В комментариях к предыдущему посту про иероглифы сказали, что хорошо бы иметь такую же блок-схему для кракозябр.
Итак, вуаля!
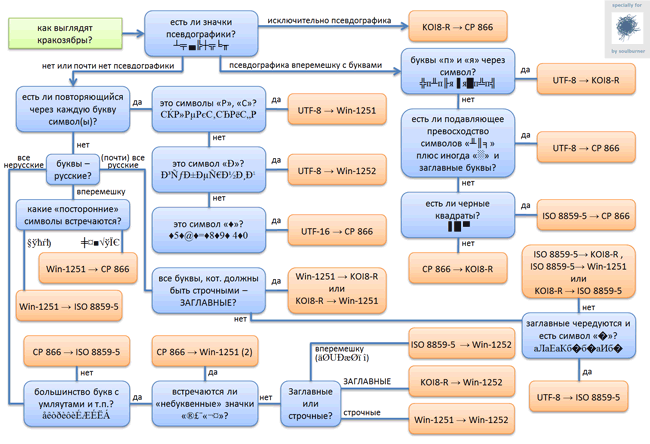
За источник информации была взята статья из вики. В блок-схеме «UTF-16 → CP 866» означает, что исходная кодировка была «UTF-16», а распозналась она как «CP 866».
Как всегда — кликабельно. Исходник в .docx: здесь.
Итак, вуаля!

За источник информации была взята статья из вики. В блок-схеме «UTF-16 → CP 866» означает, что исходная кодировка была «UTF-16», а распозналась она как «CP 866».
Как всегда — кликабельно. Исходник в .docx: здесь.
