Компания Adapteva (про которую вы скорее всего слышите в первый раз) планирует сделать суперкомпьютер который будет доступен каждому. С 2008 года они занимаются разработками энергоэффективных RISC-процессоров по заказам производителей смартфонов и других мобильных устройств.
«Мы идем вниз по пищевой цепочке», говорит CEO и основатель Andreas Olofsson. Но Adapteva хочет дать свои технологии напрямую людям через проект на Кикстартере, если они соберут как минимум $750K с конечной целью в $3M.
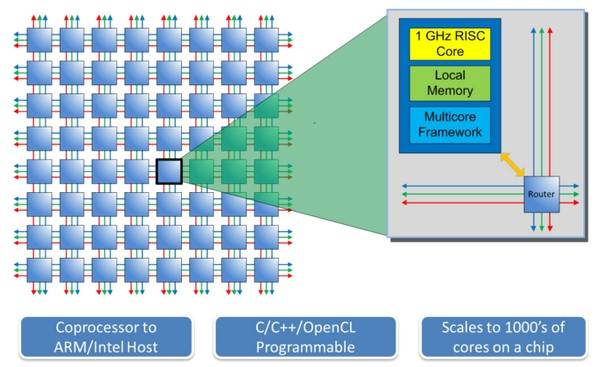
Adapteva называет свой проект “Parallella: A Supercomputer For Everyone”, который представляет собой плату 16-ядерным процессором с суммарной частотой всех ядер 16GHz, производительностью 26 GFLOPS и ценой $99. Если они достигнут цели в $3M, то сделают плату с 64-ядерным процессором (45GHz и 90 GFLOPS) за $199. (Adapteva считает частоту и производительность как сумму по всем ядрам процессора). Обе платы включают в себя так же двухядерный ARM A9 SoC с 16- или 64- ядерным RISC-процессором который выступает как сопроцессор к основному. Adapteva утверждает, что они добились энергоэффективности 70 GFLOPS на ватт и 25 GHz на ватт соответсвенно.
Обещаные сроки поставки (при условии сбора $750K) — Май 2013 для 16-ядерной версии.
Устройство будет предствлять собой полность работающий компьютер с Ubuntu 11.10 ARM, 1GB RAM, двумя портами USB 2.0, 16GB MicroSD картой, HDMI и Gigabit Ethernet'ом. Open source SDK будет поддерживать C, C++ и OpenCL. Размером устройство будет примерно 8.5 x 5.5 см (размером с Raspberry Pi).
Есть большое сходство между Parallella и проектами подобными Raspberry Pi (компьютеру с линукс за $35, и ардуино за $30), но Olofsson утверждает, что Parallella будет от 10 до 50 раз быстрее, чем Raspberry Pi (если сравнивать с 64-ядерной версией) и при этом только в 3 раза дороже. Он замечает, что с ценой $99 это сильно дешевле, чем большинство текущих платформ для параллельных вычислений. Платы, содержащие процессоры Adapteva, который продают их партнеры сейчас стоят от нескольких тысяч долларов.
В качестве сферы применения Olofsson называет разработку мобильных и встраиваемых систем, создание новых языков программирования, иследование параллельных алгоритмов и тд. «То, что люди могут сделать с Parallella ничем не ограничено» — говорит он. «Мы надеемся, что их будут использовать работающие на open source проектами энтузиасты которым сегодня не хватает платформы такого типа для удовлетворения их потребностей».
В дополнение к энтузиастам и разработчикам Olofsson надеется, что параллельные вычисления широко распространятся среди обычных фирм. «Сегодня существует пропасть между исследователями и обычным бизнесом», говорит он. «Я знаю, что в конце концов параллельные вычисления станут повсеместными, это всего лишь вопрос времени, но я предпочел бы что бы это случилось сейчас, а не через три года ».
Определение «суперкомпьютера» представляется несколько туманными. Самый медленный суперкомпьютер в top-500 дает 61 TFLOPS. Кластер из сотни 16-ядерных Parallellas будет стоить $10000 и обеспечивать 10 TFLOPS, сказал он. Даже если это не суперкомпьютер, то он может быть полезным для очень многих людей.
Adapteva говорит, что им необходимо собрать $3M через Kickstarter, чтобы начать производство 64-ядерной версии Parallella. В то время как 16-ядерный чип производится с использованием 65-нанометрового процесса, 64-ядерный чип будет производится с использованием более сложного и дорогого 28-нанометрового процесса.
Kickstarter недавно начал отказывать разработчикам железа, говоря: «Kickstarter это не магазин». Но Adapteva сумел их убедить, что они не являются обычными розничным торговцами.
Но почему Adapteva вообще пошел на Kickstarter? Компания привлекла $ 2,5 млн венчурного капитала, но Олофссон говорит, что это «очень мало для разработчика электроники.… Наш исследовательский бюджет вероятно 1/1000 от такого в Intel. Чтобы осуществить этот проект, нам нужны миллионы долларов. Мы говорили, с венчурными капиталистами, но для них модель „железного“ стартапа больше не работает. Они не получают хорошую отдачу от инвестиций ».
Несмотря на то, что Parallella основана на существующих процессорах, сбор денег является единственным способом получить цену в $99, и они происходят от затрат на производство на заводе Global Foundries. И такая небольшая цена является ключом к успеху проекта, говорит Olofsson.
Оригинал
Обсуждение на slashdot
Теперь несколько слов от себя:
Если, они сделают то, что они хотят, то это будет действительно прорывом в деле выхода на широкий рынок многопроцессорных систем. В отличии от GPGPU (NVidia CUDA и тд), которые являются в большей части SIMD, эта штука действительно MIMD и каждое ядро может выполнять полностью независимый код от других ядер. Я думаю, что с появлением Project Glass от google появится сильная потребность в железках такого рода например для обработки изображения в реализации дополненной реальности.
Да, пока они проигрывают по производительности видеокартам, но при этом их чип ест 2(!) ватта. Характеристики одного узла процессора (собрано из разных частей документации):
Но главным их отличием является то, что их архитектура, тулчейны, библиотеки и API полностью OpenSource (привет NVIdia с твоими бинарными драйверами и архитектурой под NDA).
Ну и даже если абстрагироваться от сего чипа, то имхо сам по себе development board с ARM A9 за $99 более чем нормально.
UPD:
Результаты опроса на кикстартере по поводу возможных сфер применения
К вопросу о том, что оно сильно слабее видеокарты:
В варианте с одним чипом — да, но авторы добавили варианты MINI-CLOUD($495) и CLUSTER ($975). За эту цену они обещают решение из четырех / восьми плат (72 / 144 процессора (именно процессора, а не ядер как я понял)), гигабитный коммутатор и источник питания.
«Мы идем вниз по пищевой цепочке», говорит CEO и основатель Andreas Olofsson. Но Adapteva хочет дать свои технологии напрямую людям через проект на Кикстартере, если они соберут как минимум $750K с конечной целью в $3M.
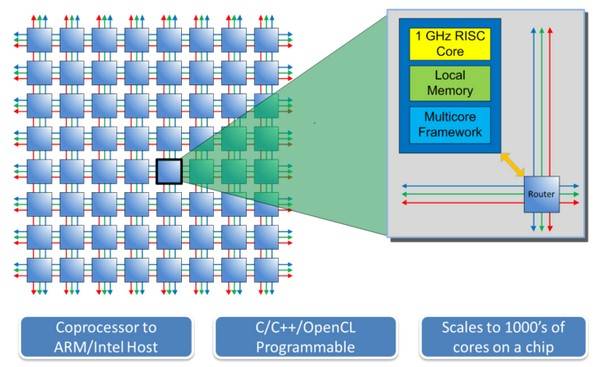
Adapteva называет свой проект “Parallella: A Supercomputer For Everyone”, который представляет собой плату 16-ядерным процессором с суммарной частотой всех ядер 16GHz, производительностью 26 GFLOPS и ценой $99. Если они достигнут цели в $3M, то сделают плату с 64-ядерным процессором (45GHz и 90 GFLOPS) за $199. (Adapteva считает частоту и производительность как сумму по всем ядрам процессора). Обе платы включают в себя так же двухядерный ARM A9 SoC с 16- или 64- ядерным RISC-процессором который выступает как сопроцессор к основному. Adapteva утверждает, что они добились энергоэффективности 70 GFLOPS на ватт и 25 GHz на ватт соответсвенно.
Обещаные сроки поставки (при условии сбора $750K) — Май 2013 для 16-ядерной версии.
Устройство будет предствлять собой полность работающий компьютер с Ubuntu 11.10 ARM, 1GB RAM, двумя портами USB 2.0, 16GB MicroSD картой, HDMI и Gigabit Ethernet'ом. Open source SDK будет поддерживать C, C++ и OpenCL. Размером устройство будет примерно 8.5 x 5.5 см (размером с Raspberry Pi).
Есть большое сходство между Parallella и проектами подобными Raspberry Pi (компьютеру с линукс за $35, и ардуино за $30), но Olofsson утверждает, что Parallella будет от 10 до 50 раз быстрее, чем Raspberry Pi (если сравнивать с 64-ядерной версией) и при этом только в 3 раза дороже. Он замечает, что с ценой $99 это сильно дешевле, чем большинство текущих платформ для параллельных вычислений. Платы, содержащие процессоры Adapteva, который продают их партнеры сейчас стоят от нескольких тысяч долларов.
В качестве сферы применения Olofsson называет разработку мобильных и встраиваемых систем, создание новых языков программирования, иследование параллельных алгоритмов и тд. «То, что люди могут сделать с Parallella ничем не ограничено» — говорит он. «Мы надеемся, что их будут использовать работающие на open source проектами энтузиасты которым сегодня не хватает платформы такого типа для удовлетворения их потребностей».
В дополнение к энтузиастам и разработчикам Olofsson надеется, что параллельные вычисления широко распространятся среди обычных фирм. «Сегодня существует пропасть между исследователями и обычным бизнесом», говорит он. «Я знаю, что в конце концов параллельные вычисления станут повсеместными, это всего лишь вопрос времени, но я предпочел бы что бы это случилось сейчас, а не через три года ».
Определение «суперкомпьютера» представляется несколько туманными. Самый медленный суперкомпьютер в top-500 дает 61 TFLOPS. Кластер из сотни 16-ядерных Parallellas будет стоить $10000 и обеспечивать 10 TFLOPS, сказал он. Даже если это не суперкомпьютер, то он может быть полезным для очень многих людей.
Adapteva говорит, что им необходимо собрать $3M через Kickstarter, чтобы начать производство 64-ядерной версии Parallella. В то время как 16-ядерный чип производится с использованием 65-нанометрового процесса, 64-ядерный чип будет производится с использованием более сложного и дорогого 28-нанометрового процесса.
Kickstarter недавно начал отказывать разработчикам железа, говоря: «Kickstarter это не магазин». Но Adapteva сумел их убедить, что они не являются обычными розничным торговцами.
Но почему Adapteva вообще пошел на Kickstarter? Компания привлекла $ 2,5 млн венчурного капитала, но Олофссон говорит, что это «очень мало для разработчика электроники.… Наш исследовательский бюджет вероятно 1/1000 от такого в Intel. Чтобы осуществить этот проект, нам нужны миллионы долларов. Мы говорили, с венчурными капиталистами, но для них модель „железного“ стартапа больше не работает. Они не получают хорошую отдачу от инвестиций ».
Несмотря на то, что Parallella основана на существующих процессорах, сбор денег является единственным способом получить цену в $99, и они происходят от затрат на производство на заводе Global Foundries. И такая небольшая цена является ключом к успеху проекта, говорит Olofsson.
Оригинал
Обсуждение на slashdot
Теперь несколько слов от себя:
Если, они сделают то, что они хотят, то это будет действительно прорывом в деле выхода на широкий рынок многопроцессорных систем. В отличии от GPGPU (NVidia CUDA и тд), которые являются в большей части SIMD, эта штука действительно MIMD и каждое ядро может выполнять полностью независимый код от других ядер. Я думаю, что с появлением Project Glass от google появится сильная потребность в железках такого рода например для обработки изображения в реализации дополненной реальности.
Да, пока они проигрывают по производительности видеокартам, но при этом их чип ест 2(!) ватта. Характеристики одного узла процессора (собрано из разных частей документации):
- 32-bit single-precision floating point only (no double-precision)
- Core local store global-addressable on 32-bit flat address space; can R/W outside address space with proper address mapping support
- 32KB local store on each core, 32 GB/s @ 1 GHz
- External interface 2 GB/s * 4 (four directions) = max 8 GB/s
- Fetch instruction from global address space
- Fast inter-core write, slow read requests (1 for each 8 cycles)
Но главным их отличием является то, что их архитектура, тулчейны, библиотеки и API полностью OpenSource (привет NVIdia с твоими бинарными драйверами и архитектурой под NDA).
Ну и даже если абстрагироваться от сего чипа, то имхо сам по себе development board с ARM A9 за $99 более чем нормально.
UPD:
Результаты опроса на кикстартере по поводу возможных сфер применения
К вопросу о том, что оно сильно слабее видеокарты:
В варианте с одним чипом — да, но авторы добавили варианты MINI-CLOUD($495) и CLUSTER ($975). За эту цену они обещают решение из четырех / восьми плат (72 / 144 процессора (именно процессора, а не ядер как я понял)), гигабитный коммутатор и источник питания.
