 В ряду наших продуктов для разработчиков пополнение – выпущена очередная версия ABBYY FlexiCapture Engine. Напомню, что это продукт, позволяющий встраивать технологию ввода данных из изображений (data capture) в пользовательские решения.
В ряду наших продуктов для разработчиков пополнение – выпущена очередная версия ABBYY FlexiCapture Engine. Напомню, что это продукт, позволяющий встраивать технологию ввода данных из изображений (data capture) в пользовательские решения. Одной из интересных фич новой версии стала возможность быстрой настройки на извлечение данных из документов простых типов. Мои коллеги уже рассказывали читателям хабра про то, как эта функция реализована во FlexiLayout Studio 10. В новую версию продукта добавлено API, дающее полный программный доступ к этой функциональности. Кроме этого мы сделали простой в использовании инструмент (доступный также в виде исходного кода), который позволяет всего за несколько минут (как показано вот в этом видео) настроиться на задачу пользователя и сделать быстрый работающий прототип решения, не вникая глубоко в тонкости технологии.
Эта статья написана разработчиком для разработчиков и расскажет вам о возможностях и ограничениях данной технологии – то, чего вы не найдёте в маркетинговых материалах.
Одной из известных проблем, стоящих на пути широкого использования технологий data capture, являются высокие начальные инвестиции времени и сил на настройку работы с требуемыми типами изображений. Разработчку-интегратору необходимо научиться работать с целым рядом инструментов и разобраться в тонкостях достаточно сложной технологии, которая чаще всего не соответствует его основному профилю работы и предыдущему опыту. Только после этого он может собрать самый простой прототип готового решения и дать оценку эффективности и целесообразности всего проекта.
Новый инструментарий позволяет отложить глубокое знакомство с технологией либо на этап тонкой настройки готового решения перед выпуском, либо даже на версию номер два. Он не может полностью заменить продвинутый инструмент типа FlexiLayout Studio, но позволяет не переусложнять работу в простых случаях или в более сложных случаях быстро получить упрощённый работающий прототип.
Как мы уже описывали вот в этой статье, собственно извлечение данных с помощью API требует всего несколько строк кода, среди которых, однако, есть вот такая:
// Создадим экземпляр процессора и сконфигурируем его одним или более определениями документов
IFlexiCaptureProcessor processor = engine.CreateFlexiCaptureProcessor();
processor.AddDocumentDefinitionFile( sampleFolder + "Invoice_eng.fcdot" );
Эта одиночная строка кода и настраивает работу на определённый тип документа. Файл с расширением FCDOT (FlexiCapture DОcument Template) содержит описание извлекаемых данных с накладываемыми ограничениями, способ нахождения этих данных на изображении, настройки распознавания и, опционально, настройки экспорта данных документа.
При работе с примерами всё просто – нужный файл определения документа прилагается. Однако как получить подобное определение документа для текущей задачи, чтобы просто “пощупать”, как оно будет работать?
До выхода 10-ки для этого в любом случае требовалось установить настольную версию FlexiCapture и научиться работать как минимум с редактором определений документов (для работы с документами с жёсткой структурой с хорошо определёнными реперами), а в большинстве более “жизненных” случаев нужно было ещё и научиться работать с инструментом для описания гибкой разметки документов FlexiLayout Studio. При этом у вас вряд ли получилось бы создать даже простейший работающий вариант “слёту” – практически наверняка пришлось бы вдумчиво почитать документацию для обоих инструментов или пройти курс обучения.
Что же теперь? Теперь у нас есть простой пример-инструмент Automatic Template Generation, сделанный в виде wizard-а, который поможет вам получить удовлетворительно работающий прототип за несколько минут. Посмотрим на примере, как это работает.
Задача
 Предположим, мы хотим написать приложение для регистрации чеков в некоторой бухгалтерской системе и у нас есть пачка отсканированных чеков. Отберём из этой пачки однотипные чеки и попробуем сделать прототип определения документа (шаблон документа) для нашего приложения.
Предположим, мы хотим написать приложение для регистрации чеков в некоторой бухгалтерской системе и у нас есть пачка отсканированных чеков. Отберём из этой пачки однотипные чеки и попробуем сделать прототип определения документа (шаблон документа) для нашего приложения.Заранее скажу о возможностях и ограничениях:
• мы не сможем сделать универсальный шаблон, хорошо работающий с произвольными чеками – наш шаблон будет хорошо работать с более-менее однотипными чеками желательно из одного источника
• в текущей версии мы не сможем описать сложные структуры типа таблиц; для подобных вещей потребуется изучить FlexiLayout Studio
• но мы вполне сможем извлечь такие “плоские” данные как номер, дата, сумма и т.п.
Решение
Итак, начнём. Для начала нам понадобиться папочка с несколькими (3-5 шт.) изображениями интересующего нас типа. Это будет папка с изображениями для обучения (training images). На данном этапе нам желательны изображения хорошего качества, для того чтобы в данных не было лишнего “шума” и шаблон соответствовал бы случаю с идеальным распознаванием.
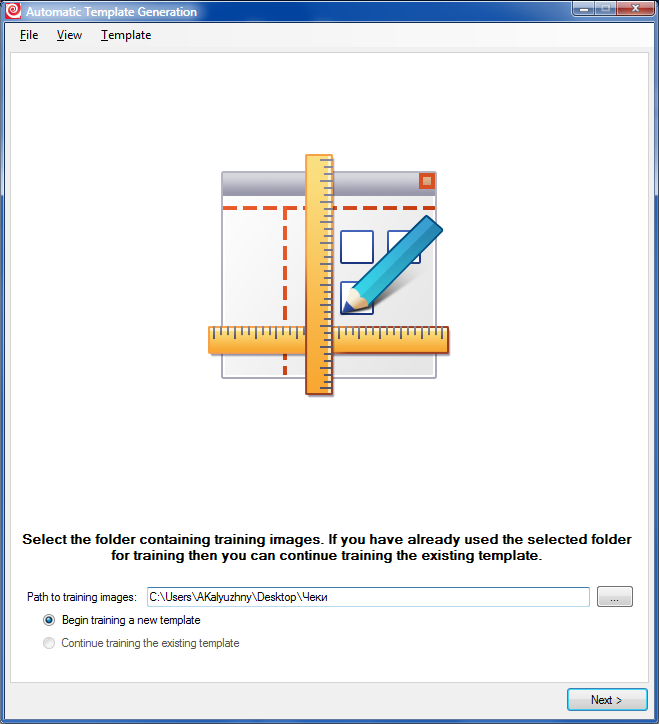
1. Запускаем визард и указываем путь к нашей папке:
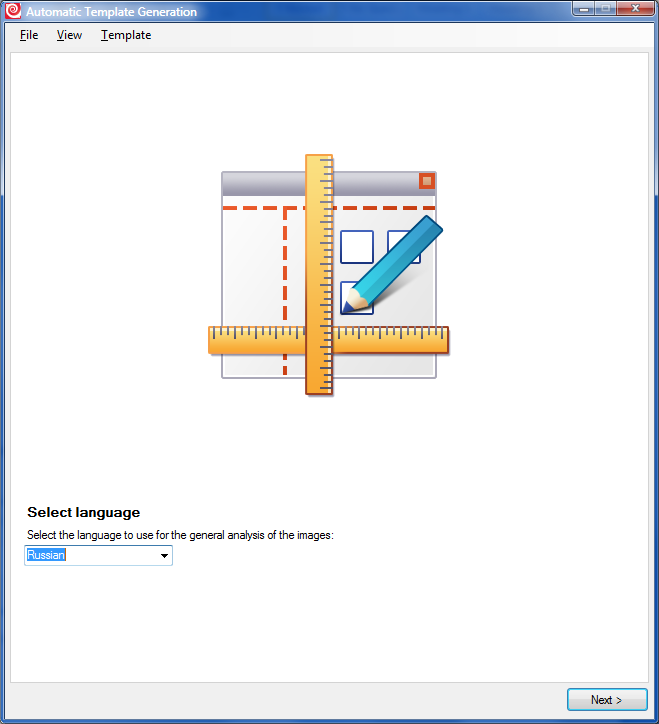
2. Выбираем язык:
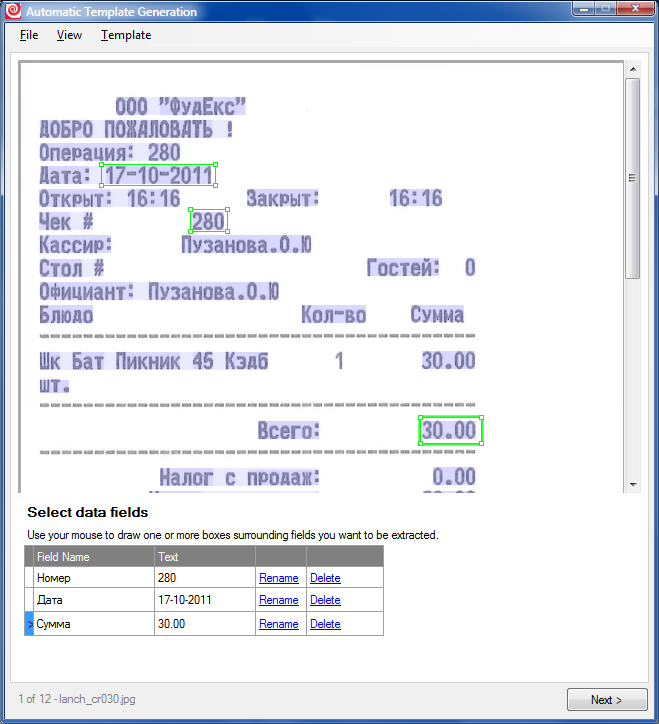
3. “Рисуем” извлекаемые поля и даём им названия:
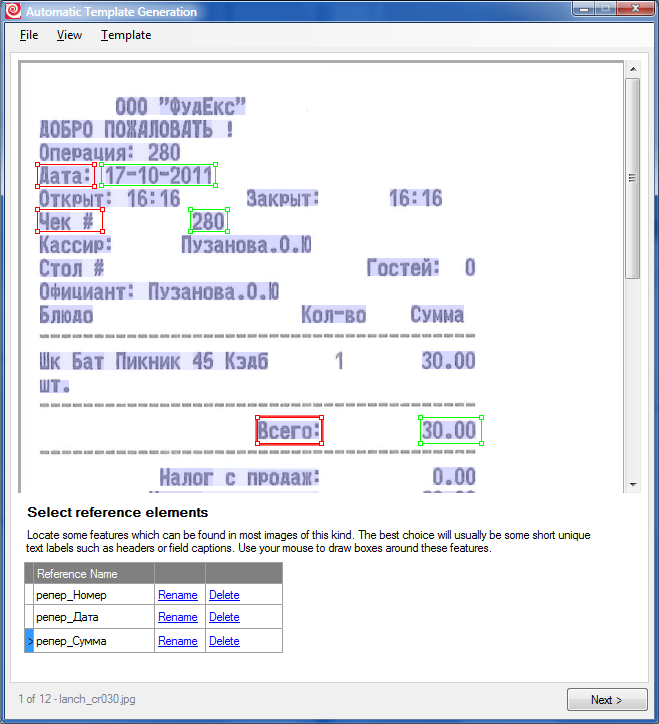
4. Теперь нам нужно нарисовать опорные элементы (reference elements). Это единственный не совсем тривиальный шаг во всём процессе. Опорные элементы – это несколько отобранных статических (то есть постоянных) объектов на изображении (обычно текст), относительно которых ищутся поля с переменным содержанием. Обычно, как в нашем примере (см. скриншот), названия полей – это хорошие кандидаты на роль опорных элементов.
Хозяйке на заметку
NB. Опорный элемент необязательно должен быть у каждого поля. Это может быть одна постоянная строчка на небольшом документе, относительно которой поля расположены достаточно жёстко. Опорных элементов не должно быть слишком много, чтобы не вносить лишнюю путаницу. Текст опорного элемента может меняться, главное, чтобы сохранялась семантика: в нашем случае вместо “Всего:” на некоторых чеках могло бы быть “Итого:” – в процессе обучения нужно было бы просто единожды указать, что это одно и то же. Важно, чтобы текст был уникальным – например, если на документе одновременно присутствуют “Итого” и “Итого с НДС”, то отдельное слово “Итого” будет плохой опорой.
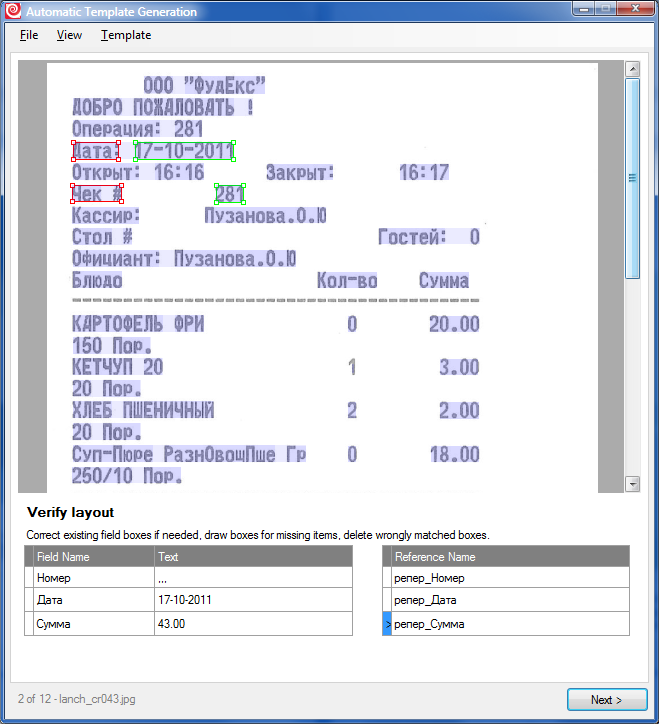
5. Далее мы последовательно проходим через все изображения в нашем тренировочном пакете и проверяем разметку. Система для каждой картинки предлагает вариант разметки, который получается по результатам обучения на уже проверенных картинках. Наша задача – исправить ошибки: исправить геометрию полей, нарисовать ненайденные, удалить лишние. В нашем случае ошибок в наложении нет уже после первой картинки, но есть мелкие проблемы с распознаванием.
Хозяйке на заметку
NB. Проблемы с распознаванием случаются из-за того, что у нас используются параметры распознавания по умолчанию там, где можно было бы их уточнить (например, задать тип шрифта – матричный принтер и ограничить возможный алфавит или задать регулярное выражение для некоторых полей). В API такая возможность есть уже сейчас, но в рассматриваемом инструменте такой функциональности пока нет.
NB. Некоторое поле может отсутствовать на некоторых изображениях.
NB. Через меню Template\Modify Language and Fields можно в любой момент вернуться к редактированию языка и полей, если что-то забыли.
NB. Некоторое поле может отсутствовать на некоторых изображениях.
NB. Через меню Template\Modify Language and Fields можно в любой момент вернуться к редактированию языка и полей, если что-то забыли.
6. После того как мы закончили обучение на отобранных изображениях, предлагается проверить получившийся шаблон. Мы отвечаем «да» и выбираем в качестве тестовой папку, где лежат все изображения нужного типа, которые у нас есть.
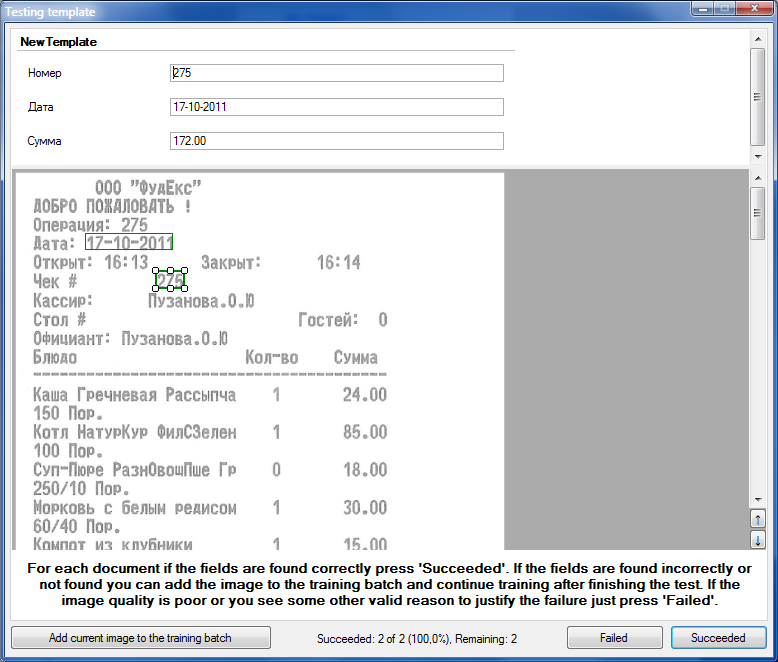
Последовательно для каждой картинки из папки нам предлагаются результаты наложения. Наша задача нажимать Succeeded или Failed для сбора статистики. Если шаблон не наложился на некоторую картинку, а картинка выглядит вполне нормальной, мы можем добавить её в пакет для тестирования, нажав на кнопку Add current image to the training batch. После завершения теста можно будет “дообучиться на добавленных картинках” и, таким образом, последовательно улучшать шаблон.
Хозяйке на заметку
NB. На этом этапе можно подмешивать в пакет для обучения изображения худшего качества, чтобы учесть часто встречающиеся ошибки. Главное, с этим не переусердствовать.
NB. Работу с приложением можно в любой момент прервать. При повторном запуске можно будет продолжить с того места, где закончили. Более того мы всегда можем вернуться к нашему “проекту”, если у нас через неделю или месяц появились новые изображения, на которых мы хотим улучшить работу.
NB. Работу с приложением можно в любой момент прервать. При повторном запуске можно будет продолжить с того места, где закончили. Более того мы всегда можем вернуться к нашему “проекту”, если у нас через неделю или месяц появились новые изображения, на которых мы хотим улучшить работу.
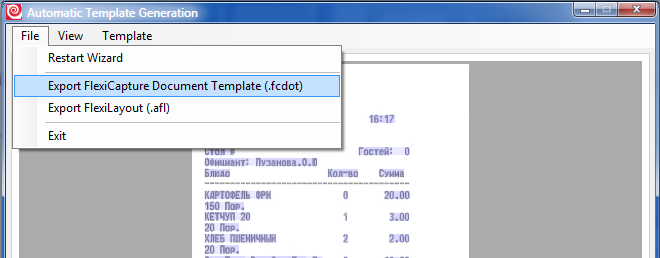
7. После того как результат нас удовлетворил, последнее, что нам осталось сделать – это экспортировать получившийся шаблон в FCDOT файл, с чего всё и началось, и вернуться к написанию кода нашего приложения.
Результат
В результате мы получили шаблон, который на наши изображения накладывается очень неплохо (с качеством выше 90), но есть некоторые проблемы при распознавании полей, так как не учтены особенности шрифта и типы данных полей (дата, число и т.п.). Для прототипа он вполне неплох.
Ещё раз повторюсь, что описанный инструмент не претендует на универсальность. Если нужна универсальность, то придётся научиться использовать FlexiLayout Studio и язык гибких описаний. Но для действительно простых задач типа “извлечь несколько полей”, он работает вполне прилично и позволяет получить работающее решение быстрее и проще.
Немного об API
Описанный инструмент полностью написан на общедоступном API, поставляется с исходными кодами, и наши клиенты могут модифицировать его под свои нужды или использовать в качестве базы для изготовления инструментов для конечных пользователей. Конечным пользователям подобная функциональность может быть полезна для возможности быстрой настройки системы на новые документы.
Работа примера на уровне вызовов API выглядит так (дальше см. комментарии):
СЦЕНАРИЙ 1 – ЛИНЕЙНЫЙ. ИДЁМ ПРЕДСКАЗУЕМО ОТ НАЧАЛА ДО КОНЦА. ПРОЩЕ ДЛЯ ПОНИМАНИЯ
Код
// Создаём пакет для обучения и наполняем изображениями
ITrainingBatch trainingBatch = engine.CreateTrainingBatch( rootFolder, "_TrainingBatch", "English" );
try {
trainingBatch.AddImageFile( rootFolder + "\\00.jpg" );
trainingBatch.AddImageFile( rootFolder + "\\01.jpg" );
// На первом изображении определяем структуру документа
ITrainingPage firstPage = trainingBatch.Pages[0];
// Перед началом работы страницу нужно подготовить. На этом этапе изображение анализируется и извлекаются
// примитивные объекты (которые можно использовать в UI для подсказок пользователю)
firstPage.PrepareLayout();
// Пользователь “рисует” на изображении поля и опорные элементы. Эмулируем этот процесс
for( int j = 0; j < firstPage.ImageObjects.Count; j++ ) {
ITrainingImageObject obj = firstPage.ImageObjects[j];
string text = obj.RecognizedText;
// Пользователь “видит” текст
if( text == "978-1-4095-3439-6" ) {
// “Рисует” поле
ITrainingField isbnField = trainingBatch.Definition.Fields.AddNew( "ISBN", TrainingFieldTypeEnum.TFT_Field );
firstPage.SetFieldBlock( isbnField, obj.Region );
break;
}
}
for( int j = 0; j < firstPage.ImageObjects.Count; j++ ) {
ITrainingImageObject obj = firstPage.ImageObjects[j];
string text = obj.RecognizedText;
// Пользователь “видит” текст опорного элемента
if( text == "ISBN" ) {
// “Рисует” опорный элемент
ITrainingField isbnTag = trainingBatch.Definition.Fields.AddNew( "ISBNTag", TrainingFieldTypeEnum.TFT_ReferenceText );
firstPage.SetFieldBlock( isbnTag, obj.Region );
break;
}
}
assert( trainingBatch.Definition.Fields.Count == 2 );
// Структура определена и разметка проверена
trainingBatch.SubmitPageForTraining( firstPage );
// Проверяем последовательно разметку всех страниц
for( int i = 1; i < trainingBatch.Pages.Count; i++ ) {
ITrainingPage page = trainingBatch.Pages[i];
// Кроме извлечения примитивных объектов, система пытается предсказать разметку
page.PrepareLayout();
// Пользователь проверил разметку
trainingBatch.SubmitPageForTraining( page );
}
// Экпортируем гибкую разметку. На её основе шаблон создаётся одним вызовом CreateDocumentDefinitionFromAFL
trainingBatch.Definition.ExportToAFL( rootFolder + "\\_TrainingBatch\\NewTemplate.afl" );
} finally {
trainingBatch.Close();
}
СЦЕНАРИЙ 2 – НЕЛИНЕЙНЫЙ. ПОЛЬЗОВАТЕЛЬ ИТЕРИРУЕТ ПО СТРАНИЦАМ И В ЛЮБОЙ МОМЕН МОЖЕТ ИЗМЕНИТЬ ОПИСАНИЕ. УДОБНЕЕ ДЛЯ ПОЛЬЗОВАТЕЛЯ
Код
// Создаём пакет для обучения и наполняем изображениями
ITrainingBatch trainingBatch = engine.CreateTrainingBatch( rootFolder, "_TrainingBatch", "English" );
try {
trainingBatch.AddImageFile( rootFolder + "\\00.jpg" );
trainingBatch.AddImageFile( rootFolder + "\\01.jpg" );
// Перебираем страницы, пока пользователь не проверит разметку на всех
ITrainingPage page = trainingBatch.PrepareNextPageNotSubmittedForTraining();
while( page != null ) {
// Пользователь может в любой момент дорисовать поле, при этом цикл проверки будет пройден заново. В этой
// эмуляции предполагаем, что пользователь определяет все нужные поля уже на первой странице
if( page == trainingBatch.Pages[0] ) {
for( int j = 0; j < page.ImageObjects.Count; j++ ) {
TrainingImageObject obj = page.ImageObjects[j];
string text = obj.RecognizedText;
// Пользователь “видит” текст
if( text == "978-1-4095-3439-6" ) {
// “Рисует” поле
ITrainingField isbnField = trainingBatch.Definition.Fields.AddNew( "ISBN", TrainingFieldTypeEnum.TFT_Field );
page.SetFieldBlock( isbnField, obj.Region );
break;
}
}
for( int j = 0; j < page.ImageObjects.Count; j++ ) {
ITrainingImageObject obj = page.ImageObjects[j];
string text = obj.RecognizedText;
// Пользователь “видит” текст опорного элемента
if( text == "ISBN" ) {
// “Рисует” опорный элемент
ITrainingField isbnTag = trainingBatch.Definition.Fields.AddNew( "ISBNTag", TrainingFieldTypeEnum.TFT_ReferenceText );
page.SetFieldBlock( isbnTag, obj.Region );
break;
}
}
assert( trainingBatch.Definition.Fields.Count == 2 );
}
// Пользователь проверил разметку
trainingBatch.SubmitPageForTraining( page );
// Даём ему следующую на проверку
page = trainingBatch.PrepareNextPageNotSubmittedForTraining();
}
// Экпортируем гибкую разметку. На её основе шаблон создаётся одним вызовом CreateDocumentDefinitionFromAFL
trainingBatch.Definition.ExportToAFL( rootFolder + "\\_TrainingBatch\\NewTemplate.afl" );
} finally {
trainingBatch.Close();
}
В заключение
Кроме описанного из новых фич, интересных разработчикам, у нас теперь есть:
• Продвинутые инструменты предобработки изображений. Среди них продвинутый шумодав и настраиваемый фильтр, работающий в частотной области, наподобие wavelet-ов. Этот фильтр после настройки позволяет значительно улучшить качество работы с фотографиями (лёгкая расфокусировка, шумы).
• API для доступа к вариантам распознавания слов и символов. Это позволяет в некоторых случаях, когда хорошо известна модель извлекаемых данных, программно выбрать вариант наиболее подходящий под эту модель и улучшить качество на выходе. Например, можно осмысленно сравнивать с данными, содержащимися в некоторой БД, или считать контрольную сумму.
• По замечаниям читателей хабра! Приличная поддержка Java – в дистрибутив включён JAR, содержащий структуру объектов и интерфейсов (повторяющий интерфейсы, как они выглядят из .Net), и dll-ку со всеми необходимым JNI-переходниками для вызовов. Для 99% случаев можно использовать прямо “из коробки”. Нет только поддержки callback-ов, которую пользователи могут при сильной необходимости выборочно реализовать сами (мы расскажем как).
Более подробно об ABBYY FlexiCapture Engine вы можете прочитать на сайте ABBYY.
Алексей Калюжный AlekseyKa
Руководитель группы разработки FlexiCapture Engine
