Не так давно, прочитав статью idoroshenko «Почему eval — это не всегда плохо», я задумался, можно ли использовать подход с генерацией тела функции для клонирования объектов. Даже написал небольшую библиотеку для этого. Бенчмарки давали невероятные результаты, но применимость этого подхода ограничивалась лишь множественным клонированием одинаковых объектов.
Поэтому и у меня возник вопрос: неужели в v8 нет другой возможности избежать расходов, связанных со множественным пересозданием скрытых классов? Ведь это составляет основные траты ресурсов, когда мы клонируем объекты. Как оказалось, такая возможность действительно есть: в самом v8 у объектов существует метод v8::Object::Clone. Этот метод клонирует объекты в широком смысле этого слова, то есть собственно объекты, а также массивы, даты, регулярные выражения, функции и т.д., при этом сохраняя все их свойства, в том числе нестандартные (например, именованные свойства массивов) и даже скрытые.
Была только одна маленькая проблема. Этот метод использовался только в недрах node.js, и не был открыт наружу, для javascript'а.
Недолго думая, я полез в документацию node.js по созданию расширений на c++ и написал пробную версию модуля, который просто раскрывает эту функцию.
Получив ускорение для разных объектов примерно в 10-100 раз, я понял, что у этой техники есть большой потенциал, и начал его воплощать в жизнь в модуле node-v8-clone (npm), стараясь этот потенциал не растерять по пути, применяя смесь TDD и benchmark driven development. Это позволило следить за скоростью при разработке и исправлении проблем, а также следить за регрессиями при оптимизациях. Заодно, раз бенчмарки и тесты были готовы, я решил сравнить свой модуль с другими:
Одной из целей было добиться максимального качества клонирования. Пришлось поднапрячь фантазию, чтобы придумать достаточное количество неприятных для процесса клонирования ситуаций. В число таких входят, например, функции, замыкания, arguments, регулярные выражения с текущим состоянием и добавленными пользователем свойствами. Мой модуль с этими ситуациями справляется так:
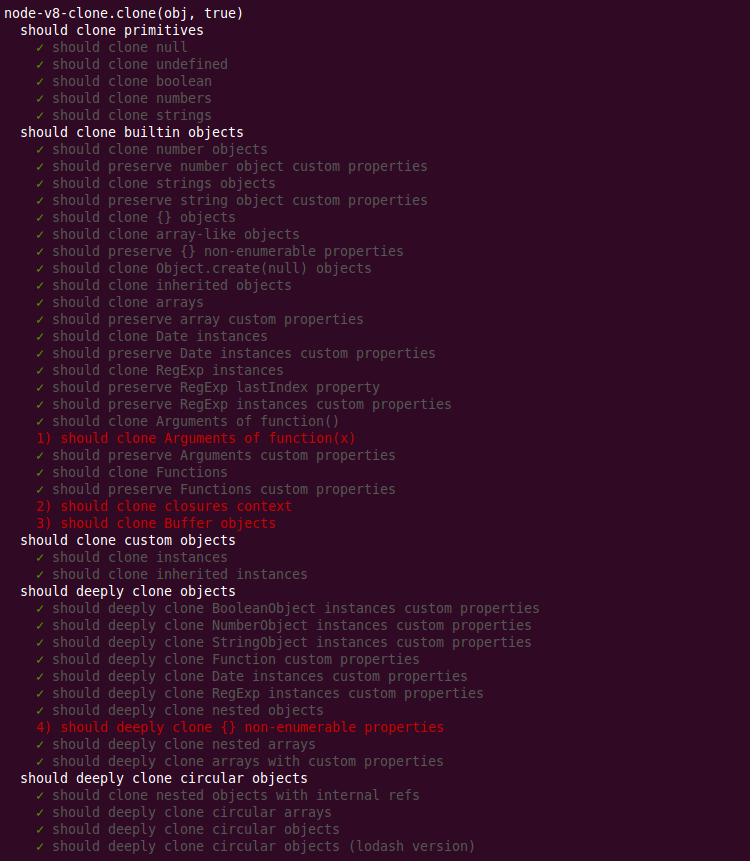
Как обстоят дела у конкурентов, можно оценить здесь.
Мне кажется, получилось очень даже достойно.
Вполне закономерно было бы предположить, что из-за поддержки высокого качества клонирования должна была упасть скорость. И скорость действительно упала, но не настолько, чтобы node-v8-clone потерял первенство в большинстве ситуаций.
Например, вот результаты поверхностного клонирования объекта из 100 элементов
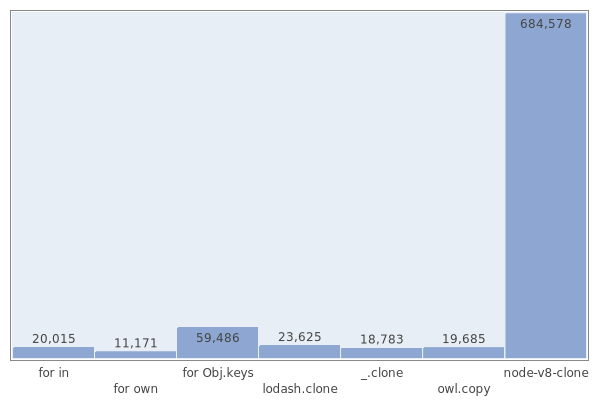
Глубокое клонирование 500 вложенных массивов, расположенных в 4 уровня вложенности, которые содержат 900 строк (тут также сравнивается оптимизированная версия клонирования из node-v8-clone, которая не проходит еще один тест, но существенно ускоряет работу глубоким клонированием массивов):
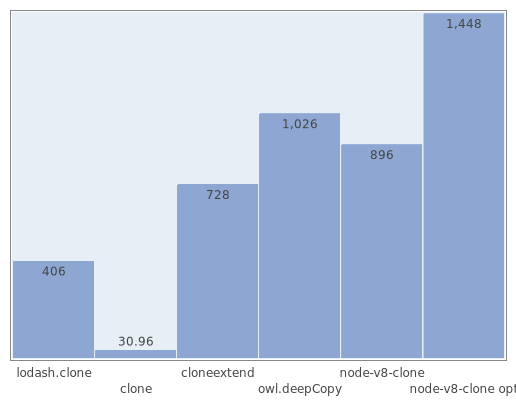
А вот с небольшими массивами дела обстоят несколько хуже. Тут сказывается дороговизна обращения к c++-модулю, так что у простых алгоритмов, таких как for, появляется преимущество.

Все результаты бенчмарков.
Собираюсь починить клонирование node.js-овских буферов. Сейчас они клонируются (a !== b), но указывают на одну и ту же область памяти и содержимое у них оказывается все еще связанным.
Хотелось бы починить клонирование arguments. Когда у функции есть аргументы, объект arguments оказывается связанным с контекстом функции, и при клонировании они тоже оказываются связанными между собой.
Хотелось бы придумать еще больше каверзных входящих данных, например файловые дескрипторы, модули, таймеры… Я не рассчитываю, что у меня получится их по-настоящему клонировать, но как минимум хотелось бы понимать, как будет вести себя с ними этот модуль.
Буду рад любым отзывам, предложеним, багам и патчам. Ну и fork me on GitHub :)
Поэтому и у меня возник вопрос: неужели в v8 нет другой возможности избежать расходов, связанных со множественным пересозданием скрытых классов? Ведь это составляет основные траты ресурсов, когда мы клонируем объекты. Как оказалось, такая возможность действительно есть: в самом v8 у объектов существует метод v8::Object::Clone. Этот метод клонирует объекты в широком смысле этого слова, то есть собственно объекты, а также массивы, даты, регулярные выражения, функции и т.д., при этом сохраняя все их свойства, в том числе нестандартные (например, именованные свойства массивов) и даже скрытые.
Была только одна маленькая проблема. Этот метод использовался только в недрах node.js, и не был открыт наружу, для javascript'а.
Недолго думая, я полез в документацию node.js по созданию расширений на c++ и написал пробную версию модуля, который просто раскрывает эту функцию.
Получив ускорение для разных объектов примерно в 10-100 раз, я понял, что у этой техники есть большой потенциал, и начал его воплощать в жизнь в модуле node-v8-clone (npm), стараясь этот потенциал не растерять по пути, применяя смесь TDD и benchmark driven development. Это позволило следить за скоростью при разработке и исправлении проблем, а также следить за регрессиями при оптимизациях. Заодно, раз бенчмарки и тесты были готовы, я решил сравнить свой модуль с другими:
- lodash (о котором я недавно писал)
- underscore
- owl-deepcopy
- clone
- cloneextend
Качество клонирования
Одной из целей было добиться максимального качества клонирования. Пришлось поднапрячь фантазию, чтобы придумать достаточное количество неприятных для процесса клонирования ситуаций. В число таких входят, например, функции, замыкания, arguments, регулярные выражения с текущим состоянием и добавленными пользователем свойствами. Мой модуль с этими ситуациями справляется так:

Как обстоят дела у конкурентов, можно оценить здесь.
Мне кажется, получилось очень даже достойно.
Скорость
Вполне закономерно было бы предположить, что из-за поддержки высокого качества клонирования должна была упасть скорость. И скорость действительно упала, но не настолько, чтобы node-v8-clone потерял первенство в большинстве ситуаций.
Например, вот результаты поверхностного клонирования объекта из 100 элементов
{'_0': '_0', ..., '_99': '_99'} (в операциях в секунду):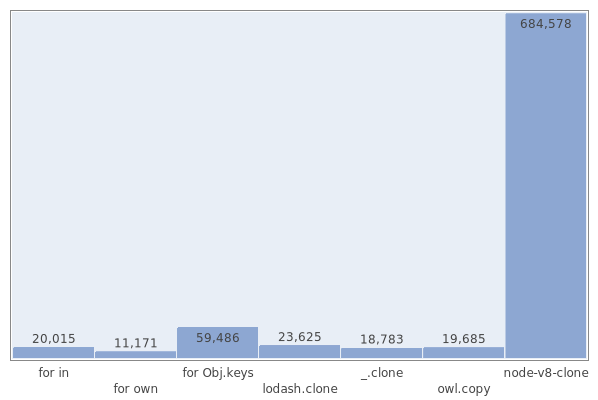
Глубокое клонирование 500 вложенных массивов, расположенных в 4 уровня вложенности, которые содержат 900 строк (тут также сравнивается оптимизированная версия клонирования из node-v8-clone, которая не проходит еще один тест, но существенно ускоряет работу глубоким клонированием массивов):
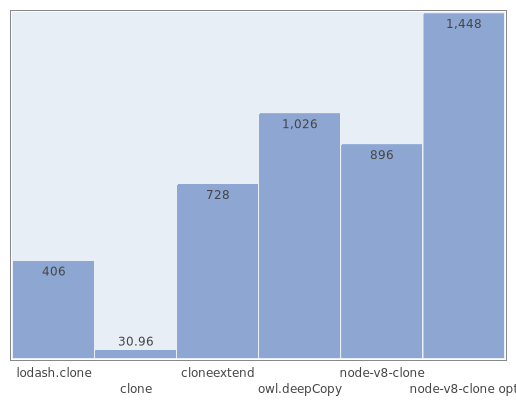
А вот с небольшими массивами дела обстоят несколько хуже. Тут сказывается дороговизна обращения к c++-модулю, так что у простых алгоритмов, таких как for, появляется преимущество.

Все результаты бенчмарков.
Что дальше
Собираюсь починить клонирование node.js-овских буферов. Сейчас они клонируются (a !== b), но указывают на одну и ту же область памяти и содержимое у них оказывается все еще связанным.
Хотелось бы починить клонирование arguments. Когда у функции есть аргументы, объект arguments оказывается связанным с контекстом функции, и при клонировании они тоже оказываются связанными между собой.
Хотелось бы придумать еще больше каверзных входящих данных, например файловые дескрипторы, модули, таймеры… Я не рассчитываю, что у меня получится их по-настоящему клонировать, но как минимум хотелось бы понимать, как будет вести себя с ними этот модуль.
Буду рад любым отзывам, предложеним, багам и патчам. Ну и fork me on GitHub :)
