в зависимости от того, сколько необработанных обнаружений находится в группе. По умолчанию этот параметр равен трем, что означает слияние группы из трех и более прямоугольников и отбрасывание групп с меньшим количеством прямоугольников. Если заметно недостает распознавания большого количества лиц и черт лица, то надо снижать значение порога до меньшего числа. Если его установить равным нулю, то функция вернет полный перечень необработанных обнаружений классификатора Хаара.
Чтобы сделать минимальный масштаб больше, чем значение по умолчанию, можно установить новое значение этого параметра. Если вы решите использовать значение, отличное от стандартного, то надо убедиться в сохранении стандартных пропорций (отношение ширины к высоте). В этом случае, соотношение сторон будет 1:1.
Четвертый параметр функции определяет как быстро OpenCV будет увеличивать масштаб для лицевых обнаружений вместе с каждым проходом, осуществляемым по изображению. Установка большего значения делает работу детектора более быстрой (из-за меньшего количества проходов сканирующего окна), но если минимальный масштаб слишком высок, то существует возможность слишком быстрых переходов между масштабами и упущение лиц. По умолчанию в OpenCV данный параметр имеет значение 1.1, или другими словами, масштаб увеличивается с коэффициентом 1.1 (10%) с каждым проходом.
Флаговая переменная функции cvHaarDetectObject() может принимать несколько значений:
- 0;
- CV_HAAR_DO_CANNY_PRUNING;
- CV_HAAR_FIND_BIGGEST_OBJECT;
- CV_HAAR_DO_ROUGH_SEARCH;
- CV_HAAR_DO_CANNY_PRUNING;
- CV_HAAR_SCALE_IMAGE.
Если выбран флаг «практичной обрезки» (0|CV_HAAR_DO_CANNY_PRUNING), то детектор пропускает те области изображения, нахождение лица внутри которых маловероятно, что снижает время вычисления и, возможно, устраняет некоторые ложные обнаружения. Пропускаемые области идентифицируются детектором, который обнаруживает такие «ненужные» края по всему изображению, перед запуском лицевого детектора. Опять же, выбор установки данного типа флага является компромиссом выбора между скоростью и обнаружением большего количества лиц. Установка флага приведет к увеличению скорости обработки, но может привести к пропуску некоторых лиц.
Минимальный размер, по которому производится поиск, нужно задать как можно меньше, так как какой масштаб лица будет – не определено. По умолчанию он равен (0, 0), что означает использование такого масштаба, какой записан в xml-файле классификатора.
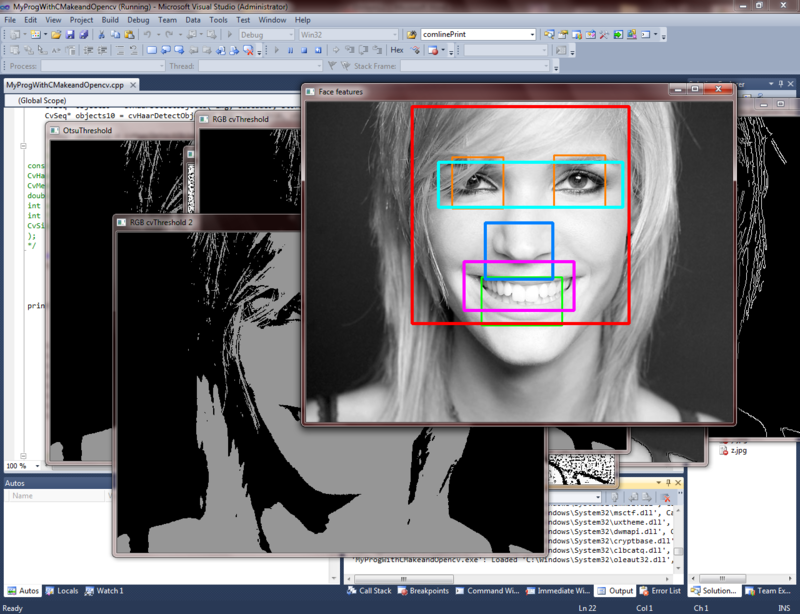
Пример плохого распознавания черт лица на этапе плохо обученного классификатора при неправильно подобранных параметрах поиска:
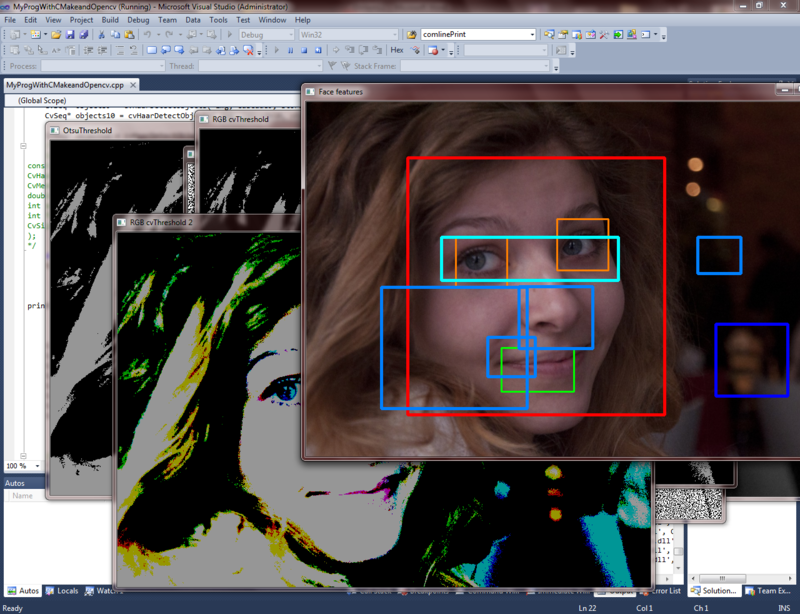
Пример хорошего распознавания черт лица на этапе хорошо обученного классификатора:
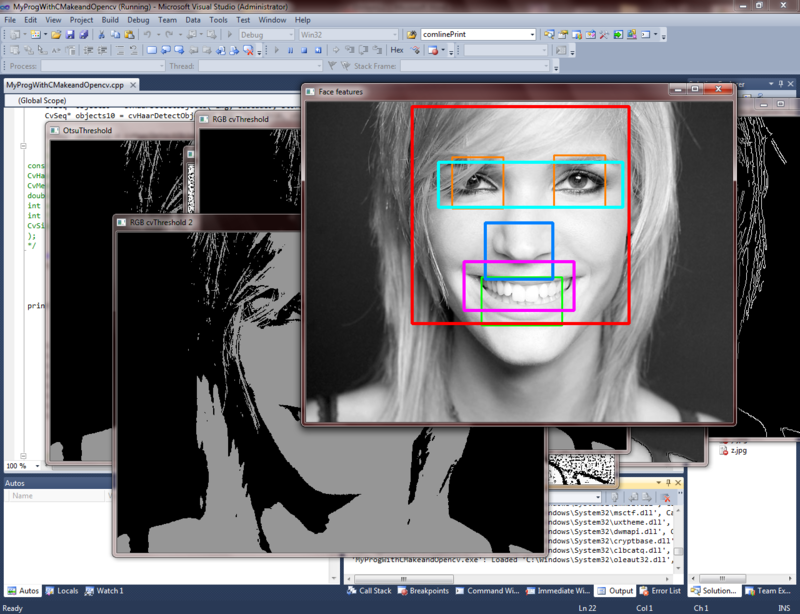
- Функции recognizeResult(resPic); передается информация, какой тип классификатора сработал в функции detect_and_draw(resPic); иными словами, какой объект был найден. И если найденные классификаторы удовлетворяют условиям типа эмоции, то выводится информация, что эмоция определена.
К примеру, если сработали следующие классификаторы:
• happysmile_kalian_classifier.xml, • happyeyes_kalian_classifier.xml, • happyeyebrows_kalian_classifier.xml
– то это эмоция радости.
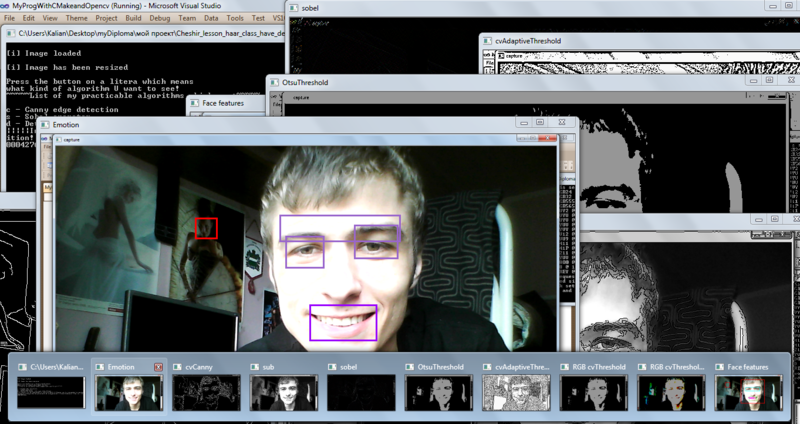
— Emotion? — Yes!!!

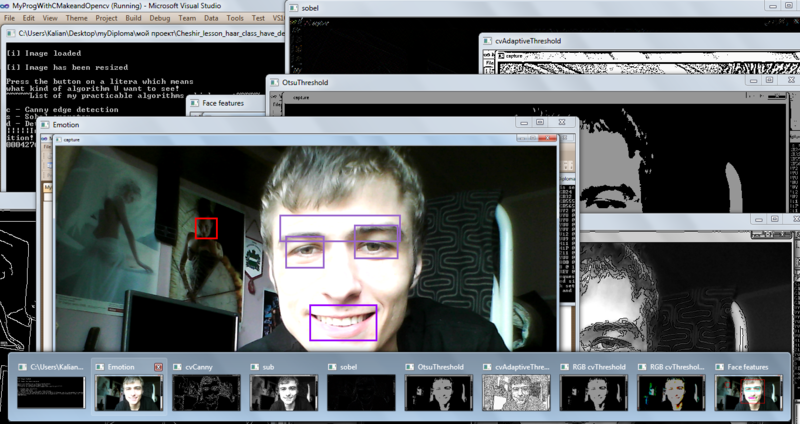
Тестирование модуля и алгоритма
Для проверки эффективности работы и быстродействия алгоритма были проведены тестовые испытания с наполненной базой данных EmotionDB (15 изображений – больше для теста не понадобится) и простым массивом изображений в локальной директории (10 изображений). Данные изображения в базе и в массиве имеют разный размер, есть цветные, а есть и черно-белые фотографии, с разным количеством человек на них.
Для тестов использован встроенный файл OpenCV performance.cpp, где ведется подсчет всех данных и выстраивание ROC-кривой. Пример подсчета этапов или стадий классификатора:
int* numclassifiers = new int[cascade->count];
numclassifiers[0] = cascade->stage_classifier[0].count;
for( i = 1; i < cascade->count; i++ )
{
numclassifiers[i] = numclassifiers[i-1] + cascade->stage_classifier[i].count;
}
Несмотря на то, что в тестируемом наборе изображений есть наклоненные лица, алгоритм не пропускает и идентифицирует такие лица, но обнаружение работает с более низкой скоростью, чем возможно в простом случае с не наклоненным лицом. В условиях недостаточного освещения и большого слияния с фоном искомых объектов, а также мешающего зашумления и помех на изображении, модуль работает медленнее, чем с нормальными изображениями, наравне со стандартным алгоритмом Виолы-Джонса.
В условиях плохой видимости объекта (смешение с фоном) модуль справляется с распознаванием лучше за счет использования предложенного механизма предварительной обработки изображения.
В таблице представлены результаты тестирования алгоритма, а также сравнения точности работы алгоритма Виолы-Джонса с базовым набором из библиотеки OpenCV и модифицированного Виолы-Джонса с натренированным набором для распознавания черт лица:
Результаты сравнения алгоритмов
| Алгоритм/Данные | Viola-Jones OpenCV | EmoRec (prep. + Viola-Jones + OpenCV) |
|---|---|---|
| Массив изображений (10 штук) | 89%, ~7 сек (7475 ms) | 93%, ~7 сек (7412 ms) |
| БД EmotionDB (15 штук) | 92%, ~12 сек (12167 ms) | 94%, ~12 сек (11870 ms) |
| * — % обнаружения, количество стадий (этапов), общее время работы по нахождению лица |
Выводы
Cкорость работы разработанного алгоритма при обнаружении лица человека совсем ненамного, но превышает скорость работы базового алгоритма, хотя на разных тестовых наборах фотографий выдаются разные результаты. В таблице приведены усредненные значения. К сожалению, не в промышленном масштабе, а на довольно стареньких компьютерах и ноутбуке полное тестирование не удастся воспроизвести, как бы этого не хотелось.
По программе: много времени кушается на предобработку фотографии (~250-300 ms), но надо отрефакторить код. Детекция признаков занимает порядка 400 ms в среднем. Само определение эмоции занимает мало времени, так как функция определяет типы сработавших классификаторов и выдает молниеносно результат.
Вопросы тем, кто дочитал до конца
- Получилось в полной мере осветить алгоритм Viola Jones и его применение?
- Мне руки отрубить или нормально читается?
- Писать еще?
- Есть подборка книг и сайтов. По мере написания статей я туда заглядывал и либо находил нужное, либо ничего не находил. Но указатели на страницы и ссылки на форумы и сайты у меня остались. Оформить их отдельной темой и выложить на Хабр?
Всем спасибо! Читайте больше! С Новым Годом и всех благ! Это был SkyNoName
P.S. Жду Вашей критики и вопросов по сабжу! Ну или Вашего «Спасибо», если материал хоть как-то Вам помог…
