Сегодня существуют разные мнения по поводу успешности объектной технологии. С одной стороны, большинство современных mainstream языков программирования являются объектно-ориентированными, с другой стороны, нередко можно услышать критику ООП, дескать, объектно-ориентированное программирование «провалилось» и не оправдало тех надежд, которые были возложены на нее индустрией разработки ПО. Все, мол, ожидали наступления вселенского счастья в виде увеличения повторного использования, упрощения сопровождения, да и вообще, обещали, что думать придется кому-то другому, а я за это буду деньги получать.
Причин у подобных разочарований тоже несколько. Во-первых, такое отношение к ООП может быть следствием завышенных ожиданий, а ведь Фред Брукс еще двадцать лет назад писал о том, что не стоит ждать «серебряных пуль», способных на порядок увеличить продуктивность труда программиста. Во-вторых, никто из серьезных сторонников ООП (типа Гради Буча или Бертрана Мейера) не обещали, что все будет просто. ООП – это не волшебная палочка, которая сделает из любого УГ конфетку, даже обертку которой можно будет использовать повторно.
Так вот вопрос: как же можно достичь той заветной мечты, когда системы можно будет строить из готовых компонентов, не написав при этом ни строчки кода? Я не уверен, что в таком виде эта мечта вообще осуществима из-за неотъемлемой сложности ПО, а также потому, что часто само решение влияет на решаемую задачу. Тем не менее, если направить энергию, затрачиваемую на повторное использование в правильное русло, то с разумным количеством трудозатрат можно поднять «реюз» кода на достойный уровень.
Как мне кажется, причин у столь плачевного состояния дел с повторным использованием две: (1) разработчики уделяют повторному использованию слишком мало внимания и (2) разработчики уделяют повторному использованию слишком много внимания. Да, это звучит, по меньшей мере, глупо, но давайте я немного перефразирую: проблема с повторным использованием в том, что усилия прикладываются не вовремя и не всегда туда, куда нужно.
Для начала, давайте рассмотрим типичный жизненный цикл одной итерации разработки ПО:
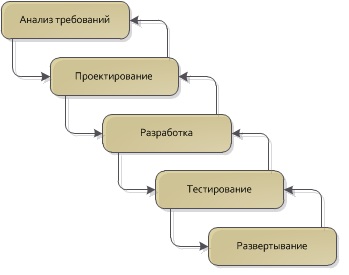
Классический жизненный цикл разработки ПО является итеративным, при этом каждая итерация состоит из (более или менее) одних и тех же этапов. В некоторых случаях этапы проектирования и реализации могут объединяться в один, а перед фазой анализа иногда может быть анализ осуществимости, но суть от этого не меняется. Теперь давайте попробуем ответить на вопрос: на каком из этих этапов принимается решение о том, что определенные классы (или модули целиком) достойны повторного использования? Обычно это решение принимается на лету где-то между анализом и проектирование, иногда оно принимается на этапе проектирования, иногда – во время реализации.
В целом, ничего плохого в этом нет, пока процесс обобщения не начинает влиять на дизайн системы, затягивать сроки и приводить к увеличению сложности, вместо того, чтобы с ней бороться.
Каждый уважающий себя разработчик знает цитату Кнута о злобной преждевременной оптимизации, которая может привести к невероятно быстрому коду (правда, обычно не в тех местах, что нужно), прочитать и понять который со временем не сможет и сам автор. Но поскольку сейчас наиболее затратной частью многих систем является не производительность, а эффективность разработки, то вместо преждевременной оптимизации все чаще можно столкнуться с проблемой «преждевременного обобщения» (premature generalization).
По сути, преждевременное обобщение сводится к созданию более сложного решения в надежде на повторное использование или на «гибкость», которая позволит справиться с будущими изменениями. Но, как это обычно бывает, «гибкость» оказывается не такой и гибкой, требования начинают меняться не в ту сторону, в результате трудозатраты не оправдываются и команда получает более сложное решение, хотя могла бы обойтись и более простым. Иногда бывают и более паталогические случаи: например, с самого начала за дело может взяться «архитектор» с непреклонным желанием построить свой «фреймворк» с блэкджеком и девицами когда еще нет четкого видения того, что нужно команде, проекту и заказчику. В результате, каждый проект обрастает кривыми библиотеками и фреймворками, использовать которые неудобно, а сопровождать – дорого.
Проблема в том, что затраты на дизайн, реализацию и сопровождения публично доступного кода на несколько порядков выше стоимости сопровождения простого кастомного решения. Начинается все с того, что реюзабельный код требует более полной и подробной документации, лучшего качества и покрытия тестами, примеров использования и пользовательской документации. Даже если код предназначен для повторного использования внутри команды, то его качество и простота использования должны быть такими, чтобы программисту было экономически выгодно разобраться в вашем решении, а не городить свой собственный любимый огород. И я уже не говорю о необходимости культуры повторного использования, без которой вся идея «реюза» накроется медным тазом благодаря всеми любимому симптому NIH (Not Invented Here).
Когда же речь заходит не о библиотеках, а о «гибкости» конкретных решений, то мы сталкиваемся с похожей проблемой. Многие считают, что «обобщенное» решение (с кучей возможностей для расширения) является лучшим способом справиться с будущими изменениями. Возможно это и так, но практика показывает, что с этого пути очень легко скатиться к громоздкому коду, который сложно понять (ведь он может все) и сопровождать. Если вы считаете, что некоторый аспект поведения может измениться, то достаточно спрятать его за абстрактным интерфейсом и сделать этот аспект деталью реализации. Как и в случае с производительностью, программисты (и архитекторы) плохо угадывают, что именно будет изменяться в будущем и какие новые потребности появятся. А раз так, то нет ничего лучше простого решения, которое можно легко адаптировать под изменяющиеся требования путем его модификации.
Все эти сложности не говорят о том, что заниматься повторным использованием глупо. Нет. Аналогично тому, как оптимизация производительности должна осуществляться после профилирования, так и обобщение должно осуществляться вОвремя: не во время разработки самой «фичи», а на более поздних этапах, когда команда понимает, куда будут направлены возможные изменения и, что нужно обобщать, а что – нет.
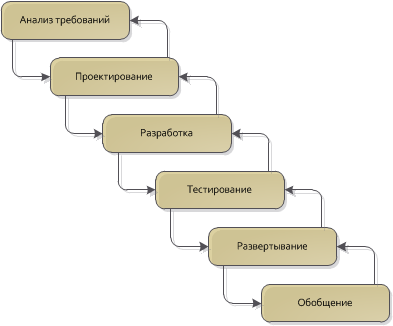
Здесь нужно понять очень важный момент: шаг обобщения не является сам по себе достаточным условием для создания реюзабельного кода, точно также как процесс профилирования не гарантирует того, что вы сможете повысить производительность найденного bottle neck-а. Это лишь этап, во время которого простое и адекватное решение, полученное на этапе проектирования и реализации «причесывается» дополнительно для доведения его до уровня повторного использования: убираются лишние зависимости, улучшается документация, добавляются дополнительные юнит-тесты. Если во время реализации все скомкать в одну кучу и сделать из системы такой клубок, что без бутыля не разобраться, то не о каком будущем «реюзе» речи быть не может. Но если начать с простой и понятной архитектуры, которая хорошо решает поставленную задачу, то объединить несколько однотипных решений в одно будет значительно легче, когда будет уже точно понятно, что у них общего.
ПРИМЕЧАНИЕ
В данном случае я не рассматриваю разработку библиотек, как отдельного продукта. Библиотека изначально заточена на повторное использование и там многое делается по-другому; достаточно полистать Framework Design Guidelines, чтобы понять – при разработке библиотеки на первый план выходит ее качество, удобство использования, отсутствие ломающих изменений, интуитивная понятность, «иерархичность» и много другое. Здесь же речь идет не о библиотеках для широкой общественности, а о проблемах с «реюзом» в типичных enterprise приложениях.
Этап обобщения не обязательно должен быть формальным или проходить на каждой итерации разработки, но рано или поздно команде понадобится приложить дополнительные усилия для доведения кода (и дизайна) до ума, а значит, о нем должны знать руководители проекта.
К сожалению, даже этап обобщения не является залогом повышения «реюза» кода. Первая проблема связана с выбиванием у руководства дополнительного времени на непонятное обобщение, вместо того, чтобы клепать новую функциональность следующей итерации. Да, все твердят о важности повторного использования, но когда заходит речь о дополнительных расходах, то близорукость руководителей проекта может сыграть свою роль и в обобщении будет отказано. В этом есть и доля истины; вторая проблема связана с тем, что наличие качественного кода, доступного для повторного использования, не гарантирует его использования. Для нормального «реюза» нужна еще и культура, а всеми любимый NIH и жажда велосипедостроения могут быть настолько сильными, что любые попытки повторного использования ни к чему не приведут.
Но, в любом случае, мой совет сводится к тому, чтобы при выборе простота vs «гибкость» к будущим изменениям, вы останавливались именно на простоте. Ведь если решение простое, то его несложно модифицировать под будущие потребности, или обобщить для повторного использования. Ну а если ничего такого не понадобится, то вы просто сэкономите силы и время, и будете жить с этим простым решением долгие годы.
ПРИМЕЧАНИЕ
Идею с этапом обобщения предложил Бертран Мейер в свое книге «Объектно-ориентированное конструирование программных систем», так что немного подробностей можно найти в разделе «28.5 Обобщение» (кстати, это и правда отличная книга, в которой можно найти много интересных идей об ООП и разработке ПО).
Причин у подобных разочарований тоже несколько. Во-первых, такое отношение к ООП может быть следствием завышенных ожиданий, а ведь Фред Брукс еще двадцать лет назад писал о том, что не стоит ждать «серебряных пуль», способных на порядок увеличить продуктивность труда программиста. Во-вторых, никто из серьезных сторонников ООП (типа Гради Буча или Бертрана Мейера) не обещали, что все будет просто. ООП – это не волшебная палочка, которая сделает из любого УГ конфетку, даже обертку которой можно будет использовать повторно.
Так вот вопрос: как же можно достичь той заветной мечты, когда системы можно будет строить из готовых компонентов, не написав при этом ни строчки кода? Я не уверен, что в таком виде эта мечта вообще осуществима из-за неотъемлемой сложности ПО, а также потому, что часто само решение влияет на решаемую задачу. Тем не менее, если направить энергию, затрачиваемую на повторное использование в правильное русло, то с разумным количеством трудозатрат можно поднять «реюз» кода на достойный уровень.
Как мне кажется, причин у столь плачевного состояния дел с повторным использованием две: (1) разработчики уделяют повторному использованию слишком мало внимания и (2) разработчики уделяют повторному использованию слишком много внимания. Да, это звучит, по меньшей мере, глупо, но давайте я немного перефразирую: проблема с повторным использованием в том, что усилия прикладываются не вовремя и не всегда туда, куда нужно.
Стандартный жизненный цикл ПО
Для начала, давайте рассмотрим типичный жизненный цикл одной итерации разработки ПО:
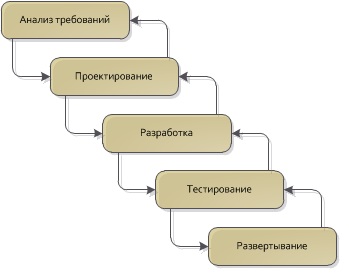
Классический жизненный цикл разработки ПО является итеративным, при этом каждая итерация состоит из (более или менее) одних и тех же этапов. В некоторых случаях этапы проектирования и реализации могут объединяться в один, а перед фазой анализа иногда может быть анализ осуществимости, но суть от этого не меняется. Теперь давайте попробуем ответить на вопрос: на каком из этих этапов принимается решение о том, что определенные классы (или модули целиком) достойны повторного использования? Обычно это решение принимается на лету где-то между анализом и проектирование, иногда оно принимается на этапе проектирования, иногда – во время реализации.
В целом, ничего плохого в этом нет, пока процесс обобщения не начинает влиять на дизайн системы, затягивать сроки и приводить к увеличению сложности, вместо того, чтобы с ней бороться.
Преждевременное обобщение
Каждый уважающий себя разработчик знает цитату Кнута о злобной преждевременной оптимизации, которая может привести к невероятно быстрому коду (правда, обычно не в тех местах, что нужно), прочитать и понять который со временем не сможет и сам автор. Но поскольку сейчас наиболее затратной частью многих систем является не производительность, а эффективность разработки, то вместо преждевременной оптимизации все чаще можно столкнуться с проблемой «преждевременного обобщения» (premature generalization).
По сути, преждевременное обобщение сводится к созданию более сложного решения в надежде на повторное использование или на «гибкость», которая позволит справиться с будущими изменениями. Но, как это обычно бывает, «гибкость» оказывается не такой и гибкой, требования начинают меняться не в ту сторону, в результате трудозатраты не оправдываются и команда получает более сложное решение, хотя могла бы обойтись и более простым. Иногда бывают и более паталогические случаи: например, с самого начала за дело может взяться «архитектор» с непреклонным желанием построить свой «фреймворк» с блэкджеком и девицами когда еще нет четкого видения того, что нужно команде, проекту и заказчику. В результате, каждый проект обрастает кривыми библиотеками и фреймворками, использовать которые неудобно, а сопровождать – дорого.
Проблема в том, что затраты на дизайн, реализацию и сопровождения публично доступного кода на несколько порядков выше стоимости сопровождения простого кастомного решения. Начинается все с того, что реюзабельный код требует более полной и подробной документации, лучшего качества и покрытия тестами, примеров использования и пользовательской документации. Даже если код предназначен для повторного использования внутри команды, то его качество и простота использования должны быть такими, чтобы программисту было экономически выгодно разобраться в вашем решении, а не городить свой собственный любимый огород. И я уже не говорю о необходимости культуры повторного использования, без которой вся идея «реюза» накроется медным тазом благодаря всеми любимому симптому NIH (Not Invented Here).
Когда же речь заходит не о библиотеках, а о «гибкости» конкретных решений, то мы сталкиваемся с похожей проблемой. Многие считают, что «обобщенное» решение (с кучей возможностей для расширения) является лучшим способом справиться с будущими изменениями. Возможно это и так, но практика показывает, что с этого пути очень легко скатиться к громоздкому коду, который сложно понять (ведь он может все) и сопровождать. Если вы считаете, что некоторый аспект поведения может измениться, то достаточно спрятать его за абстрактным интерфейсом и сделать этот аспект деталью реализации. Как и в случае с производительностью, программисты (и архитекторы) плохо угадывают, что именно будет изменяться в будущем и какие новые потребности появятся. А раз так, то нет ничего лучше простого решения, которое можно легко адаптировать под изменяющиеся требования путем его модификации.
Все эти сложности не говорят о том, что заниматься повторным использованием глупо. Нет. Аналогично тому, как оптимизация производительности должна осуществляться после профилирования, так и обобщение должно осуществляться вОвремя: не во время разработки самой «фичи», а на более поздних этапах, когда команда понимает, куда будут направлены возможные изменения и, что нужно обобщать, а что – нет.
Модифицированный жизненный цикл итерации
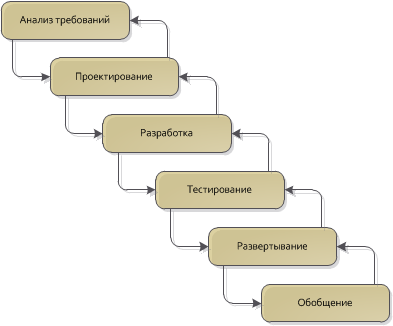
Здесь нужно понять очень важный момент: шаг обобщения не является сам по себе достаточным условием для создания реюзабельного кода, точно также как процесс профилирования не гарантирует того, что вы сможете повысить производительность найденного bottle neck-а. Это лишь этап, во время которого простое и адекватное решение, полученное на этапе проектирования и реализации «причесывается» дополнительно для доведения его до уровня повторного использования: убираются лишние зависимости, улучшается документация, добавляются дополнительные юнит-тесты. Если во время реализации все скомкать в одну кучу и сделать из системы такой клубок, что без бутыля не разобраться, то не о каком будущем «реюзе» речи быть не может. Но если начать с простой и понятной архитектуры, которая хорошо решает поставленную задачу, то объединить несколько однотипных решений в одно будет значительно легче, когда будет уже точно понятно, что у них общего.
ПРИМЕЧАНИЕ
В данном случае я не рассматриваю разработку библиотек, как отдельного продукта. Библиотека изначально заточена на повторное использование и там многое делается по-другому; достаточно полистать Framework Design Guidelines, чтобы понять – при разработке библиотеки на первый план выходит ее качество, удобство использования, отсутствие ломающих изменений, интуитивная понятность, «иерархичность» и много другое. Здесь же речь идет не о библиотеках для широкой общественности, а о проблемах с «реюзом» в типичных enterprise приложениях.
Этап обобщения не обязательно должен быть формальным или проходить на каждой итерации разработки, но рано или поздно команде понадобится приложить дополнительные усилия для доведения кода (и дизайна) до ума, а значит, о нем должны знать руководители проекта.
Заключение
К сожалению, даже этап обобщения не является залогом повышения «реюза» кода. Первая проблема связана с выбиванием у руководства дополнительного времени на непонятное обобщение, вместо того, чтобы клепать новую функциональность следующей итерации. Да, все твердят о важности повторного использования, но когда заходит речь о дополнительных расходах, то близорукость руководителей проекта может сыграть свою роль и в обобщении будет отказано. В этом есть и доля истины; вторая проблема связана с тем, что наличие качественного кода, доступного для повторного использования, не гарантирует его использования. Для нормального «реюза» нужна еще и культура, а всеми любимый NIH и жажда велосипедостроения могут быть настолько сильными, что любые попытки повторного использования ни к чему не приведут.
Но, в любом случае, мой совет сводится к тому, чтобы при выборе простота vs «гибкость» к будущим изменениям, вы останавливались именно на простоте. Ведь если решение простое, то его несложно модифицировать под будущие потребности, или обобщить для повторного использования. Ну а если ничего такого не понадобится, то вы просто сэкономите силы и время, и будете жить с этим простым решением долгие годы.
ПРИМЕЧАНИЕ
Идею с этапом обобщения предложил Бертран Мейер в свое книге «Объектно-ориентированное конструирование программных систем», так что немного подробностей можно найти в разделе «28.5 Обобщение» (кстати, это и правда отличная книга, в которой можно найти много интересных идей об ООП и разработке ПО).
