Представляю вашему вниманию заключительную статью из трилогии «Восстановление расфокусированных и смазанных изображений». Первые две вызвали заметный интерес — область, действительно, интересная. В этой части я рассмотрю семейство методов, которые дают лучшее качество, по сравнении со стандартным Винеровским фильтром — это методы, основанные на Total Variaton prior.
Также по традиции я выложил новую версию SmartDeblur (вместе с исходниками в open-source) в которой реализовал этот метод. Итоговое качество получилось на уровне коммерческих аналогов типа Topaz InFocus. Вот пример обработки реального изображения с очень большим размытием:

Описывать базовую теорию деконволюции здесь я не буду, о ней очень подробно было написано в предыдущих статьях. Тем, кто не читал их или подзабыл, рекомендую для начала ознакомиться с ними, чтобы понять терминологию и классические подходы:
Часть 1. Теория;
Часть 2. Практика.
Прежде чем перейти к описанию Total Variation (далее TV prior), необходимо понять, какие же недостатки есть у алгоритмов типа классического Винеровского фильтра? Самые основные — это эффект типа звона (периодический ореол на краях объектов) даже при небольшом уровне шума, размывание границ и мелких деталей, а также плохое шумоподавление с точки зрения человеческого восприятия. Все это сильно мешает практическому применению фильтра Винера ограничивая его применение задачами технического восстановления изображений, например для прочтения интересующих надписей.
Поэтому в последнее время было разработано большое количество самых разных методов, цель которых состоит в улучшении визуального качества. Надо заметить, что количество деталей при этом, как правило не возрастает.
Основное качество Total Variation prior с точки зрения результата — сохранение резких краев и сглаживание артефактов деконволюции. Записывается следующим образом:
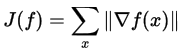
К сожалению, вычисление этого функционала нельзя сделать простым образом, поскольку здесь требуется применение весьма сложных техник оптимизации.
В качестве альтернативы можно использовать сглаженный функционал вместо абсолютного значения:
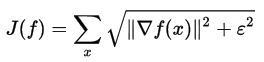
Когда эпсилон стремится к нулю, результат стремится к первоначальному определению Total Variation, но процесс оптимизации становится более сложным. И наоборот, при достаточном большом эпсилон результат оптимизации будет напоминать фильтр Винера с размытием краев. К сожалению, приведенная выше формула имеет неквадратичный вид, поэтому она не может быть просто вычислена в частотном пространстве Фурье, как это получалось с фильтрами Винера и Тихонова. Поэтому необходим один из методов пошаговой оптимизации для нахождения приближенного решения — например классический метод градиентного спуска:
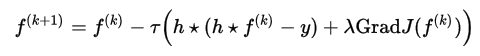
Где тау вычисляется по следующей формуле:
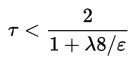
А градиент сглаженного функционала определяется как:
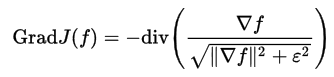
Количество итераций должно быть достаточно большим — несколько сотен.
Это самый базовый подход в реализации TV prior, что называется «в лоб». Тем не менее, даже он дает очень неплохие результаты. На базе его в научных публикациях появилось много исследований, которые пытаются еще улучшить качество, а также уменьшить время расчета.
Описанные формулы, в принципе, несложные, хотя и очень громоздкие в реализации. Основная проблема — достичь высокого быстродействия, т.к. количество итераций очень большое и каждая итерация содержит много сложных действий. А именно — несколько сверток изображения целиком, вычисления полного градиента и дивергенции.
Скажу сразу, добиться хорошей скорости работы мне пока не удалось, на изображении размером несколько мегапикселей время финального вычисления составляет 2-3 минуты. Но Preview работает быстро — порядка 0.2 секунды.
Сборку под Windows можно скачать по адресу:
github.com/downloads/Y-Vladimir/SmartDeblur/SmartDeblur-1.27-win.zip
Исходники (под лицензией GPL v3) доступны по ссылке: github.com/Y-Vladimir/SmartDeblur
Основные изменения по сравнению с прошлой версией, которая была описана во второй части:
Язык C++ с использованием Qt.
Ну и теперь самое главное — на какое же качество можно рассчитывать при обработке размытых изображений. Будем сравнивать с топовым коммерческим аналогом Topaz InFocus. Остальные аналоги (типа FocusMagic) уже давно не поддерживаются или дают уж совсем неприемлемые результаты обработки. Итак поехали.
Сначала возьмем рекламный пример с сайта Topaz InFocus: www.topazlabs.com/infocus/_images/licenseplate_compare.jpg

Вот результат от Topaz InFocus:

А вот результат работы SmartDeblur при следующих параметрах:
Type: Motion Blur, Length: 10.1, Angle: -45, Smooth: 60%

Как видим, результаты очень схожие. И не так очевидно, что лучше. Topaz InFocus, судя по всему, тоже использует алгоритм, похожий на TV prior плюс пост-обработка в виде шарпинга краев. Надо заметить, что приведенное исходное смазанное изображение, с очень большой вероятностью, является синтетическим. Т.е. взято неискаженное изображение и применен фильтр Motion Blur. Это видно по практически идеальному восстановлению, а также по подозрительно целым параметрам искажения — угол 45 градусов и длина 10 пикселей.
Теперь возьмем реальное изображение, которое я вчера сфоткал на свой Canon 500D с ручным уводом фокуса:

Результат от Topaz InFocus при следующих параметрах:
Type: Out-of-Focus, Radius: 5.5, Suppress Artifacts: 0.34

Результат SmartDeblur при следующих параметрах:
Type: Out of Focus, Radius: 5.9, Smooth: 60%

Тут ничья, можно сказать. Параметры в каждой программе подбирались так, чтобы обеспечить наилучшее качество.
Еще один реальный пример снятый мною:

Результат SmartDeblur при следующих параметрах:
Type: Motion Blur, Length: 6.6, Angle: -37, Smooth: 53%

Подошла к концу третья заключительная статья. Получилась она не особо большой, но, надеюсь, будет полезной. Как видим полученное качество обработки уже вполне приемлемо для реального применения. Основная проблема, которая остается — в местах, где есть светлые объекты, после обработки получается заметный эффект звона. Думаю, это связано с тем, что на светлых участках нарушается линейность отображения яркости пикселей, что дает неверную интерпретацию о его реальной яркости. Возможно, нужна логарифмическая предобработка яркости, либо еще что-то.
Еще раз напомню:
Сборку под Windows можно скачать по адресу:
github.com/downloads/Y-Vladimir/SmartDeblur/SmartDeblur-1.27-win.zip
Исходники (под лицензией GPL v3) доступны по ссылке: github.com/Y-Vladimir/SmartDeblur
И как обычно — буду очень рад замечаниям и предложениям по SmartDeblur!
Кто будет пробовать программу — учтите, что параметр качества Smooth в режиме превью и в режиме High-Quality ведет себя весьма по-разному. Поэтому финальный результат ползунка сглаживания можно оценить только после завершения просчета High-Quality.
P.S. Огромная просьба ко всем, кто мне пишет на почту. После публикации двух предыдущих статьей мне пришло (и продолжает приходить) большое количество писем с просьбой восстановить номера машин на кадрах с камер видеонаблюдения, когда весь номер занимает площадь несколько пикселей.
Я этим не занимаюсь! SmartDeblur этого тоже делать не умеет. Это задача совсем другого рода, а именно Super-Resolution, когда из нескольких изображений малого разрешения получается изображение высокого разрешения с новыми деталями, которых не было на исходных данных. Может быть когда-нибудь ей и займусь, но точно не в ближайшее время.
UPDATE Ссылка на продолжение:
Blind Deconvolution — автоматическое восстановление смазанных изображений
Также по традиции я выложил новую версию SmartDeblur (вместе с исходниками в open-source) в которой реализовал этот метод. Итоговое качество получилось на уровне коммерческих аналогов типа Topaz InFocus. Вот пример обработки реального изображения с очень большим размытием:

Введение
Описывать базовую теорию деконволюции здесь я не буду, о ней очень подробно было написано в предыдущих статьях. Тем, кто не читал их или подзабыл, рекомендую для начала ознакомиться с ними, чтобы понять терминологию и классические подходы:
Часть 1. Теория;
Часть 2. Практика.
Прежде чем перейти к описанию Total Variation (далее TV prior), необходимо понять, какие же недостатки есть у алгоритмов типа классического Винеровского фильтра? Самые основные — это эффект типа звона (периодический ореол на краях объектов) даже при небольшом уровне шума, размывание границ и мелких деталей, а также плохое шумоподавление с точки зрения человеческого восприятия. Все это сильно мешает практическому применению фильтра Винера ограничивая его применение задачами технического восстановления изображений, например для прочтения интересующих надписей.
Поэтому в последнее время было разработано большое количество самых разных методов, цель которых состоит в улучшении визуального качества. Надо заметить, что количество деталей при этом, как правило не возрастает.
Описание TV prior
Основное качество Total Variation prior с точки зрения результата — сохранение резких краев и сглаживание артефактов деконволюции. Записывается следующим образом:
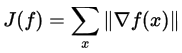
К сожалению, вычисление этого функционала нельзя сделать простым образом, поскольку здесь требуется применение весьма сложных техник оптимизации.
В качестве альтернативы можно использовать сглаженный функционал вместо абсолютного значения:

Когда эпсилон стремится к нулю, результат стремится к первоначальному определению Total Variation, но процесс оптимизации становится более сложным. И наоборот, при достаточном большом эпсилон результат оптимизации будет напоминать фильтр Винера с размытием краев. К сожалению, приведенная выше формула имеет неквадратичный вид, поэтому она не может быть просто вычислена в частотном пространстве Фурье, как это получалось с фильтрами Винера и Тихонова. Поэтому необходим один из методов пошаговой оптимизации для нахождения приближенного решения — например классический метод градиентного спуска:
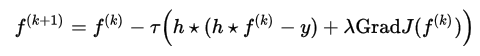
Где тау вычисляется по следующей формуле:
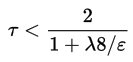
А градиент сглаженного функционала определяется как:
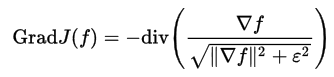
Количество итераций должно быть достаточно большим — несколько сотен.
Это самый базовый подход в реализации TV prior, что называется «в лоб». Тем не менее, даже он дает очень неплохие результаты. На базе его в научных публикациях появилось много исследований, которые пытаются еще улучшить качество, а также уменьшить время расчета.
Практическая реализация
Описанные формулы, в принципе, несложные, хотя и очень громоздкие в реализации. Основная проблема — достичь высокого быстродействия, т.к. количество итераций очень большое и каждая итерация содержит много сложных действий. А именно — несколько сверток изображения целиком, вычисления полного градиента и дивергенции.
Скажу сразу, добиться хорошей скорости работы мне пока не удалось, на изображении размером несколько мегапикселей время финального вычисления составляет 2-3 минуты. Но Preview работает быстро — порядка 0.2 секунды.
Сборку под Windows можно скачать по адресу:
github.com/downloads/Y-Vladimir/SmartDeblur/SmartDeblur-1.27-win.zip
Исходники (под лицензией GPL v3) доступны по ссылке: github.com/Y-Vladimir/SmartDeblur
Основные изменения по сравнению с прошлой версией, которая была описана во второй части:
- Добавлены два метода деконволюции: TV prior и фильтрация по Тихонову
- Добавлена поддержка восстановления Гауссового размытия
- Улучшена скорость работы (примерно в 2.5 раза)
- Уменьшено потребление памяти (примерно в 1.5 раза)
- Максимальный размер обрабатываемого изображения по умолчанию 3000 (но можно менять в настройках)
- Добавлена секция настроек
- Добавлен Updates Checker
- Поддержка Drag&Drop
- Добавлен Help Screen с примером изображения и советами по настройке
- Исправлен баг с рябью в режиме preview
Язык C++ с использованием Qt.
Сравнение
Ну и теперь самое главное — на какое же качество можно рассчитывать при обработке размытых изображений. Будем сравнивать с топовым коммерческим аналогом Topaz InFocus. Остальные аналоги (типа FocusMagic) уже давно не поддерживаются или дают уж совсем неприемлемые результаты обработки. Итак поехали.
Сначала возьмем рекламный пример с сайта Topaz InFocus: www.topazlabs.com/infocus/_images/licenseplate_compare.jpg

Вот результат от Topaz InFocus:

А вот результат работы SmartDeblur при следующих параметрах:
Type: Motion Blur, Length: 10.1, Angle: -45, Smooth: 60%

Как видим, результаты очень схожие. И не так очевидно, что лучше. Topaz InFocus, судя по всему, тоже использует алгоритм, похожий на TV prior плюс пост-обработка в виде шарпинга краев. Надо заметить, что приведенное исходное смазанное изображение, с очень большой вероятностью, является синтетическим. Т.е. взято неискаженное изображение и применен фильтр Motion Blur. Это видно по практически идеальному восстановлению, а также по подозрительно целым параметрам искажения — угол 45 градусов и длина 10 пикселей.
Теперь возьмем реальное изображение, которое я вчера сфоткал на свой Canon 500D с ручным уводом фокуса:

Результат от Topaz InFocus при следующих параметрах:
Type: Out-of-Focus, Radius: 5.5, Suppress Artifacts: 0.34

Результат SmartDeblur при следующих параметрах:
Type: Out of Focus, Radius: 5.9, Smooth: 60%

Тут ничья, можно сказать. Параметры в каждой программе подбирались так, чтобы обеспечить наилучшее качество.
Еще один реальный пример снятый мною:

Результат SmartDeblur при следующих параметрах:
Type: Motion Blur, Length: 6.6, Angle: -37, Smooth: 53%

Выводы
Подошла к концу третья заключительная статья. Получилась она не особо большой, но, надеюсь, будет полезной. Как видим полученное качество обработки уже вполне приемлемо для реального применения. Основная проблема, которая остается — в местах, где есть светлые объекты, после обработки получается заметный эффект звона. Думаю, это связано с тем, что на светлых участках нарушается линейность отображения яркости пикселей, что дает неверную интерпретацию о его реальной яркости. Возможно, нужна логарифмическая предобработка яркости, либо еще что-то.
Еще раз напомню:
Сборку под Windows можно скачать по адресу:
github.com/downloads/Y-Vladimir/SmartDeblur/SmartDeblur-1.27-win.zip
Исходники (под лицензией GPL v3) доступны по ссылке: github.com/Y-Vladimir/SmartDeblur
И как обычно — буду очень рад замечаниям и предложениям по SmartDeblur!
Кто будет пробовать программу — учтите, что параметр качества Smooth в режиме превью и в режиме High-Quality ведет себя весьма по-разному. Поэтому финальный результат ползунка сглаживания можно оценить только после завершения просчета High-Quality.
P.S. Огромная просьба ко всем, кто мне пишет на почту. После публикации двух предыдущих статьей мне пришло (и продолжает приходить) большое количество писем с просьбой восстановить номера машин на кадрах с камер видеонаблюдения, когда весь номер занимает площадь несколько пикселей.
Я этим не занимаюсь! SmartDeblur этого тоже делать не умеет. Это задача совсем другого рода, а именно Super-Resolution, когда из нескольких изображений малого разрешения получается изображение высокого разрешения с новыми деталями, которых не было на исходных данных. Может быть когда-нибудь ей и займусь, но точно не в ближайшее время.
UPDATE Ссылка на продолжение:
Blind Deconvolution — автоматическое восстановление смазанных изображений
--Vladimir Yuzhikov (Владимир Южиков)

{kind=link}