Sentiment analysis (по-русски, анализ тональности) — это область компьютерной лингвистики, которая занимается изучением мнений и эмоций в текстовых документах. Недавно на хабре появилась статья про использование машинного обучения для анализа тональности, однако, она была настолько плохо составлена, что я решил написать свою версию. Итак, в этой статье я постараюсь доступно объяснить, что такое анализ тональности, и как реализовать подобную систему для русского языка.
Анализ тональности
Целью анализа тональности является нахождение мнений в тексте и определение их свойств. В зависимости от поставленной задачи нас могут интересовать разные свойства, например:
- автор — кому принадлежит это мнение
- тема — о чем говорится во мнении
- тональность — позиция автора относительно упомянутой темы (обычно «положительная» или «отрицательная»)
Пример: "Главный итог завершившихся Игр ХХХ Олимпиады в Лондоне – то чувство гордости за нашу страну, которое испытывали болельщики благодаря выступлениям российских олимпийцев», — считает Александр Жуков"
автор: Александр Жуков
тема: "выступление российских олимпийцев"
тональность: "положительная"
В литературе встречаются разные способы формализировать модель мнений. Я лишь привел в пример одну из них. Также используется и разная терминология. В английском языке эту область исследования обычно называют opinion mining and sentiment analysis (дословно: «поиск мнений и анализ чувств»). В русских статьях обычно употребляется термин «анализ тональности». Несмотря на то, что тональность является лишь одной из характеристик мнения, именно задача классификации тональности является наиболее часто изучаемой в наши дни. Это можно объяснить несколькими причинами:
- Определение автора и темы является гораздо более трудными задачами чем классификация тональности, поэтому имеет смысл сначала решить более простую задачу, а затем уже переключиться на остальные.
- Во многих случаях нам достаточно лишь определить тональность, т.к. другие характеристики нам уже известны. Например, если мы собираем мнения из блогов, обычно авторами мнений являются авторы постов, т.е. определять автора нам не требуется. Также зачастую нам уже известна тема: например, если мы производим в Твиттере поиск по ключевому слову «Windows 8», то затем нам нужно лишь определить тональность найденных твитов. Конечно же, это работает не во всех случаях, а лишь в большинстве из них. Но эти допущения позволяют в значительной мере упростить и так нелегкую задачу.
Анализ тональности находит свое практическое применение в разных областях:
- социология — собираем данные из соц. сетей (например, о религиозных взглядах)
- политология — собираем данные из блогов о политических взглядах населения
- маркетинг — анализируем Твиттер, чтобы узнать какая модель ноутбуков пользуется наибольшим спросом
- медицина и психология — определяем депрессию у пользователей соц. сетей
Подходы к классификации тональности
Анализ тональности обычно определяют как одну из задач компьютерной лингвистики, т.е. подразумевается, что мы можем найти и классифицировать тональность, используя инструменты обработки естественного языка (такие как теггеры, парсеры и др.). Сделав большое обобщение, можно разделить существующие подходы на следующие категории:

- Подходы, основанные на правилах
- Подходы, основанные на словарях
- Машинное обучение с учителем
- Машинное обучение без учителя
Первый тип систем состоит из набора правил, применяя которые система делает заключение о тональности текста. Например, для предложения «Я люблю кофе», можно применить следующее правило:
если сказуемое ("люблю") входит в положительный набор глаголов ("люблю", "обожаю", "одобряю" ...) и в предложении не имеется отрицаний, то классифицировать тональность как "положительная"
Многие коммерческие системы используют данный подход, несмотря на то что он требует больших затрат, т.к. для хорошей работы системы необходимо составить большое количество правил. Зачастую правила привязаны к определенному домену (например, «ресторанная тематика») и при смене домена («обзор фотоаппаратов») требуется заново составлять правила. Тем не менее, этот подход является наиболее точным при наличии хорошей базы правил, но совершенно неинтересным для исследования.
Подходы, основанные на словарях, используют так называемые тональные словари (affective lexicons) для анализа текста. В простом виде тональный словарь представляет из себя список слов со значением тональности для каждого слова. Вот пример из базы ANEW, переведенный на русский:
| слово | валентность (1-9) |
|---|---|
| счастливый | 8.21 |
| хороший | 7.47 |
| скучный | 2.95 |
| сердитый | 2.85 |
| грустный | 1.61 |
Чтобы проанализировать текст, можно воспользоваться следующим алгоритмом: сначала каждому слову в тексте присвоить его значением тональности из словаря (если оно присутствует в словаре), а затем вычислить общую тональность всего текста. Вычислять общую тональность можно разными способами. Самый простой из них — среднее арифметическое всех значений. Более сложный — обучить классификатор (напр. нейронная сеть).
Машинное обучение с учителем является наиболее распространенным методом, используемым в исследованиях. Его суть состоит в том, чтобы обучить машинный классификатор на коллекции заранее размеченных текстах, а затем использовать полученную модель для анализа новых документов. Именно про этот метод я расскажу далее.
Машинное обучение без учителя представляет собой, наверное, наиболее интересный и в то же время наименее точный метод анализа тональности. Одним из примеров данного метода может быть автоматическая кластеризация документов.
Машинное обучение с учителем
Процесс создания системы анализа тональности очень похож на процесс создания других систем с применением машинного обучения:
- необходимо собрать коллекцию документов для обучения классификатора
- каждый документ из обучающей коллекции нужно представить в виде вектора признаков
- для каждого документа нужно указать «правильный ответ», т.е. тип тональности (например, положительная или отрицательная), по этим ответам и будет обучаться классификатор
- выбор алгоритма классификации и обучение классификатора
- использование полученной модели
Количество классов
Количество классов, на которые делят тональность, обычно задается из спецификации системы. Например, заказчику требуется, чтобы система различала три вида тональности: «положительная», «нейтральная», «отрицательная». В исследованиях обычно рассматривается задача бинарной классификации тональности, т.е. классов всего два: «положительный» и «отрицательный». Из своего опыта могу сказать, что классификация тональности на более чем два класса — это очень сложная задача. Даже с тремя классами очень сложно достичь хорошей точности независимо от применяемого подхода.
Если стоит задача классификации на более чем два класса, то тут возможны следующие варианты для обучения классификатора:
- Плоская классификация — обучаем лишь один классификатор для всех классов

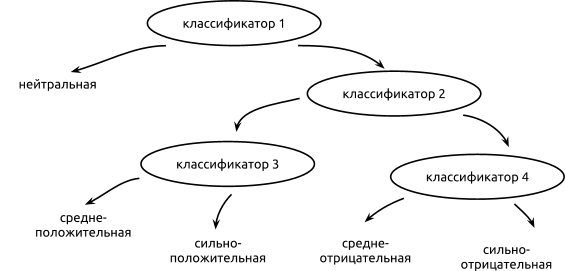
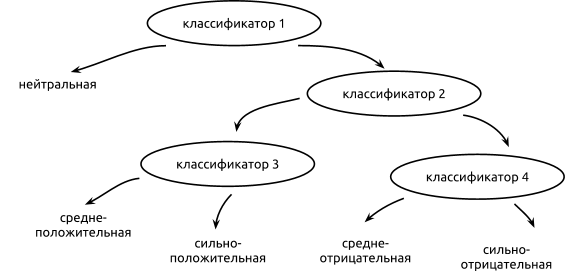
- Иерархическая классификация — делим классы на группы и обучаем несколько классификаторов для определения групп. Например, если у нас 5 классов («сильно положительный», «средне положительный», «нейтральный», «средне отрицательный», «сильно отрицательный»), то можно сначала обучить бинарный классификатор, который отделяет нейтральные тексты от субъективных; затем обучить классификатор, который отделяет положительные мнения от отрицательных; и в итоге классификатор, который отделяет сильно выраженные мнения от средних.
- Регрессия — обучаем классификатор для получения численного значения тональности, например от 1 до 10, где большее значение означает более положительную тональность.

Обычно иерархическая классификация дает лучшие результаты чем плоская, т.к. для каждого классификатора можно найти набор признаков, который позволяет улучшить результаты. Однако, он требует больших времени и усилий для обучения и тестирования. Регрессия может показать лучшие результаты, если классов действительно много (от 5 и более).
Выбор признаков
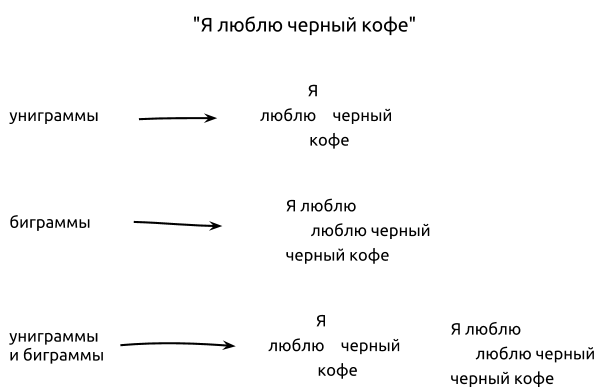
Качество результатов напрямую зависят от того, как мы представим документ для классификатора, а именно, какой набор характеристик мы будем использовать для составления вектора признаков. Наиболее распространенный способ представления документа в задачах комп. лингвистики и поиска — это либо в виде набора слов (bag-of-words) либо в виде набора N-грамм. Так, например, предложение «Я люблю черный кофе» можно представить в виде набора униграмм (Я, люблю, черный, кофе) или биграмм (Я люблю, люблю черный, черный кофе).
Обычно униграммы и биграммы дают лучшие результаты чем N-граммы более высоких порядков (триграммы и выше), т.к. выборка обучения в большинстве случаев недостаточна большая для подсчета N-грамм высших порядков. Всегда имеет смысл протестировать результаты с применением униграмм, биграмм и их комбинации (Я, люблю, черный, кофе, Я люблю, люблю черный, черный кофе). В зависимости от типа данных униграммы могут показать лучшие результаты чем биграммы, а могут и наоборот. Также иногда комбинация униграммов и биграммов позволяет улучшить результаты.
Стемминг и лемматизация
В некоторых исследованиях при представлении текста все слова проходят через процедуру стемминга (удаление окончания) либо лемматизации (приведение к начальной форме). Цель этой процедуры — уменьшение размерности задачи, иными словами — если в тексте встречаются одинаковые слова, но с разными окончаниями, при помощи стемминга и лемматизации можно их привести к одному виду. Однако, на практике это обычно не дает никаких ощутимых результатов. Причина этому в том, что, избавляясь от окончаний слов, мы теряем морфологическую информацию, которая может быть полезна для анализа тональности. Например, слова «хочу» и «хотел» имеют разную тональность. Если в первом случае тональность скорее всего положительная, т.к. автор может выражать надежду и положительные эмоции, то у глагола в прошлом времени, тональность может быть отрицательной, если автор выражает сожаление.
Другой способ представления текста — символьные N-граммы. Текст из примера можно представить в виде следующих 4-символьных N-грамм: «я лю», " люб", «юблю», «блю », и т.д. Несмотря на то, что такой способ может показаться слишком примитивным, т.к. на первый взгляд набор символов не несет в себе никакой семантики, тем не менее этот метод иногда дает результаты даже лучше чем N-граммы слов. Если присмотреться, то можно увидеть, что N-граммы символов соответствуют в какой-то мере морфемам слов, а в частности корень слова («люб») несет в себе его смысл. Символьные N-граммы могут быть полезны в двух случаях:
- при наличии орфографических ошибок в тексте — набор символов у текста с ошибками и набор символов у текста без ошибок будет практически одинаков в отличие от слов.
- для языков с богатой морфологией (например, для русского) — в текстах могут встречаться одинаковые слова, но в разных вариациях (разные род или число), но при этом корень слов неизменяется, а следовательно и общий набор символов.
Символьные N-граммы применяются гораздо реже чем N-граммы слов, но иногда они могут улучшить результаты.
Также можно использовать дополнительные признаки, такие как: части речи, пунктуация (наличие в тексте смайлов, восклицательных знаков), наличие в тексте отрицаний («не», «нет», «никогда»), междометий и т.д.
Взвешенный вектор
Следующим шагом в составлении вектора признаков является присваивание каждому признаку его вес. Для некоторых классификаторов это является необязательным, например, для байесовского классификатора, т.к. он сам высчитывает вероятность для признаков. Но если вы используете метод опорных векторов, то задание весов может заметно улучшить результаты.
В информационном поиске наиболее распространенным методом оценки веса признаков является TF-IDF. Для анализа тональности этот метод не дает хороших результатов. Причиной этому является то, что для анализа тональности не настолько важны слова, которые часто повторяются в тексте (т.е. слова с высоким TF), в отличие от задачи поиска. Поэтому обычно используют бинарный вес, т.е., признакам (если используем униграммы, то словам) присваивается единичный вес, если те присутствуют в тексте. В противном случае вес равен нулю. Например, «я люблю черный кофе» будет представлен в виде следующего вектора (мы опускаем слова с весом = 0):
{"я": 1, "люблю": 1, "черный": 1, "кофе": 1}
Однако, существуют методы оценки важности слов, которые вычисляют веса слов, дающие гораздо лучшие результаты при классификации тональности, например, дельта TF-IDF.
Дельта TF-IDF
Идея метода дельта TF-IDF заключается в том, чтобы дать больший вес для слов, которые имеют не-нейтральную тональность, т.к. именно такие слова определяют тональность всего текста. Формула для расчета веса слова w следующая:
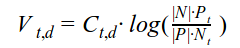
где:
Что же в итоге получается? Допустим, мы работаем с коллекцией отзывов фильмов. Рассмотрим три слова: «отличный», «нудный», «сценарий». Самое главное в формуле дельта TF-IDF — это второй множитель log(...). Именно он будет разный у этих трех слов:
В итоге вес слов с положительной тональностью будет большим положительным числом, вес слов с отрицательной тональностью будет отрицательным числом, вес нейтральных слов будет близок к нулю. Такое взвешивание вектора признаков в большинстве случаев позволяет улучшить точность классификации тональности.

где:
- Vt,d — вес слова t в документе d
- Сt,d — кол-во раз слово t встречается в документе d
- |P| — кол-во документов с положительной тональностью
- |N| — кол-во документов с отрицательной тональностью
- Pt — кол-во положительных документов, где встречается слово t
- Nt — кол-во отрицательных документов, где встречается слово t
Что же в итоге получается? Допустим, мы работаем с коллекцией отзывов фильмов. Рассмотрим три слова: «отличный», «нудный», «сценарий». Самое главное в формуле дельта TF-IDF — это второй множитель log(...). Именно он будет разный у этих трех слов:
- Слово «отличный» скорее всего встречается в большинстве положительных (Pt) отзывов и почти не встречается в отрицательных (Nt), в итоге вес будет большим положительным числом, т.к. отношение Pt/Nt будет числом гораздо больше 1.
- Слово «нудный» наоборот встречается в основном в отрицательных отзывах, поэтому отношение Pt/Nt будет меньше единицы и в итоге логарифм будет отрицательным. В итоге вес слова будет отрицательным числом, но большим по модулю.
- Слово «сценарий» может встречаться с одинаковой вероятностью и в положительных, так и в отрицательных отзывах, поэтому отношение Pt/Nt будет очень близко к единице, и в итоге логарифм будет близок к нулю. Вес слова будет практически равен нулю.
В итоге вес слов с положительной тональностью будет большим положительным числом, вес слов с отрицательной тональностью будет отрицательным числом, вес нейтральных слов будет близок к нулю. Такое взвешивание вектора признаков в большинстве случаев позволяет улучшить точность классификации тональности.
Реализация классификатора
Я реализовал простой классификатор тональности отзывов о фильмах на питоне. Данные были собраны с Кинопоиска. Было отобрано 500 положительных и 500 отрицательных отзывов. В качестве алгоритма классификации я использовал наивный байесовский классификатор (NB) и метод опорных векторов (SVM). В качестве признаков я протестировал униграммы, биграммы и их комбинацию, а в качестве функции взвешивания: бинарная функция для байеса и SVM, и дельта TF-IDF для SVM. Для оценки работы классификатора я провел перекрестную проверку: для каждого набора параметров было запущено подряд 5 тестов, в каждом из которых использовалось 800 отзывов для обучения и 200 для тестирования. Ниже представлены результаты (точность в процентах) для всех 9-ти наборов параметров.
| Признаки | NB | SVM | SVM+delta |
|---|---|---|---|
| униграммы | 85.5 | 82.5 | 86.2 |
| биграммы | 84.9 | 86.5 | 87.8 |
| комбинация | 86.5 | 88.4 | 90.8 |

Из результатов видно, что для данной коллекции лучшие результаты показывает метод опорных векторов с функцией взвешивания дельта TF-IDF. Если же использовать обычную бинарную функцию, то оба классификатора (NB и SVM) показывают примерно одинаковые результаты. Комбинация униграммов и биграммов дает лучше результаты во всех тестах.
Посмотрим, почему же дельта TF-IDF дает такой отрыв (2.4 — 4.3%) в результатах. Выберем N-граммы с максимальными по модулю значениями дельта TF-IDF:
| потрясающий | 5.20 | ведут себя | -5.02 |
| зависит | 5.08 | зачем-то | -4.80 |
| принимает | 4.95 | не смогли | -4.80 |
| создают | 4.80 | ни о | -4.71 |
| работами | 4.80 | не впечатлил | -4.71 |
| тщательно | 4.71 | сексом | -4.71 |
| самого себя | 4.71 | хуже чем | -4.71 |
| ким | 4.62 | но этого | -4.71 |
| триллеров | 4.62 | был снят | -4.62 |
| для нее | 4.51 | не смотрите | -4.62 |
На примере негативных N-граммов особо заметно, что их вес отражает негативную тональность.
Практическое применение
В качестве примера практического применения классификатора тональности, я реализовал на скорую руку классификатор твитов, схема работа которой следующая:
- производим поиск в Твиттере по названию фильмов
- пропускаем твиты через классификатор тональности
- получаем положительные и отрицательные высказывания о фильмах из Твиттера
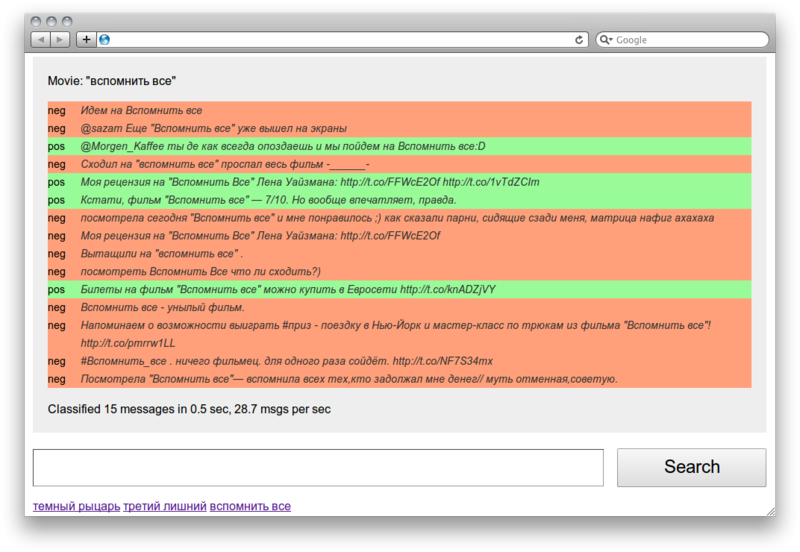
Пример работы анализатора:
alexpak@dard:~/projects/pyrus$ src/sentiment/test.py "марсупилами"
1. pos Скачат фильм Джунгли зовут! В поисках Марсупилами / Sur la piste du Marsupilami (2012) DVDRip http://t.co/to5EuTHL
2. neg Вот советую посмотреть эту комедию Джунгли зовут! В поисках Марсупилами (2012)!
3. pos мы ходили на фильм "джунгли зовут!в поисках марсупилами" мне понравилось
4. pos Джунгли зовут! В поисках Марсупилами. Приятного просмотра:)
5. pos Джунгли зовут! В поисках Марсупилами - Sur la piste du Marsupilami (2012) HDRip http://t.co/UB1hwnHh
6. pos Марсупилами, както так называется фильм. Норм такой, на один раз)
7. pos такой лапочка #марсупилами
8. pos Went to the movies) watched the movie "Джунгли зовут! В поисках Марсупилами." http://t.co/EBlIsWMs
9. neg идём с брателло на Марсупилами)
10. neg Как можно было снять такой отвратный фильм про Марсупилами?! Он такой няша
11. pos Джунгли зовут! В поисках Марсупилами / Sur la piste du Marsupilami (2012) http://t.co/OoH3chso
12. pos Джунгли зовут! В поисках Марсупилами http://t.co/rb1BWurX
13. pos Джунгли зовут! В поисках Марсупилами http://t.co/rHorvtvu
14. pos Джунгли зовут! В поисках Марсупилами http://t.co/xNBHadIN
15. pos Джунгли зовут! В поисках Марсупилами http://t.co/33t35O35
Как видно, результаты не особо удовлетворительные. Классификатор делает 2 типа ошибок:
- Классифицирует нейтральные твиты (описание фильма, новости, спам) как положительные/отрицательные
- Неправильно классифицирует тональность отзывов
Первый тип ошибок можно исправить, если добавить дополнительный классификатор, который будет фильтровать нейтральные твиты. Это непростая задача, но вполне осуществимая. Второй тип ошибок возникает в основном из-за того, что твиты сильно отличаются от коллекции обучения: присутствует сленг, орфографические ошибки, отличается манера высказывания. Тут надо либо искать другую коллекцию для обучения классификатора (взять те же твиты, например), либо улучшить набор признаков (например, добавить смайлы). Но в целом, этот пример показывает, что создать систему анализа мнений в Твиттере вполне возможно.
Заключение
Создание системы анализа мнений является сложной задачей, но вполне посильной, если имеются данные для обучения и заранее определен домен (тема). При использовании машинного обучения важно тестировать разные параметры, чтобы подобрать те, которые работают лучше на тестовых данных. В частности нужно тестировать разные алгоритмы классификации (NB, SVM), набор признаков (униграммы, биграммы, символьные N-граммы), функцию взвешивания признаков. Существует еще куча способов для улучшения классификации тональности, такие как использование тональных словарей, дополнительные лингвистические признаки (например, части речи), так и общие способы улучшение машинного обучения (бустинг, баггинг и др.). В этой статье я постарался описать лишь основные методы.
Как всегда буду рад критике, вопросам и пожеланиям.
Исходный код
Онлайн демо
FAQ:
В демо неправильно классифицируются отзывы!
— да, это всего лишь прототип написанный за день
А что если в тексте присутствует и положительный, и отрицательный отзыв?
— текущий алгоритм классифицирует только один из них
А если я специально напишу негативный отзыв положительными словами?
— он будет неправильно классифицирован (а что вы ожидали от компьютера?)
