Недавно захотелось вспомнить свое «шпионское» детство и хотя бы базово изучить разные методы шифрования. И первым выбор пал на шифр Виженера. Сам по себе он не является чрезвычайно сложным, но достаточно долго считался криптоустойчивым. Века эдак с XV и к самому XIX, пока некто Казиски полностью не взломал шифр.
Однако ограничим цитирование Википедии только описанием самого алгоритма.
Метод является усовершенствованным шифром Цезаря, где буквы смещались на определенную позицию.
Шифр Виженера состоит из последовательности нескольких шифров Цезаря с различными значениями сдвига.
Допустим у нас есть некий алфавит, где каждой букве соответствуют цифры:
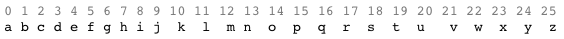
Тогда если буквы a-z соответствуют числам 0-25, то шифрование Виженера можно записать в виде формулы:
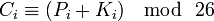
Расшифровка:
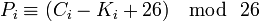
По сути нам больше ничего и не нужно кроме двух этих формул и мы можем приступить к реализации.
Тут хочу сказать, что я постарался реализовать алгоритм не проще и изящнее, а наиболее понятно и развернуто.
Собственно приступим-с.
Закодируем слова 'Hello world' с хитрым ключом 'key'.
Сначала необходимо создать словарь символов, которые будут участвовать в шифровании:
Дальше необходимо сопоставить буквы в нашем слове с буквами в словаре и присвоить им соответствующие числовые индексы
И так мы закодировали наше слово и ключ и получили 2 списка индексов:
Value= [72, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
Key = [107, 101, 121]
Дальше мы сопоставляем индексы ключа с индексами нашего слова функцией full_encode():
Получаем наш индексы шифра и переводим их в строку функцией decode_val():
{0: [72, 107], 1: [101, 101], 2: [108, 121], 3: [108, 107], 4: [111, 101], 5: [32, 121], 6: [119, 107], 7: [111, 101], 8: [114, 121], 9: [108, 107], 10: [100, 101]}
Индексы: [52, 75, 102, 88, 85, 26, 99, 85, 108, 88, 74]
Получаем закодированное суперсекретное послание: 4KfXUcUlXJ
Раскодировать же все это можно с помощью функции full_decode(), первым аргументом которой есть список числовых индексов шифра, а вторым — список индексов ключа:
Все так же получаем индексы шифра и переводим их в строку уже знакомой функцией decode_val():
[72, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
И вуаля! Наше зашифрованное слово: Hello world
Ну и главный вызов
В статье постарался все описать так чтобы было максимально понятно даже для самого начинающего в Python. Хотя данный алгоритм шифрования больше не является на 100% надежным, однако он хорошо подойдет для тех кто стал на путь изучения более серьезных вещей, например того же RSA.
Ссылки и код:
Описание шифра Виженера на Википедии
Исходный код на Python
Однако ограничим цитирование Википедии только описанием самого алгоритма.
Метод является усовершенствованным шифром Цезаря, где буквы смещались на определенную позицию.
Шифр Виженера состоит из последовательности нескольких шифров Цезаря с различными значениями сдвига.
Допустим у нас есть некий алфавит, где каждой букве соответствуют цифры:

Тогда если буквы a-z соответствуют числам 0-25, то шифрование Виженера можно записать в виде формулы:

Расшифровка:
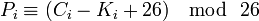
По сути нам больше ничего и не нужно кроме двух этих формул и мы можем приступить к реализации.
Тут хочу сказать, что я постарался реализовать алгоритм не проще и изящнее, а наиболее понятно и развернуто.
Собственно приступим-с.
Закодируем слова 'Hello world' с хитрым ключом 'key'.
Сначала необходимо создать словарь символов, которые будут участвовать в шифровании:
def form_dict():
d = {}
iter = 0
for i in range(0,127):
d[iter] = chr(i)
iter = iter +1
return d
Дальше необходимо сопоставить буквы в нашем слове с буквами в словаре и присвоить им соответствующие числовые индексы
def encode_val(word):
list_code = []
lent = len(word)
d = form_dict()
for w in range(lent):
for value in d:
if word[w] == d[value]:
list_code.append(value)
return list_code
И так мы закодировали наше слово и ключ и получили 2 списка индексов:
Value= [72, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
Key = [107, 101, 121]
Дальше мы сопоставляем индексы ключа с индексами нашего слова функцией full_encode():
def comparator(value, key):
len_key = len(key)
dic = {}
iter = 0
full = 0
for i in value:
dic[full] = [i,key[iter]]
full = full + 1
iter = iter +1
if (iter >= len_key):
iter = 0
return dic
def full_encode(value, key):
dic = comparator(value, key)
print 'Compare full encode', dic
lis = []
d = form_dict()
for v in dic:
go = (dic[v][0]+dic[v][1]) % len(d)
lis.append(go)
return lis
def decode_val(list_in):
list_code = []
lent = len(list_in)
d = form_dict()
for i in range(lent):
for value in d:
if list_in[i] == value:
list_code.append(d[value])
return list_code
Получаем наш индексы шифра и переводим их в строку функцией decode_val():
{0: [72, 107], 1: [101, 101], 2: [108, 121], 3: [108, 107], 4: [111, 101], 5: [32, 121], 6: [119, 107], 7: [111, 101], 8: [114, 121], 9: [108, 107], 10: [100, 101]}
Индексы: [52, 75, 102, 88, 85, 26, 99, 85, 108, 88, 74]
Получаем закодированное суперсекретное послание: 4KfXUcUlXJ
Раскодировать же все это можно с помощью функции full_decode(), первым аргументом которой есть список числовых индексов шифра, а вторым — список индексов ключа:
def full_decode(value, key):
dic = comparator(value, key)
print 'Deshifre=', dic
d = form_dict()
lis =[]
for v in dic:
go = (dic[v][0]-dic[v][1]+len(d)) % len(d)
lis.append(go)
return lis
Все так же получаем индексы шифра и переводим их в строку уже знакомой функцией decode_val():
[72, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
И вуаля! Наше зашифрованное слово: Hello world
Ну и главный вызов
if __name__ == "__main__":
word = 'Hello world'
key = 'key'
print 'Слово: '+ word
print 'Ключ: '+ key
key_encoded = encode_val(key)
value_encoded = encode_val(word)
print 'Value= ',value_encoded
print 'Key= ', key_encoded
shifre = full_encode(value_encoded, key_encoded)
print 'Шифр=', ''.join(decode_val(shifre))
decoded = full_decode(shifre, key_encoded)
print 'Decode list=', decoded
decode_word_list = decode_val(decoded)
print 'Word=',''.join(decode_word_list)
В статье постарался все описать так чтобы было максимально понятно даже для самого начинающего в Python. Хотя данный алгоритм шифрования больше не является на 100% надежным, однако он хорошо подойдет для тех кто стал на путь изучения более серьезных вещей, например того же RSA.
Ссылки и код:
Описание шифра Виженера на Википедии
Исходный код на Python
