Вот и мне посчастливилось познакомиться с git. Каюсь, пользуясь Subversion, я знал, как в IDEA или TortoiseSVN сделать то, что мне надо, но даже не представлял, что происходит за сценой. В данном случае я решил подойти к git более ответственно и хорошенько изучить его перед использованием. Сейчас я знаю какие команды надо использовать для выполнения задуманного, но не знаю, как это сделать в IDEA или TortoiseSVN.
Но я решил пойти еще дальше и узнать, что происходит в самой директории .git. Там оказалось все настолько интересно и просто, что я решил поделиться этим с вами.
Вот так выглядит .git после команды git init.
Это не все, что вы можете увидеть, так как при дальнейшей работе появятся другие файлы и директории. Например, так выглядит .git на моем рабочем проекте.
Я не буду описывать назначение каждого файла, а остановлюсь на основных моментах.
Самыми важными элементами являются objects, refs, HEAD, index. Для того чтобы понять, что это и с чем их едят, мы создадим несколько файлов, каталог, и добавим их в наш репозиторий.
Первоначально каталог оbjects содержит пустые подкаталоги pack и info и никаких файлов.
Создадим в рабочей директории файл test.txt с содержимым «test file version 1».
Добавим этот файл в индекс.
Теперь посмотрим что изменилось у нас в репозитории.
В директорию objects добавился файл. Следует сказать, что все файлы в данной директории являются git объектами определенного типа.
Давайте посмотрим содержимое и тип данного объекта с помощью команды cat-file.
Данный объект имеет тип blob. Это и есть начальное представление данных в Git — один файл на единицу хранения с именем, которое вычисляется как SHA1 хеш содержимого и заголовка объекта. Первые два символа SHA определяют подкаталог файла, остальные 38 — имя. Данный объект просто хранит снимок содержимого файла test.txt.
Далее видим, что появился файл index. Это бинарный файл, содержащий список индексированных файлов и связанных с ними blob объектов.
То есть индекс содержит всю необходимую информацию для создания tree объекта при последующем коммите. Tree объект — это еще один тип объекта в git. Чуть позже мы с ним познакомимся.
А теперь добавим каталог new и файл new/new.txt
Давайте узнаем тип нового объекта и его содержимое.
И заглянем снова в index.
А теперь все это закоммитим.
Теперь наш репозиторий содержит 5 объектов.
Добавилось еще три файла. Посмотрим что это за файлы.
Это другой тип объектов git — tree объект. Объект данного типа содержит одну или более записей, указывающей на другое дерево или на blob объект.
И наконец, последний тип объекта — объект-коммит.
Мы видим дерево верхнего уровня, о котором я уже упоминал ранее, имя автора и коммитера и сообщение коммита.
Сделаем новое изменение(в test.txt изменим текст на «test file version 2»)и закоммитим. Кроме ссылки на дерево появилась еще ссылка на предшествующий коммит.
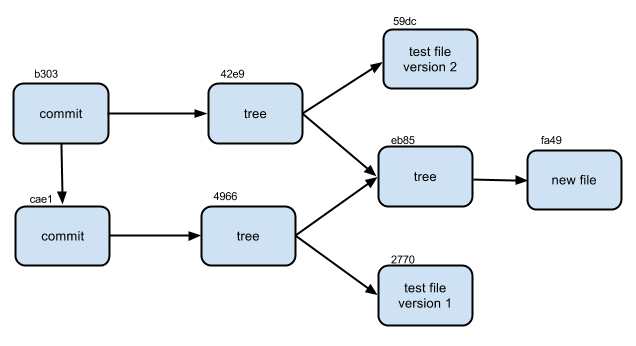
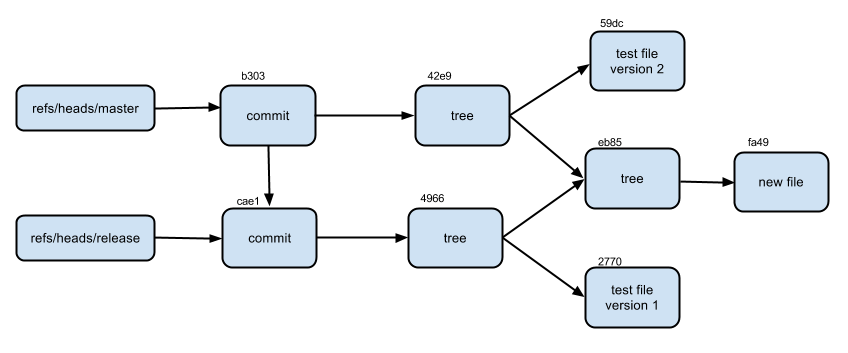
Чтобы все стало на свои места, нарисуем граф объектов
В git ссылка — это файл-указатель с простым именем, который содержит значение хеша SHA-1. Данные файлы размещаются в каталоге .git/refs/
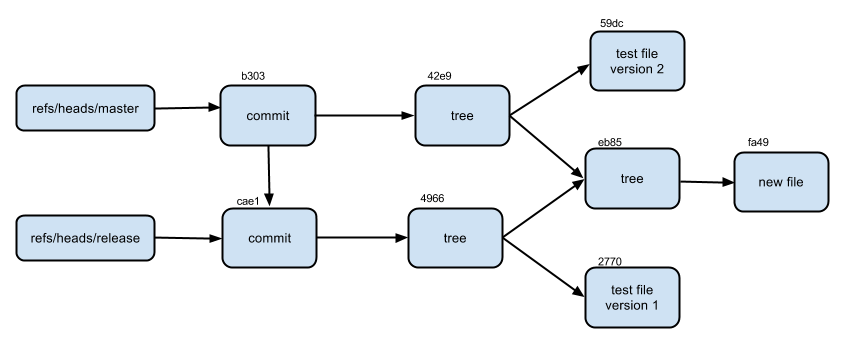
Так как у нас только одна ветка master, то и ссылка тоже только одна, которая указывает на последний коммит.
Давайте сделаем бранч release, указывающий на первый коммит.
Вот по сути что такое ветка в git — простой указатель на определенный коммит.
Посмотрим более наглядно
Данный файл содержит ссылку не на хеш, а на текущую ветку.
Если перейти на другую ветку, то и содержание данного файла изменится.
А есть еще метки, удаленные ссылки, директория info и много много вкусного.
Но я решил пойти еще дальше и узнать, что происходит в самой директории .git. Там оказалось все настолько интересно и просто, что я решил поделиться этим с вами.
Вот так выглядит .git после команды git init.
Это не все, что вы можете увидеть, так как при дальнейшей работе появятся другие файлы и директории. Например, так выглядит .git на моем рабочем проекте.
Я не буду описывать назначение каждого файла, а остановлюсь на основных моментах.
Самыми важными элементами являются objects, refs, HEAD, index. Для того чтобы понять, что это и с чем их едят, мы создадим несколько файлов, каталог, и добавим их в наш репозиторий.
Объекты
Первоначально каталог оbjects содержит пустые подкаталоги pack и info и никаких файлов.
Создадим в рабочей директории файл test.txt с содержимым «test file version 1».
$ echo ‘test file version 1’ > test.txt
Добавим этот файл в индекс.
$ git add test.txt
Теперь посмотрим что изменилось у нас в репозитории.
$ find .git/objects
.git/objects/27/703ec79a98c1d097d5b1cd320befffa376e826
В директорию objects добавился файл. Следует сказать, что все файлы в данной директории являются git объектами определенного типа.
Давайте посмотрим содержимое и тип данного объекта с помощью команды cat-file.
$ git cat-file -p 2770
test file version 1
$ git cat-file -t 2770
blob
Данный объект имеет тип blob. Это и есть начальное представление данных в Git — один файл на единицу хранения с именем, которое вычисляется как SHA1 хеш содержимого и заголовка объекта. Первые два символа SHA определяют подкаталог файла, остальные 38 — имя. Данный объект просто хранит снимок содержимого файла test.txt.
Далее видим, что появился файл index. Это бинарный файл, содержащий список индексированных файлов и связанных с ними blob объектов.
$ git ls-files --stage
100644 27703ec79a98c1d097d5b1cd320befffa376e826 0 test.txt
То есть индекс содержит всю необходимую информацию для создания tree объекта при последующем коммите. Tree объект — это еще один тип объекта в git. Чуть позже мы с ним познакомимся.
А теперь добавим каталог new и файл new/new.txt
$ mkdir new
$ echo "new file" > new/new.txt
$ git add .
$ find .git/objects -type f
.git/objects/27/703ec79a98c1d097d5b1cd320befffa376e826
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92
Давайте узнаем тип нового объекта и его содержимое.
$ git cat-file -p fa49
new file
$ git cat-file -t fa49
blob
И заглянем снова в index.
$ git ls-files --stage
100644 fa49b077972391ad58037050f2a75f74e3671e92 0 new/new.txt
100644 27703ec79a98c1d097d5b1cd320befffa376e826 0 test.txt
А теперь все это закоммитим.
$ git commit -m "first commit"
[master (root-commit) cae1990] first commit
2 files changed, 2 insertions(+), 0 deletions(-)
create mode 100644 new/new.txt
create mode 100644 test.txt
Теперь наш репозиторий содержит 5 объектов.
$ find .git/objects -type f
.git/objects/27/703ec79a98c1d097d5b1cd320befffa376e826
.git/objects/49/66bf4e5c88c5f9d149b45bb2f3099644701d93
.git/objects/ca/e19909974ee9e64f5787fe4ee89b9b8fe94ccf
.git/objects/eb/85079ce7fd354ffc630f4a8e2991196cb3807f
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92
Добавилось еще три файла. Посмотрим что это за файлы.
$ git cat-file -t 4966
tree
$ git cat-file -p 4966
040000 tree eb85079ce7fd354ffc630f4a8e2991196cb3807f new
100644 blob 27703ec79a98c1d097d5b1cd320befffa376e826 test.txt
$ git cat-file -t eb85
tree
$ git cat-file -p eb85
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
Это другой тип объектов git — tree объект. Объект данного типа содержит одну или более записей, указывающей на другое дерево или на blob объект.
И наконец, последний тип объекта — объект-коммит.
$ git cat-file -p cae1
tree 4966bf4e5c88c5f9d149b45bb2f3099644701d93
author Ivan Ivanov <i_ivanov@adam.net> 1335783964 +0300
committer Ivan Ivanov <i_ivanov@adam.net> 1335783964 +0300
first commit
Мы видим дерево верхнего уровня, о котором я уже упоминал ранее, имя автора и коммитера и сообщение коммита.
Сделаем новое изменение(в test.txt изменим текст на «test file version 2»)и закоммитим. Кроме ссылки на дерево появилась еще ссылка на предшествующий коммит.
$ git cat-file -p b303
tree 42e998096f18d4249dc00ec89eaaadc44a8bf3cb
parent cae19909974ee9e64f5787fe4ee89b9b8fe94ccf
author Ivan Ivanov <i_ivanov@adam.net> 1335786789 +0300
committer Ivan Ivanov <i_ivanov@adam.net> 1335786789 +0300
second commit
Чтобы все стало на свои места, нарисуем граф объектов

Ссылки
В git ссылка — это файл-указатель с простым именем, который содержит значение хеша SHA-1. Данные файлы размещаются в каталоге .git/refs/
$ find .git/refs
.git/refs
.git/refs/heads
.git/refs/heads/master
.git/refs/tags
Так как у нас только одна ветка master, то и ссылка тоже только одна, которая указывает на последний коммит.
Давайте сделаем бранч release, указывающий на первый коммит.
$ git branch release cae1990
$ find .git/refs
.git/refs
.git/refs/heads
.git/refs/heads/master
.git/refs/heads/release
.git/refs/tags
$ cat .git/refs/heads/release
cae19909974ee9e64f5787fe4ee89b9b8fe94ccfa
Вот по сути что такое ветка в git — простой указатель на определенный коммит.
Посмотрим более наглядно
HEAD
Данный файл содержит ссылку не на хеш, а на текущую ветку.
$ cat .git/HEAD
ref: refs/heads/master
Если перейти на другую ветку, то и содержание данного файла изменится.
$ git co release
Switched to branch 'release'
$ cat .git/HEAD
ref: refs/heads/release
Вместо итога
А есть еще метки, удаленные ссылки, директория info и много много вкусного.
