Введение
Это не просто обзор существующих OCR (мы будем говорить всего о трёх) и не руководство по установке (хотя установка будет описана). Эта статья была создана с целью разобраться, что и как реально может распознать русский и английский языки в Linux.
Пару слов для того, чтобы вникнуть в суть описываемых процессов.
OCR – оптическое распознавание символов.
Технология необходима для оцифровки печатных документов; некоторые используют OCR в целях автоматизации (к примеру, для распознавания капчи или для защиты от спам-ботов).
OCR в Linux
Повторюсь еще раз: здесь будут рассмотрены программы, распознающие русский язык. Под Linux есть несколько OCR, предназначенных для работы с латиницей, есть специализированные комплексы, работающие только с ивритом, к примеру, – все это не относится к нашей теме.
По сути, речь будет идти только о трех продуктах: Cuneiform, Tesseract и Finereader Engine. Все они сами по себе предоставляют только консольный интерфейс, хотя для первых двух разработано достаточно GUI.
Я использую Debian Squeeze, но зачастую буду давать ссылки на исходники и пояснять сборку пакетов (можете воспользоваться репозиториями на notesalexp.org или репозиториями вашего дистрибутива — я просто даю пример сборки).
Тема будет раскрываться в следующем порядке:
1. Установка OCR для Linux (3 движка), их установка.
2. Сравнение CLI OCR на примерах.
3. GUI для OCR, их сравнение.
4. Небольшой тест online-OCR.
5. Выводы и некоторые прогнозы и предложения.
Установка OCR для Linux
Cuneiform
Страница о проекте на Википедии.
Заявленные возможности: поддержка множества языков, сохранение форматирования исходного документа, вывод в txt, hocr, html, распознавание факсов и текстов, отпечатанных на матричном принтере.
Мы рассмотрим два реальных пути использования Cuneiform под Linux: нативный и с помощью Wine (в этом есть необходимость, ниже вы сможете убедиться сами).
1. Нативный Cuneiform
Раздел на Launchpad
Исходники
Приступим к установке.
Скачиваем исходники и распаковываем их.
Далее все стандартно (см. readme.txt в комплекте с исходниками). Переходим в директорию с исходниками и последовательно выполняем:
mkdir builddir
cd builddir
cmake -DCMAKE_BUILD_TYPE=debug ..
make
sudo checkinstall
sudo ldconfig
Готово.
2. Установка под Wine.
Плюс этого способа в том, что мы сразу получаем оригинальный функциональный GUI. Версия Wine не важна (Cuneiform работал и под Wine 1.0). Единственная особенность: необходимо в настройках Wine указать новое замещение для библиотеки msvcrt.
Дистрибутив доступен по этой ссылке.
Tesseract.
Страница о проекте на Википедии.
Страница на Google Code.
Заявленные возможности: поддержка множества языков, вывод в txt и hocr, тренировка программы на своих примерах (я это рассматривать не буду, работаем as is), использование файла конфигурации для конкретного образца.
Я в кратком и вольном варианте описываю данный Readme.
Разрешение зависимостей перед установкой:
sudo apt-get install autoconf automake libtool libpng12-dev libjpeg62-dev libtiff4-dev zlib1g-dev
Также Tesseract зависит от libleptonica-dev версии не ниже 1.67. В Squeeze этот пакет устарел, поэтому пришлось его собирать.
Получаем исходный код, распаковываем и выполняем сборку:
./autobuild
./configure
make
sudo checkinstall
sudo ldconfig
Теперь получаем исходники Tesseract, распаковываем и переходим в директорию с ними.
Далее выполняем:
./autogen.sh
./configure
make
sudo checkinstall
sudo ldconfig
Tesseract установлен. Получим пакеты для распознавания языков: русского и английского — и распакуем их в директорию tessdata ( /usr/local/share/tessdata по умолчанию).
Можно работать.
FineReader Engine
Анонс можно просмотреть здесь.
Как получить? Идем сюда, внимательно читаем и запрашиваем триал (лимит в 100 распознаваний). Можно попросить и на русском.
Установка проста: скачать, запустить под рутом abbyyocr.run и выполнить текстовые указания.
Заявленные возможности: поддержка множества языков, различных кодировок, работа с паролями, нумерацией страниц, распознавание таблиц, штрихкодов, текстов, отпечатанных на матричном принтере, печатной машинке, готических шрифтов и т.д., вывод в txt, rtf, html, xml, xls.
Rubyquet+
Раз уж я заговорил о CLI OCR, упомяну CLI Rubyquet+ для Tesseract и Cuneiform.
Тестировать я его не стал (этим можете заняться вы) – тот же CLI для вышеупомянутых OCR доступен и сам по себе.
Сравнение CLI OCR
*CLI – command line interface – интерфейс командной строки (“консоль”).
Предупреждаю сразу: этот раздел достаточно объёмный. Если вы хотите обойтись без лишних подробностей и множества букв — рекомендую не раскрывать спойлеры.
Помните: я не претендую на абсолютную объективность сравнения. У вас могут получиться другие результаты и другие выводы.
Обозначу критерии тестирования.
Конечно, идеальным результатом должно стать стопроцентное распознавание всех символов, форматирования и рисунков. Однако, на практике наиболее востребованным является просто распознавание текста. Необходимое форматирование и дополнение текста изображениями пользователь в состоянии произвести при постобработке.
Для оценки качества распознавания я введу следующие критерии (хотя и буду отступать от них):
Критерий “Неверных слов” — неверно распознанных слов (от одного неверного символа в слове вплоть до полного отсутствия слова) для простоты расчета – самый важный критерий.
Критерий “Неверных символов” — неверно распознанных символов при невозможности применения первого критерия (лишние символы, знаки препинания и т.д.).
Критерий “Ошибки форматирования” — служит для определения качества работы с таблицами, рисунками, определения написания болдом и курсивом.
Для каждого образца и программы будет рассчитываться процент верно распознанных слов, что и будет основополагающим фактором. Количество слов в образце я буду принимать по результату распознавания в Finereader.
Теперь об образцах.
Что мы чаще всего распознаем? Либо документацию, прошедшую через сканер, либо фотографию документа. Естественно, с различным качеством и разрешением (для OCR рекомендуется сканирование в качестве не ниже 300 dpi, поэтому сравним сканированные образцы 200dpi, 300 dpi и 600dpi; для фотографий используем съемку с качеством 2МП и 5МП). К тому же, на некоторых образцах будут таблицы и картинки.
Распознаваемые изображения я буду давать в виде ссылок на них (их непосредственное присутствие в статье будет только мешать). Результат распознавания по первой ссылке будет доступен на Google Docs, по второй ссылке с пометкой «Оригинал» — в исходном виде на Dropbox
Чтобы не захламлять обзор, вместо путей исходного изображения и полученного текста я буду писать соответственно INPUT и OUTPUT.
Образец №1 (нумерованный список).
Тест образца №1
Так сложилось, что этот список вопросов, отсканированный в 200 dpi (точек на дюйм), первым попался под руку и постоянно использовался по ходу исследования.
0001.png
Особенности образца: он фактически разделен на 2 столбца (нумерация и сам текст), язык русский с несколькими латинскими символами.
1. Cuneiform.
Синтаксис:
Результат:
0001.png.cun.rtf
(Оригинал)
Неверных слов: 14 (в тексте 728 слов)
Неверных символов: 7
Ошибки форматирования: местами не поставил абзацы, ошибочно вводил курсив.
Вывод: правильность распознавания слов – около 98%. Основная ошибка – путаница с “и” и “н”. В одном месте сумел распознать вставку латиницей.
В целом хорошо.
2. Tesseract.
Синтаксис:
Результат (в RTF сохранять не умеет):
0001.png.tes.txt
(Оригинал)
Неверных слов: 6 (в тексте 728 слов)
Неверных символов: 5
Ошибки форматирования: при выводе в текстовый файл невозможно сохранить форматирование оригинала, с абзацами работает лучше, чем cuneiform, вставки латиницей распознать не может технически.
Вывод: правильность распознавания слов – около 99%. Текст выглядит приятнее, чем при работе с cuneiform.
3. Finereader.
Сразу отмечу большой минус: насколько я понял, Finereader работает только с правами суперпользователя.
Синтаксис:
0001.png.fin.rtf
(Оригинал)
Неверных слов: 2 (в тексте 728 слов)
Неверных символов: 0
Ошибки форматирования: почти идеально. 2 ошибки в словах – не смог распознать латиницу.
Вывод: фактически стопроцентная точность.
Вывод по образцу №1: первое место занимает Finereader, второе – Tesseract, третье с минимальным отрывом – Cuneiform.
0001.png
Особенности образца: он фактически разделен на 2 столбца (нумерация и сам текст), язык русский с несколькими латинскими символами.
1. Cuneiform.
cuneiform -l ruseng -f rtf --singlecolumn -o 'OUTPUT' 'INPUT'Синтаксис:
-l ruseng – распознавать в тексте русский и английский (по отдельности было бы, соответственно, rus или eng);-f rtf – формат вывода RTF (пытаемся сохранить форматирование);--singlecolumn – воспринимать текст как единый столбец;-o 'OUTPUT' – путь к файлу с текстом;'INPUT' – путь к изображению.Результат:
0001.png.cun.rtf
(Оригинал)
Неверных слов: 14 (в тексте 728 слов)
Неверных символов: 7
Ошибки форматирования: местами не поставил абзацы, ошибочно вводил курсив.
Вывод: правильность распознавания слов – около 98%. Основная ошибка – путаница с “и” и “н”. В одном месте сумел распознать вставку латиницей.
В целом хорошо.
2. Tesseract.
tesseract 'INPUT' 'OUTPUT' -l rus -psm 6Синтаксис:
-l rus – 2 языка сразу tesseract не поддерживает;-psm 6 — “Assume a single uniform block of text”, т.е. форматировать полученный текст единым блоком (иначе нумерация будет аккуратно размещена поперед всего текста – блок все-таки).Результат (в RTF сохранять не умеет):
0001.png.tes.txt
(Оригинал)
Неверных слов: 6 (в тексте 728 слов)
Неверных символов: 5
Ошибки форматирования: при выводе в текстовый файл невозможно сохранить форматирование оригинала, с абзацами работает лучше, чем cuneiform, вставки латиницей распознать не может технически.
Вывод: правильность распознавания слов – около 99%. Текст выглядит приятнее, чем при работе с cuneiform.
3. Finereader.
Сразу отмечу большой минус: насколько я понял, Finereader работает только с правами суперпользователя.
sudo abbyyocr9 -rl Russian English -if 'INPUT' -f RTF -of 'OUTPUT' Синтаксис:
-rl Russian English – русский и английский языки текста.-f RTF – вывод в RTF.0001.png.fin.rtf
(Оригинал)
Неверных слов: 2 (в тексте 728 слов)
Неверных символов: 0
Ошибки форматирования: почти идеально. 2 ошибки в словах – не смог распознать латиницу.
Вывод: фактически стопроцентная точность.
Вывод по образцу №1: первое место занимает Finereader, второе – Tesseract, третье с минимальным отрывом – Cuneiform.
Образец №2 (сканированный учебник английского).
Тест образца №2
0002.png
1. Cuneiform.
Результат:
0002.png.cun.rtf
(Оригинал)
Неверных слов: 2 (в тексте 534 слова)
Неверных символов: 6
Ошибки форматирования: распознал сноски как одинарные кавычки, не справился с квадратными скобками, дефисом и тире; не смог распознать транскрипцию слова.
Вывод: 99% слов. Хорошо.
Версия, распознанная с помощью CuneiformV12:
0002.cun.win.rtf
(Оригинал)
Результат близок к результату нативной версии.
2. Tesseract.
Результат:
0002.png.tes.txt
(Оригинал)
Неверных слов: 1 (в тексте 534 слова)
Неверных символов: 4
Ошибки форматирования: нашел пару лишних символов, не справился со сносками.
Вывод: 99% слов. Лучше, чем у cuneiform.
3. Finereader.
Результат:
0002.png.fin.rtf
(Оригинал)
Неверных слов: 0 (в тексте 534 слова)
Неверных символов: 2
Ошибки форматирования: не распознал одну сноску и номер страницы.
Вывод: 100% слов, распознал курсив. Лучший результат.
0003.png
1. Cuneiform.
0003.png.cun.rtf
(Оригинал)
Качество распознавания на том же уровне.
2. Tesseract.
0003.png.tes.txt
(Оригинал)
Внезапно качество распознавания ухудшилось. Tesseract умудрился распознать горизонтальные линии как совокупность точек и символов. Кроме этого, лишние символы (тильды, одинарные кавычки) появились и в самом тексте.
3. Finereader.
0003.png.fin.rtf
(Оригинал)
Качество распознавания на том же уровне.
0004.png
1. Cuneiform.
0004.png.cun.rtf
(Оригинал)
Качество ухудшилось. Появляются лишние символы, дефисы и тире все так же не распознает, потерял букву “U” в слове “Unit”.
2. Tesseract.
0004.png.tes.txt
(Оригинал)
Отсутствует “Unit 6”, нет номера страницы, появилось несколько лишних кавычек.
3. Finereader.
0004.png.fin.rtf
(Оригинал)
Появился номер страницы, а вместе с ним и горизонтальная линия, превратившаяся в набор точек. Качество не улучшилось.
Вывод по образцу №2: для всех трех систем оптимальным было изображение качеством 200 dpi. При увеличении плотности точек на дюйм либо происходило ухудшение распознавания, либо просто не было подвижек в лучшую сторону.
На первое место по качеству работы я ставлю Finereader, на второе – Tesseract (следует помнить, что он не поддерживает RTF), на третье (с минимальным отставанием) – Cuneiform.
200dpi.
0002.png
1. Cuneiform.
cuneiform -l eng -f rtf --singlecolumn -o 'OUTPUT' 'INPUT'Результат:
0002.png.cun.rtf
(Оригинал)
Неверных слов: 2 (в тексте 534 слова)
Неверных символов: 6
Ошибки форматирования: распознал сноски как одинарные кавычки, не справился с квадратными скобками, дефисом и тире; не смог распознать транскрипцию слова.
Вывод: 99% слов. Хорошо.
Версия, распознанная с помощью CuneiformV12:
0002.cun.win.rtf
(Оригинал)
Результат близок к результату нативной версии.
2. Tesseract.
tesseract 'INPUT' 'OUTPUT' -l eng -psm 6Результат:
0002.png.tes.txt
(Оригинал)
Неверных слов: 1 (в тексте 534 слова)
Неверных символов: 4
Ошибки форматирования: нашел пару лишних символов, не справился со сносками.
Вывод: 99% слов. Лучше, чем у cuneiform.
3. Finereader.
sudo abbyyocr9 -rl English -if 'INPUT' -f RTF -of 'OUTPUT' Результат:
0002.png.fin.rtf
(Оригинал)
Неверных слов: 0 (в тексте 534 слова)
Неверных символов: 2
Ошибки форматирования: не распознал одну сноску и номер страницы.
Вывод: 100% слов, распознал курсив. Лучший результат.
Тот же учебник, 300 dpi.
0003.png
1. Cuneiform.
0003.png.cun.rtf
(Оригинал)
Качество распознавания на том же уровне.
2. Tesseract.
0003.png.tes.txt
(Оригинал)
Внезапно качество распознавания ухудшилось. Tesseract умудрился распознать горизонтальные линии как совокупность точек и символов. Кроме этого, лишние символы (тильды, одинарные кавычки) появились и в самом тексте.
3. Finereader.
0003.png.fin.rtf
(Оригинал)
Качество распознавания на том же уровне.
Тот же учебник, 600 dpi.
0004.png
1. Cuneiform.
0004.png.cun.rtf
(Оригинал)
Качество ухудшилось. Появляются лишние символы, дефисы и тире все так же не распознает, потерял букву “U” в слове “Unit”.
2. Tesseract.
0004.png.tes.txt
(Оригинал)
Отсутствует “Unit 6”, нет номера страницы, появилось несколько лишних кавычек.
3. Finereader.
0004.png.fin.rtf
(Оригинал)
Появился номер страницы, а вместе с ним и горизонтальная линия, превратившаяся в набор точек. Качество не улучшилось.
Вывод по образцу №2: для всех трех систем оптимальным было изображение качеством 200 dpi. При увеличении плотности точек на дюйм либо происходило ухудшение распознавания, либо просто не было подвижек в лучшую сторону.
На первое место по качеству работы я ставлю Finereader, на второе – Tesseract (следует помнить, что он не поддерживает RTF), на третье (с минимальным отставанием) – Cuneiform.
Образец №3 (сфотографированный учебник английского).
Тест образца №3
Основными особенностями такого изображения являются неравномерность распределения яркости и возможные смазы (“шевеленка” при съемке на длинных выдержках без использования вспышки)
Сразу договоримся, что никаких ручных коррекций изображения проводить не будем (кроме одного примера): как сняли, так сняли.
0005.JPG
1. Cuneiform.
0005.JPG.cun.rtf
(Оригинал)
Распознал около 40% текста, остальное превратилось в месиво различных символов.
CuneiformV12 под Wine на этом изображении распознал буквально пару слов. Пример не привожу.
2. Tesseract.
0005.JPG.tes.txt
(Оригинал)
Результат намного лучше, чем у Cuneiform. Верно распознано около 80% текста.
3. Finereader.
0005.jpg.fin.rtf
(Оригинал)
Неверных слов: 3 (в тексте 534 слова)
Неверных символов: 0
Ошибки форматирования: не распознал одну сноску и номер страницы.
Вывод: 99% точность. Отлично.
0006.JPG
1. Cuneiform.
0006.JPG.cun.rtf
(Оригинал)
Распознал около 20% текста, результат совершенно негодный.
2. Tesseract.
0006.JPG.tes.txt
(Оригинал)
Распознал около 30% текста.
3. Finereader.
0006.JPG.fin.rtf
(Оригинал)
Распознал около 95% текста.
0007.JPG
1. Cuneiform.
0007.JPG.cun.rtf
(Оригинал)
Распознал несколько слов.
2. Tesseract.
0007.JPG.tes.txt
(Оригинал)
Распознал пару десятков слов.
3. Finereader.
0007.JPG.fin.rtf
(Оригинал)
И все равно Finereader показывает высший класс: распознано около 85% текста.
0008.JPG
1. Cuneiform.
0008.JPG.cun.rtf
(Оригинал)
Распознал пару десятков слов.
2. Tesseract.
0008.JPG.tes.txt
(Оригинал)
Распознал около 60% текста.
3. Finereader.
0008.JPG.fin.rtf
(Оригинал)
Распознал около 95% текста.
Вывод по образцу №3: здесь становится ясно, почему Finereader Engine имеет размер около 400 МБ: у него в комплекте с OCR есть алгоритмы обработки изображений, за счет чего при распознавании фотографий он дает неизменно хороший результат. Средствами же Cuneiform и Tesseract фотографии без хорошей предварительной обработки лучше не распознавать.
Сразу договоримся, что никаких ручных коррекций изображения проводить не будем (кроме одного примера): как сняли, так сняли.
5МП со вспышкой.
0005.JPG
1. Cuneiform.
0005.JPG.cun.rtf
(Оригинал)
Распознал около 40% текста, остальное превратилось в месиво различных символов.
CuneiformV12 под Wine на этом изображении распознал буквально пару слов. Пример не привожу.
2. Tesseract.
0005.JPG.tes.txt
(Оригинал)
Результат намного лучше, чем у Cuneiform. Верно распознано около 80% текста.
3. Finereader.
0005.jpg.fin.rtf
(Оригинал)
Неверных слов: 3 (в тексте 534 слова)
Неверных символов: 0
Ошибки форматирования: не распознал одну сноску и номер страницы.
Вывод: 99% точность. Отлично.
5МП без вспышки.
0006.JPG
1. Cuneiform.
0006.JPG.cun.rtf
(Оригинал)
Распознал около 20% текста, результат совершенно негодный.
2. Tesseract.
0006.JPG.tes.txt
(Оригинал)
Распознал около 30% текста.
3. Finereader.
0006.JPG.fin.rtf
(Оригинал)
Распознал около 95% текста.
О предварительной обработке изображения
Приведу простой пример того, что предварительная обработка изображения повысит качество распознавания (используем imagemagick для повышения констраста путем нормализации на предыдущем изображении):
Результат:
0006_2.JPG
1. Cuneiform.
0006_2.JPG.cun.rtf
(Оригинал)
2. Tesseract.
0006_2.JPG.tes.txt
(Оригинал)
Можете сами сравнить: сейчас результаты определенно лучше.
convert 'INPUT' -normalize 'OUTPUT'Результат:
0006_2.JPG
1. Cuneiform.
0006_2.JPG.cun.rtf
(Оригинал)
2. Tesseract.
0006_2.JPG.tes.txt
(Оригинал)
Можете сами сравнить: сейчас результаты определенно лучше.
2МП со вспышкой.
0007.JPG
1. Cuneiform.
0007.JPG.cun.rtf
(Оригинал)
Распознал несколько слов.
2. Tesseract.
0007.JPG.tes.txt
(Оригинал)
Распознал пару десятков слов.
3. Finereader.
0007.JPG.fin.rtf
(Оригинал)
И все равно Finereader показывает высший класс: распознано около 85% текста.
2МП без вспышки.
0008.JPG
1. Cuneiform.
0008.JPG.cun.rtf
(Оригинал)
Распознал пару десятков слов.
2. Tesseract.
0008.JPG.tes.txt
(Оригинал)
Распознал около 60% текста.
3. Finereader.
0008.JPG.fin.rtf
(Оригинал)
Распознал около 95% текста.
Вывод по образцу №3: здесь становится ясно, почему Finereader Engine имеет размер около 400 МБ: у него в комплекте с OCR есть алгоритмы обработки изображений, за счет чего при распознавании фотографий он дает неизменно хороший результат. Средствами же Cuneiform и Tesseract фотографии без хорошей предварительной обработки лучше не распознавать.
Образец №4 (распознавание таблиц и рисунков сканированного изображения).
Тест образца №4
Изображение:
0009.png
1. Cuneiform.
0009.png.cun.rtf
(Оригинал)
Вывод: не справился.
В то же время CuneiformV12 под Wine дает неплохой результат (потерял половину изображения, но справился с таблицей).
0009.cun.wine.rtf
(Оригинал)
2. Tesseract
Форматированный текст он, к сожалению, дать не может.
3. Finereader.
0009.png.fin.rtf
(Оригинал)
Когда я открыл этот документ во Writer'е — я очень удивился: таблицы не было (странно: различие реализации такого старого и простого формата, как RTF?..). Однако Word и Google Docs открыли этот RTF правильно.
Finereader отлично справился и с рисунком, и с таблицей.
Вывод по образцу №4: на первом месте Finereader, на втором — CuneiformV12 (нативный Cuneiform с задачей не справился).
0009.png
1. Cuneiform.
cuneiform -l ruseng -f rtf -o 'OUTPUT' 'INPUT'0009.png.cun.rtf
(Оригинал)
Вывод: не справился.
В то же время CuneiformV12 под Wine дает неплохой результат (потерял половину изображения, но справился с таблицей).
0009.cun.wine.rtf
(Оригинал)
2. Tesseract
Форматированный текст он, к сожалению, дать не может.
3. Finereader.
0009.png.fin.rtf
(Оригинал)
Когда я открыл этот документ во Writer'е — я очень удивился: таблицы не было (странно: различие реализации такого старого и простого формата, как RTF?..). Однако Word и Google Docs открыли этот RTF правильно.
Finereader отлично справился и с рисунком, и с таблицей.
Вывод по образцу №4: на первом месте Finereader, на втором — CuneiformV12 (нативный Cuneiform с задачей не справился).
Образец №5 (сканированный учебник “Металлические конструкции”).
Тест образца №5
0010.png
1. Cuneiform.
Результат:
0010.png.cun.rtf
(Оригинал)
Неверных слов: 17 (в тексте 310 слов)
Неверных символов: 12
Ошибки форматирования: не распознал тире, знаки параграфов и процентов. Проблемы с распознаванием “Й”. Ошибочно распознал курсив.
Вывод: 95% слов. Выглядит не очень.
Версия, распознанная с помощью CuneiformV12:
0010.cun.win.rtf
(Оригинал)
Качество явно выше, чем у нативной версии.
2. Tesseract.
Результат:
0010.png.tes.txt
(Оригинал)
Неверных слов: 8 (в тексте 310 слов)
Неверных символов: 15
Ошибки форматирования: проблемы с распознаванием “Й”.
Вывод: 97% слов. Лучше, чем у cuneiform.
3. Finereader.
Результат:
0010.png.fin.rtf
(Оригинал)
Неверных слов: 0 (в тексте 310 слов)
Неверных символов: 5
Ошибки форматирования: проблемы с капитализацией символов.
Вывод: 100% слов. Лучший результат.
0012.png
1. Cuneiform.
0012.png.cun.rtf
(Оригинал)
В отличие от предыдущего результата, появились больше “Й” и римские цифры. Для части слов распознавание улучшилось, однако вместе с тем появились и новые ошибки и лишние символы.
Вывод: ошибок меньше не стало.
2. Tesseract.
0012.png.tes.txt
(Оригинал)
Вывод: ситуация как и в случае с Cuneiform: ошибок меньше не стало.
3. Finereader.
0012.png.fin.rtf
(Оригинал)
Вывод: ничего не изменилось.
0011.png
И Cuneiform, и Tesseract показали снижение качества распознавания, как и в случае с англоязычным образцом. Примеры не привожу (можете проверить сами).
Вывод по образцу №5: подтвердилось наблюдение о том, что использование изображения качеством более, чем 200 dpi, не приводит к улучшению результата.
Первое место занимает Finereader, второе — Tesseract, третье — Cuneiform (причем под Wine он работает лучше).
200dpi.
0010.png
1. Cuneiform.
cuneiform -l ruseng -f rtf --singlecolumn -o 'OUTPUT' 'INPUT'Результат:
0010.png.cun.rtf
(Оригинал)
Неверных слов: 17 (в тексте 310 слов)
Неверных символов: 12
Ошибки форматирования: не распознал тире, знаки параграфов и процентов. Проблемы с распознаванием “Й”. Ошибочно распознал курсив.
Вывод: 95% слов. Выглядит не очень.
Версия, распознанная с помощью CuneiformV12:
0010.cun.win.rtf
(Оригинал)
Качество явно выше, чем у нативной версии.
2. Tesseract.
tesseract 'INPUT' 'OUTPUT' -l rus -psm 6Результат:
0010.png.tes.txt
(Оригинал)
Неверных слов: 8 (в тексте 310 слов)
Неверных символов: 15
Ошибки форматирования: проблемы с распознаванием “Й”.
Вывод: 97% слов. Лучше, чем у cuneiform.
3. Finereader.
sudo abbyyocr9 -rl Russian English -if 'INPUT' -f RTF -of 'OUTPUT' Результат:
0010.png.fin.rtf
(Оригинал)
Неверных слов: 0 (в тексте 310 слов)
Неверных символов: 5
Ошибки форматирования: проблемы с капитализацией символов.
Вывод: 100% слов. Лучший результат.
300dpi.
0012.png
1. Cuneiform.
0012.png.cun.rtf
(Оригинал)
В отличие от предыдущего результата, появились больше “Й” и римские цифры. Для части слов распознавание улучшилось, однако вместе с тем появились и новые ошибки и лишние символы.
Вывод: ошибок меньше не стало.
2. Tesseract.
0012.png.tes.txt
(Оригинал)
Вывод: ситуация как и в случае с Cuneiform: ошибок меньше не стало.
3. Finereader.
0012.png.fin.rtf
(Оригинал)
Вывод: ничего не изменилось.
600dpi.
0011.png
И Cuneiform, и Tesseract показали снижение качества распознавания, как и в случае с англоязычным образцом. Примеры не привожу (можете проверить сами).
Вывод по образцу №5: подтвердилось наблюдение о том, что использование изображения качеством более, чем 200 dpi, не приводит к улучшению результата.
Первое место занимает Finereader, второе — Tesseract, третье — Cuneiform (причем под Wine он работает лучше).
Образец №6 (сканированная страница рассказа О'Генри).
Тест образца №6
0013.png
1. Cuneiform.
0013.png.cun.rtf
(Оригинал)
Неверных слов: 28 (в тексте 316 слов)
Неверных символов: множество.
Ошибки форматирования: ошибочный курсив.
Вывод: 91% слов, очень много ошибок, что неприемлимо для такого образца
И версия, распознанная с помощью CuneiformV12:
0013.cun.win.rtf
(Оригинал)
Неверных слов: 15 (в тексте 316 слов)
Неверных символов: несколько.
Ошибки форматирования: нету.
Вывод: 95% слов, результат лучше, чем у нативной версии.
2. Tesseract.
0013.png.tes.txt
(Оригинал)
Неверных слов: 30 (в тексте 316 слов)
Неверных символов: множество.
Ошибки форматирования: лишние символы.
Вывод: 90% слов, плохо.
3. Finereader.
0013.png.fin.rtf
(Оригинал)
Неверных слов: 3 (в тексте 316 слов)
Неверных символов: нету.
Ошибки форматирования: нету.
Вывод: 99% слов.
Вывод по образцу №6: у Cuneiform и Tesseract замечены однотипные ошибки распознавания букв «и»,«н» и «п» из шрифта образца.
Первое место — Finereader, второе — Cuneiform под Wine (нативный Cuneiform сработал хуже), третье — Tesseract.
200dpi.
0013.png
1. Cuneiform.
0013.png.cun.rtf
(Оригинал)
Неверных слов: 28 (в тексте 316 слов)
Неверных символов: множество.
Ошибки форматирования: ошибочный курсив.
Вывод: 91% слов, очень много ошибок, что неприемлимо для такого образца
И версия, распознанная с помощью CuneiformV12:
0013.cun.win.rtf
(Оригинал)
Неверных слов: 15 (в тексте 316 слов)
Неверных символов: несколько.
Ошибки форматирования: нету.
Вывод: 95% слов, результат лучше, чем у нативной версии.
2. Tesseract.
0013.png.tes.txt
(Оригинал)
Неверных слов: 30 (в тексте 316 слов)
Неверных символов: множество.
Ошибки форматирования: лишние символы.
Вывод: 90% слов, плохо.
3. Finereader.
0013.png.fin.rtf
(Оригинал)
Неверных слов: 3 (в тексте 316 слов)
Неверных символов: нету.
Ошибки форматирования: нету.
Вывод: 99% слов.
Вывод по образцу №6: у Cuneiform и Tesseract замечены однотипные ошибки распознавания букв «и»,«н» и «п» из шрифта образца.
Первое место — Finereader, второе — Cuneiform под Wine (нативный Cuneiform сработал хуже), третье — Tesseract.
Образец №7 (сканированная страница книги «Момент истины»).
Тест образца №7
0014.png
1. Cuneiform.
0014.png.cun.rtf
(Оригинал)
Неверных слов: 11 (в тексте 323 слова)
Неверных символов: упорно не распознает дефисы и тире.
Ошибки форматирования: ошибочный курсив.
Вывод: 91% слов, плохо.
И версия, распознанная с помощью CuneiformV12:
0014.cun.win.rtf
(Оригинал)
Неверных слов: 1 (в тексте 323 слова)
Неверных символов: 1.
Ошибки форматирования: нету.
Вывод: 99% слов, отлично.
2. Tesseract.
0014.png.tes.txt
(Оригинал)
Неверных слов: процентов 30.
Неверных символов: множество.
Ошибки форматирования: лишние символы.
Вывод: отвратительно.
3. Finereader.
0014.png.fin.rtf
(Оригинал)
Неверных слов: 0 (в тексте 323 слова)
Неверных символов: нету.
Ошибки форматирования: нету.
Вывод: 100% слов. Идеально.
Вывод по образцу №7: Первое место — Finereader, второе — Cuneiform под Wine (нативный Cuneiform сработал гораздо хуже), третье — Tesseract (результат бесполезно даже корректировать).
200dpi.
0014.png
1. Cuneiform.
0014.png.cun.rtf
(Оригинал)
Неверных слов: 11 (в тексте 323 слова)
Неверных символов: упорно не распознает дефисы и тире.
Ошибки форматирования: ошибочный курсив.
Вывод: 91% слов, плохо.
И версия, распознанная с помощью CuneiformV12:
0014.cun.win.rtf
(Оригинал)
Неверных слов: 1 (в тексте 323 слова)
Неверных символов: 1.
Ошибки форматирования: нету.
Вывод: 99% слов, отлично.
2. Tesseract.
0014.png.tes.txt
(Оригинал)
Неверных слов: процентов 30.
Неверных символов: множество.
Ошибки форматирования: лишние символы.
Вывод: отвратительно.
3. Finereader.
0014.png.fin.rtf
(Оригинал)
Неверных слов: 0 (в тексте 323 слова)
Неверных символов: нету.
Ошибки форматирования: нету.
Вывод: 100% слов. Идеально.
Вывод по образцу №7: Первое место — Finereader, второе — Cuneiform под Wine (нативный Cuneiform сработал гораздо хуже), третье — Tesseract (результат бесполезно даже корректировать).
Образец №8 (Панграмма с разными шрифтами).
Тест образца №8
Наконец, последний тест, который выявит зависимость OCR от шрифта (оригинал отпечатан на струйном принтере со средним качеством).
В этом примере для наглядности я при необходимости откорректирую абзацы и наименования шрифтов.
0015.png
1. Cuneiform.
Русский текст:
0015_rus.png.cun.txt
(Оригинал)
Без ошибок (не считая злосчастного дефиса) распознаны только Arial и Trebuchet MS.
Английский текст:
0015_eng.png.cun.txt
(Оригинал)
Ошибки только в Courier New и ISOCPEUR.
CuneiformV12:
Русский текст:
0015_rus.wine.cun.txt
(Оригинал)
Без ошибок распознаны Sans-serif, Arial, Courier New, DejaVu Sans, DejaVu Serif, Palladio Uralic, Trebuchet MS, Verdana.
Разница по сравнению с портированным Cuneiform налицо.
Английский текст:
0015_eng.wine.cun.txt
(Оригинал)
Внезапно ошибок раза в три больше, чем в нативной версии.
2. Tesseract.
Русский текст:
0015_rus.png.tes.txt
(Оригинал)
Ошибки (опять же, не считая проблем с дефисами) есть только в Palladio Uralic, Verdana и ISOCPEUR.
Английский текст:
0015_eng.png.tes.txt
(Оригинал)
Ошибок нет.
Вывод по образцу №8: С русским лучше всего отработали CuneiformV12 (под Wine) и Tesseract. С английским без ошибок справился Tesseract.
В этом примере для наглядности я при необходимости откорректирую абзацы и наименования шрифтов.
200dpi.
0015.png
1. Cuneiform.
Русский текст:
0015_rus.png.cun.txt
(Оригинал)
Без ошибок (не считая злосчастного дефиса) распознаны только Arial и Trebuchet MS.
Английский текст:
0015_eng.png.cun.txt
(Оригинал)
Ошибки только в Courier New и ISOCPEUR.
CuneiformV12:
Русский текст:
0015_rus.wine.cun.txt
(Оригинал)
Без ошибок распознаны Sans-serif, Arial, Courier New, DejaVu Sans, DejaVu Serif, Palladio Uralic, Trebuchet MS, Verdana.
Разница по сравнению с портированным Cuneiform налицо.
Английский текст:
0015_eng.wine.cun.txt
(Оригинал)
Внезапно ошибок раза в три больше, чем в нативной версии.
2. Tesseract.
Русский текст:
0015_rus.png.tes.txt
(Оригинал)
Ошибки (опять же, не считая проблем с дефисами) есть только в Palladio Uralic, Verdana и ISOCPEUR.
Английский текст:
0015_eng.png.tes.txt
(Оригинал)
Ошибок нет.
Вывод по образцу №8: С русским лучше всего отработали CuneiformV12 (под Wine) и Tesseract. С английским без ошибок справился Tesseract.
GUI для Linux.
*GUI – graphical user interface – интерфейс графический (“окошки и кнопочки”).
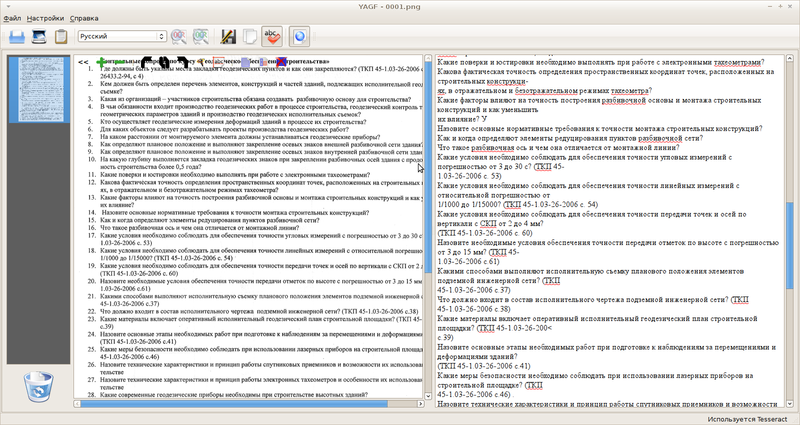
Yagf
Официальная страница.
Зависимости при сборке: libaspell-dev и libqt4-dev не ниже версии 4.5. Для запуска необходимы Qt 4.5 и aspell (см. документацию, поставляемую с исходниками).
Установка (начинаем в директории с исходниками):
mkdir builddir
cd build dir
cmake ../
make
sudo checkinstall
Yagf хорошо локализован, может получать изображение из буфера обмена, из файла, со сканера, импортировать pdf, позволяет выравнивать изображение.
В настройках Yagf можно переключаться между Tesseract и Cuneiform. Yagf может производить пакетное распознавание (все импортированные изображения) или распознавание конкретной текстовой области.
Единственным существенным минусом я считаю невозможность задания дополнительных параметров для движков сканирования, т.е. аналогично командной строке (рассмотренный ниже OCRFeeder лишен этого недостатка).
Cuneiform-Qt
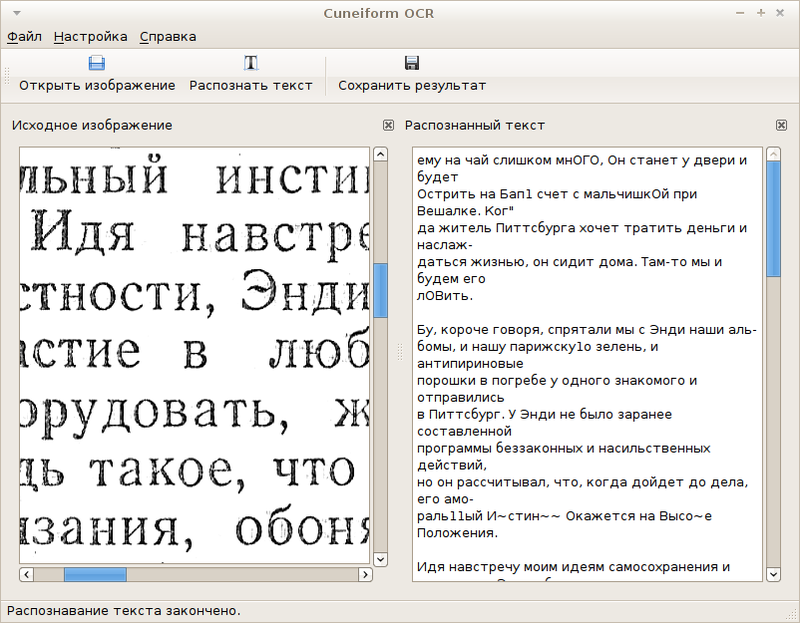
Проект начал и окончил свою активную жизнь в апреле 2009-го года в рамках проекта Altlinux. Cuneiform-Qt предоставляет простой GUI для Cuneiform.
Поскольку ничего особого я от этого GUI не ожидал, то решил ограничиться установкой готового пакета версии 0.1.1-1 (последняя версия исходников 0.1.2 – разработка ушла недалеко).
GUI, кстати, оказался очень интересным – при сохранении в RTF распознаваемый текст превратился в повторяющуюся сотни раз последовательность нескольких латинских символов, расположенных в столбец шириной в одну букву. В обычный текстовый файл сохранение проходит нормально.
Делаем вывод: этот GUI бесполезен.
KBookOCR
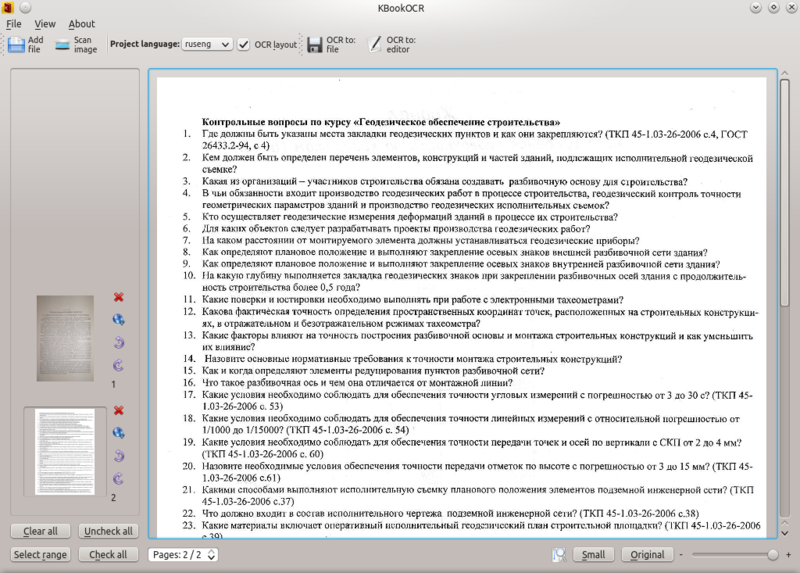
Это анонсировавшийся на хабре “убийца Finereader'а”, являющийся надстройкой над Cuneiform.
Официальный блог автора.
Deb-пакет.
К сожалению, в зависимостях тянет за собой кусок KDE. Запланированная более года назад версия 2.2 предполагает поддержку Tesseract, однако подвижек похоже нету.
Для обзора я использовал Kubuntu 12.04 в Virtualbox.
Версия 2.1 этой софтины умеет получать изображение из файла или путем сканирования, выводить полученный результат в html или открыть в текстовом редакторе. Выделять блоки для распознавания KBookOcr, в отличие от Yagf, не умеет.
Вывод: KBookOcr проигрывает Yagf по функционалу да и предназначен только для KDE.
OCRFeeder

GUI для Cuneiform, Tesseract и пары других OCR, русский язык не поддерживающих. В deb-пакетах представлены только очень старые версии, поэтому будем собирать из исходного кода.
Сразу появляется раздражение: Readme написан к версии 0.3, текущая версия – 0.7.1. Структура файлов изменилась, никакого требуемого setup.py нету. Зато есть ./confugure
Зависимости:
sudo apt-get install python-pygoocanvas ocrad unpaper python-gtkspell python-enchant sane python-imaging-sane
Далее оказывается, что:
Your intltool is too old. You need intltool 0.35.0 or later.
По умолчанию установлен старый пакет intltool-debian: ставим из репозитория пакет intltool версии 0.41.
Собираем:
./confugure
make
sudo checkinstall
Набор функций стандартный: открыть/сканировать, сохранить/открыть в редакторе. Есть несколько бонусов: поддерживается unpaper, настройки движка распознавания позволяют передать ему в текстовом виде любые поддерживаемые параметры (к примеру, выбор языка распознавания производится именно так); можно выделять текстовые блоки.
Ocropus
http://code.google.com/p/ocropus/ — то ли GUI, то CLI для Tesseract.
Следуя инструкции, попытался собрать последнюю версию, однако python сказал в отношении какой-то строки исходников:
SyntaxError: invalid syntaxВ код лезть не хочется, делаю вывод, что продукт скорее мёртв, чем жив.
gImageReader

GUI для Tesseract.
Берем deb-пакет отсюда.
gImageReader максимально прост: позволяет открыть изображение, подкорректировать на ходу яркость и контраст и распознать текстовую область или все сразу.
Tesseract-gui
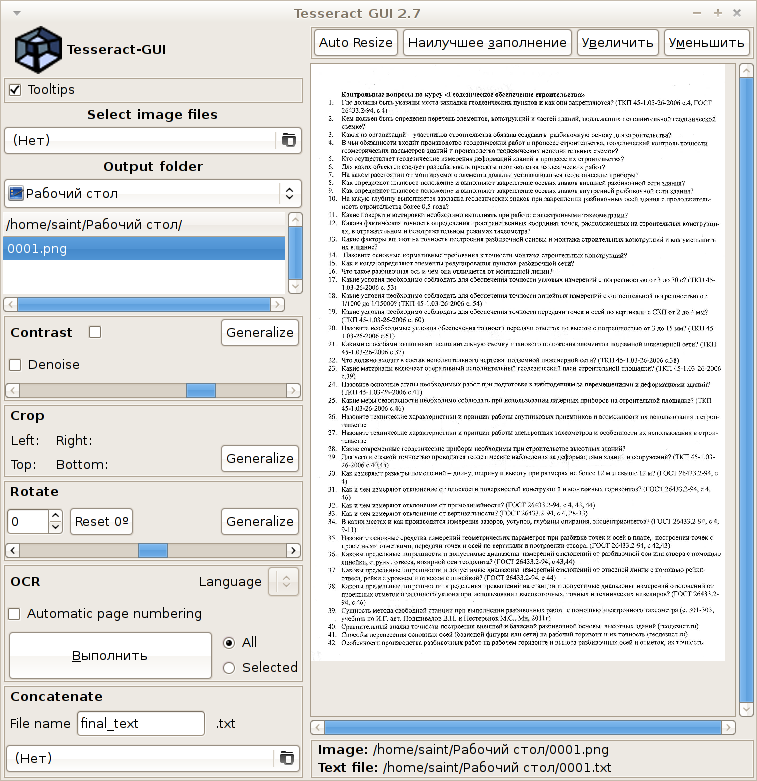
Страница проекта.
Пакеты лежат здесь.
У меня распознавать что-либо отказался.
Вывод о GUI:
Единственным реальным плюсом представленных GUI может быть функция распознавания отдельных текстовых блоков (некоторые не могут и этого).
Поэтому я считаю, что существующие GUI для OCR в Linux не функциональны. Если уж выбирать среди них, то по сути единственными приемлемыми окажутся только два: Yagf и OCRFeeder. При этом, Yagf сообществом используется и упоминается гораздо чаще.
Пробуйте и оставляйте свои впечатления.
Тест online-OCR
Небольшой список online-OCR.
Online OCR очень много, и, в принципе, все они реализованы на трех вышеперечисленных движках: Cuneiform, Tesseract и Finereader.
Поскольку данные OCR подпадают под тему этой статьи, рассмотрим пару из них, заодно сделаем интересные выводы.
1. Finereader Online.
finereader.abbyyonline.com/ru
Явно базируется на Finereader Engine 9 (а, может, и 10?) Пробовать не стал, уверен в высоком качестве.
Позволяет бесплатно распознать 10 страниц в сутки.
2. New OCR.
www.newocr.com
Бесплатен, не требует регистрации и не имеет ограничений.
Очень интересный ресурс, который позволит сделать выводы о конечной применимости Cuneiform и Tesseract. Загрузим изображения, с которыми у этих двух систем возникли проблемы, и посмотрим на результат.
Образец №3, 5МП без вспышки
Распознавание с помощью Cuneiform:
0006.cun.newocr.txt
(Оригинал)
Распознавание с помощью Tesseract:
0006.tes.newocr.txt
(Оригинал)
Результаты онлайн-распознавания очевидно лучше.
Образец №7
Распознавание с помощью Cuneiform:
0014.cun.newocr.txt
(Оригинал)
Не хватает дефисов и тире, однако в словах только 2 ошибки. Отличный результат.
Распознавание с помощью Tesseract:
0014.tes.newocr.txt
(Оригинал)
6 ошибок в словах, несколько лишних символов — но Tesseract у меня на этом изображении не смог распознать нормальный текст. Пожалуй, самый интересный результат теста.
Вот отличный пример использования свободных OCR: создатели сайта явно применили предварительную обработку изображения и (возможно) постобработку текста (корректировка с помощью словарей или что-то подобное). И в таком виде свободные OCR уже могут конкурировать с Finereader'ом.
Заключение
Мы рассмотрели три системы OCR, умеющие работать с русским и английским языками.
Без сомнения, лучший результат показал FineReader Engine v9.0. Он великолепно распознает как сканированные, так и сфотографированные изображения. Однако, минимальная стоимость его составляет 149€ за лицензию на 12000 распознаваний в год — надо ли вам это?
Свободные OCR: Cuneiform и Tesseract — сами по себе могут адекватно обрабатывать только отсканированные изображения с равномерно распределенной по полю яркостью и высоким контрастом.
С англоязычным образцом неплохо справились оба этих движка, тогда как с русским текстом возникали проблемы — вообще, по ходу теста выяснилось, что результаты работы свободных OCR «плавают» от образца к образцу.
При этом CuneiformV12, запущенный под Wine, с русскими текстами справился лучше, чем нативная версия под Linux.
Интересным оказался тот факт, что на рассмотренных образцах оптимальным качеством изображения было 200 dpi — при большем количестве точек на дюйм начиналось ухудшение качества распознавания.
GUI для Cuneiform и Tesseract создано много, но они не приносят реальной пользы.
На примере FineReader и онлайн-системы New OCR отлично видно, что нормальный функциональный OCR должен обязательно существовать в совокупности с системой предварительной обработки изображений и системой постобработки текста, основанной на словарном контроле результатов.
При этом данная технология для свободных движков уже фактически реализована (у New OCR распознавание происходит весьма качественно).
Достаточно поделиться такой технологией либо реализовать её самим — и свободные OCR будут стоять на одном уровне с продуктами ABBYY — после этого можно говорить о написании хорошего GUI.
Подытожу: свободные OCR не дают стабильного результата даже на отсканированных изображениях, Finereader стоит денег — простому пользователю проще пользоваться онлайн-сервисами.
Ну а если вы собираетесь использовать OCR в других масштабах — тут другой разговор: придется платить или тратить время на корректировку результатов вручную.
P.S. Если у вас есть готовые наработки или скрипты по подготовке изображения к распознаванию — делитесь в комментариях. Всем будет интересно и полезно.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}