Моя любимая тема в программировании — копаться в негативных эффектах, которые преподносят нам самые, на наш взгляд, тривиальные операции.
Один из таких вопросов — удаление записей в базе данных. Данная операция, по мнению большинства программистов, ускоряет работу с базой и делает её компактнее. Фокус состоит в том, что это неправда. И если с реляционными базами это неправда только отчасти, то с NoSQL это может быть полнейшим враньём.
Вот о такой проблеме в Apache CouchDB мы и поговорим далее.
Картинка в тему:
Данные в любой базе хранятся по принципу файловой системы: есть карта размещения данных и файл, в котором они непосредственно размещаются. Для SQL это обычно таблица, а для NoSQL — обычно дерево.
Когда мы удаляем данные, как и в случае файловой системы, база не будет тратить время на то, чтобы пересоздать файл карты и файл данных без записи, которую мы хотим удалить. Она просто пометит запись как удалённую в карте. В этом легко убедиться, для этого создадим простую таблицу в MySQL, используя MyISAM, добавим туда одну запись, затем удалим и посмотрим статистику:

Чтобы оптимизировать это, нам нужно пересоздать файл карты и файл данных. Выполним:
и получим:

Интересно, что таблица в неоптимизированном варианте, как это ни странно, работает почти так же быстро, как и в оптимизированном. Происходит это потому, что сам принцип хранения реляционных данных обычно довольно прост и легко рассчитать, насколько нужно сделать seek, чтобы пропустить удалённые записи. Вышесказанное, конечно, не означает, что overhead можно игнорировать, однако достаточно написать простейший bash-скрипт, который по расписанию будет оптимизировать данные, и никакой дополнительной работы в программном коде делать не придётся.
Возьмём простой документ:
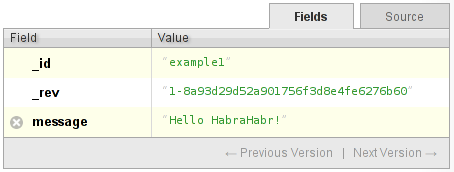
и удалим его. Что происходит? База помечает документ как удалённый. Как она это делает? Она считывает документ, удаляет из него все поля, вставляет дополнительное свойство _deleted:true и записывает документ под новой ревизией. Пример:

Теперь, если вы попробуете получить документ последней версии, вы получите ошибку 404 с указанием того, что документ удалён. Однако, если обратиться к первой ревизии документа, она будет доступна.
Далее делаем compact. Для удалённых документов база автоматически удалит все ревизии, кроме той, которая говорит о том, что документ удалён. Это делается для того, чтобы при репликации сообщить другой базе об этом. Эта ревизия навсегда остаётся в базе и не может быть удалена. (Правда, можно использовать _purge, но это костыль с большим количеством негативных эффектов и не рекомендуется для продакшена.)
В CouchDB данные хранятся в виде B+ дерева. Удалённый документ, хоть он и пустышка, остаётся частью дерева. Это значит, что эта мёртвая запись учитывается. И учитывается она не только при построении индексов, но и при обычной вставке документа, так как при вставке документа может происходить перестроение дерева, а чем больше там записей, тем этот процесс медленнее.
И наконец, остаётся понять, насколько Erlang быстр. Вот если взять синтетические тесты, то видно, что производительность Эрланга близка к PHP. То есть B+ деревом манипулирует не самый быстрый язык.
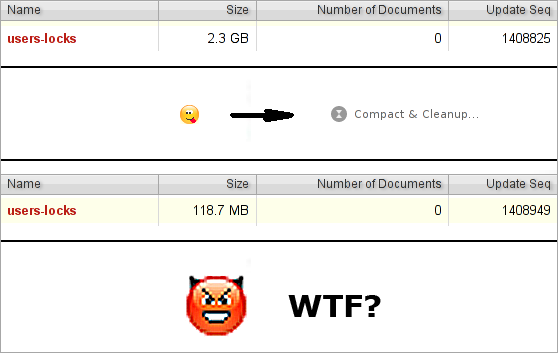
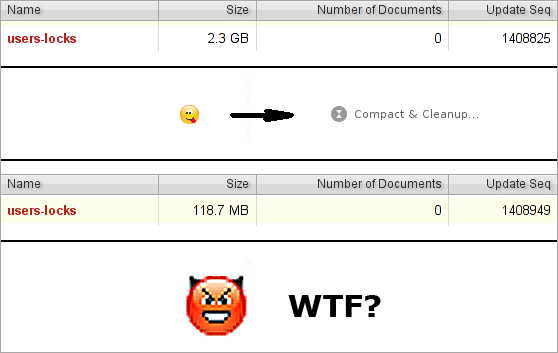
Если WRITE у вас не самая редкая операция, то, имея в дереве несколько миллионов документов, вы неожиданно (причём именно неожиданно) можете обнаружить, что база начинает сильно тормозить. Например, вы используете CouchDB, чтобы хранить документы с низкой продолжительностью жизни (сессии, lock-файлы, очереди). Возьмём график с реального продакшена:
Из графика видно, что пики довольно-таки острые. Резкий рост пика не всегда предсказуем. Порой у нас около 2 млн. обновлений базы (около 1 млн. документов в дереве) и работает вполне сносно, но появляется ещё 100 тысяч, и производительность вылетает в трубу. А резкий спад пика происходит потому, что мы пересоздаём базу и производительность на несколько недель становится приемлемой.
Один из таких вопросов — удаление записей в базе данных. Данная операция, по мнению большинства программистов, ускоряет работу с базой и делает её компактнее. Фокус состоит в том, что это неправда. И если с реляционными базами это неправда только отчасти, то с NoSQL это может быть полнейшим враньём.
Вот о такой проблеме в Apache CouchDB мы и поговорим далее.
Картинка в тему:
Как хранятся данные
Данные в любой базе хранятся по принципу файловой системы: есть карта размещения данных и файл, в котором они непосредственно размещаются. Для SQL это обычно таблица, а для NoSQL — обычно дерево.
Когда мы удаляем данные, как и в случае файловой системы, база не будет тратить время на то, чтобы пересоздать файл карты и файл данных без записи, которую мы хотим удалить. Она просто пометит запись как удалённую в карте. В этом легко убедиться, для этого создадим простую таблицу в MySQL, используя MyISAM, добавим туда одну запись, затем удалим и посмотрим статистику:

Чтобы оптимизировать это, нам нужно пересоздать файл карты и файл данных. Выполним:
OPTIMIZE TABLE guest;и получим:

Интересно, что таблица в неоптимизированном варианте, как это ни странно, работает почти так же быстро, как и в оптимизированном. Происходит это потому, что сам принцип хранения реляционных данных обычно довольно прост и легко рассчитать, насколько нужно сделать seek, чтобы пропустить удалённые записи. Вышесказанное, конечно, не означает, что overhead можно игнорировать, однако достаточно написать простейший bash-скрипт, который по расписанию будет оптимизировать данные, и никакой дополнительной работы в программном коде делать не придётся.
Надо отметить, что вышесказанное не совсем подходит для InnoDB, где ньюансов ещё больше, но сегодня статья о CouchDB, а не о MySQL.
Как работает удаление в CouchDB
Возьмём простой документ:
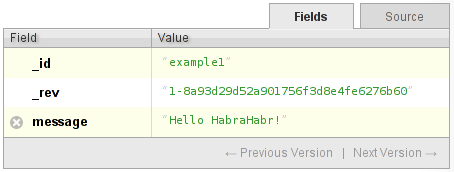
и удалим его. Что происходит? База помечает документ как удалённый. Как она это делает? Она считывает документ, удаляет из него все поля, вставляет дополнительное свойство _deleted:true и записывает документ под новой ревизией. Пример:

Теперь, если вы попробуете получить документ последней версии, вы получите ошибку 404 с указанием того, что документ удалён. Однако, если обратиться к первой ревизии документа, она будет доступна.
Далее делаем compact. Для удалённых документов база автоматически удалит все ревизии, кроме той, которая говорит о том, что документ удалён. Это делается для того, чтобы при репликации сообщить другой базе об этом. Эта ревизия навсегда остаётся в базе и не может быть удалена. (Правда, можно использовать _purge, но это костыль с большим количеством негативных эффектов и не рекомендуется для продакшена.)
Как это влияет на работу
В CouchDB данные хранятся в виде B+ дерева. Удалённый документ, хоть он и пустышка, остаётся частью дерева. Это значит, что эта мёртвая запись учитывается. И учитывается она не только при построении индексов, но и при обычной вставке документа, так как при вставке документа может происходить перестроение дерева, а чем больше там записей, тем этот процесс медленнее.
Контрольный в голову
И наконец, остаётся понять, насколько Erlang быстр. Вот если взять синтетические тесты, то видно, что производительность Эрланга близка к PHP. То есть B+ деревом манипулирует не самый быстрый язык.
Как это тормозит в реальности
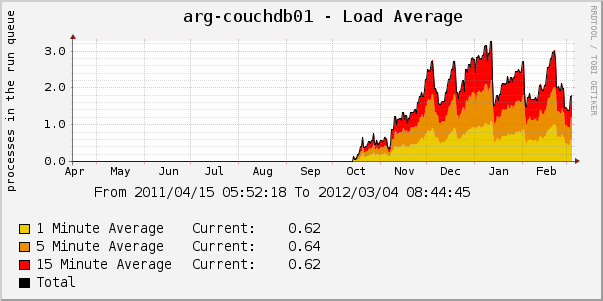
Если WRITE у вас не самая редкая операция, то, имея в дереве несколько миллионов документов, вы неожиданно (причём именно неожиданно) можете обнаружить, что база начинает сильно тормозить. Например, вы используете CouchDB, чтобы хранить документы с низкой продолжительностью жизни (сессии, lock-файлы, очереди). Возьмём график с реального продакшена:
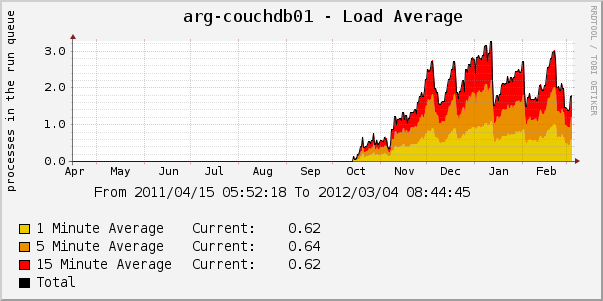
Из графика видно, что пики довольно-таки острые. Резкий рост пика не всегда предсказуем. Порой у нас около 2 млн. обновлений базы (около 1 млн. документов в дереве) и работает вполне сносно, но появляется ещё 100 тысяч, и производительность вылетает в трубу. А резкий спад пика происходит потому, что мы пересоздаём базу и производительность на несколько недель становится приемлемой.
Выводы
- CouchDB хранит все документы в B+ дереве, которое периодически перестраивается. Язык Erlang не самый быстрый для этого. Не используйте CouchDB для документов с низкой продолжительностью жизни, иначе у вас будет слишком большое дерево, ибо документы из него никогда не удаляются.
- Даже если вы не будете удалять документы, вы получите лаг на добавление новых, когда у вас будет несколько милионов записей.
- Советую обратить внимание на статью 16 практических советов по работе с CouchDB.
- Становится понятно, почему Дэмиен Кац, создатель CouchDB, решил сделать форк CouchBase и переписать ядро на Си. Кстати, CouchBase содержит встроенный memcached, который позволяет хранить документы с низкой продолжительностью жизни в отдельной области.
