Искусственные нейронные сети применяются в различных областях науки: начиная от систем распознавания речи до распознавания вторичной структуры белка, классификации различных видов рака и генной инженерии. Однако, как они работают и чем они хороши?
Когда речь идет о задачах, отличных от обработки больших массивов информации, человеческий мозг обладает большим преимуществом по сравнению с компьютером. Человек может распознавать лица, даже если в помещении будет много посторонних объектов и плохое освещение. Мы легко понимаем незнакомцев даже когда находимся в шумном помещении. Но, несмотря на годы исследований, компьютеры все еще далеки от выполнения подобных задач на высоком уровне.
Человеческий мозг удивительно надежный: по сравнению с компьютером он не перестанет работать только потому, что несколько клеток погибнет, в то время как компьютер обычно не выдерживает каких-либо поломок в CPU. Но самой удивительной особенностью человеческого мозга является то, что он может учиться. Не нужно никакого программного обеспечения и никаких обновлений, если мы хотим научиться ездить на велосипеде.
Расчеты головного мозга производятся посредством тесно взаимосвязанных нейронных сетей, которые передают информацию, отсылая электрические импульсы через нейронные проводки, состоящие из аксонов, синапсов и дендритов. В 1943 году, компания McCulloch and Pitts смоделировала искусственный нейрон, как переключатель, который получает информацию от других нейронов и в зависимости от общего взвешенного входа, либо приводится в действие, либо остается неактивным. В узле ИНС пришедшие сигналы умножаются на соответствующие веса синапсов и суммируются. Эти коэффициенты могут быть как положительными (возбуждающими), так и отрицательными (тормозящими). В 1960 годах было доказано, что такие нейронные модели обладают свойствами, сходными с мозгом: они могут выполнять сложные операции распознавания образов, и они могут функционировать, даже если некоторые связи между нейронами разрушены. Демонстрация персептона Розенблатта показала, что простые сети из таких нейронов могут обучаться на примерах, известных в определенных областях. Позже, Минский и Паперт доказали, что простые пресептоны могут решать только очень узкий класс линейно сепарабельных задач (см. ниже), после чего активность изучения ИНС уменьшилась. Тем не менее, метод обратного распространения ошибки обучения, который может облегчить задачу обучения сложных нейронных сетей на примерах, показал, что эти проблемы могут быть и не сепарабельными.
Программа NETtalk применяла искусственные нейронные сети для машинного чтения текста и была первым широкоизвестным приложением. В биологии, точно такой же тип сети был применен для прогнозирования вторичной структуры белка; в самом деле, некоторые из лучших исследователей до сих пор пользуются тем же методом. С этого началась другая волна, вызвавшая интерес к исследованиям ИНС и поднявшая шумиху вокруг магического обучения мыслящих машин. Некоторые из наиболее важных ранних открытий приведены в 5 источнике.
ИНС могут быть созданы путем имитации модели сетей нейронов на компьютере. Используя алгоритмы, которые имитируют процессы реальных нейронов, мы можем заставить сеть «учиться», что помогает решить множество различных проблем. Модель нейрона представляется как пороговая величина (она проиллюстрирована на рисунке 1а). Модель получает данные от ряда других внешних источников, определяет значение каждого входа и добавляет эти значения. Если общий вход выше пороговой величины, то выход блока равен единице, в противном случае – нулю. Таким образом, выход изменяется от 0 до 1, когда общая «взвешенная» сумма входов равна пороговой величине. Точки в исходном пространстве, удовлетворяющие этому условию, определяют, так называемые, гиперплоскости. В двух измерениях, гиперплоскость – линия, в то время как в трех измерениях, гиперплоскость является нормальной (перпендикулярной) плоскостью. Точки с одной стороны от гиперплоскости классифицируются как 0, а точки с другой стороны – 1. Это означает, что задача классификации может быть решена с использованием пороговой величины, если два класса будут разделены гиперплоскостью. Эти проблемы называются линейно сепарабельными и изображены на рисунке 1b.
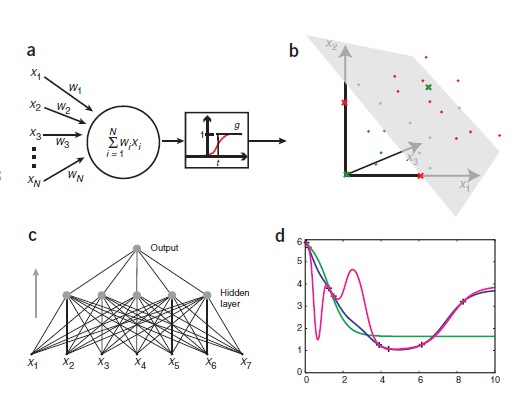
рисунок 1
Искусственные нейронные сети. (а) Графическое представление модели нейронной сети и порогового элемента McCulloch and Pitts. Пороговый блок получает входной сигнал от N других блоков или внешних источников, пронумерованных от 1 до N. Входной i называется xi и связывается с весом wi. Общий вход в устройство измерения суммы весов по всем входам, wixi=w1x1+w2x2+.. .+wNxΣi=1 N N.Если значение ниже порога t, то выход блока будет равен 1, в противном случае – 0. Таким образом, вывод может быть выражен как wixi Σi=1 – t g( N ), где g – ступенчатая функция, которая равна 0, если аргумент отрицателен, и 1, если аргумент положительный (фактическое значение в неле не имеет значения, здесь, мы выбрали 1). Так называемая, передаточная функция, g, также может быть неприрывной и «сигмоидальной», как показано красной линией. (b) Линейная сепарабельность (отделимость). В трех измерениях пороговое значение может классифицировать моменты, которые могут разделяться плоскостью. Каждая точка представляет входное значение х1, х2, х3 на пороге блока. Зеленые точки соответствуют точкамданных класса 0, и красные точки – 1. Зеленые и красные кресты иллюстрируют логическую функцию исключающего или. Найти плоскости, которые отделяют зеленые и красные точки, (или линии в х1, х2, плоскости) невозможно.(с) Однонаправленная ИНС. Показанная сеть занимает семь входов, имеет пять единиц в скрытом слое и один выход. Это двухслойная сеть, т.к. входной слой не выполняет никаких изменений и не учитывается. (d) переобучение. Восемь точек показаны плюсами на параболе (за исключением «экспериментального» шума). Они использованы для обучения трех различных ИНС. Сети воспринимают значения х в качестве входных данных (один вход) и обучаются с у значением, как желаемым результатом. Как и ожидалось, сеть с одним скрытым блоком (зеленая) не справляется с работой на высоком уровне. Сети с 10 скрытыми элементами (синяя) приближает основные функции на удивление хорошо. Последняя сеть с 20 скрытыми элементами (фиолетовая) перерабатывает информацию хорошо, сеть прекрасно обучилась, но для некоторых промежуточных областей она чрезмерно креативна.
Если проблема классификации сепарабельна, то нам все еще нужно найти способ установления веса и пороговой величины таким образом, чтобы пороговое устройство решало задачу классификации правильно. Этого можно добиться путем постоянного добавления примеров из ранее известной классификации. Такой процесс называется обучением или тренировкой, так как он напоминает процесс изучения чего-либо человеком. Моделирование обучения с помощью компьютера предполагает постоянное изменение весов и порогов таким образом, что классификация приобретает более высокий уровень после каждого шага. Обучение может быть реализовано различными алгоритмами, об одном из таких алгоритмов мы поговорим позже.
Во время тренировки гиперплоскость движется то в одну сторону, то в другую, пока не найдет правильное положение в пространстве, после чего она уже не будет значительно изменяться. Такой процесс хорошо продемонстрирован программой Neural Java (http://lcn.epfl.ch/tutorial/english/index.html); следуйте по ссылке «Adline, Percepton and Backpropagation» (красные и синие точки представляют два класса) и нажмите «play».
Рассмотрим пример задачи, для которой легко применить искусственную нейронную сеть. Из двух видов рака, только один отвечает на определенные способы лечения. Так как не существует простых биомаркеров, позволяющих отличить эти два вида рака друг от друга, вы решаете измерить генную экспрессию образцов опухоли, что бы определить тип каждой опухоли. Предположим, вы измерили значения 20 различных генов в 50 опухолях класса 0 (нереагирующих) и 50 класса 1 (реагирующих). На основе этих данных, вы обучаете пороговое устройство, который принимает 20 значений генов в качестве входных данных и выдает 0 или 1 в качестве результата для определения одного из двух классов, соответственно. Если данные линейно сепарабельны, то пороговый блок будет классифицировать обучающие данные правильно.
Тем не менее, многие проблемы классификации не являются линейно сепарабельными. Мы можем разделить классы в таких нелинейных задачах путем введения большего количества гиперплоскостей, а именно за счет введения более чем одного порогового блока. Обычно это осуществляется добавлением дополнительного (скрытого) уровня порогового элемента, каждая из которых производит частичную классификацию входных данных и посылает выводные данные на последний уровень. На заключительном уровне собираются все частичные классификации для составления окончательной (рис. 1b). Такие сети называют многоуровневыми перцептонами или однонаправленной сетью. Однонаправленные нейронные сети также могут быть использованы для задач регрессии, которые требуют постоянного выхода, в отличие от бинарных выходов (0 и 1). Заменяя ступенчатую функцию непрерывной, мы получаем вещественное число в качестве выхода. Зачастую, когда используется «сигмоидальная» функция активации, она является временной пороговой функцией (рис. 1а). «Сигмоидальная» функция активации также может быть использована для задач классификации, интерпретируя выход ниже 0.5, как класс 0, и выход выше 0.5, как класс 1. Также имеет смысл интерпретировать результат как вероятность класса 1.
В вышеприведенном примере, также возможны следующие варианты: класс 1 характеризуется как ярко выраженный ген 1 и бессимптомный класс — 0, или наоборот. Если оба из генов ярко выражены или бессимптомны, то присваивается класс 0 (опухоль). Это соответствует исключающему логическому «или» и является каноническим примером нелинейно сепарабельной функции (рис. 1b). В данном случае, для классификации опухолей было необходимо использовать многоуровневую сеть.
Вышеуказанный алгоритм обратной передачи ошибки обучения работает на однонаправленных нейронных сетях с аналоговым выходом. Обучение начинается с установки всех весов в сеть малых случайных чисел. Теперь, для каждого входного примера сеть дает выход, который начинается случайно. Мы измеряем квадрат разности между этими двумя выходами и желаемыми результатами для соответствующего класса или значения. Сумма всех этих чисел за все учебные примеры называется общей ошибкой сети. Если число равно нулю, то сеть является идеальной, следовательно, чем меньше погрешность, тем лучше сеть.
При выборе весов, которые сведут суммарную погрешность к минимуму, мы получим нейронную сеть, решающую проблему лучшим способом. Это то же самое, что и линейная регрессия, где два параметра характеризуют выбранные линии так, чтобы сумма квадратов разностей между линией и информационными точками была минимальной. Такую задачу можно решить аналитически в линейной регрессии, но нет никакого решения в однонаправленных нейронных сетях со скрытыми элементами. В алгоритме обратной передачи ошибки, веса и пороги меняются каждый раз, когда предоставляется новый пример, таким образом, возможность ошибки постепенно становится меньше. Процесс повторяется сотни раз, пока ошибка не остается неизменной. Наглядное представление этого процесса можно найти на сайте Neural Java, который указан выше, перейдя по ссылке «Multi-layer Perceptron» (с выходом нейрона {0, 1}).
В алгоритме обратной передачи ошибки, численный метод оптимизации называется алгоритмом градиентного спуска, который особенно упрощает математические вычисления. Название этот алгоритм получил из-за формы уравнений, которые он помогает решить. Есть несколько параметров обучения (так называемый коэффициент обучения и импульса), которые нуждаются в настройке при использовании обратной передачи ошибки. Также существуют и другие проблемы, которые стоит рассмотреть. Например, алгоритм градиентного спуска не гарантирует нахождение глобального минимума ошибки, поэтому результат обучения зависит от начальных значений весов. Тем не менее, одна проблема затмевает все остальные: проблема переобучения.
Переобучение происходит, когда нейронная сеть имеет слишком много параметров, которые можно извлечь из числа имеющихся параметров, то есть, когда несколько пунктов соответствуют функции со слишком большим количеством свободных параметров (рис. 1d). Несмотря на то, что все эти методы подходят и для классификации, и для регрессии, нейронные сети обычно склонны к перепараметризации. Например, сеть с 10 скрытыми элементами для решения нашей проблемы будет иметь 221 параметр: 20 скрытых весов и пороговых величин, а также 10 весов и пороговых величин на выходе. Это слишком большое количество параметров, которые можно извлечь из 100 примеров. Сеть, которая слишком подходит для обучающих данных, вряд ли обобщит выходные данные, не являющиеся обучающими. Существует множество способов для ограничения переобучения сети (исключая создание маленькой сети), но наиболее распространенные включают усреднение по нескольким сетям, регуляризацию и использование метода Байесовской статистики.
Для оценки производительности нейронных сетей, необходимо тестировать их на независимых данных, которые не использовались во время обучения сети. Обычно производится перекрестная проверка, где набор данных делится, например, на несколько комплектов одинакового размера. Тогда, сеть обучается по 9 комплектам и тестируется на десятом, и эта операция повторяется десять раз, так что все наборы используются для тестирования. Это дает оценку способности сети к обобщению, то есть, ее способности классифицировать входные данные, которым сеть не была обучена. Чтобы получить объективную оценку, что является очень важным, отдельные наборы не должны содержать похожие примеры.
И простой персептрон с одним блоком, и многослойные сети с несколькими устройствами могут быть легко обобщены для прогнозирования более чем двух параметров, простым добавлением большего количества выходных значений. Любая проблема классификации может быть закодирована набором бинарных выходов. В вышеприведенном примере, мы могли бы, например, представить, что существуют три различных метода лечения, и для данной опухоли мы хотим знать, какой из методов лечения будет эффективным. Проблема может быть решена использованием трех выходных элементов, по одному для каждого вида лечения, которые подключены к тем же скрытым единицам.
Нейронные сети применяются для многих интересных проблем в различных областях науки, медицины и техники, а в некоторых случаях они обеспечивают высокотехнологичные решения. Нейронные сети иногда случайно использовались для задач, где более простые методы давали лучшие результаты, тем самым давая плохую репутацию ИНС среди некоторых ученых.
Существуют и другие типы нейронных сетей, которые не описывались здесь. Например, машина Больцмана, неконтролируемые сети и сети Кохонена. Поддержка векторных машин тесно связанных с ИНС. Для более детального ознакомления, я советую книгу Криса Бишопа, старые книги с моим соавторством, книгу Дуда и др. Существует множество программ, которые можно использовать для создания ИНС, обученных по собственным данным. К ним относятся расширения и плагины для Microsoft Excell, Matlab, и R (http://www.r-project.org/), а также библиотеки кода и большие коммерческие пакеты. FANN библиотеки (http://leenissen.dk/fann/), которые используются для серьезных приложений. Она наполнена открытым программным кодом на С, но может быть вызвана из, например, Perl и Python программ.
1. Minsky, M.L. & Papert, S.A. Perceptrons (MIT Press,Cambridge, 1969).
2. Rumelhart, D.E., Hinton, G.E. & Williams, R.J. Nature 323, 533–536 (1986).
3. Sejnowski, T.J. & Rosenberg, C.R. Complex Systems 1, 145–168 (1987).
4. Qian, N. & Sejnowski, T.J. J. Mol. Biol. 202, 865–884 (1988).
5. Anderson, J.A. & Rosenfeld, E. (eds). Neurocomputing: Foundations of Research (MIT Press, Cambridge, 1988).
6. Bishop, C.M. Neural Networks for Pattern Recognition (Oxford University Press, Oxford, 1995).
7. Noble, W.S. Nat. Biotechnol. 24, 1565–1567 (2006).
8. Bishop, C.M. Pattern Recognition and Machine Learning (Springer, New York, 2006).
9. Hertz, J.A., Krogh, A. & Palmer, R. Introduction to the Theory of Neural Computation (Addison-Wesley, Redwood City, 1991).
10. Duda, R.O., Hart, P.E. & Stork, D.G. Pattern Classification (Wiley Interscience, New York, 2000).
Перевод статьи (Anders Krogh NATURE BIOTECHNOLOGY VOLUME 26 NUMBER 2 FEBRUARY 2008)
Когда речь идет о задачах, отличных от обработки больших массивов информации, человеческий мозг обладает большим преимуществом по сравнению с компьютером. Человек может распознавать лица, даже если в помещении будет много посторонних объектов и плохое освещение. Мы легко понимаем незнакомцев даже когда находимся в шумном помещении. Но, несмотря на годы исследований, компьютеры все еще далеки от выполнения подобных задач на высоком уровне.
Человеческий мозг удивительно надежный: по сравнению с компьютером он не перестанет работать только потому, что несколько клеток погибнет, в то время как компьютер обычно не выдерживает каких-либо поломок в CPU. Но самой удивительной особенностью человеческого мозга является то, что он может учиться. Не нужно никакого программного обеспечения и никаких обновлений, если мы хотим научиться ездить на велосипеде.
Расчеты головного мозга производятся посредством тесно взаимосвязанных нейронных сетей, которые передают информацию, отсылая электрические импульсы через нейронные проводки, состоящие из аксонов, синапсов и дендритов. В 1943 году, компания McCulloch and Pitts смоделировала искусственный нейрон, как переключатель, который получает информацию от других нейронов и в зависимости от общего взвешенного входа, либо приводится в действие, либо остается неактивным. В узле ИНС пришедшие сигналы умножаются на соответствующие веса синапсов и суммируются. Эти коэффициенты могут быть как положительными (возбуждающими), так и отрицательными (тормозящими). В 1960 годах было доказано, что такие нейронные модели обладают свойствами, сходными с мозгом: они могут выполнять сложные операции распознавания образов, и они могут функционировать, даже если некоторые связи между нейронами разрушены. Демонстрация персептона Розенблатта показала, что простые сети из таких нейронов могут обучаться на примерах, известных в определенных областях. Позже, Минский и Паперт доказали, что простые пресептоны могут решать только очень узкий класс линейно сепарабельных задач (см. ниже), после чего активность изучения ИНС уменьшилась. Тем не менее, метод обратного распространения ошибки обучения, который может облегчить задачу обучения сложных нейронных сетей на примерах, показал, что эти проблемы могут быть и не сепарабельными.
Программа NETtalk применяла искусственные нейронные сети для машинного чтения текста и была первым широкоизвестным приложением. В биологии, точно такой же тип сети был применен для прогнозирования вторичной структуры белка; в самом деле, некоторые из лучших исследователей до сих пор пользуются тем же методом. С этого началась другая волна, вызвавшая интерес к исследованиям ИНС и поднявшая шумиху вокруг магического обучения мыслящих машин. Некоторые из наиболее важных ранних открытий приведены в 5 источнике.
ИНС могут быть созданы путем имитации модели сетей нейронов на компьютере. Используя алгоритмы, которые имитируют процессы реальных нейронов, мы можем заставить сеть «учиться», что помогает решить множество различных проблем. Модель нейрона представляется как пороговая величина (она проиллюстрирована на рисунке 1а). Модель получает данные от ряда других внешних источников, определяет значение каждого входа и добавляет эти значения. Если общий вход выше пороговой величины, то выход блока равен единице, в противном случае – нулю. Таким образом, выход изменяется от 0 до 1, когда общая «взвешенная» сумма входов равна пороговой величине. Точки в исходном пространстве, удовлетворяющие этому условию, определяют, так называемые, гиперплоскости. В двух измерениях, гиперплоскость – линия, в то время как в трех измерениях, гиперплоскость является нормальной (перпендикулярной) плоскостью. Точки с одной стороны от гиперплоскости классифицируются как 0, а точки с другой стороны – 1. Это означает, что задача классификации может быть решена с использованием пороговой величины, если два класса будут разделены гиперплоскостью. Эти проблемы называются линейно сепарабельными и изображены на рисунке 1b.
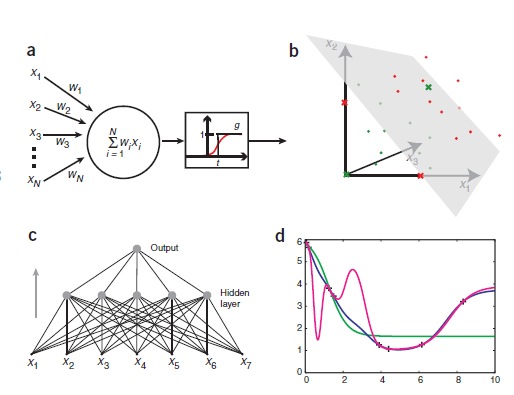
рисунок 1
Искусственные нейронные сети. (а) Графическое представление модели нейронной сети и порогового элемента McCulloch and Pitts. Пороговый блок получает входной сигнал от N других блоков или внешних источников, пронумерованных от 1 до N. Входной i называется xi и связывается с весом wi. Общий вход в устройство измерения суммы весов по всем входам, wixi=w1x1+w2x2+.. .+wNxΣi=1 N N.Если значение ниже порога t, то выход блока будет равен 1, в противном случае – 0. Таким образом, вывод может быть выражен как wixi Σi=1 – t g( N ), где g – ступенчатая функция, которая равна 0, если аргумент отрицателен, и 1, если аргумент положительный (фактическое значение в неле не имеет значения, здесь, мы выбрали 1). Так называемая, передаточная функция, g, также может быть неприрывной и «сигмоидальной», как показано красной линией. (b) Линейная сепарабельность (отделимость). В трех измерениях пороговое значение может классифицировать моменты, которые могут разделяться плоскостью. Каждая точка представляет входное значение х1, х2, х3 на пороге блока. Зеленые точки соответствуют точкамданных класса 0, и красные точки – 1. Зеленые и красные кресты иллюстрируют логическую функцию исключающего или. Найти плоскости, которые отделяют зеленые и красные точки, (или линии в х1, х2, плоскости) невозможно.(с) Однонаправленная ИНС. Показанная сеть занимает семь входов, имеет пять единиц в скрытом слое и один выход. Это двухслойная сеть, т.к. входной слой не выполняет никаких изменений и не учитывается. (d) переобучение. Восемь точек показаны плюсами на параболе (за исключением «экспериментального» шума). Они использованы для обучения трех различных ИНС. Сети воспринимают значения х в качестве входных данных (один вход) и обучаются с у значением, как желаемым результатом. Как и ожидалось, сеть с одним скрытым блоком (зеленая) не справляется с работой на высоком уровне. Сети с 10 скрытыми элементами (синяя) приближает основные функции на удивление хорошо. Последняя сеть с 20 скрытыми элементами (фиолетовая) перерабатывает информацию хорошо, сеть прекрасно обучилась, но для некоторых промежуточных областей она чрезмерно креативна.
Обучение
Если проблема классификации сепарабельна, то нам все еще нужно найти способ установления веса и пороговой величины таким образом, чтобы пороговое устройство решало задачу классификации правильно. Этого можно добиться путем постоянного добавления примеров из ранее известной классификации. Такой процесс называется обучением или тренировкой, так как он напоминает процесс изучения чего-либо человеком. Моделирование обучения с помощью компьютера предполагает постоянное изменение весов и порогов таким образом, что классификация приобретает более высокий уровень после каждого шага. Обучение может быть реализовано различными алгоритмами, об одном из таких алгоритмов мы поговорим позже.
Во время тренировки гиперплоскость движется то в одну сторону, то в другую, пока не найдет правильное положение в пространстве, после чего она уже не будет значительно изменяться. Такой процесс хорошо продемонстрирован программой Neural Java (http://lcn.epfl.ch/tutorial/english/index.html); следуйте по ссылке «Adline, Percepton and Backpropagation» (красные и синие точки представляют два класса) и нажмите «play».
Рассмотрим пример задачи, для которой легко применить искусственную нейронную сеть. Из двух видов рака, только один отвечает на определенные способы лечения. Так как не существует простых биомаркеров, позволяющих отличить эти два вида рака друг от друга, вы решаете измерить генную экспрессию образцов опухоли, что бы определить тип каждой опухоли. Предположим, вы измерили значения 20 различных генов в 50 опухолях класса 0 (нереагирующих) и 50 класса 1 (реагирующих). На основе этих данных, вы обучаете пороговое устройство, который принимает 20 значений генов в качестве входных данных и выдает 0 или 1 в качестве результата для определения одного из двух классов, соответственно. Если данные линейно сепарабельны, то пороговый блок будет классифицировать обучающие данные правильно.
Тем не менее, многие проблемы классификации не являются линейно сепарабельными. Мы можем разделить классы в таких нелинейных задачах путем введения большего количества гиперплоскостей, а именно за счет введения более чем одного порогового блока. Обычно это осуществляется добавлением дополнительного (скрытого) уровня порогового элемента, каждая из которых производит частичную классификацию входных данных и посылает выводные данные на последний уровень. На заключительном уровне собираются все частичные классификации для составления окончательной (рис. 1b). Такие сети называют многоуровневыми перцептонами или однонаправленной сетью. Однонаправленные нейронные сети также могут быть использованы для задач регрессии, которые требуют постоянного выхода, в отличие от бинарных выходов (0 и 1). Заменяя ступенчатую функцию непрерывной, мы получаем вещественное число в качестве выхода. Зачастую, когда используется «сигмоидальная» функция активации, она является временной пороговой функцией (рис. 1а). «Сигмоидальная» функция активации также может быть использована для задач классификации, интерпретируя выход ниже 0.5, как класс 0, и выход выше 0.5, как класс 1. Также имеет смысл интерпретировать результат как вероятность класса 1.
В вышеприведенном примере, также возможны следующие варианты: класс 1 характеризуется как ярко выраженный ген 1 и бессимптомный класс — 0, или наоборот. Если оба из генов ярко выражены или бессимптомны, то присваивается класс 0 (опухоль). Это соответствует исключающему логическому «или» и является каноническим примером нелинейно сепарабельной функции (рис. 1b). В данном случае, для классификации опухолей было необходимо использовать многоуровневую сеть.
Обратная передача ошибки обучения
Вышеуказанный алгоритм обратной передачи ошибки обучения работает на однонаправленных нейронных сетях с аналоговым выходом. Обучение начинается с установки всех весов в сеть малых случайных чисел. Теперь, для каждого входного примера сеть дает выход, который начинается случайно. Мы измеряем квадрат разности между этими двумя выходами и желаемыми результатами для соответствующего класса или значения. Сумма всех этих чисел за все учебные примеры называется общей ошибкой сети. Если число равно нулю, то сеть является идеальной, следовательно, чем меньше погрешность, тем лучше сеть.
При выборе весов, которые сведут суммарную погрешность к минимуму, мы получим нейронную сеть, решающую проблему лучшим способом. Это то же самое, что и линейная регрессия, где два параметра характеризуют выбранные линии так, чтобы сумма квадратов разностей между линией и информационными точками была минимальной. Такую задачу можно решить аналитически в линейной регрессии, но нет никакого решения в однонаправленных нейронных сетях со скрытыми элементами. В алгоритме обратной передачи ошибки, веса и пороги меняются каждый раз, когда предоставляется новый пример, таким образом, возможность ошибки постепенно становится меньше. Процесс повторяется сотни раз, пока ошибка не остается неизменной. Наглядное представление этого процесса можно найти на сайте Neural Java, который указан выше, перейдя по ссылке «Multi-layer Perceptron» (с выходом нейрона {0, 1}).
В алгоритме обратной передачи ошибки, численный метод оптимизации называется алгоритмом градиентного спуска, который особенно упрощает математические вычисления. Название этот алгоритм получил из-за формы уравнений, которые он помогает решить. Есть несколько параметров обучения (так называемый коэффициент обучения и импульса), которые нуждаются в настройке при использовании обратной передачи ошибки. Также существуют и другие проблемы, которые стоит рассмотреть. Например, алгоритм градиентного спуска не гарантирует нахождение глобального минимума ошибки, поэтому результат обучения зависит от начальных значений весов. Тем не менее, одна проблема затмевает все остальные: проблема переобучения.
Переобучение происходит, когда нейронная сеть имеет слишком много параметров, которые можно извлечь из числа имеющихся параметров, то есть, когда несколько пунктов соответствуют функции со слишком большим количеством свободных параметров (рис. 1d). Несмотря на то, что все эти методы подходят и для классификации, и для регрессии, нейронные сети обычно склонны к перепараметризации. Например, сеть с 10 скрытыми элементами для решения нашей проблемы будет иметь 221 параметр: 20 скрытых весов и пороговых величин, а также 10 весов и пороговых величин на выходе. Это слишком большое количество параметров, которые можно извлечь из 100 примеров. Сеть, которая слишком подходит для обучающих данных, вряд ли обобщит выходные данные, не являющиеся обучающими. Существует множество способов для ограничения переобучения сети (исключая создание маленькой сети), но наиболее распространенные включают усреднение по нескольким сетям, регуляризацию и использование метода Байесовской статистики.
Для оценки производительности нейронных сетей, необходимо тестировать их на независимых данных, которые не использовались во время обучения сети. Обычно производится перекрестная проверка, где набор данных делится, например, на несколько комплектов одинакового размера. Тогда, сеть обучается по 9 комплектам и тестируется на десятом, и эта операция повторяется десять раз, так что все наборы используются для тестирования. Это дает оценку способности сети к обобщению, то есть, ее способности классифицировать входные данные, которым сеть не была обучена. Чтобы получить объективную оценку, что является очень важным, отдельные наборы не должны содержать похожие примеры.
Расширения и приложения
И простой персептрон с одним блоком, и многослойные сети с несколькими устройствами могут быть легко обобщены для прогнозирования более чем двух параметров, простым добавлением большего количества выходных значений. Любая проблема классификации может быть закодирована набором бинарных выходов. В вышеприведенном примере, мы могли бы, например, представить, что существуют три различных метода лечения, и для данной опухоли мы хотим знать, какой из методов лечения будет эффективным. Проблема может быть решена использованием трех выходных элементов, по одному для каждого вида лечения, которые подключены к тем же скрытым единицам.
Нейронные сети применяются для многих интересных проблем в различных областях науки, медицины и техники, а в некоторых случаях они обеспечивают высокотехнологичные решения. Нейронные сети иногда случайно использовались для задач, где более простые методы давали лучшие результаты, тем самым давая плохую репутацию ИНС среди некоторых ученых.
Существуют и другие типы нейронных сетей, которые не описывались здесь. Например, машина Больцмана, неконтролируемые сети и сети Кохонена. Поддержка векторных машин тесно связанных с ИНС. Для более детального ознакомления, я советую книгу Криса Бишопа, старые книги с моим соавторством, книгу Дуда и др. Существует множество программ, которые можно использовать для создания ИНС, обученных по собственным данным. К ним относятся расширения и плагины для Microsoft Excell, Matlab, и R (http://www.r-project.org/), а также библиотеки кода и большие коммерческие пакеты. FANN библиотеки (http://leenissen.dk/fann/), которые используются для серьезных приложений. Она наполнена открытым программным кодом на С, но может быть вызвана из, например, Perl и Python программ.
Дополнительная литература
1. Minsky, M.L. & Papert, S.A. Perceptrons (MIT Press,Cambridge, 1969).
2. Rumelhart, D.E., Hinton, G.E. & Williams, R.J. Nature 323, 533–536 (1986).
3. Sejnowski, T.J. & Rosenberg, C.R. Complex Systems 1, 145–168 (1987).
4. Qian, N. & Sejnowski, T.J. J. Mol. Biol. 202, 865–884 (1988).
5. Anderson, J.A. & Rosenfeld, E. (eds). Neurocomputing: Foundations of Research (MIT Press, Cambridge, 1988).
6. Bishop, C.M. Neural Networks for Pattern Recognition (Oxford University Press, Oxford, 1995).
7. Noble, W.S. Nat. Biotechnol. 24, 1565–1567 (2006).
8. Bishop, C.M. Pattern Recognition and Machine Learning (Springer, New York, 2006).
9. Hertz, J.A., Krogh, A. & Palmer, R. Introduction to the Theory of Neural Computation (Addison-Wesley, Redwood City, 1991).
10. Duda, R.O., Hart, P.E. & Stork, D.G. Pattern Classification (Wiley Interscience, New York, 2000).
Перевод статьи (Anders Krogh NATURE BIOTECHNOLOGY VOLUME 26 NUMBER 2 FEBRUARY 2008)
