В последнее время я все чаще слышу о NoSQL и о графовых базах данных в частности. Но воспользовавшись хабропоиском с удивлением обнаружил, что статей на эту тему не так и много, а по запросу «Neo4j», так вообще 4 результата, где косвенно упоминается это название в тексте статей.

Neo4j — это высокопроизводительная, NoSQL база данных основанная на принципе графов. В ней нет такого понятия как таблицы со строго заданными полями, она оперирует гибкой структурой в виде нод и связей между ними.
Уже более года я не использовал в своих проектах SQL, с того времени, как попробовал документо-ориентированную СУБД "MongoDB". После MySQL моей радости не было предела, как все просто и удобно можно делать в MongoDB. За год, в нашей студии создания сайтов, переписали тройку CMS, использующих основные фишки Mongo c её документами, и с десяток сайтов работающих на их основе. Всё было хорошо, и я уже начал забывать, что такое писать запросы в полсотни строк на каждое действие с БД и все бы ничего пока на мою голову не свалился проект с кучей отношений, которые ну никак не укладывались в документы. Возвращаться к SQL очень не хотелось, и пару дней я потратил чисто на поиск NoSQL решения, позволяющего делать гибкие связи — на графовые СУБД. И по ряду причин мой выбор остановился на Neo4j, одна из главных причин — это то, что мой движок был написан на PHP, а для неё был написан хороший драйвер "Neo4jPHP", который охватывает почти 100% REST-интерфейса, предоставляющегося сервером Noe4j.
Графовые базы данных, в первую очередь, предназначены для решения тех задач, где данные тесно связанные между собой в отношениях, которые могут углубляться в несколько уровней. Например, в реляционных базах данных нам не трудно выполнить запрос: «Дайте мне список всех актеров, которые были в фильме с Кевином Бэконом».
Привел пример с под запросом, вы можете переписать его в голове с использованием «JOIN».
Но предположим, что мы хотим получить имена всех актеров, которые были в кино с кем-то, кто был в кино с Кевином Бэконом. И тут у нас появляется ещё один JOIN. А теперь попробуйте добавить третью степень: «Тот, кто был в кино с кем-то, кто был в кино с кем-то, кто был в фильме с Кевином Бэконом.» Страшно звучит, но задача реальная и с каждой новой связью мы должны добавлять JOIN, а запрос будет становится все более сложным, трудоёмким, все менее производительным.
Глубокие связи особенно актуальны в различных социальных проектах, когда нам нужно получать друзей друзей, в задачах поиска маршрутов и т.п. Графовые базы данных призваны решить эти проблемы, когда наши данные могут быть удаленны друг от друга на два и более отношений. Они решаются очень элегантно, когда мы моделируем данные как «вершины графов», а связи как «ребра графа» между этими узлами. Мы можем делать обход графа с помощью давно известных и эффективных алгоритмов.
Приведенный выше пример может быть легко смоделирован следующим образом: каждый актер и фильм являются узлами, а роли — отношения, идущие от актера в кино, где они играли:
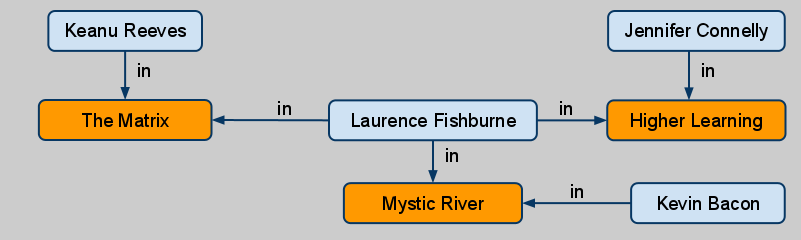
Теперь становится очень легко найти путь от Кевина Бэкона до любого другого актера.
Во-первых, нам нужно установить соединение с базой данных. Так как Neo4jPHP работает с сервером БД через REST интерфейс, то нет постоянного соединения, и передача данных происходит, только тогда когда нам нужно считать или записать данные:
Теперь нам нужно создать узлы для каждого актёра и фильма. Это аналогично тому, как мы делаем INSERT в традиционных реляционных СУБД:
Каждый узел имеет методы setProperty и getProperty, которые позволяют записывать произвольные данные в узел считывать их. Узел не имеет заданной структуры, это похоже на документы в документо-ориентированных СУБД, правда мы не можем делать вложенные данные и свойство может быть только одим из двух типов: строкой или числом.
На сервер данные отправляются только когда мы вызываем save() и это нужно сделать для каждого узла.
Теперь мы должны задать связи между актерами и фильмами, в которых они играли. В реляционных СУБД для этой цели мы бы создавали внешний ключ, тут мы создадим отношение, которое может быть произвольно названо хранить в себе любые параметры, как и узел и так же сохраняется в БД:
Как видите, все отношения называются «IN», но мы можем дать им и любое другое имя, например «ACTED IN». Так же мы можем задать обратное отношение от фильмов к актерам и сформулировать его как фильм «HAS» (имеет) актёра. Пути могут быть найдены не зависимо от того какое направление связи мы создадим, т.е. мы можем использовать любую семантику подходящую по смыслу для конкретной предметной области. В тоже время между узлами могут быть множественные отношения направленные в обе стороны.
Все отношения настроены, и теперь мы готовы найти связь между любым актером в нашей системе и Кевином Бэйконом до любой заданной глубины:
Так же мы можем выбирать не сами узлы, а связи между ними, например:
getRelationships — может вернуть все отношения для узла, необязательно ограничивать его только определенным типом отношения. Так же мы можем получить, только все входящие или исходящие из узла связи.
На этом пока закончу данный пост, и надеюсь он даст некий резонанс к написанию статей на тематику графовых баз данных и neo4j в частности.
В статье использовался пример с сайта разработчика Neo4jPHP с изменениями и комментариями основанными на моём личном опыте.
Что такое Neo4j?

Neo4j — это высокопроизводительная, NoSQL база данных основанная на принципе графов. В ней нет такого понятия как таблицы со строго заданными полями, она оперирует гибкой структурой в виде нод и связей между ними.
Как я докатился до этого?
Уже более года я не использовал в своих проектах SQL, с того времени, как попробовал документо-ориентированную СУБД "MongoDB". После MySQL моей радости не было предела, как все просто и удобно можно делать в MongoDB. За год, в нашей студии создания сайтов, переписали тройку CMS, использующих основные фишки Mongo c её документами, и с десяток сайтов работающих на их основе. Всё было хорошо, и я уже начал забывать, что такое писать запросы в полсотни строк на каждое действие с БД и все бы ничего пока на мою голову не свалился проект с кучей отношений, которые ну никак не укладывались в документы. Возвращаться к SQL очень не хотелось, и пару дней я потратил чисто на поиск NoSQL решения, позволяющего делать гибкие связи — на графовые СУБД. И по ряду причин мой выбор остановился на Neo4j, одна из главных причин — это то, что мой движок был написан на PHP, а для неё был написан хороший драйвер "Neo4jPHP", который охватывает почти 100% REST-интерфейса, предоставляющегося сервером Noe4j.
Ближе к делу
Графовые базы данных, в первую очередь, предназначены для решения тех задач, где данные тесно связанные между собой в отношениях, которые могут углубляться в несколько уровней. Например, в реляционных базах данных нам не трудно выполнить запрос: «Дайте мне список всех актеров, которые были в фильме с Кевином Бэконом».
> SELECT actor_name, role_name FROM roles WHERE movie_title IN (SELECT DISTINCT movie_title FROM roles WHERE actor_name='Kevin Bacon')
Привел пример с под запросом, вы можете переписать его в голове с использованием «JOIN».
Но предположим, что мы хотим получить имена всех актеров, которые были в кино с кем-то, кто был в кино с Кевином Бэконом. И тут у нас появляется ещё один JOIN. А теперь попробуйте добавить третью степень: «Тот, кто был в кино с кем-то, кто был в кино с кем-то, кто был в фильме с Кевином Бэконом.» Страшно звучит, но задача реальная и с каждой новой связью мы должны добавлять JOIN, а запрос будет становится все более сложным, трудоёмким, все менее производительным.
Глубокие связи особенно актуальны в различных социальных проектах, когда нам нужно получать друзей друзей, в задачах поиска маршрутов и т.п. Графовые базы данных призваны решить эти проблемы, когда наши данные могут быть удаленны друг от друга на два и более отношений. Они решаются очень элегантно, когда мы моделируем данные как «вершины графов», а связи как «ребра графа» между этими узлами. Мы можем делать обход графа с помощью давно известных и эффективных алгоритмов.
Приведенный выше пример может быть легко смоделирован следующим образом: каждый актер и фильм являются узлами, а роли — отношения, идущие от актера в кино, где они играли:

Теперь становится очень легко найти путь от Кевина Бэкона до любого другого актера.
Немного кода
Во-первых, нам нужно установить соединение с базой данных. Так как Neo4jPHP работает с сервером БД через REST интерфейс, то нет постоянного соединения, и передача данных происходит, только тогда когда нам нужно считать или записать данные:
use Everyman\Neo4j\Client,
Everyman\Neo4j\Transport,
Everyman\Neo4j\Node,
Everyman\Neo4j\Relationship;
$client = new Client(new Transport('localhost', 7474));
Теперь нам нужно создать узлы для каждого актёра и фильма. Это аналогично тому, как мы делаем INSERT в традиционных реляционных СУБД:
$keanu = new Node($client);
$keanu->setProperty('name', 'Keanu Reeves')->save();
$laurence = new Node($client);
$laurence->setProperty('name', 'Laurence Fishburne')->save();
$jennifer = new Node($client);
$jennifer->setProperty('name', 'Jennifer Connelly')->save();
$kevin = new Node($client);
$kevin->setProperty('name', 'Kevin Bacon')->save();
$matrix = new Node($client);
$matrix->setProperty('title', 'The Matrix')->save();
$higherLearning = new Node($client);
$higherLearning->setProperty('title', 'Higher Learning')->save();
$mysticRiver = new Node($client);
$mysticRiver->setProperty('title', 'Mystic River')->save();
Каждый узел имеет методы setProperty и getProperty, которые позволяют записывать произвольные данные в узел считывать их. Узел не имеет заданной структуры, это похоже на документы в документо-ориентированных СУБД, правда мы не можем делать вложенные данные и свойство может быть только одим из двух типов: строкой или числом.
На сервер данные отправляются только когда мы вызываем save() и это нужно сделать для каждого узла.
Теперь мы должны задать связи между актерами и фильмами, в которых они играли. В реляционных СУБД для этой цели мы бы создавали внешний ключ, тут мы создадим отношение, которое может быть произвольно названо хранить в себе любые параметры, как и узел и так же сохраняется в БД:
$keanu->relateTo($matrix, 'IN')->save();
$laurence->relateTo($matrix, 'IN')->save();
$laurence->relateTo($higherLearning, 'IN')->save();
$jennifer->relateTo($higherLearning, 'IN')->save();
$laurence->relateTo($mysticRiver, 'IN')->save();
$kevin->relateTo($mysticRiver, 'IN')->save();
Как видите, все отношения называются «IN», но мы можем дать им и любое другое имя, например «ACTED IN». Так же мы можем задать обратное отношение от фильмов к актерам и сформулировать его как фильм «HAS» (имеет) актёра. Пути могут быть найдены не зависимо от того какое направление связи мы создадим, т.е. мы можем использовать любую семантику подходящую по смыслу для конкретной предметной области. В тоже время между узлами могут быть множественные отношения направленные в обе стороны.
Все отношения настроены, и теперь мы готовы найти связь между любым актером в нашей системе и Кевином Бэйконом до любой заданной глубины:
$path = $keanu->findPathsTo($kevin)
->setMaxDepth(12)
->getSinglePath();
foreach ($path as $i => $node) {
if ($i % 2 == 0) {
echo $node->getProperty('name');
if ($i+1 != count($path)) {
echo " was in\n";
}
} else {
echo "\t" . $node->getProperty('title') . " with\n";
}
}
Так же мы можем выбирать не сами узлы, а связи между ними, например:
echo $laurence->getProperty('name') . " was in:\n";
$relationships = $laurence->getRelationships('IN');
foreach ($relationships as $relationship) {
$movie = $relationship->getEndNode();
echo "\t" . $movie->getProperty('title') . "\n";
}
getRelationships — может вернуть все отношения для узла, необязательно ограничивать его только определенным типом отношения. Так же мы можем получить, только все входящие или исходящие из узла связи.
На этом пока закончу данный пост, и надеюсь он даст некий резонанс к написанию статей на тематику графовых баз данных и neo4j в частности.
В статье использовался пример с сайта разработчика Neo4jPHP с изменениями и комментариями основанными на моём личном опыте.
