Любой администратор рано или поздно получает инструкцию от руководства: «посчитать, кто ходит в сеть, и сколько качает». Для провайдеров она дополняется задачами «пустить кого надо, взять оплату, ограничить доступ». Что считать? Как? Где? Отрывочных сведений много, они не структурированы. Избавим начинающего админа от утомительных поисков, снабдив его общими знаниями, и полезными ссылками на матчасть.
В данной статье я постараюсь описать принципы организации сбора, учёта и контроля трафика в сети. Мы рассмотрим проблематику вопроса, и перечислим возможные способы съема информации с сетевых устройств.
Это первая теоретическая статья из цикла статей, посвящённого сбору, учёту, управлению и биллингу трафика и IT-ресурсов.
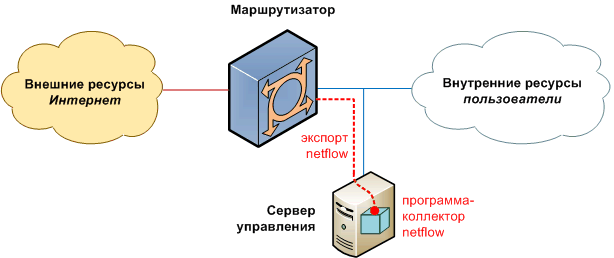
В общем случае, структура доступа в сеть выглядит следующим образом:
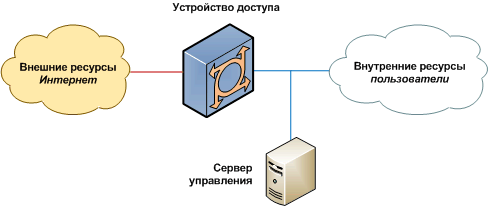
В данной структуре, сетевой трафик проходит от внешних ресурсов к внутренним, и обратно, через устройство доступа. Оно передает на сервер управления информацию о трафике. Сервер управления обрабатывает эту информацию, хранит в базе, отображает, выдает команды на блокировку. Однако, не все комбинации устройств (методов) доступа, и методов сбора и управления, совместимы. О различных вариантах и пойдет речь ниже.
Для начала необходимо определить, а что же подразумевается под «сетевым трафиком», и какую полезную статистическую информацию можно извлечь из потока пользовательских данных.
Доминирующим протоколом межсетевого взаимодействия пока остается IP версии 4. Протокол IP соответствует 3му уровню модели OSI (L3). Информация (данные) между отправителем и получателем упаковывается в пакеты – имеющие заголовок, и «полезную нагрузку». Заголовок определяет, откуда и куда идет пакет (IP-адреса отправителя и получателя), размер пакета, тип полезной нагрузки. Основную часть сетевого трафика составляют пакеты с полезной нагрузкой UDP и TCP – это протоколы 4-го уровня (L4). Помимо адресов, заголовок этих двух протоколов содержит номера портов, которые определяют тип службы (приложения), передающего данные.

Для передачи IP-пакета по проводам (или радио) сетевые устройства вынуждены «оборачивать» (инкапсулировать) его в пакет протокола 2го уровня (L2). Самым распространенным протоколом такого типа является Ethernet. Фактическая передача «в провод» идет на 1м уровне. Обычно, устройство доступа (маршрутизатор) не занимается анализом заголовков пакетов на уровне, выше 4го (исключение – интеллектуальные межсетевые экраны).
Информация из полей адресов, портов, протоколов и счетчики длин из L3 и L4 заголовков пакетов данных и составляет тот «исходный материал», который используется при учёте и управлении трафиком. Собственно объем передаваемой информации находится в поле Length («Длина пакета») заголовка IP (включая длину самого заголовка). Кстати, из-за фрагментации пакетов вследствие механизма MTU общий объем передаваемых данных всегда больше размера полезной нагрузки.
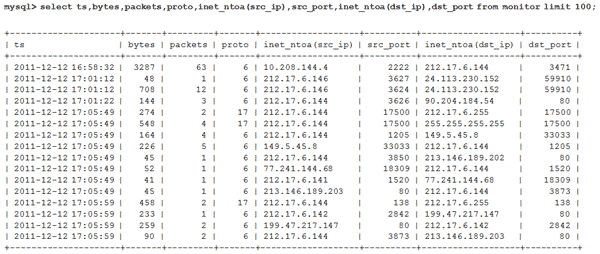
Суммарная длина интересных нам в данном контексте IP- и TCP/UDP- полей пакета составляет 2...10% общей длины пакета. Если обрабатывать и хранить всю эту информацию попакетно, не хватит никаких ресурсов. К счастью, подавляющий объем трафика структурирован так, что состоит из набора «диалогов» между внешними и внутренними сетевыми устройствами, так называемых «потоков». Например, в рамках одной операции пересылки электронного письма (протокол SMTP) открывается TCP-сессия между клиентом и сервером. Она характеризуется постоянным набором параметров {IP-адрес источника, TCP-порт источника, IP-адрес получателя TCP-порт получателя}. Вместо того, чтобы обрабатывать и хранить информацию попакетно, гораздо удобнее хранить параметры потока (адреса и порты), а также дополнительную информацию – число и сумму длин переданных пакетов в каждую сторону, опционально длительность сессии, индексы интерфейсов маршрутизатора, значение поля ToS и прочее. Такой подход выгоден для ориентированных на соединение протоколов (TCP), где можно явно перехватить момент завершения сессии. Однако и для не ориентированных на сессии протоколов можно проводить агрегацию и логическое завершение записи о потоке по, например, таймауту. Ниже приведена выдержка из SQL-базы собственной системы биллинга, осуществляющей протоколирование информации о потоках трафика:
Необходимо отметить случай, когда устройство доступа осуществляет трансляцию адресов (NAT, маскарадинг) для организации доступа в Интернет компьютеров локальной сети, используя один, внешний, публичный IP-адрес. В этом случае специальный механизм осуществляет подмену IP-адресов и TCP/UDP портов пакетов трафика, заменяя внутренние (не маршрутизируемые в Интернете) адреса согласно своей динамической таблице трансляции. В такой конфигурации необходимо помнить, что для корректного учета данных по внутренним хостам сети съём статистики должен производиться способом и в том месте, где результат трансляции ещё не «обезличивает» внутренние адреса.
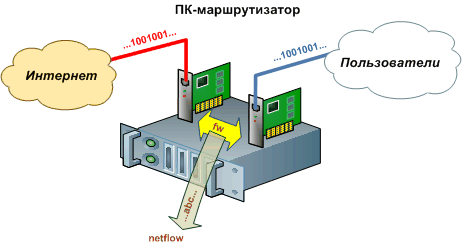
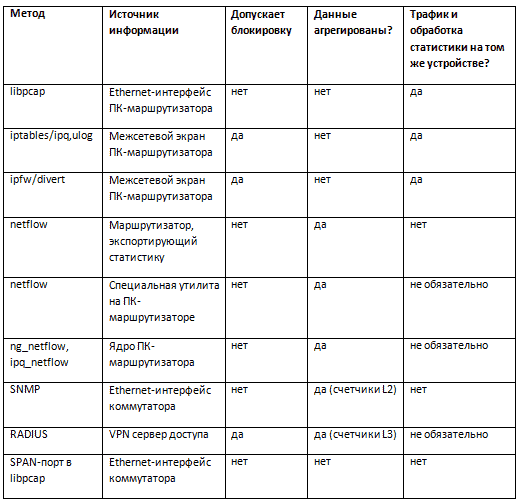
Снимать и обрабатывать информацию о проходящем трафике можно непосредственно на самом устройстве доступа (ПК-маршрутизатор, VPN-сервер), с этого устройства передавая ее на отдельный сервер (NetFlow, SNMP), или «с провода» (tap, SPAN). Разберем все варианты по-порядку.
Рассмотрим простейший случай – устройство доступа (маршрутизатор) на базе ПК c ОС Linux.
О том, как настроить такой сервер, трансляцию адресов и маршрутизацию, написано много . Нас же интересует следующий логический шаг – сведения о том, как получить информацию о проходящем через такой сервер трафике. Существует три распространенных способа:
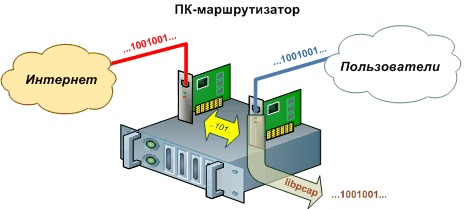
В первом случае копия пакета, проходящего через интерфейс, после прохождения фильтра (man pcap-filter) может быть запрошена клиентской программой на сервере, написанной с использованием данной библиотеки. Пакет поступает вместе с заголовком 2го уровня (Ethernet). Можно ограничить длину захватываемой информации (если нас интересует только информация из его заголовка). Примерами таких программ могут быть tcpdump и Wireshark. Существует реализация libpcap под Windows. В случае применения трансляции адресов на ПК-маршрутизаторе такой перехват можно осуществлять только на его внутреннем интерфейсе, подключенном к локальным пользователям. На внешнем интерфейсе, после трансляции, IP-пакеты не содержат информации о внутренних хостах сети. Однако при таком способе невозможно учесть трафик, создаваемый самим сервером в сети Интернет (что важно, если на нем работают веб– или почтовый сервис).
Работа libpcap требует поддержки со стороны операционной системы, что в настоящее время сводится к установке единственной бибилиотеки. При этом прикладная (пользовательская) программа, осуществляющая сбор пакетов, должна:
При передаче пакета через выбранный интерфейс, после прохождения фильтра эта функция получает буфер, содержащий Ethernet, (VLAN), IP и т.д. заголовки, общим размером до snaplen. Поскольку библиотека libcap копирует пакеты, заблокировать их прохождение при ее помощи невозможно. В таком случае программе сбора и обработки трафика придется использовать альтернативные методы, например вызов скрипта для помещения заданного IP-адреса в правило блокировки трафика.
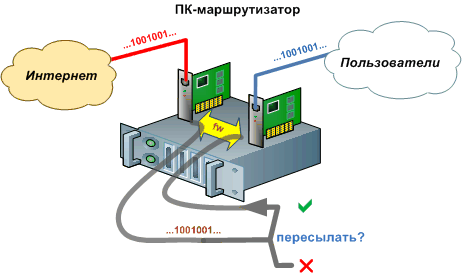
Захват данных, проходящих через межсетевой экран, позволяет учесть и трафик самого сервера, и трафик пользователей сети, даже при работе трансляции адресов. Главное в этом случае – правильно сформулировать правило захвата, и поставить его в нужное место. Данным правилом активируется передача пакета в сторону системной библиотеки, откуда приложение учета и управления трафиком может его получить. Для ОС Линукс в качестве межсетевого экрана применяют iptables, а средства перехвата – ipq, netfliter_queue или ulog. Для OC FreeBSD – ipfw с правилами типа tee или divert. В любом случае механизм межсетевого экрана дополняется возможностью работы с пользовательской программой следующим способом:
Поскольку IP-пакет не копируется, а пересылается в программное обеспечение для анализа, становится возможным его «выброс», а следовательно, полное или частичное ограничение трафика определенного типа (например, до выбранного абонента локальной сети). Однако в случае, если прикладная программа перестала отвечать ядру о своем решении (зависла, к примеру), трафик через сервер просто блокируется.
Необходимо отметить, что описанные механизмы при существенных объемах передаваемого трафика создают избыточную нагрузку на сервер, что связано с постоянным копированием данных из ядра в пользовательскую программу. Этого недостатка лишен метод сбора статистики на уровне ядра ОС, с выдачей в прикладную программу агрегированной статистики по протоколу NetFlow.
Этот протокол был разработан фирмой Cisco Systems для экспорта информации о трафике с маршрутизаторов с целью учета и анализа трафика. Наиболее популярная сейчас версия 5 предоставляет получателю поток структурированных данных в виде UDP-пакетов, содержащих информацию о прошедшем трафике в виде так называемых flow records:
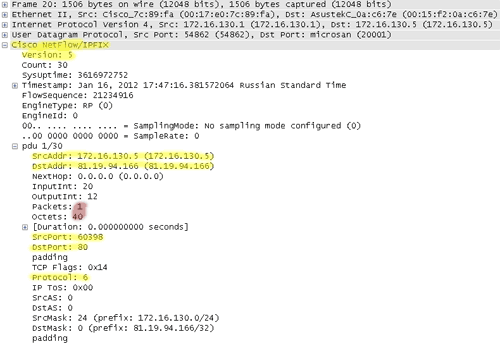
Объем информации о трафике меньше самого трафика на несколько порядков, что особенно актуально в больших и распределенных сетях. Конечно же, блокировать передачу информации при сборе статистики по netflow невозможно (если не использовать дополнительные механизмы).
В настоящее время становится популярным дальнейшее развитие этого протокола – версия 9, основанная на шаблонной структуре flow record, реализации для устройств других производителей (sFlow). Недавно был принят стандарт IPFIX, который позволяет передавать статистику и по протоколам более глубоких уровней (например, по типу приложения).
Реализация netflow-источников (агентов, probe) доступна для ПК-маршрутизаторов, как в виде работающих по описанных выше механизмам утилит (flowprobe, fprobe, softflowd), так и непосредственно встроенных в ядро ОС (FreeBSD: ng_netgraph, Linux: ipt_neflow). Для программных маршрутизаторов поток статистики netflow можно принимать и обрабатывать локально на самом маршрутизаторе, или отправлять по сети (протокол передачи – поверх UDP) на принимающее устройство (коллектор).
Программа — коллектор может собирать сведения от многих источников сразу, имея возможность различать их трафик даже при пересекающихся адресных пространствах. При помощи дополнительных средств, таких как nprobe возможно также проводить дополнительную агрегацию данных, раздвоение потоков или конвертацию протоколов, что актуально при управлении большой и распределенной сетью с десятками маршрутизаторов.
Функции экспорта netflow поддерживают маршрутизаторы Cisco Systems, Mikrotik, и некоторые другие. Аналогичный функционал (с другими протоколами экспорта) поддерживается всеми крупными производителями сетевого оборудования.
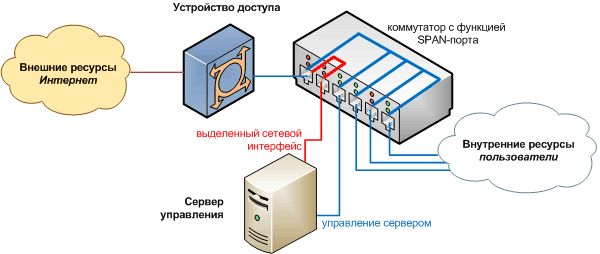
Немного усложним задачу. Что, если ваше устройство доступа – аппаратный маршрутизатор другого производителя? Например, D-Link, ASUS, Trendnet и т.д. На нем, скорее всего, невозможно поставить дополнительное программное средство съема данных. Как вариант – интеллектуальное устройство доступа у вас есть, но настроить его не представляется возможным (нет прав, или оно управляется вашим провайдером). В таком случае можно собирать информацию о трафике непосредственно в точке стыка устройства доступа с внутренней сетью, пользуясь «аппаратными» средствами копирования пакетов. В таком случае непременно потребуется отдельно стоящий сервер с выделенной сетевой картой для приема копий Ethernet-пакетов.
Сервер должен использовать механизм сбора пакетов по методу libpcap, описанному выше, и наша задача — на вход выделенной для этого сетевой карты подать поток данных, идентичный выходящему из сервера доступа. Для этого можно использовать:
Естественно, вы можете настроить SPAN-порт и на самом устройстве доступа (маршрутизаторе), если оно это позволяет – Cisco Catalyst 6500, Cisco ASA. Вот пример такой конфигурации для коммутатора Cisco:
Что, если маршрутизатора под нашим контролем нет, с netflow связываться нет желания, нас не интересуют детали трафика наших пользователей. Они просто подключены в сеть через управляемый коммутатор, и нам надо просто грубо оценить объем трафика, приходящегося на каждый из его портов. Как вы знаете, сетевые устройства с возможностью удаленного управления поддерживают, и могут отобразить счетчики пакетов (байт), проходящих через сетевые интерфейсы. Для их опроса правильно будет использовать стандартизованный протокол удаленного управления SNMP. При помощи его можно достаточно просто получить не только значения указанных счетчиков, но также другие параметры, такие как имя и описание интерфейса, видимые через него MAC-адреса, и другую полезную информацию. Это делается как утилитами командной строки (snmpwalk), графическими SNMP-браузерами, так и более сложными программами мониторинга сети (rrdtools, cacti, zabbix, whats up gold и т.д.). Однако, данный метод имеет два существенных недостатка:
Отдельно стоит рассмотреть случай доступа пользователей к сети путем явного установления соединения к серверу доступа. Классическим примером может служить старый добрый dial-up, аналогом которого в современном мире являются VPN-службы удаленного доступа (PPTP, PPPoE, L2TP, OpenVPN, IPSEC)
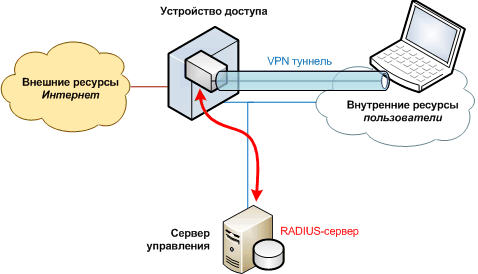
Устройство доступа не только маршрутизирует IP-трафик пользователей, но также представляет из себя специализированный VPN-сервер, и терминирует логические туннели (часто зашифрованные), внутри которых передается пользовательский трафик.
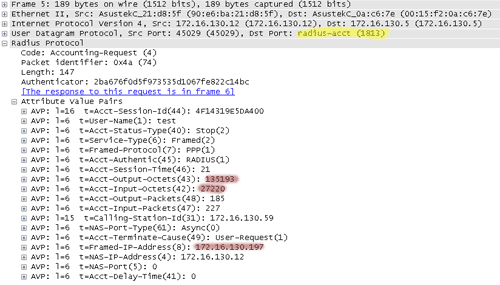
Для учета такого трафика можно пользоваться как всеми средствами, описанными выше (и для глубокого анализа по портам/протоколам они хорошо подходят), так и дополнительными механизмами, которые предоставляют средства управления VPN-доступом. В первую очередь речь пойдет о протоколе RADIUS. Его работа – достаточно сложная тема. Мы же кратко упомянем, что контролем (авторизацией) доступа к VPN-серверу (RADIUS-клиенту) управляет специальное приложение (RADIUS-сервер), имеющее за собой базу (текстовый файл, SQL, Active Directory) допустимых пользователей с их атрибутами (ограничения по скорости подключения, назначенные IP-адреса). Помимо процесса авторизации, клиент периодически передает серверу сообщения аккаунтинга, информацию о состоянии каждой текущей работающей VPN-сессии, в том числе счетчики переданных байт и пакетов.
Сведем все описанные выше методы сбора информации о трафике воедино:
Подведем небольшой итог. На практике существует большое количество методов присоединения управляемой вами сети (с клиентами или офисными абонентами) к внешней сетевой инфраструктуре, с использованием ряда средств доступа – программных и аппаратных маршрутизаторов, коммутаторов, VPN-серверов. Однако практически в любом случае можно придумать схему, когда информация о переданном по сети трафике может быть направлена на программное или аппаратное средство его анализа и управления. Возможно также, что это средство позволит осуществлять обратную связь с устройством доступа, применяя интеллектуальные алгоритмы ограничения доступа для отдельных клиентов, протоколов и прочего.
На этом закончу разбор матчасти. Из неразобранных тем остались:
В данной статье я постараюсь описать принципы организации сбора, учёта и контроля трафика в сети. Мы рассмотрим проблематику вопроса, и перечислим возможные способы съема информации с сетевых устройств.
Это первая теоретическая статья из цикла статей, посвящённого сбору, учёту, управлению и биллингу трафика и IT-ресурсов.
Структура доступа в сеть Интернет
В общем случае, структура доступа в сеть выглядит следующим образом:
- Внешние ресурсы – сеть Интернет, со всеми сайтами, серверами, адресами и прочим, что не принадлежит сети, которую вы контролируете.
- Устройство доступа – маршрутизатор (аппаратный, или на базе PC), коммутатор, VPN-сервер или концентратор.
- Внутренние ресурсы – набор компьютеров, подсетей, абонентов, работу которых в сети необходимо учитывать или контролировать.
- Сервер управления или учёта – устройство, на котором работает специализированное программное обеспечение. Может быть функционально совмещён с программным маршрутизатором.
В данной структуре, сетевой трафик проходит от внешних ресурсов к внутренним, и обратно, через устройство доступа. Оно передает на сервер управления информацию о трафике. Сервер управления обрабатывает эту информацию, хранит в базе, отображает, выдает команды на блокировку. Однако, не все комбинации устройств (методов) доступа, и методов сбора и управления, совместимы. О различных вариантах и пойдет речь ниже.
Сетевой трафик
Для начала необходимо определить, а что же подразумевается под «сетевым трафиком», и какую полезную статистическую информацию можно извлечь из потока пользовательских данных.
Доминирующим протоколом межсетевого взаимодействия пока остается IP версии 4. Протокол IP соответствует 3му уровню модели OSI (L3). Информация (данные) между отправителем и получателем упаковывается в пакеты – имеющие заголовок, и «полезную нагрузку». Заголовок определяет, откуда и куда идет пакет (IP-адреса отправителя и получателя), размер пакета, тип полезной нагрузки. Основную часть сетевого трафика составляют пакеты с полезной нагрузкой UDP и TCP – это протоколы 4-го уровня (L4). Помимо адресов, заголовок этих двух протоколов содержит номера портов, которые определяют тип службы (приложения), передающего данные.
Для передачи IP-пакета по проводам (или радио) сетевые устройства вынуждены «оборачивать» (инкапсулировать) его в пакет протокола 2го уровня (L2). Самым распространенным протоколом такого типа является Ethernet. Фактическая передача «в провод» идет на 1м уровне. Обычно, устройство доступа (маршрутизатор) не занимается анализом заголовков пакетов на уровне, выше 4го (исключение – интеллектуальные межсетевые экраны).
Информация из полей адресов, портов, протоколов и счетчики длин из L3 и L4 заголовков пакетов данных и составляет тот «исходный материал», который используется при учёте и управлении трафиком. Собственно объем передаваемой информации находится в поле Length («Длина пакета») заголовка IP (включая длину самого заголовка). Кстати, из-за фрагментации пакетов вследствие механизма MTU общий объем передаваемых данных всегда больше размера полезной нагрузки.
Суммарная длина интересных нам в данном контексте IP- и TCP/UDP- полей пакета составляет 2...10% общей длины пакета. Если обрабатывать и хранить всю эту информацию попакетно, не хватит никаких ресурсов. К счастью, подавляющий объем трафика структурирован так, что состоит из набора «диалогов» между внешними и внутренними сетевыми устройствами, так называемых «потоков». Например, в рамках одной операции пересылки электронного письма (протокол SMTP) открывается TCP-сессия между клиентом и сервером. Она характеризуется постоянным набором параметров {IP-адрес источника, TCP-порт источника, IP-адрес получателя TCP-порт получателя}. Вместо того, чтобы обрабатывать и хранить информацию попакетно, гораздо удобнее хранить параметры потока (адреса и порты), а также дополнительную информацию – число и сумму длин переданных пакетов в каждую сторону, опционально длительность сессии, индексы интерфейсов маршрутизатора, значение поля ToS и прочее. Такой подход выгоден для ориентированных на соединение протоколов (TCP), где можно явно перехватить момент завершения сессии. Однако и для не ориентированных на сессии протоколов можно проводить агрегацию и логическое завершение записи о потоке по, например, таймауту. Ниже приведена выдержка из SQL-базы собственной системы биллинга, осуществляющей протоколирование информации о потоках трафика:
Необходимо отметить случай, когда устройство доступа осуществляет трансляцию адресов (NAT, маскарадинг) для организации доступа в Интернет компьютеров локальной сети, используя один, внешний, публичный IP-адрес. В этом случае специальный механизм осуществляет подмену IP-адресов и TCP/UDP портов пакетов трафика, заменяя внутренние (не маршрутизируемые в Интернете) адреса согласно своей динамической таблице трансляции. В такой конфигурации необходимо помнить, что для корректного учета данных по внутренним хостам сети съём статистики должен производиться способом и в том месте, где результат трансляции ещё не «обезличивает» внутренние адреса.
Методы сбора информации о трафике/статистике
Снимать и обрабатывать информацию о проходящем трафике можно непосредственно на самом устройстве доступа (ПК-маршрутизатор, VPN-сервер), с этого устройства передавая ее на отдельный сервер (NetFlow, SNMP), или «с провода» (tap, SPAN). Разберем все варианты по-порядку.
ПК-маршрутизатор
Рассмотрим простейший случай – устройство доступа (маршрутизатор) на базе ПК c ОС Linux.
О том, как настроить такой сервер, трансляцию адресов и маршрутизацию, написано много . Нас же интересует следующий логический шаг – сведения о том, как получить информацию о проходящем через такой сервер трафике. Существует три распространенных способа:
- перехват (копирование) пакетов, проходящих через сетевую карту сервера, при помощи библиотеки libpcap
- перехват пакетов, проходящих через встроенный межсетевой экран
- использование сторонних средств преобразования попакетной статистики (полученной одним из двух предыдущих методов) в поток агрегированной информации netflow
Libpcap
В первом случае копия пакета, проходящего через интерфейс, после прохождения фильтра (man pcap-filter) может быть запрошена клиентской программой на сервере, написанной с использованием данной библиотеки. Пакет поступает вместе с заголовком 2го уровня (Ethernet). Можно ограничить длину захватываемой информации (если нас интересует только информация из его заголовка). Примерами таких программ могут быть tcpdump и Wireshark. Существует реализация libpcap под Windows. В случае применения трансляции адресов на ПК-маршрутизаторе такой перехват можно осуществлять только на его внутреннем интерфейсе, подключенном к локальным пользователям. На внешнем интерфейсе, после трансляции, IP-пакеты не содержат информации о внутренних хостах сети. Однако при таком способе невозможно учесть трафик, создаваемый самим сервером в сети Интернет (что важно, если на нем работают веб– или почтовый сервис).
Работа libpcap требует поддержки со стороны операционной системы, что в настоящее время сводится к установке единственной бибилиотеки. При этом прикладная (пользовательская) программа, осуществляющая сбор пакетов, должна:
- открыть необходимый интерфейс
- указать фильтр, через который пропускать принятые пакеты, размер захватываемой части (snaplen), размер буфера,
- задать параметр promisc, который переводит сетевой интерфейс в режим захвата вообще всех проходящих мимо пакетов, а не только адресованных MAC-адресу этого интерфейса
- установить функцию (callback), вызываемую на каждый принятый пакет.
При передаче пакета через выбранный интерфейс, после прохождения фильтра эта функция получает буфер, содержащий Ethernet, (VLAN), IP и т.д. заголовки, общим размером до snaplen. Поскольку библиотека libcap копирует пакеты, заблокировать их прохождение при ее помощи невозможно. В таком случае программе сбора и обработки трафика придется использовать альтернативные методы, например вызов скрипта для помещения заданного IP-адреса в правило блокировки трафика.
Межсетевой экран
Захват данных, проходящих через межсетевой экран, позволяет учесть и трафик самого сервера, и трафик пользователей сети, даже при работе трансляции адресов. Главное в этом случае – правильно сформулировать правило захвата, и поставить его в нужное место. Данным правилом активируется передача пакета в сторону системной библиотеки, откуда приложение учета и управления трафиком может его получить. Для ОС Линукс в качестве межсетевого экрана применяют iptables, а средства перехвата – ipq, netfliter_queue или ulog. Для OC FreeBSD – ipfw с правилами типа tee или divert. В любом случае механизм межсетевого экрана дополняется возможностью работы с пользовательской программой следующим способом:
- Пользовательская программа — обработчик трафика регистрирует себя в системе, используя системный вызов, или библиотеку.
- Пользовательская программа или внешний скрипт устанавливает правило в межсетевой экран, “заворачивающее” выбранный трафик (согласно правилу) вовнутрь обработчика.
- На каждый проходящий пакет обработчик получает его содержимое в виде буфера памяти (с заголовками IP и т.д. После обработки (учёта) программе необходимо также сообщить ядру операционной системы, что делать далее с таким пакетом — отбросить или передать далее. Как вариант, возможно передать ядру видоизмененный пакет.
Поскольку IP-пакет не копируется, а пересылается в программное обеспечение для анализа, становится возможным его «выброс», а следовательно, полное или частичное ограничение трафика определенного типа (например, до выбранного абонента локальной сети). Однако в случае, если прикладная программа перестала отвечать ядру о своем решении (зависла, к примеру), трафик через сервер просто блокируется.
Необходимо отметить, что описанные механизмы при существенных объемах передаваемого трафика создают избыточную нагрузку на сервер, что связано с постоянным копированием данных из ядра в пользовательскую программу. Этого недостатка лишен метод сбора статистики на уровне ядра ОС, с выдачей в прикладную программу агрегированной статистики по протоколу NetFlow.
Netflow
Этот протокол был разработан фирмой Cisco Systems для экспорта информации о трафике с маршрутизаторов с целью учета и анализа трафика. Наиболее популярная сейчас версия 5 предоставляет получателю поток структурированных данных в виде UDP-пакетов, содержащих информацию о прошедшем трафике в виде так называемых flow records:
Объем информации о трафике меньше самого трафика на несколько порядков, что особенно актуально в больших и распределенных сетях. Конечно же, блокировать передачу информации при сборе статистики по netflow невозможно (если не использовать дополнительные механизмы).
В настоящее время становится популярным дальнейшее развитие этого протокола – версия 9, основанная на шаблонной структуре flow record, реализации для устройств других производителей (sFlow). Недавно был принят стандарт IPFIX, который позволяет передавать статистику и по протоколам более глубоких уровней (например, по типу приложения).
Реализация netflow-источников (агентов, probe) доступна для ПК-маршрутизаторов, как в виде работающих по описанных выше механизмам утилит (flowprobe, fprobe, softflowd), так и непосредственно встроенных в ядро ОС (FreeBSD: ng_netgraph, Linux: ipt_neflow). Для программных маршрутизаторов поток статистики netflow можно принимать и обрабатывать локально на самом маршрутизаторе, или отправлять по сети (протокол передачи – поверх UDP) на принимающее устройство (коллектор).
Программа — коллектор может собирать сведения от многих источников сразу, имея возможность различать их трафик даже при пересекающихся адресных пространствах. При помощи дополнительных средств, таких как nprobe возможно также проводить дополнительную агрегацию данных, раздвоение потоков или конвертацию протоколов, что актуально при управлении большой и распределенной сетью с десятками маршрутизаторов.
Функции экспорта netflow поддерживают маршрутизаторы Cisco Systems, Mikrotik, и некоторые другие. Аналогичный функционал (с другими протоколами экспорта) поддерживается всеми крупными производителями сетевого оборудования.
Libpcap “снаружи”
Немного усложним задачу. Что, если ваше устройство доступа – аппаратный маршрутизатор другого производителя? Например, D-Link, ASUS, Trendnet и т.д. На нем, скорее всего, невозможно поставить дополнительное программное средство съема данных. Как вариант – интеллектуальное устройство доступа у вас есть, но настроить его не представляется возможным (нет прав, или оно управляется вашим провайдером). В таком случае можно собирать информацию о трафике непосредственно в точке стыка устройства доступа с внутренней сетью, пользуясь «аппаратными» средствами копирования пакетов. В таком случае непременно потребуется отдельно стоящий сервер с выделенной сетевой картой для приема копий Ethernet-пакетов.
Сервер должен использовать механизм сбора пакетов по методу libpcap, описанному выше, и наша задача — на вход выделенной для этого сетевой карты подать поток данных, идентичный выходящему из сервера доступа. Для этого можно использовать:
- Ethernet – хаб (hub): устройство, просто пересылающее пакеты между всеми своими портами без разбора. В современных реалиях его можно найти где-нибудь на пыльном складе, и применять такой метод не рекомендуется: ненадежно, низкая скорость (хабов на скорости 1 Гбит/с не бывает)
- Ethernet – коммутатор с возможностью зеркалирования (мирроринга, SPAN портов. Современные интеллектуальные (и дорогие) коммутаторы позволяют копировать на указанный порт весь трафик (входящий, выходящий, оба) другого физического интерфейса, VLANа, в том числе удаленного (RSPAN)
- Аппаратный раздвоитель, который может потребовать установки для сбора двух сетевых карт вместо одной – и это помимо основной, системной.
Естественно, вы можете настроить SPAN-порт и на самом устройстве доступа (маршрутизаторе), если оно это позволяет – Cisco Catalyst 6500, Cisco ASA. Вот пример такой конфигурации для коммутатора Cisco:
monitor session 1 source vlan 100 ! откуда берем пакеты
monitor session 1 destination interface Gi6/3! куда выдаем пакетыSNMP
Что, если маршрутизатора под нашим контролем нет, с netflow связываться нет желания, нас не интересуют детали трафика наших пользователей. Они просто подключены в сеть через управляемый коммутатор, и нам надо просто грубо оценить объем трафика, приходящегося на каждый из его портов. Как вы знаете, сетевые устройства с возможностью удаленного управления поддерживают, и могут отобразить счетчики пакетов (байт), проходящих через сетевые интерфейсы. Для их опроса правильно будет использовать стандартизованный протокол удаленного управления SNMP. При помощи его можно достаточно просто получить не только значения указанных счетчиков, но также другие параметры, такие как имя и описание интерфейса, видимые через него MAC-адреса, и другую полезную информацию. Это делается как утилитами командной строки (snmpwalk), графическими SNMP-браузерами, так и более сложными программами мониторинга сети (rrdtools, cacti, zabbix, whats up gold и т.д.). Однако, данный метод имеет два существенных недостатка:
- блокировка трафика может производиться только путем полного отключения интерфейса, при помощи того же SNMP
- счетчики трафика, снимаемые по SNMP, относятся к сумме длин Ethernet-пакетов (причем unicast, broadcast и multicast по-отдельности), в то время как остальные описанные ранее средства дают величины относительно IP-пакетов. Это создает заметное расхождение (особенно на коротких пакетах) из-за оверхеда, вызванного длиной Ethernet-заголовка (впрочем, с этим можно приближенно бороться: L3_байт = L2_байт — L2_пакетов*38).
VPN
Отдельно стоит рассмотреть случай доступа пользователей к сети путем явного установления соединения к серверу доступа. Классическим примером может служить старый добрый dial-up, аналогом которого в современном мире являются VPN-службы удаленного доступа (PPTP, PPPoE, L2TP, OpenVPN, IPSEC)
Устройство доступа не только маршрутизирует IP-трафик пользователей, но также представляет из себя специализированный VPN-сервер, и терминирует логические туннели (часто зашифрованные), внутри которых передается пользовательский трафик.
Для учета такого трафика можно пользоваться как всеми средствами, описанными выше (и для глубокого анализа по портам/протоколам они хорошо подходят), так и дополнительными механизмами, которые предоставляют средства управления VPN-доступом. В первую очередь речь пойдет о протоколе RADIUS. Его работа – достаточно сложная тема. Мы же кратко упомянем, что контролем (авторизацией) доступа к VPN-серверу (RADIUS-клиенту) управляет специальное приложение (RADIUS-сервер), имеющее за собой базу (текстовый файл, SQL, Active Directory) допустимых пользователей с их атрибутами (ограничения по скорости подключения, назначенные IP-адреса). Помимо процесса авторизации, клиент периодически передает серверу сообщения аккаунтинга, информацию о состоянии каждой текущей работающей VPN-сессии, в том числе счетчики переданных байт и пакетов.
Заключение
Сведем все описанные выше методы сбора информации о трафике воедино:
Подведем небольшой итог. На практике существует большое количество методов присоединения управляемой вами сети (с клиентами или офисными абонентами) к внешней сетевой инфраструктуре, с использованием ряда средств доступа – программных и аппаратных маршрутизаторов, коммутаторов, VPN-серверов. Однако практически в любом случае можно придумать схему, когда информация о переданном по сети трафике может быть направлена на программное или аппаратное средство его анализа и управления. Возможно также, что это средство позволит осуществлять обратную связь с устройством доступа, применяя интеллектуальные алгоритмы ограничения доступа для отдельных клиентов, протоколов и прочего.
На этом закончу разбор матчасти. Из неразобранных тем остались:
- как и куда попадают собранные данные о трафике
- программное обеспечение для учета трафика
- чем отличается биллинг от простой “считалки”
- как можно накладывать ограничение на трафик
- учёт и ограничение посещенных веб-сайтов
