Если вкратце, потому что мы жадные.
Мы продвинутые пользователи Matlab. Некоторые из нас хакеры Lisp. Некоторые питонисты, другие рубисты, есть ещё Perl-хакеры. Среди нас есть такие, кто использовал Mathematica раньше, чем у него начали расти волосы на лице. Есть и такие, у кого до сих пор не выросли. Мы построили больше графиков на R, чем способен любой здравомыслящий человек. C — это язык, который мы бы взяли на необитаемый остров.
Мы любим все эти языки; они прекрасны и могучи. Для той работы, которую мы делаем — научные вычисления, машинное обучение, дата-майнинг, крупномасштабная линейная алгебра, распределённые и параллельные вычисления — каждый идеально подходит в определённом аспекте, но ужасен в других. Каждый из них — это компромисс.
Мы жадные: мы хотим больше.
Мы хотим язык с открытыми исходниками, под свободной лицензией. Мы хотим скорость C и динамизм Ruby. Мы хотим язык с равнозначностью кода и данных, с настоящими макросами как в Lisp, но с очевидными, знакомыми математическими нотациями, как в Matlab. Мы хотим удобное средство для обобщённого программирования как Python, простое для статистики как R, естественную обработку строк как Perl, мощную линейную алгебру как Matlab, хорошую склейку программ как shell. Что-то абсолютно простое в изучении, но при этом делающее счастливыми большинство серьёзных хакеров. Мы хотим это интерактивным и мы хотим это скомпилированным.
(Мы упомянули, что оно должно быть быстрым, как C?)
Пока мы продолжаем требовать, добавим ещё что-нибудь, обеспечивающее распределённую производительность Hadoop — без килобайтов boilerplate-кода Java и XML; без необходимости пробираться через гигабайты логов на сотнях машин, чтобы отловить баги. Мы хотим мощь без оболочек непроходимой сложности. Мы хотим писать простые скалярные циклы, которые компилируются в компактный машинный код, используя только регистры на одном CPU. Мы хотим написать A*B и запустить тысячу процессов на тысяче машин, вместе вычисляющих огромную матрицу.
Мы не хотим упоминать типы данных без необходимости. Но если нам нужны полиморфные функции, мы хотим использовать обобщённое программирование для записи алгоритма один раз и применения его к бесконечной решётке типов; мы хотим использовать множественную диспетчеризацию для эффективного выбора лучшего метода для всех аргументов функции, из десятков описаний метода, обеспечивая общую функциональность среди радикально различных типов. Несмотря на всю эту мощь, мы хотим, чтобы язык был простым и ясным.
Мы ведь не слишком многого просим, верно?
Даже хотя мы осознаём свою непозволительную жадность, мы по-прежнему хотим всё это. Около двух с половиной лет назад мы начали создавать язык своей мечты. Он ещё не закончен, но пришло время для релиза 1.0 — язык программирования, который мы создали, называется Джулия. Она уже удовлетворяет 90% наших грубых запросов, и теперь ей нужно ещё больше грубых запросов от других людей, чтобы развиваться дальше. Так что, если вы жадный, безрассудный, требовательный программист, вы должны попробовать.
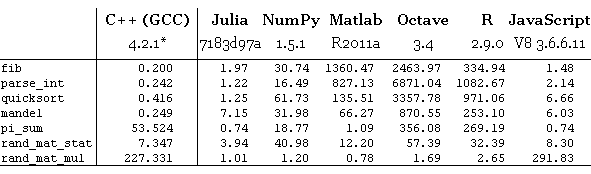
Микробенчмарк на MacBook Pro с 2,53 ГГц Intel Core 2 Duo CPU и 8 ГБ DDR3 RAM 1066 МГц, для C++ указано абсолютное время выполнения в миллисекундах, остальные относительно к C++ (меньше — лучше)
Исходники всех бенчмарков
Пример кода Julia для множества Мандельброта и статистики случайных матриц
Мы продвинутые пользователи Matlab. Некоторые из нас хакеры Lisp. Некоторые питонисты, другие рубисты, есть ещё Perl-хакеры. Среди нас есть такие, кто использовал Mathematica раньше, чем у него начали расти волосы на лице. Есть и такие, у кого до сих пор не выросли. Мы построили больше графиков на R, чем способен любой здравомыслящий человек. C — это язык, который мы бы взяли на необитаемый остров.
Мы любим все эти языки; они прекрасны и могучи. Для той работы, которую мы делаем — научные вычисления, машинное обучение, дата-майнинг, крупномасштабная линейная алгебра, распределённые и параллельные вычисления — каждый идеально подходит в определённом аспекте, но ужасен в других. Каждый из них — это компромисс.
Мы жадные: мы хотим больше.
Мы хотим язык с открытыми исходниками, под свободной лицензией. Мы хотим скорость C и динамизм Ruby. Мы хотим язык с равнозначностью кода и данных, с настоящими макросами как в Lisp, но с очевидными, знакомыми математическими нотациями, как в Matlab. Мы хотим удобное средство для обобщённого программирования как Python, простое для статистики как R, естественную обработку строк как Perl, мощную линейную алгебру как Matlab, хорошую склейку программ как shell. Что-то абсолютно простое в изучении, но при этом делающее счастливыми большинство серьёзных хакеров. Мы хотим это интерактивным и мы хотим это скомпилированным.
(Мы упомянули, что оно должно быть быстрым, как C?)
Пока мы продолжаем требовать, добавим ещё что-нибудь, обеспечивающее распределённую производительность Hadoop — без килобайтов boilerplate-кода Java и XML; без необходимости пробираться через гигабайты логов на сотнях машин, чтобы отловить баги. Мы хотим мощь без оболочек непроходимой сложности. Мы хотим писать простые скалярные циклы, которые компилируются в компактный машинный код, используя только регистры на одном CPU. Мы хотим написать A*B и запустить тысячу процессов на тысяче машин, вместе вычисляющих огромную матрицу.
Мы не хотим упоминать типы данных без необходимости. Но если нам нужны полиморфные функции, мы хотим использовать обобщённое программирование для записи алгоритма один раз и применения его к бесконечной решётке типов; мы хотим использовать множественную диспетчеризацию для эффективного выбора лучшего метода для всех аргументов функции, из десятков описаний метода, обеспечивая общую функциональность среди радикально различных типов. Несмотря на всю эту мощь, мы хотим, чтобы язык был простым и ясным.
Мы ведь не слишком многого просим, верно?
Даже хотя мы осознаём свою непозволительную жадность, мы по-прежнему хотим всё это. Около двух с половиной лет назад мы начали создавать язык своей мечты. Он ещё не закончен, но пришло время для релиза 1.0 — язык программирования, который мы создали, называется Джулия. Она уже удовлетворяет 90% наших грубых запросов, и теперь ей нужно ещё больше грубых запросов от других людей, чтобы развиваться дальше. Так что, если вы жадный, безрассудный, требовательный программист, вы должны попробовать.

Микробенчмарк на MacBook Pro с 2,53 ГГц Intel Core 2 Duo CPU и 8 ГБ DDR3 RAM 1066 МГц, для C++ указано абсолютное время выполнения в миллисекундах, остальные относительно к C++ (меньше — лучше)
Исходники всех бенчмарков
Пример кода Julia для множества Мандельброта и статистики случайных матриц
function mandel(z)
c = z
maxiter = 80
for n = 1:maxiter
if abs(z) > 2
return n-1
end
z = z^2 + c
end
return maxiter
end
function randmatstat(t)
n = 5
v = zeros(t)
w = zeros(t)
for i = 1:t
a = randn(n,n)
b = randn(n,n)
c = randn(n,n)
d = randn(n,n)
P = [a b c d]
Q = [a b; c d]
v[i] = trace((P.'*P)^4)
w[i] = trace((Q.'*Q)^4)
end
std(v)/mean(v), std(w)/mean(w)
end