 В связи с дельной критикой хабрахабровцев, я кардинально переделал пост. Надеюсь, такой вариант будет оценен более положительно.
В связи с дельной критикой хабрахабровцев, я кардинально переделал пост. Надеюсь, такой вариант будет оценен более положительно. Я почти два года работаю в компании, которая занимается оцифровкой архивных и библиотечных фондов. Сканирование информации у нас поставлено на поток и в сутки мы получаем десятки тысяч графических образов, которые необходимо распознать и выгрузить заказчику. Моя задача состоит в создании конвейерной технологии для распознавания информации с графических образов.
В этом посте я хочу поделиться полученным опытом и рассказать о технологии распознавания рукописного текста.
Тестирование автоматического распознавания
Печатный текст
ABBYY FineReader является безоговорочным лидером в данном сегменте. Программы распознавания разрабатываются с уклоном на стандартную документацию компаний, которые является основными потребителями софта. Они не рассчитаны на нестандартные форматы, поэтому программы не могут дать уровень достоверности выше 80%.
При обработке библиотечных карточек десяти-двадцатилетней давности, ABBYY FineReader не может дать результат выше 60% достоверности. Смотрите скриншот ниже.
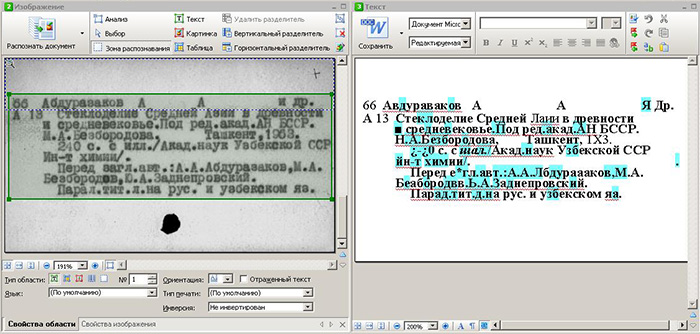
Рукописный текст
У ABBYY FineReader есть версии программы, где, после обучения, она должна распознавать текст. Суть проста – продукт представляет собой пустую нейронную сеть. Пользователю необходимо ее наполнить вручную. Если пользователь пытается распознать несколько почерков, программа не сможет выдать результат. Потратив неделю времени на обучение такого программного решения, в итоге, мы не получили положительный результат.
Применение автоматизированных программ для распознавания рукописного текста на сегодняшний день почти невозможно. Ввод оператором информации с графического образа является единственным способом получения оцифрованной информации. Смотрите скриншот ниже.
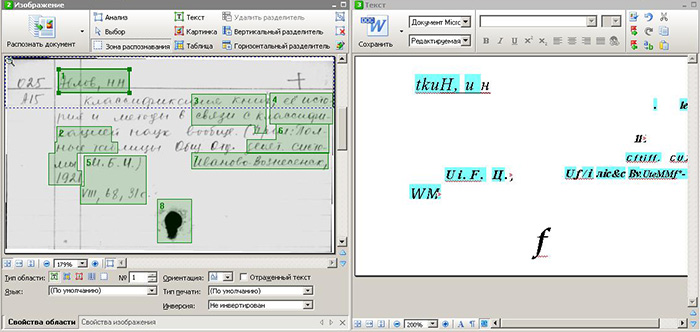
Создание технологии ручного распознавания
Далее пойдет речь о технологии, которую необходимо было создать. Был алгоритм, на реализацию которого ушло полгода. Ниже приведен порядок действий для получения распознанного текста:
- Сканирование – потоковый сканер выполняет сам.
- Разделение массива графических образов по признаку на подкатегории — это и все дальнейшие этапы выполняет человек. Этот этап позволяет повысить КПД ввода.
- Проверка работы сделанной на предыдущем этапе.
- Ввод данных. Вся информация логически разделяется на поля и заполняется частями. Каждый массив данных имеет свою специфику и свои правила ввода:
- если информация конфиденциальная — изображение автоматически режется на части, и каждый оператор получает для ввода только часть информации;
- при большом количестве полей — поля одной карточки делятся между несколькими операторами.
- Проверка данных ввода. Наличие ошибок влияет на оплату труда людей, которые вводят данные.
- Проводится ряд общих автоматизированных проверок по базе.
- Отгрузка законченных частей массива заказчику.
Проект получил название «Центр удаленного трудоустройства» и начал набирать обороты. Первый месяц приходилось постоянно исправлять ошибки, которые вылезали при обкатке. Далее процесс наладился, и софт стал стабильно работать и выгружать готовые массивы данных.
С ростом нагрузки — на сервере стали возникать новые проблемы по оптимальности алгоритмов и скорости их обработки. Пока они решаются локально, но, вполне возможно, скоро придется проводить оптимизацию всей системы.
Весь проект был реализован при поддержке Министерства культуры и туризма Украины, подробнее можно почитать по ссылке.
Кратко о системе
Язык программирования: PHP.
База данных: MySQL.
CMS, Framework: отсутствуют, разработка велась с нуля.
Напоследок
Если этот пост будет принят положительно, я опубликую продолжение и расскажу о том, как построена технология автоматизации библиотек в странах СНГ. Особое внимание я уделю модулю с интересными особенностями, который отвечает за отображение информации в интернете.
