Решение рассматривается (пока) только для одного сайта — того, на котором мы находимся. Идея появилась в результате того, что один пользователь сделал юзерскрипт, который переадресует страницу на кеш Гугла, если вместо статьи видим «Доступ к публикации закрыт». Понятно, что это решение будет работать лишь частично, но полного решения пока не существует. Можно повысить вероятность нахождения копии выбором результата из нескольких сервисов. Этим стал заниматься скрипт HabrAjax (наряду с 3 десятками других функций). Теперь (с версии 0.859), если пользователь увидел полупустую страницу, с которой можно перейти лишь на главную, в личную страницу автора (если повезёт) и назад, юзерскрипт предоставляет несколько альтернативных ссылок, в которых можно попытаться найти потерю. И тут начинается самое интересное, потому что ни один сервис не заточен на качественное архивирование одного сайта.
Кстати, статья и исследования порождены интересным опросом А вас раздражает постоянное «Доступ к публикации закрыт»? и скриптом пользователя dotneter — комментарий habrahabr.ru/post/146070/#comment_4914947.
Требуется, конечно, более качественный сервис, поэтому, кроме описания нынешней скромной функциональности (вероятность найти в Гугл-кеше и на нескольких сайтах-копировщиках), поднимем в статье краудсорсинговые вопросы — чтобы «всем миром» задачу порешать и прийти к качественному решению, тем более, что решение видится близким для тех, кто имеет сервис копирования контента. Но давайте обо всём по порядку, рассмотрим все предложенные на данный момент решения.
В отличие от кеша Яндекса, к нему имеется прямой доступ по ссылке, не надо просить пользователя «затем нажать кнопку „копия“». Однако, все кеширователи, как и известный archive.org, имеют ряд ненужных особенностей.
1) они просто не успевают мгновенно и многократно копировать появившиеся ссылки. Хотя надо отдать должное, что к популярным сайтам обращение у них частое, и за 2 и более часов они кешируют новые страницы. Каждый в своё время.
2) далее, возникает такая смешная особенность, что они могут чуть позже закешировать пустую страницу, говорящую о том, что «доступ закрыт».
3) поэтому результат кеширования — как повезёт. Можно обойти все такие кеширующие ссылки, если очень надо, но и оттуда информацию стоит скопировать себе, потому что вскоре может пропасть или замениться «более актуальной» бессмысленной копией пустой страницы.
Он работает на весь интернет с мощностями, меньшими, чем у поисковиков, поэтому обходит страницы какого-то далёкого русскоязычного сайта редко. Частоту можно увидеть здесь: wayback.archive.org/web/20120801000000*/http://habrahabr.ru
Да и цель сайта — запечатлеть фрагменты истории веба, а не все события на каждом сайте. Поэтому мы редко будем попадать на полезную информацию.
Нет прямой ссылки, поэтому нужно просить (самое простое) пользователя нажать на ссылку «копия» на странице поиска, на которой будет одна эта статья (если её Яндекс вообще успел увидеть).
Как показывает опыт, статья, повисевшая пару часов и закрытая автором, довольно успешно сохраняется в кешах поисковиков. Впоследствии, скорее всего, довольно быстро заменится на пустую. Всё это, конечно, не устроит пользователей веба, который по определению должен хранить попавшую в него информацию.
pipes.yahoo.com/pipes/search?q=habrahabr+full&x=0&y=0 и прочие.
Довольно интересное решение. Те, кто умеет их настраивать, возможно, полноценно решат задачу архивирования RSS. Из имеющегося, я не нашёл пайпов с поиском статьи по её номеру, поэтому пока нет прямой ссылки на такие сохранённые полные статьи. (Кто умеет с ним работать — прошу изготовить такую ссылку для скрипта.)
Все из них болеют тем, что не дают ссылки на статью по её номеру, не приводят полный текст статьи, а некоторые вообще ограничиваются «захабренным» или «настолько ленивы», что копируют редко (к примеру, раз в день), что актуально не всегда. Однако, если хотя бы один автор копировщика подкрутит движок на сохранение полноценного и актуального контента, он окажет неоценимую услугу интернету, и его сервис займёт главное место в скрипте HabrAjax.
Из живых я нашёл пока что 4, некоторые давно существовавшие (itgator) на данный момент не работали. В общем, пока что они почти бесполезны, потому что заставляют искать статью по названию или ключевым словам, а не по адресу, по которому пользователь пришёл на закрытую страницу (а по словам отлично ищет Яндекс и не только по одному их сайту). Приведены в скрипте для какой-нибудь полезной информации.
Перед сообществом стоит задача, не утруждая организаторов сайта, довести продукт до качественного, не теряющего информацию ресурса. Для этого, как правильно заметили в комментариях к опросу, нужен архиватор актуальных полноценных статей (и комментариев к ним заодно).
В настоящее время неполное решение её, как описано выше, выглядит так:
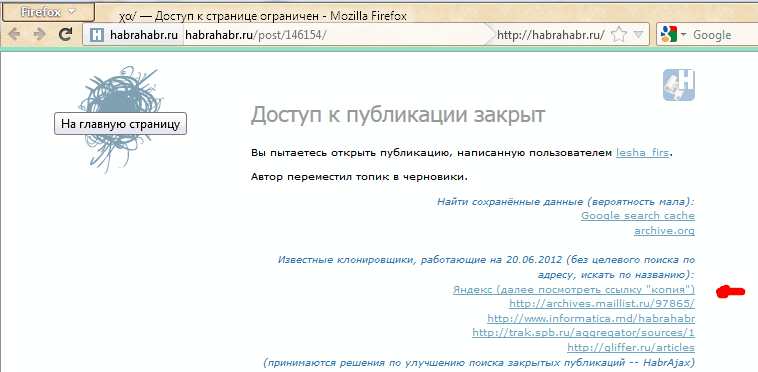
Если искать в Яндексе, то подобранный адрес выведет единственную ссылку (или ничего):

Нажав ссылку «копия», увидим (если повезёт) сохранённую копию (страница выбрана исключительно для актуального на данный момент примера):
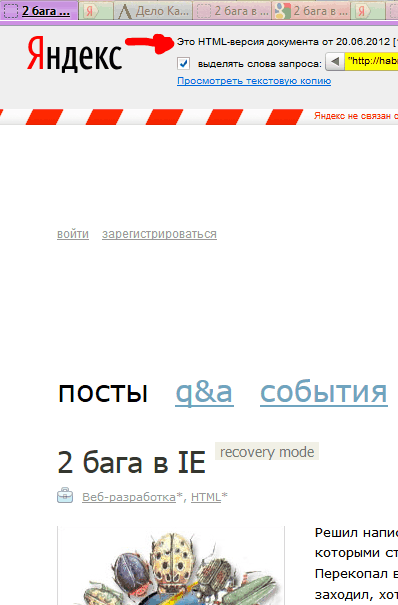
В Гугле несколько проще — сразу попадаем на копию, если тоже повезёт, и Гугл успел сохранить именно то, что нам надо, а не дубль отсутствующей страницы.
Забавно, что скрипт теперь предлагает «выбор альтернативных сервисов» и в этом случае («профилактические работы»):

Жду предложений по добавлению сервисов и копировщиков (или хотя бы проектов) (для неавторизованных — на почту spmbt0 на известном гуглоресурсе, далее выберем удобный формат).
UPD 23:00: опытным путём для mail.ru было выяснено строение прямой ссылки на кеш:
Добавил ссылки мейла и ВК в обновление скрипта (habrAjax) (0.861), теперь там — на 2 строчки больше.
Кстати, статья и исследования порождены интересным опросом А вас раздражает постоянное «Доступ к публикации закрыт»? и скриптом пользователя dotneter — комментарий habrahabr.ru/post/146070/#comment_4914947.
Требуется, конечно, более качественный сервис, поэтому, кроме описания нынешней скромной функциональности (вероятность найти в Гугл-кеше и на нескольких сайтах-копировщиках), поднимем в статье краудсорсинговые вопросы — чтобы «всем миром» задачу порешать и прийти к качественному решению, тем более, что решение видится близким для тех, кто имеет сервис копирования контента. Но давайте обо всём по порядку, рассмотрим все предложенные на данный момент решения.
Кеш Гугла
В отличие от кеша Яндекса, к нему имеется прямой доступ по ссылке, не надо просить пользователя «затем нажать кнопку „копия“». Однако, все кеширователи, как и известный archive.org, имеют ряд ненужных особенностей.
1) они просто не успевают мгновенно и многократно копировать появившиеся ссылки. Хотя надо отдать должное, что к популярным сайтам обращение у них частое, и за 2 и более часов они кешируют новые страницы. Каждый в своё время.
2) далее, возникает такая смешная особенность, что они могут чуть позже закешировать пустую страницу, говорящую о том, что «доступ закрыт».
3) поэтому результат кеширования — как повезёт. Можно обойти все такие кеширующие ссылки, если очень надо, но и оттуда информацию стоит скопировать себе, потому что вскоре может пропасть или замениться «более актуальной» бессмысленной копией пустой страницы.
Кеш archive.org
Он работает на весь интернет с мощностями, меньшими, чем у поисковиков, поэтому обходит страницы какого-то далёкого русскоязычного сайта редко. Частоту можно увидеть здесь: wayback.archive.org/web/20120801000000*/http://habrahabr.ru
Да и цель сайта — запечатлеть фрагменты истории веба, а не все события на каждом сайте. Поэтому мы редко будем попадать на полезную информацию.
Кеш Яндекса
Нет прямой ссылки, поэтому нужно просить (самое простое) пользователя нажать на ссылку «копия» на странице поиска, на которой будет одна эта статья (если её Яндекс вообще успел увидеть).
Как показывает опыт, статья, повисевшая пару часов и закрытая автором, довольно успешно сохраняется в кешах поисковиков. Впоследствии, скорее всего, довольно быстро заменится на пустую. Всё это, конечно, не устроит пользователей веба, который по определению должен хранить попавшую в него информацию.
Yahoo Pipes
pipes.yahoo.com/pipes/search?q=habrahabr+full&x=0&y=0 и прочие.
Довольно интересное решение. Те, кто умеет их настраивать, возможно, полноценно решат задачу архивирования RSS. Из имеющегося, я не нашёл пайпов с поиском статьи по её номеру, поэтому пока нет прямой ссылки на такие сохранённые полные статьи. (Кто умеет с ним работать — прошу изготовить такую ссылку для скрипта.)
Многочисленные клонировщики
Все из них болеют тем, что не дают ссылки на статью по её номеру, не приводят полный текст статьи, а некоторые вообще ограничиваются «захабренным» или «настолько ленивы», что копируют редко (к примеру, раз в день), что актуально не всегда. Однако, если хотя бы один автор копировщика подкрутит движок на сохранение полноценного и актуального контента, он окажет неоценимую услугу интернету, и его сервис займёт главное место в скрипте HabrAjax.
Из живых я нашёл пока что 4, некоторые давно существовавшие (itgator) на данный момент не работали. В общем, пока что они почти бесполезны, потому что заставляют искать статью по названию или ключевым словам, а не по адресу, по которому пользователь пришёл на закрытую страницу (а по словам отлично ищет Яндекс и не только по одному их сайту). Приведены в скрипте для какой-нибудь полезной информации.
Задача
Перед сообществом стоит задача, не утруждая организаторов сайта, довести продукт до качественного, не теряющего информацию ресурса. Для этого, как правильно заметили в комментариях к опросу, нужен архиватор актуальных полноценных статей (и комментариев к ним заодно).
В настоящее время неполное решение её, как описано выше, выглядит так:
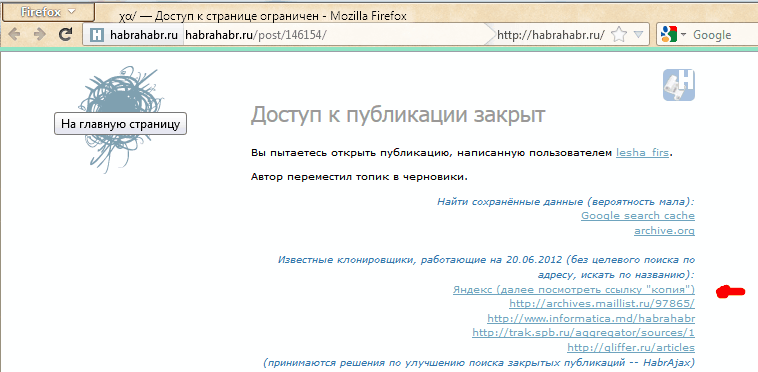
Если искать в Яндексе, то подобранный адрес выведет единственную ссылку (или ничего):

Нажав ссылку «копия», увидим (если повезёт) сохранённую копию (страница выбрана исключительно для актуального на данный момент примера):
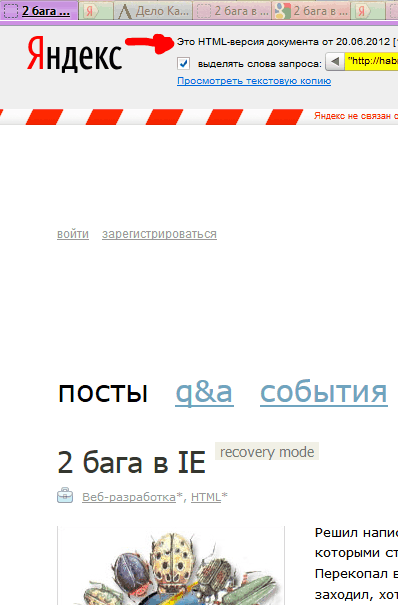
В Гугле несколько проще — сразу попадаем на копию, если тоже повезёт, и Гугл успел сохранить именно то, что нам надо, а не дубль отсутствующей страницы.
Забавно, что скрипт теперь предлагает «выбор альтернативных сервисов» и в этом случае («профилактические работы»):

Жду предложений по добавлению сервисов и копировщиков (или хотя бы проектов) (для неавторизованных — на почту spmbt0 на известном гуглоресурсе, далее выберем удобный формат).
UPD 23:00: опытным путём для mail.ru было выяснено строение прямой ссылки на кеш:
'http://hl.mailru.su/gcached?q=cache:'+ window.location
Добавил ссылки мейла и ВК в обновление скрипта (habrAjax) (0.861), теперь там — на 2 строчки больше.
