В 2007-м Стив Джобс представил iPhone, который произвел революцию в высокотехнологичной индустрии и изменил наш подход к работе и ведению бизнеса. Сейчас 2012-й и все больше и больше сайтов предлагают нативные iOS и Android клиенты для своих сервисов. Между тем не все стартапы обладают финансами для разработки приложений в дополнение к основному продукту. Для увеличения популярности своего продукта эти компании предлагают открытые API, которыми могут воспользоваться сторонние разработчики. Пожалуй Twitter был первым в этой сфере и теперь число компаний, последовавших этой стратегии, растет стремительно. Это действительно отличный способ создать привлекательную экосистему вокруг своего продукта.
Жизнь стартапа полна перемен, поворотных моментов, в которых от принятых решений зависит дальнейшая судьба проекта. Если ваша кодовая база не сможет обеспечить воплощение самых разных ваших решений – вы проиграли. Серверный код, который достаточно гибок для того, чтобы в короткие сроки подстроиться под нужды бизнеса, решает быть проекту или нет. Успешные стартапы не те, которые просто предложили отличную идею, но те, которые смогли ее качественно воплотить. Успех стартапа зависит от успешности его продукта, будь то приложение под iOS, сервис или API. Последние три года я работал над разными приложениями под iOS (в основном для стартапов) использовавшими web сервисы и в этом блоге я попытался собрать накопленные знания воедино и показать вам лучшие методики, которым вам нужно следовать при разработке RESTful API. Хороший RESTful API тот, который можно менять легко и просто.
Этот пост предназначен для тех, кто обладает знаниями в разработке RESTful API уровня от средних до продвинутых. А также некоторыми базовыми знаниями объектно-ориентированного (или функционального) программирования на таких серверных языках как Java/Ruby/Scala. (Я намеренно проигнорировал PHP или Programmable Hyperlinked Pasta).
Прим. Пер. Тут автор привел ссылку на полушутливую статью о истории языков программирования где PHP был расшифрован как Programmable Hyperlinked Pasta (Программируемая Гиперссылочная Лапша). Что как бы характеризует отношение автора к PHP.
Статья довольно подробна и состоит из двух частей. Первая описывает основы REST тогда как вторая описывает документирование и поддержку разных версий вашего API. Первая часть для новичков, вторая для профи. Я не сомневаюсь, что вы профи, а потому вот вам ссылка чтобы перескочить сразу к главе «Документирование API». Возможно, вам стоит начать оттуда, если вам кажется, что этот пост из разряда «Многа букаф, ниасилил…».
Сервер может считаться RESTful если он соответствует принципам REST. Когда вы разрабатываете API, который будет в основном использоваться мобильными устройствами, понимание и следование трем наиважнейшим принципам может быть весьма полезным. Причем не только при разработке API, но и при его поддержке и развитии в дальнейшем. Итак, приступим.
Первый принцип – независимость от состояния. Проще говоря, RESTful сервер не должен отслеживать, хранить и тем более использовать в работе текущую контекстную информацию о клиенте. С другой стороны клиент должен взять эту задачу на себя. Другими словами не заставляйте сервер помнить состояние мобильного устройства, использующего API.
Давайте представим, что у вас есть стартап под названием «Новый Фейсбук». Хороший пример, где разработчик мог совершить ошибку это предоставление вызова API, который позволяет мобильному устройству установить последний прочитанный элемент в потоке (назовем его лентой Фейсбука). Вызов API, обычно возвращающий ленту (назовем его /feed), теперь будет возвращать элементы, которые новее установленного. Звучит умно, не правда ли? Вы «оптимизировали» обмен данными между клиентом и сервером? А вот и нет.
Что может пойти не так в приведенном случае, так это то, что если ваш пользователь использует сервис с двух или трех устройств, то, в случае когда одно из них устанавливает последний прочитанный элемент, то остальные не смогут загрузить элементы ленты, прочитанные на других устройствах ранее.
Независимость от состояния означает, что данные, возвращаемые определенным вызовом API, не должны зависеть от вызовов, сделанных ранее.
Правильный способ оптимизации данного вызова – передача времени создания последней прочитанной записи ленты в качестве параметра вызова API, возвращающего ленту (/feed?lastFeed=20120228). Есть и другой, более «правильный» метод – использование заголовка HTTP If-Modified-Since. Но мы пока не будем углубляться в эту сторону. Мы обсудим это во второй части.
Клиент же со своей стороны, может (должен) помнить параметры, сгенерированные на сервере при обращении к нему и использовать их для последующих вызовов API, если потребуется.
Второй принцип заключается в предоставлении клиенту информации о том, что ответ сервера может быть кэширован на определенный период времени и использоваться повторно без новых запросов к серверу. Этим клиентом может быть как само мобильное устройство, так и промежуточный прокси сервер. Я расскажу подробнее о кэшировании во второй части.
RESTful сервер должен прятать от клиента как можно больше деталей своей реализации. Клиенту не следует знать о том, какая СУБД используется на сервере или сколько серверов в данный момент обрабатывают запросы и прочие подобные вещи. Организация правильного разделения функций важна для масштабирования если ваш проект начнет быстро набирать популярность.
Это пожалуй три самых важных принципа, которым нужно следовать в ходе разработки RESTful сервера. Далее будут описаны три менее важных принципа, но все они имеют непосредственное отношение к тому, о чем мы тут говорим.
GET
POST
PUT
DELETE
Главное, что следует помнить — вызов, совершенный через GET не должен менять состояние сервера. Это в свою очередь значит, что ваши запросы могут кэшироваться любым промежуточным прокси (снижение нагрузки). Таким образом Вы, как разработчик сервера, не должны публиковать GET методы, которые меняют данные в вашей базе данных. Это нарушает философию RESTful, особенно второй пункт, описанный выше. Ваши GET вызовы не должны даже оставлять записей в access.log или обновлять данные типа “Last logged in”. Если вы меняете данные в базе, это обязательно должны быть методы POST/PUT.
Спецификация HTTP 1.1 гласит, что PUT идемпотентен. Это значит, что клиент может выполнить множество PUT запросов по одному URI и это не приведет к созданию записей дубликатов. Операции присвоения — хороший пример идемпотентной операции
Даже если эту операцию выполнить дважды или трижды, никакого вреда не будет (кроме лишних тактов процессора). POST же с другой стороны не идемпотентен. Это что-то вроде инкремента. Вам следует использовать POST или PUT с учетом того является ли выполняемое действие идемпотентным или нет. Говоря языком программистов, если клиент знает URL объекта, который нужно создать, используйте PUT. Если клиент знает URL метода/класса создающего нужный объект, используйте POST.
Используйте PUT если клиент знает URI, который сам бы мог быть результатом запроса. Даже если клиент вызовет это PUT метод много раз, какого либо вреда или дублирующих записей создано не будет.
Используйте POST если сервер сам создает уникальный идентификатор и возвращает его клиенту. Дублирующие записи будут создаваться если этот запрос будет повторяться позже с такими же параметрами.
Более подробная информация в данном обсуждении.
DELETE абсолютно однозначен. Он идемпотентен как и PUT, и должен использоваться для удаления записи если таковая существует.
Ответы от Вашего RESTful сервера могут использовать в качестве формата XML или JSON. Лично я предпочитаю JSON, поскольку он более лаконичен и по сети передается меньший объем данных нежели при передаче такого же ответа в формате XML. Разница может быть порядка нескольки сотен килобайт, но, с учетом скоростей 3G и нестабильности обмена с мобильными устройствами, эти несколько сотен килобайт могут иметь значение.
Аутентификация должна производиться через https и клиент должен посылать пароль в зашифрованном виде. Процесс получения sha1 хэша NSString в Objective-C достаточно понятен и прост и приведенный код наглядно это показывает.
Сервер должен сравнить полученный хэш пароля с сохраненным в его базе хэшем. В любом случае не следует ни при каких условиях передавать пароли с клиента на сервер в открытом виде. Из этого правила не существует исключений! День, когда Ваши пользователи узнают, что вы храните их пароли в открытом виде, может стать последним днем вашего стартапа. Доверие, потерянное однажды, вернуть невозможно.
RFC 2617 описывает два способа аутентификации на HTTP сервере. Первый — это Basic Access, второй Digest. Для мобильных клиентов подходит любой из этих двух методов и большинство серверных (и клиентских тоже) языков обладают встроенными механизмами для реализации таких схем аутентификации.
Если вы планируете сделать свой API публичным, вам следует также посмотреть в сторону oAuth или лучше oAuth 2.0. oAuth позволит Вашим пользователям публиковать контент, созданный в Вашем приложении, на других ресурсах без обмена ключами (логинами/паролями). oAuth также позволяет пользователям контролировать что именно находится в доступе и какие разрешения даны сторонним ресурсам.
Facebook Graph API это наиболее развитая и распространенная реализация oAuth на данный момент. Используя oAuth, пользователи Facebook могут давать доступ к своим фотографиям сторонним приложениям без публикации другой приватной и идентификационной информации (логин/пароль). Пользователь также может ограничить доступ нежелательным приложениям без необходимости менять свой пароль.
До сего момента я говорил об основах REST. Теперь переходим к сути статьи. В последующих главах я буду говорить о практических приемах, которые следует использовать при документировании, создании новых и завершении поддержки старых версий своего API…
Худшая документация, которую может написать разработчик сервера — это длинный, однообразный список вызовов API с описанием параметров и возвращаемых данных. Главная проблема такого подхода заключается в том, что внесение изменений в сервер и формат возвращаемых данных по мере развития проекта становится кошмаром. Я внесу кое какие предложения на этот счет, чтобы разработчик клиентского ПО понимал Вас лучше. Со временем это также поможет Вам в развитии в качестве разработчика серверного ПО.
Первым шагом я бы порекомендовал подумать об основных, высокоуровневых структурах данных (моделях), которыми оперирует ваше приложение. Затем подумайте над действиями, которые можно произвести над этими компонентами. Документация по foursquare API хороший пример, который стоит изучить перед тем как начать писать свою. У них есть набор высокоуровневых объектов, таких как места, пользователи и тому подобное. Также у них есть набор действий, которые можно произвести над этими объектами. Поскольку вы знаете высокоуровневые объекты и действия над ними в вашем продукте, создание структуры вызовов API становится проще и понятней. Например, для добавления нового места логично будет вызвать метод наподобие /venues/add
Документируйте все высокоуровневые объекты. Затем документируйте запросы и ответы на них, используя эти высокоуровневые объекты вместо простых типов данных. Вместо того, чтобы писать “Этот вызов возвращает три строковых поля, первое содержит id, второе имя, а третье описание” пишите “Этот вызов возвращает структуру (модель), описывающую место”.
Давайте представим, что у Вас есть API, позволяющий пользователю входить, используя Facebok token. Вызовем этот метод как /login.
Где profileinfo высокоуровневый объект. Поскольку вы уже задокументировали внутреннюю структуру этого объекта то такого простого упоминания достаточно. Если Ваш сервер использует такие же Accept, Accept-Encoding и параметр Encoding type всегда вы можете задокументировать их отдельно, вместо повторения их во всех разделах.
Ответы на вызовы API должны также быть задокументированы, основываясь на высокоуровневой модели объектов. Цитируя тот же пример foursquare, вызов метода /venue/#venueid# вернет структуру данных (модель), описывающую место проведения мероприятия.
Обмен идеями, документирование или информирование других разработчиков о том, что вы вернете в ответ на запрос станет проще если Вы задокументируете ваш API используя структуру объектов (моделей). Наиболее важный итог этой главы — это необходимость воспринимать документацию как контракт, который заключаете Вы, как разработчик серверной части и разработчики клиентских приложений (iOS/Android/Windows Phone/Чтобытонибыло).
До появления мобильных приложений, в эпоху Web 2.0 создание разных версий API не было проблемой. И клиент (JavaScript/AJAX front-end) и сервер разворачивались одновременно. Потребители (ваши клиенты) всегда использовали самую последнюю версию клиентского ПО для доступа к системе. Поскольку вы — единственная компания, разрабатывающая как клиентскую так и серверную часть, вы полностью контролируете то как используется ваш API и изменения в нем всегда сразу же применялись в клиентской части. К сожалению это невозможно с клиентскими приложениями, написанными под разные платформы. Вы можете развернуть API версии 2, считая что все будет отлично, однако это приведет к неработоспособности приложений под iOS, использующих старую версию. Поскольку еще могут быть пользователи, использующие такие приложения несмотря на то, что вы выложили обновленную версию в App Store. Некоторые компании прибегают к использованию Push уведомлений для напоминаний о необходимости обновления. Единственное к чему это приведет — потеря такого клиента. Я видел множество айфонов, у которых было более 100 приложений, ожидающих обновления. Шансы, что ваше станет одним из них, весьма велики. Вам всегда надо быть готовым к разделению вашего API на версии и к прекращению поддержки некоторых из них как только это потребуется. Однако поддерживайте каждую версию своего API не менее трех месяцев.
Развертывание вашего серверного кода в разные папки и использование разных URL для вызовов не означает что вы удачно разделили ваш API на версии.
Так example.com/api/v1 будет использоваться версией 1.0 приложения, а ваша свежайшая и крутейшая версия 2.0 будет использовать example.com/api/v2
Когда вы делаете обновления, вы практически всегда вносите изменения во внутренние структуры данных и в модели. Это включает изменения в базе данных (добавление или удаление столбцов). Для лучшего понимания давайте представим, что ваш “новый Фейсбук” имеет вызов API, называемый /feed который возвращает объект “Лента”. На сегодня, в версии 1, ваш объект “Лента” включает URL аватарки пользователя (avatarURL), имя пользователя (personName), текст записи (feedEntryText) и время создания (timeStamp) записи. Позднее, в версии 2, вы представляете новую возможность, позволяющую рекламодателям размещать описания своих продуктов в ленте. Теперь объект “Лента” содержит, скажем так, новое поле “sourceName”, которое перекрывает собой имя пользователя при отображении ленты. Таким образом приложение должно отображать “sourceName” вместо “personName”. Поскольку приложению больше не нужно отображать “personName” если задана “sourceName”, вы решаете не отправлять “personName” если есть “sourceName”. Это все выглядит неплохо до тех пор, пока старая версия вашего приложения, версия 1 не обратится к обновленному серверу. Она будет отображать ваши рекламные записи из ленты без заголовка поскольку “personName” отсутствует. “Грамотный” способ решения такой проблемы — отправлять как “personName”, так и “sourceName”. Но, друзья, жизнь не всегда так проста. Как разработчик вы не сможете отслеживать все одиночные изменения которые когда либо были произведены с каждой моделью данных в вашем объекте. Это не очень эффективный способ внесения изменений поскольку через пол года вы практически забудете почему и как что-то было добавлено к вашему коду.
Возвращаясь к web 2.0, это не было проблемой вообще. JavaScript клиент немедленно модифицировался для поддержки изменений в API. Однако установленные iOS приложения от вас больше не зависят. Теперь их обновление — прерогатива пользователя.
У меня есть элегантное решение для хитрых ситуаций подобного толка.
Первое решение — это разделение с использованием URL.
api.example.com/v1/feeds будет использоваться версией 1 iOS приложения тогда как
api.example.com/v2/feeds будет использоваться версией 2.
Несмотря на то, что звучит это все неплохо, вы не сможете продолжать создание копий вашего серверного кода для каждого изменения в формате возвращаемых данных. Я рекомендую использование такого подхода только в случае глобальных изменений в API.
Выше я показал как документировать ваши структуры данных (модели). Рассматривайте эту документацию как контракт между разработчиками серверной и клиентской частей. Вам не следует вносить изменения в модели без изменения версии. Это значит, что в предыдущем случае должно быть две модели, Feed1 и Feed2.
В Feed2 есть поле sourceName и она возвращает sourceName вместо personName если sourceName установлен. Поведение Feed1 остается таким же, как это было оговорено в документации. Алгоритм работы контроллера будет примерно таким:
Вам следует переместить логику создания экземпляра класса в отдельный класс согласно паттерну Factory method. Соответствующий код контроллера должен выглядеть примерно так:
Где решение о версии используемого API будет принимать контроллер в соответствии с полем UserAgent текста запроса.
Дополнение:
Вместо использования номера версии из строки UserAgent, правильней будет использовать номер версии в заголовке Accept. Таким образом вместо отправки
следует отправлять
Таким образом у вас появляется возможность указывать версию API для каждого запроса к REST серверу. Спасибо читателям hacker news за этот совет.
Контроллер использует метод Feed factory для создания корректного объекта feed (лента) основываясь на информации из запроса клиента (все запросы имеют в своем составе поле UserAgent которое выглядит наподобие AppName/1.0) касающейся версии. Когда вы разрабатываете сервер таким образом, любое изменение будет простым. Внесение изменений не будет нарушать имеющиеся соглашения. Просто создавайте новые структуры данных (модели), вносите изменения в factory method для создания экземпляра новой модели для новой версии и все!
При использовании такого подхода ваши приложения версий 1 и 2 могут продолжать работать с одним сервером. Ваш контроллер может создавать объекты версии 1 для старых клиентских приложений и объекты версии 2 для новых.
С предложенной выше парадигмой разделения API на версии через модель прекращение поддержки вашего API становится намного проще. Это очень важно на последних стадиях когда вы публикуете ваш API. Когда вы делаете глобальное обновление API проведите ревизию всех factory method в ваших моделях в соответствии с изменениями вашей бизнес логики.
Если, в ходе релиза версии 3 вашего API, вы решаете прекратить поддержку версии 1 то для этого достаточно удалить соответствующие модели и удалить строки, создающие их экземпляры в ваших factory method-ах. Создание новых версий и прекращение поддержки старых обязательно будут сопровождать ваш проект показывая насколько он гибок для поддержки ключевых решений, диктуемых бизнесом. Бизнес, неспособный к резким переменам и поворотам, обречен. Обычно неспособность к ключевым переменам обусловлена техническим несовершенством проекта. Указанная техника способна решить такую проблему.
Еще один немаловажный момент, касающийся производительности, которому следует уделить внимание — это кэширование. Если вы считаете, что это задача клиентского приложения подумайте хорошенько. В части 2 этой статьи я расскажу как организовать кэширование, используя средства http 1.1.
Доведение до клиента причины ошибки в случае ее появления не менее важно чем отправка правильных данных. Я расскажу об обработке ошибок и интернационализации в части 3 данной статьи. Не буду ничего обещать, в любом случае на написание потребуется время.
От переводчика:
Сам я не являюсь разработчиком под iOS и web-сервисов не разрабатывал, мой уровень в этой области можно описать как «Собираюсь стать начинающим». Но тема мне интересна и статья понравилась, причем настолько, что решил перевести.
Вторая часть
Жизнь стартапа полна перемен, поворотных моментов, в которых от принятых решений зависит дальнейшая судьба проекта. Если ваша кодовая база не сможет обеспечить воплощение самых разных ваших решений – вы проиграли. Серверный код, который достаточно гибок для того, чтобы в короткие сроки подстроиться под нужды бизнеса, решает быть проекту или нет. Успешные стартапы не те, которые просто предложили отличную идею, но те, которые смогли ее качественно воплотить. Успех стартапа зависит от успешности его продукта, будь то приложение под iOS, сервис или API. Последние три года я работал над разными приложениями под iOS (в основном для стартапов) использовавшими web сервисы и в этом блоге я попытался собрать накопленные знания воедино и показать вам лучшие методики, которым вам нужно следовать при разработке RESTful API. Хороший RESTful API тот, который можно менять легко и просто.
Целевая аудитория
Этот пост предназначен для тех, кто обладает знаниями в разработке RESTful API уровня от средних до продвинутых. А также некоторыми базовыми знаниями объектно-ориентированного (или функционального) программирования на таких серверных языках как Java/Ruby/Scala. (Я намеренно проигнорировал PHP или Programmable Hyperlinked Pasta).
Прим. Пер. Тут автор привел ссылку на полушутливую статью о истории языков программирования где PHP был расшифрован как Programmable Hyperlinked Pasta (Программируемая Гиперссылочная Лапша). Что как бы характеризует отношение автора к PHP.
Структура и организация статьи
Статья довольно подробна и состоит из двух частей. Первая описывает основы REST тогда как вторая описывает документирование и поддержку разных версий вашего API. Первая часть для новичков, вторая для профи. Я не сомневаюсь, что вы профи, а потому вот вам ссылка чтобы перескочить сразу к главе «Документирование API». Возможно, вам стоит начать оттуда, если вам кажется, что этот пост из разряда «Многа букаф, ниасилил…».
Принципы RESTful
Сервер может считаться RESTful если он соответствует принципам REST. Когда вы разрабатываете API, который будет в основном использоваться мобильными устройствами, понимание и следование трем наиважнейшим принципам может быть весьма полезным. Причем не только при разработке API, но и при его поддержке и развитии в дальнейшем. Итак, приступим.
Независимость от состояния (Statelessness)
Первый принцип – независимость от состояния. Проще говоря, RESTful сервер не должен отслеживать, хранить и тем более использовать в работе текущую контекстную информацию о клиенте. С другой стороны клиент должен взять эту задачу на себя. Другими словами не заставляйте сервер помнить состояние мобильного устройства, использующего API.
Давайте представим, что у вас есть стартап под названием «Новый Фейсбук». Хороший пример, где разработчик мог совершить ошибку это предоставление вызова API, который позволяет мобильному устройству установить последний прочитанный элемент в потоке (назовем его лентой Фейсбука). Вызов API, обычно возвращающий ленту (назовем его /feed), теперь будет возвращать элементы, которые новее установленного. Звучит умно, не правда ли? Вы «оптимизировали» обмен данными между клиентом и сервером? А вот и нет.
Что может пойти не так в приведенном случае, так это то, что если ваш пользователь использует сервис с двух или трех устройств, то, в случае когда одно из них устанавливает последний прочитанный элемент, то остальные не смогут загрузить элементы ленты, прочитанные на других устройствах ранее.
Независимость от состояния означает, что данные, возвращаемые определенным вызовом API, не должны зависеть от вызовов, сделанных ранее.
Правильный способ оптимизации данного вызова – передача времени создания последней прочитанной записи ленты в качестве параметра вызова API, возвращающего ленту (/feed?lastFeed=20120228). Есть и другой, более «правильный» метод – использование заголовка HTTP If-Modified-Since. Но мы пока не будем углубляться в эту сторону. Мы обсудим это во второй части.
Клиент же со своей стороны, может (должен) помнить параметры, сгенерированные на сервере при обращении к нему и использовать их для последующих вызовов API, если потребуется.
Кэшируемая и многоуровневая архитектура
Второй принцип заключается в предоставлении клиенту информации о том, что ответ сервера может быть кэширован на определенный период времени и использоваться повторно без новых запросов к серверу. Этим клиентом может быть как само мобильное устройство, так и промежуточный прокси сервер. Я расскажу подробнее о кэшировании во второй части.
Клиент – серверное разделение и единый интерфейс
RESTful сервер должен прятать от клиента как можно больше деталей своей реализации. Клиенту не следует знать о том, какая СУБД используется на сервере или сколько серверов в данный момент обрабатывают запросы и прочие подобные вещи. Организация правильного разделения функций важна для масштабирования если ваш проект начнет быстро набирать популярность.
Это пожалуй три самых важных принципа, которым нужно следовать в ходе разработки RESTful сервера. Далее будут описаны три менее важных принципа, но все они имеют непосредственное отношение к тому, о чем мы тут говорим.
REST запросы и четыре HTTP метода
GET
POST
PUT
DELETE
Принцип “кэшируемости” и GET запросы
Главное, что следует помнить — вызов, совершенный через GET не должен менять состояние сервера. Это в свою очередь значит, что ваши запросы могут кэшироваться любым промежуточным прокси (снижение нагрузки). Таким образом Вы, как разработчик сервера, не должны публиковать GET методы, которые меняют данные в вашей базе данных. Это нарушает философию RESTful, особенно второй пункт, описанный выше. Ваши GET вызовы не должны даже оставлять записей в access.log или обновлять данные типа “Last logged in”. Если вы меняете данные в базе, это обязательно должны быть методы POST/PUT.
То самое обсуждение POST vs PUT
Спецификация HTTP 1.1 гласит, что PUT идемпотентен. Это значит, что клиент может выполнить множество PUT запросов по одному URI и это не приведет к созданию записей дубликатов. Операции присвоения — хороший пример идемпотентной операции
String userId = this.request["USER_ID"];
Даже если эту операцию выполнить дважды или трижды, никакого вреда не будет (кроме лишних тактов процессора). POST же с другой стороны не идемпотентен. Это что-то вроде инкремента. Вам следует использовать POST или PUT с учетом того является ли выполняемое действие идемпотентным или нет. Говоря языком программистов, если клиент знает URL объекта, который нужно создать, используйте PUT. Если клиент знает URL метода/класса создающего нужный объект, используйте POST.
PUT www.example.com/post/1234
Используйте PUT если клиент знает URI, который сам бы мог быть результатом запроса. Даже если клиент вызовет это PUT метод много раз, какого либо вреда или дублирующих записей создано не будет.
POST www.example.com/createpost
Используйте POST если сервер сам создает уникальный идентификатор и возвращает его клиенту. Дублирующие записи будут создаваться если этот запрос будет повторяться позже с такими же параметрами.
Более подробная информация в данном обсуждении.
Метод DELETE
DELETE абсолютно однозначен. Он идемпотентен как и PUT, и должен использоваться для удаления записи если таковая существует.
REST ответы
Ответы от Вашего RESTful сервера могут использовать в качестве формата XML или JSON. Лично я предпочитаю JSON, поскольку он более лаконичен и по сети передается меньший объем данных нежели при передаче такого же ответа в формате XML. Разница может быть порядка нескольки сотен килобайт, но, с учетом скоростей 3G и нестабильности обмена с мобильными устройствами, эти несколько сотен килобайт могут иметь значение.
Аутентификация
Аутентификация должна производиться через https и клиент должен посылать пароль в зашифрованном виде. Процесс получения sha1 хэша NSString в Objective-C достаточно понятен и прост и приведенный код наглядно это показывает.
- (NSString *) sha1
{
const char *cstr = [self cStringUsingEncoding:NSUTF8StringEncoding];
NSData *data = [NSData dataWithBytes:cstr length:self.length];
uint8_t digest[CC_SHA1_DIGEST_LENGTH];
CC_SHA1(data.bytes, data.length, digest);
NSMutableString* output = [NSMutableString stringWithCapacity:CC_SHA1_DIGEST_LENGTH * 2];
for(int i = 0; i <; CC_SHA1_DIGEST_LENGTH; i++)
[output appendFormat:@"%02x", digest[i]];
return output;
}
Сервер должен сравнить полученный хэш пароля с сохраненным в его базе хэшем. В любом случае не следует ни при каких условиях передавать пароли с клиента на сервер в открытом виде. Из этого правила не существует исключений! День, когда Ваши пользователи узнают, что вы храните их пароли в открытом виде, может стать последним днем вашего стартапа. Доверие, потерянное однажды, вернуть невозможно.
RFC 2617 описывает два способа аутентификации на HTTP сервере. Первый — это Basic Access, второй Digest. Для мобильных клиентов подходит любой из этих двух методов и большинство серверных (и клиентских тоже) языков обладают встроенными механизмами для реализации таких схем аутентификации.
Если вы планируете сделать свой API публичным, вам следует также посмотреть в сторону oAuth или лучше oAuth 2.0. oAuth позволит Вашим пользователям публиковать контент, созданный в Вашем приложении, на других ресурсах без обмена ключами (логинами/паролями). oAuth также позволяет пользователям контролировать что именно находится в доступе и какие разрешения даны сторонним ресурсам.
Facebook Graph API это наиболее развитая и распространенная реализация oAuth на данный момент. Используя oAuth, пользователи Facebook могут давать доступ к своим фотографиям сторонним приложениям без публикации другой приватной и идентификационной информации (логин/пароль). Пользователь также может ограничить доступ нежелательным приложениям без необходимости менять свой пароль.
До сего момента я говорил об основах REST. Теперь переходим к сути статьи. В последующих главах я буду говорить о практических приемах, которые следует использовать при документировании, создании новых и завершении поддержки старых версий своего API…
Документирование API
Худшая документация, которую может написать разработчик сервера — это длинный, однообразный список вызовов API с описанием параметров и возвращаемых данных. Главная проблема такого подхода заключается в том, что внесение изменений в сервер и формат возвращаемых данных по мере развития проекта становится кошмаром. Я внесу кое какие предложения на этот счет, чтобы разработчик клиентского ПО понимал Вас лучше. Со временем это также поможет Вам в развитии в качестве разработчика серверного ПО.
Документация
Первым шагом я бы порекомендовал подумать об основных, высокоуровневых структурах данных (моделях), которыми оперирует ваше приложение. Затем подумайте над действиями, которые можно произвести над этими компонентами. Документация по foursquare API хороший пример, который стоит изучить перед тем как начать писать свою. У них есть набор высокоуровневых объектов, таких как места, пользователи и тому подобное. Также у них есть набор действий, которые можно произвести над этими объектами. Поскольку вы знаете высокоуровневые объекты и действия над ними в вашем продукте, создание структуры вызовов API становится проще и понятней. Например, для добавления нового места логично будет вызвать метод наподобие /venues/add
Документируйте все высокоуровневые объекты. Затем документируйте запросы и ответы на них, используя эти высокоуровневые объекты вместо простых типов данных. Вместо того, чтобы писать “Этот вызов возвращает три строковых поля, первое содержит id, второе имя, а третье описание” пишите “Этот вызов возвращает структуру (модель), описывающую место”.
Документирование параметров запроса
Давайте представим, что у Вас есть API, позволяющий пользователю входить, используя Facebok token. Вызовем этот метод как /login.
Request
/login
Headers
Authorization: Token XXXXX
User-Agent: MyGreatApp/1.0
Accept: application/json
Accept-Encoding: compress, gzip
Parameters
Encoding type – application/x-www-form-urlencoded
token – “Facebook Auth Token” (mandatory)
profileInfo = “json string containing public profile information from Facebook” (optional)
Где profileinfo высокоуровневый объект. Поскольку вы уже задокументировали внутреннюю структуру этого объекта то такого простого упоминания достаточно. Если Ваш сервер использует такие же Accept, Accept-Encoding и параметр Encoding type всегда вы можете задокументировать их отдельно, вместо повторения их во всех разделах.
Документирование параметров ответа
Ответы на вызовы API должны также быть задокументированы, основываясь на высокоуровневой модели объектов. Цитируя тот же пример foursquare, вызов метода /venue/#venueid# вернет структуру данных (модель), описывающую место проведения мероприятия.
Обмен идеями, документирование или информирование других разработчиков о том, что вы вернете в ответ на запрос станет проще если Вы задокументируете ваш API используя структуру объектов (моделей). Наиболее важный итог этой главы — это необходимость воспринимать документацию как контракт, который заключаете Вы, как разработчик серверной части и разработчики клиентских приложений (iOS/Android/Windows Phone/Чтобытонибыло).
Причины создания новых и прекращения поддержки старых версий вашего API
До появления мобильных приложений, в эпоху Web 2.0 создание разных версий API не было проблемой. И клиент (JavaScript/AJAX front-end) и сервер разворачивались одновременно. Потребители (ваши клиенты) всегда использовали самую последнюю версию клиентского ПО для доступа к системе. Поскольку вы — единственная компания, разрабатывающая как клиентскую так и серверную часть, вы полностью контролируете то как используется ваш API и изменения в нем всегда сразу же применялись в клиентской части. К сожалению это невозможно с клиентскими приложениями, написанными под разные платформы. Вы можете развернуть API версии 2, считая что все будет отлично, однако это приведет к неработоспособности приложений под iOS, использующих старую версию. Поскольку еще могут быть пользователи, использующие такие приложения несмотря на то, что вы выложили обновленную версию в App Store. Некоторые компании прибегают к использованию Push уведомлений для напоминаний о необходимости обновления. Единственное к чему это приведет — потеря такого клиента. Я видел множество айфонов, у которых было более 100 приложений, ожидающих обновления. Шансы, что ваше станет одним из них, весьма велики. Вам всегда надо быть готовым к разделению вашего API на версии и к прекращению поддержки некоторых из них как только это потребуется. Однако поддерживайте каждую версию своего API не менее трех месяцев.
Разделение на версии
Развертывание вашего серверного кода в разные папки и использование разных URL для вызовов не означает что вы удачно разделили ваш API на версии.
Так example.com/api/v1 будет использоваться версией 1.0 приложения, а ваша свежайшая и крутейшая версия 2.0 будет использовать example.com/api/v2
Когда вы делаете обновления, вы практически всегда вносите изменения во внутренние структуры данных и в модели. Это включает изменения в базе данных (добавление или удаление столбцов). Для лучшего понимания давайте представим, что ваш “новый Фейсбук” имеет вызов API, называемый /feed который возвращает объект “Лента”. На сегодня, в версии 1, ваш объект “Лента” включает URL аватарки пользователя (avatarURL), имя пользователя (personName), текст записи (feedEntryText) и время создания (timeStamp) записи. Позднее, в версии 2, вы представляете новую возможность, позволяющую рекламодателям размещать описания своих продуктов в ленте. Теперь объект “Лента” содержит, скажем так, новое поле “sourceName”, которое перекрывает собой имя пользователя при отображении ленты. Таким образом приложение должно отображать “sourceName” вместо “personName”. Поскольку приложению больше не нужно отображать “personName” если задана “sourceName”, вы решаете не отправлять “personName” если есть “sourceName”. Это все выглядит неплохо до тех пор, пока старая версия вашего приложения, версия 1 не обратится к обновленному серверу. Она будет отображать ваши рекламные записи из ленты без заголовка поскольку “personName” отсутствует. “Грамотный” способ решения такой проблемы — отправлять как “personName”, так и “sourceName”. Но, друзья, жизнь не всегда так проста. Как разработчик вы не сможете отслеживать все одиночные изменения которые когда либо были произведены с каждой моделью данных в вашем объекте. Это не очень эффективный способ внесения изменений поскольку через пол года вы практически забудете почему и как что-то было добавлено к вашему коду.
Возвращаясь к web 2.0, это не было проблемой вообще. JavaScript клиент немедленно модифицировался для поддержки изменений в API. Однако установленные iOS приложения от вас больше не зависят. Теперь их обновление — прерогатива пользователя.
У меня есть элегантное решение для хитрых ситуаций подобного толка.
Парадигма разделения на версии через URL
Первое решение — это разделение с использованием URL.
api.example.com/v1/feeds будет использоваться версией 1 iOS приложения тогда как
api.example.com/v2/feeds будет использоваться версией 2.
Несмотря на то, что звучит это все неплохо, вы не сможете продолжать создание копий вашего серверного кода для каждого изменения в формате возвращаемых данных. Я рекомендую использование такого подхода только в случае глобальных изменений в API.
Парадигма разделения на версии через модель
Выше я показал как документировать ваши структуры данных (модели). Рассматривайте эту документацию как контракт между разработчиками серверной и клиентской частей. Вам не следует вносить изменения в модели без изменения версии. Это значит, что в предыдущем случае должно быть две модели, Feed1 и Feed2.
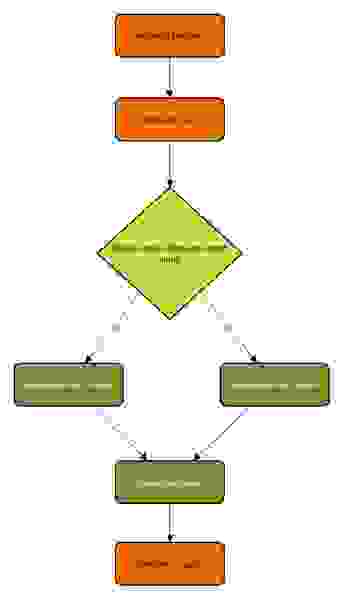
В Feed2 есть поле sourceName и она возвращает sourceName вместо personName если sourceName установлен. Поведение Feed1 остается таким же, как это было оговорено в документации. Алгоритм работы контроллера будет примерно таким:

Вам следует переместить логику создания экземпляра класса в отдельный класс согласно паттерну Factory method. Соответствующий код контроллера должен выглядеть примерно так:
Feed myFeedObject = Feed.createFeedObject("1.0");
myFeedObject.populateWithDBObject(FeedDao* feedDaoObject);
Где решение о версии используемого API будет принимать контроллер в соответствии с полем UserAgent текста запроса.
Дополнение:
Вместо использования номера версии из строки UserAgent, правильней будет использовать номер версии в заголовке Accept. Таким образом вместо отправки
Accept: application/json
следует отправлять
Accept: application/myservice.1.0+json
Таким образом у вас появляется возможность указывать версию API для каждого запроса к REST серверу. Спасибо читателям hacker news за этот совет.
Контроллер использует метод Feed factory для создания корректного объекта feed (лента) основываясь на информации из запроса клиента (все запросы имеют в своем составе поле UserAgent которое выглядит наподобие AppName/1.0) касающейся версии. Когда вы разрабатываете сервер таким образом, любое изменение будет простым. Внесение изменений не будет нарушать имеющиеся соглашения. Просто создавайте новые структуры данных (модели), вносите изменения в factory method для создания экземпляра новой модели для новой версии и все!
При использовании такого подхода ваши приложения версий 1 и 2 могут продолжать работать с одним сервером. Ваш контроллер может создавать объекты версии 1 для старых клиентских приложений и объекты версии 2 для новых.
Прекращение поддержки
С предложенной выше парадигмой разделения API на версии через модель прекращение поддержки вашего API становится намного проще. Это очень важно на последних стадиях когда вы публикуете ваш API. Когда вы делаете глобальное обновление API проведите ревизию всех factory method в ваших моделях в соответствии с изменениями вашей бизнес логики.
Если, в ходе релиза версии 3 вашего API, вы решаете прекратить поддержку версии 1 то для этого достаточно удалить соответствующие модели и удалить строки, создающие их экземпляры в ваших factory method-ах. Создание новых версий и прекращение поддержки старых обязательно будут сопровождать ваш проект показывая насколько он гибок для поддержки ключевых решений, диктуемых бизнесом. Бизнес, неспособный к резким переменам и поворотам, обречен. Обычно неспособность к ключевым переменам обусловлена техническим несовершенством проекта. Указанная техника способна решить такую проблему.
Кэширование
Еще один немаловажный момент, касающийся производительности, которому следует уделить внимание — это кэширование. Если вы считаете, что это задача клиентского приложения подумайте хорошенько. В части 2 этой статьи я расскажу как организовать кэширование, используя средства http 1.1.
Обработка ошибок и интернационализация вашего API
Доведение до клиента причины ошибки в случае ее появления не менее важно чем отправка правильных данных. Я расскажу об обработке ошибок и интернационализации в части 3 данной статьи. Не буду ничего обещать, в любом случае на написание потребуется время.
От переводчика:
Сам я не являюсь разработчиком под iOS и web-сервисов не разрабатывал, мой уровень в этой области можно описать как «Собираюсь стать начинающим». Но тема мне интересна и статья понравилась, причем настолько, что решил перевести.
Вторая часть
