 Тема префиксных деревьев поиска уже неколько раз поднималась на хабре. Здесь, например, кратко описывается, что такое префиксное дерево и зачем оно нужно, и рассматриваются основные операции над такими деревьями (поиск, вставка, удаление). К сожалению, ничего при этом не говорится про реализацию. В этом недавнем посте рассматривается «питонья библиотека datrie», являющаяся Cython-оберткой библиотеки libdatrie. По последней ссылке имеется хорошее описание реализации частично сжатых префиксных деревьев в виде детерминированных конечных автоматов (с использованием массивов). Я решил внести свои пять копеек в эту тему, рассмотрев реализацию на языке С++ префиксных деревьев с помощью указателей. Кроме того, была и еще одна цель — сравнить между собой поиск строк с помощью сбалансированного двоичного дерева поиска (АВЛ-дерево) и сжатого префиксного дерева.
Тема префиксных деревьев поиска уже неколько раз поднималась на хабре. Здесь, например, кратко описывается, что такое префиксное дерево и зачем оно нужно, и рассматриваются основные операции над такими деревьями (поиск, вставка, удаление). К сожалению, ничего при этом не говорится про реализацию. В этом недавнем посте рассматривается «питонья библиотека datrie», являющаяся Cython-оберткой библиотеки libdatrie. По последней ссылке имеется хорошее описание реализации частично сжатых префиксных деревьев в виде детерминированных конечных автоматов (с использованием массивов). Я решил внести свои пять копеек в эту тему, рассмотрев реализацию на языке С++ префиксных деревьев с помощью указателей. Кроме того, была и еще одна цель — сравнить между собой поиск строк с помощью сбалансированного двоичного дерева поиска (АВЛ-дерево) и сжатого префиксного дерева. Введение
Напомним, что префиксное дерево — это структура данных, предназначенная для хранения объектов с поразрядной структурой, например, строк. Далее мы будем рассматривать реализацию префиксных деревьев для хранения именно строк в алфавите ASCII, каждая строка заканчивается терминальным символом, который больше нигде в строке не встречается. На рисунках и в примерах терминальный символ будем обозначать знаком доллара, а в коде — нулевым символом (таким образом, в нашей реализации строки будут стандартными C-строками, что позволит использовать нам стандартную бибилиотеку string.h). На другие алфавиты все нижеизложенное должно переноситься элементарно.
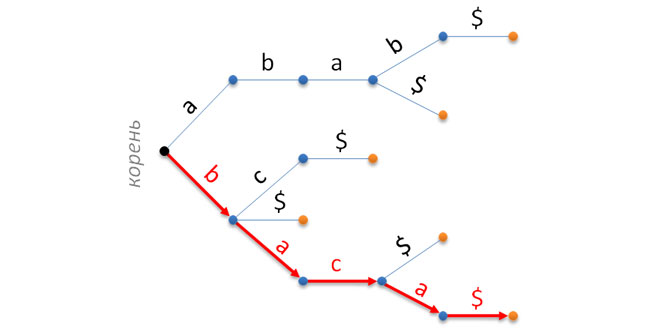
В обычном префиксном дереве каждому ребру приписан некоторый символ, в вершинах же хранится различная служебная (или пользовательская) информация. Таким образом, любой путь от корня дерева до некоторого его листа определяет ровно одну строку. Считается, что эта строка хранится в заданном дереве. Например, на следующем рисунке префиксное дерево хранит следующий набор строк {abab$, aba$, bc$, b$, bac$, baca$}. Корень слева, листья (их число совпадает с числом строк) — справа. Путь, соответствующий строке baca$, выделен красным цветом.
Внимательный читатель без труда заметит, что в таком варианте префиксное дерево представляет собой обычный детерминированный конечный автомат, принимающие состояния которого соответствуют листьям дерева. Собственно, на этом соображении и строится реализация префиксных деревьев в библиотеке libdatrie. Сам автомат при этом представляется с помощью массивов.
Для сокращения размера автомата используется представление дерева в частично сжатой форме, когда все «хвосты» дерева (участки без ветвлений, содержащие листья) упаковываются в строки (рисунок а ниже). Можно пойти дальше, и сжать аналогичным образом вообще все цепочки без ветвлений (рисунок б). В этом случае дерево перестает быть конечным автоматом (вернее, оно остается автоматом, но над алфавитом строк, а не символов) и его реализация с помощью массивов становится проблематичной — работа с деревом, как с автоматом, существенно опирается на то, что размер алфавита является конечным и, что по любому символу можно за O(1) времени определить его порядковый номер в этом алфавите (со строками такой прием не сработает). Однако, в случае реализации указателями проблем с хранением строк возникать не должно.

Представление дерева с помощью указателей
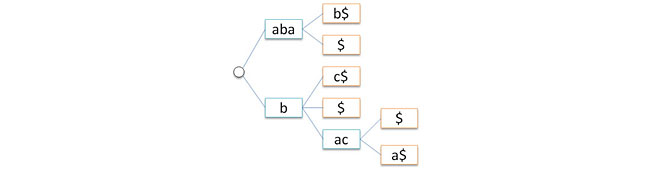
Итак, будем представлять ребра дерева указателями. Прежде всего заметим, что в этом случае хранить информацию в ребрах дерева, мягко говоря, оказывается не очень удобным. Поэтому перенесем цепочки символов с ребер в вершины (воспользовавшись очевидным свойством ориентированого дерева — в любой узел, кроме корневого, входит ровно ребро). Получим вот такую структуру.
Еще одна проблема — исходящая степень узла дерева может быть произвольной (вплоть до размера используемого алфавита). Для решения этой проблемы применим стандартный прием, а именно, будем хранить в каждом узле список дочерних узлов. Список будет односвязным и хранить в узле мы будем только голову списка (старшая дочь). Это позволит нам заодно отказаться от пустого корня. Теперь дерево будет представляться указателем на голову списка дочерних узлов старого корня (т.е. мы заменяем дерево на лес). Таким образом, каждый узел теперь будет содержать ровно два указателя: link — на старший дочерний узел, next — на свою младшую сестру. На следующем рисунке показан процесс такой трансформации, синие стрелки соответствуют указателям link, красные — указателям next.
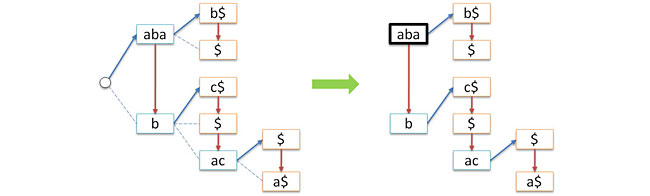
В дальнейшем, для понимания логики работы с деревом полезно в уме держать схему, показанную на рисунке слева, в то время, как реальное представление дерева будет таким, как показано справа.
Вот так, незаметно, мы перешли от дерева с переменной исходящей степенью (дерево общего вида) к двоичному дереву, в котором роль указателей на правое и левое поддеревья играют указатели link и next. Следующая картинка наглядно это демонстрирует.
Теперь можно перейти и к реализации. Узел дерева — это цепочка символов key, ее длина len (цепочка не обязана заканчиваться терминальным символов, поэтому нужно явно знать ее длину), и два указателя link и next. Плюс минимальный конструктор, который создает тривиальное дерево, состоящее из одного узла с заданным ключом (для копирования символов будем использовать стандартную функцию strncpy), и еще более минимальный деструктор.
struct node // структура для представления узлов дерева
{
char* key;
int len;
node* link;
node* next;
node(char* x, int n) : len(n), link(0), next(0)
{
key = new char[n];
strncpy(key,x,n);
}
~node() { delete[] key; }
};
Поиск ключей
Первая операция, которую мы рассмотрим — это операция вставки новой строки в префиксное дерево. Идея поиска стандартная. Движемся от корня дерева. Если корень пустой, то поиск неудачный. Иначе, сравниваем ключ key в узле с текущей строкой x. Для этого воспользуемся следующей функцией, которая вычисляет длину наибольшего общего префикса двух строк заданной длины.
int prefix(char* x, int n, char* key, int m) // длина наибольшего общего префикса строк x и key
{
for( int k=0; k<n; k++ )
if( k==m || x[k]!=key[k] )
return k;
return n;
}
В случае поиска нас интересуют три случая:
- общий префикс может быть пустым, тогда надо рекурсивно продолжить поиск в младшей сестре данного узла, т.е. перейти по ссылке next;
- общий префикс равен искомой строке x — поиск успешный, узел найден (тут мы существенно используем тот факт, что конец строки за счет наличия в нем терминального символа может быть найден только в листе дерева);
- общий префикс совпадает с ключом, но не совпадает с x — переходим рекурсивно по ссылке link к старшему дочернему узлу, передавая ему для поиска строку x без найденного префикса.
Если общий префикс есть, но не совпадает с ключом, то поиск также является неудачным.
node* find(node* t, char* x, int n=0) // поиск ключа x в дереве t
{
if( !n ) n = strlen(x)+1;
if( !t ) return 0;
int k = prefix(x,n,t->key,t->len);
if( k==0 ) return find(t->next,x,n); // поищем у сестры
if( k==n ) return t;
if( k==t->len ) return find(t->link,x+k,n-k); // поищем у старшей дочери
return 0;
}
Длина n строки x по умолчанию равна нулю (и тогда она явно вычисляется), чтобы можно было вызывать функцию поиска, указывая только корень дерева и строку для поиска:
...
node* p = find(t,"baca");
...
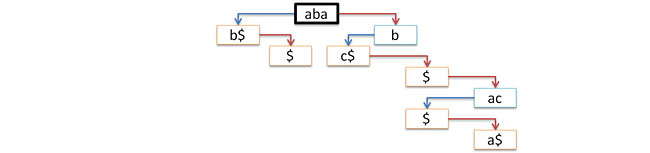
На следующем рисунке показан процесс поиска трех строк (один успешный и два не очень) в вышеприведенном дереве.
Заметим, что функция поиска в случае успеха возвращает указатель на лист дерева, где закончился поиск. Именно в этом узле должна располагаться вся информация, связанная с искомой строкой.
Вставка ключей
Вставка нового ключа (как и в двоичных деревьях поиска) очень похожа на поиск ключа. Естественно с несколькими отличиями. Во-первых, в случае пустого дерева нужно создать узел (тривиальное дерево) с заданным ключом и вернуть указатель на этот узел. Во-вторых, если длина общего префикса текущего ключа и текущей строки x больше нуля, но меньше длины ключа (второй случай недачного поиска), то надо разбить текущий узел на два, оставив в родительском узле найденный префикс, и поместив в дочерний узел p оставшуюся часть ключа. Эта операция реализуется функцией split. После разделения нужно продолжить процесс вставки в узле p строки x без найденного префикса.

Код разделения узла:
void split(node* t, int k) // разбиение узла t по k-му символу ключа
{
node* p = new node(t->key+k,t->len-k);
p->link = t->link;
t->link = p;
char* a = new char[k];
strncpy(a,t->key,k);
delete[] t->key;
t->key = a;
t->len = k;
}
Код вставки:
node* insert(node* t, char* x, int n=0) // вставка ключа x в дерево t
{
if( !n ) n = strlen(x)+1;
if( !t ) return new node(x,n);
int k = prefix(x,n,t->key,t->len);
if( k==0 ) t->next = insert(t->next,x,n);
else if( k<n )
{
if( k<t->len ) // режем или нет?
split(t,k);
t->link = insert(t->link,x+k,n-k);
}
return t;
}
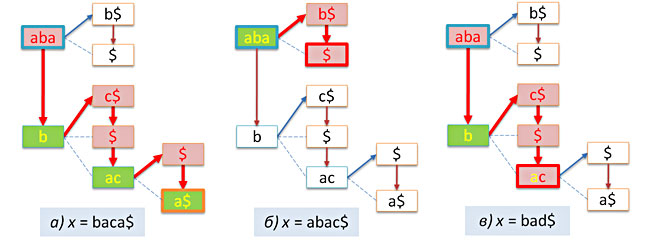
Пример вставки ключей abaca$ и abcd$ в вышерасмотренное дерево приведен на следующем рисунке.
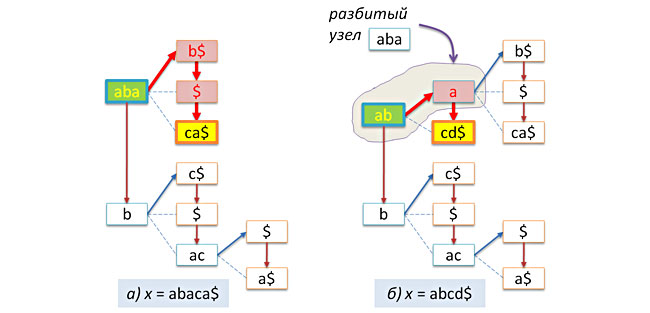
Заметим, что в случае, если заданная строка x уже содержится в дереве, то никакой вставки сделано не будет. С этой точки зрения префиксное дерево ведет себя как добропорядочное множество.
Удаление ключей
Как обычно, удаление ключа — самая сложная операция. Хотя в случае префиксного дерева все выглядит не столь страшно. Дело в том, что при удалении ключа удаляется всего один листовой узел, соответствующий суффиксу некоторому удаляемого ключа. Сначала мы находим этот узел, если поиск успешный, то мы его удаляем и возвращаем указатель на младшую сестру данного узла (дочерей у него нет, он лист, а вот сестры могут быть).
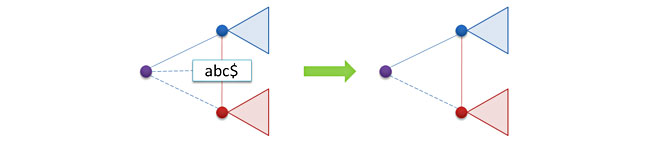
В принципе, на этом процесс удаления можно было бы и закончить, однако возникает небольшая проблема — после удаления узла в дереве может образоваться цепочка из двух узлов t и p, в которой у первого узла t имеется единственный дочерний узел p. Следовательно, если мы хотим держать дерево в сжатой форме, то нужно соединить эти два узла в один, произведя операцию слияния.

Код функции слияния достаточно тривиальный — образуем новый ключ, переподвешиваем поддерево узла p к узлу t, удаляем узел p:
void join(node* t) // слияние узлов t и t->link
{
node* p = t->link;
char* a = new char[t->len+p->len];
strncpy(a,t->key,t->len);
strncpy(a+t->len,p->key,p->len);
delete[] t->key;
t->key = a;
t->len += p->len;
t->link = p->link;
delete p;
}
За слияние отвечает старший узел, потому что у младшего нет информации о своем родителе. Критериями проведения слияния является 1) удаление ключа по ссылке link, а не по next; 2) после удаления у новой ссылки link нет ссылки next (дочерний узел всего один, значит его можно слить с текущим).
node* remove(node* t, char* x, int n=0) // удаление ключа x из дерева t
{
if( !n ) n = strlen(x)+1;
if( !t ) return 0;
int k = prefix(x,n,t->key,t->len);
if( k==n ) // удаление листа
{
znode* p = t->next;
delete t;
return p;
}
if( k==0 ) t->next = remove(t->next, x, n);
else if( k==t->len )
{
t->link = remove(t->link, x+k, n-k);
if( t->link && !t->link->next ) // у узла t имеется единственная дочь?
join(t);
}
return t;
}
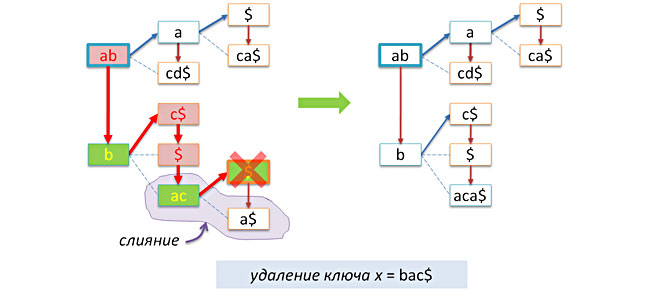
Примеры удаления ключей без слияния:

и со слиянием:
Эффективность
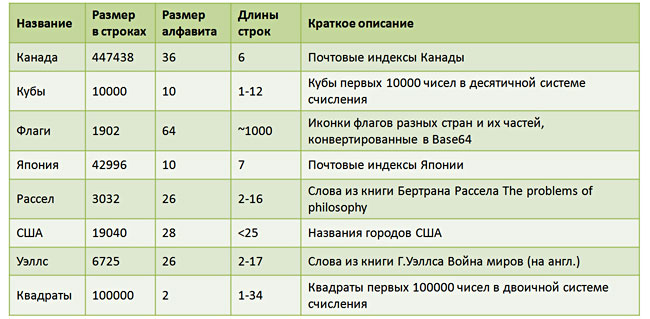
Было проведено небольшое численное исследование по сравнению АВЛ-деревьев и префиксных деревьев по времени работы и потребляемой памяти. Результаты получились для меня несколько обескураживающими (возможно, сказалась кривизна чьих-то рук). Но по порядку… Для тестирования было сформировано 8 тестовых набор строк. Их краткие характеристики перечислены в таблице.
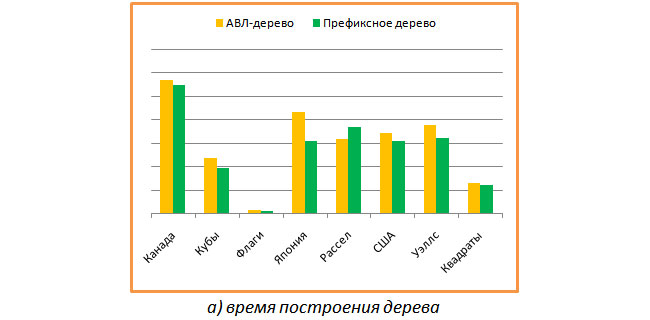
Прежде всего измерялось время построения дерева по заданному набору строк и время на поиск в нем всех ключей из этого же набора (т.е. только успешный поиск). На следующем графике показано сравнение времени построения АВЛ-дерева и префиксного дерева. Видно, что префиксное дерево строится чуть-чуть быстрее.
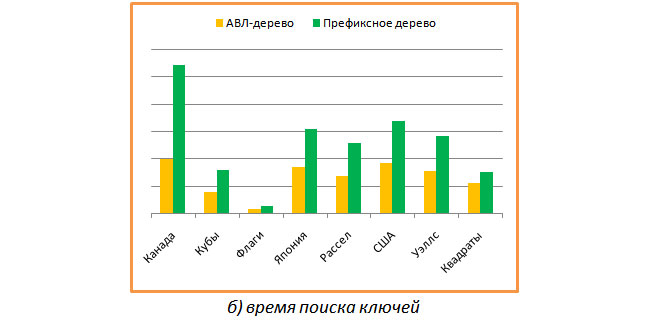
На следующем графике показано сравнение времени, затрачиваемое на поиск всех имеющихся ключей для тех же двух деревьев. И вот здесь все оказалось не так, как задумывалось. Сбалансированное двоичное дерево тратит на поиск в среднем примерно в два раза меньше времени, чем префиксное.
Наконец, интересно было посмотреть, каковы затраты памяти, приходящиеся на один символ. Результаты приведены на следующем графике.
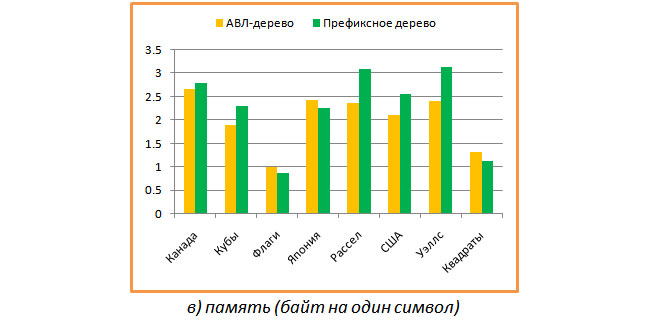
В среднем для обоих типов деревьев получается около 2-х байт на один символ, что на мой взгляд не очень плохо. Интересно, что в случае флагов, префиксное дерево тратит на один символ меньше одного байта (много общих длинных префиксов).
Так что, однозначного победителя в результате выявлено не было. Следовало бы провести сравнение времени работы этих двух деревьев относительно количества строк, но судя по вышеприведенным графикам ничего революционного ожидать все равно не приходится. И, конечно, интересно было бы сравнить эти два похода с хеш-таблицами…
Спасибо за внимание!
Буду благодарен за комментарии и замечания!
