Доброго времени суток, уважаемые!
В последнее время, читая различные статьи в хабре, всё больше стал замечать, что многие авторы до сих пор ничего не знают о ISO/IEC стандартах бинарных префиксов (KiB=кибибайт, MiB=мебибайт и т.д.) и постоянно путают их с SI префиксами (kB=килобайт, MB=мегабайт). Поэтому я решил ещё раз заговорить об этом в надежде, что, прочитав статью, ещё пара человек начнёт пользоваться стандартами!
Отступив от темы, хочу сказать, что, честно говоря, из-за отсутствия времени я никогда не собирался писать статью для хабра. Мне всегда было достаточно read-only account'a, чтоб спокойно читать интересные для меня статьи и иногда комментировать ВКонтакте (да-да, и там есть довольно много адекватов!). Но соринка в глазу начинала превращаться в бревно, так что я всё-таки пожертвовал одну ночь для написания этой статьи.
Ещё в далёком 1999 году IEC (International Electrotechnical Commission) принял международный стандарт IEC60027-2 [IEC60027-2:2005, ISO/IEC80000-13:2008].
Путём публикаций в различных научных журналах о новом стандарте узнал мир.

С того времени прошло уже больше 13 лет, но к сожалению из-за укоренившегося в сознании старшего поколения неправильного применения SI префиксов для написания размеров данных, путаница не только до сих пор процветает даже в технической литературе, но и передаётся дальше молодому поколению.
Давайте разберёмся в чём же дело!
SI (Le Système International d’Unités) — интернациональная система единиц, которая описывает не только единицы физических величин, но также дефинирует так называемые стандартные префиксы:
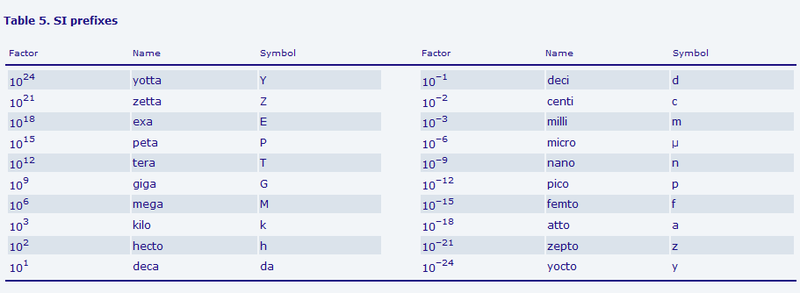
Как мы видим, основная система счисления в SI – десятичная, т.е. по основанию 10.
В информационной технологии используется, однако, двоичная система счисления, т.е. по основанию 2. Удобства ради, кто-то решил использовать приставку кило также и для единиц информации.
При этом значение кило было выхвачено из СИ, и то ли по незнанию, то ли по злому умыслу было
Соглашусь, что разница небольшая и в эпоху
640K ought to be enough for anybodyэто никого особо не напрягало, но именно здесь был открыт ящик Пандоры.
(кстати, К – это аббревиатура для единицы температуры — кельвин, и в этом смысле 640 кельвин, что примерно равно +367 градусам цельсия, для any body точно enough)
С развитием информационных технологий появлялись всё большие величины и путаница становилась всё больше и больше:
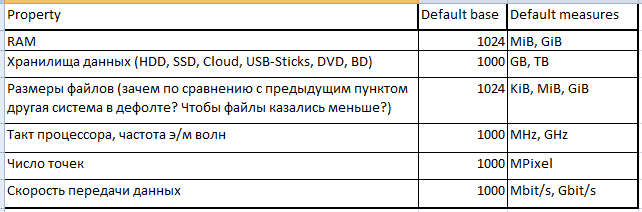
• Кто-то использовал кило, мега, гига и т.д. подразумевая 1024x (например: 1MB=1024x1024 B)
• Кто-то использовал кило, мега, гига и т.д. подразумевая 1000x (например: 1MB=1000x1000 B)
• Кто-то начал использовать и то, и другое в одной системе (например: 1МB=1024x1024 B, но одновременно 1Mbit/s = 1000x1000 bit/s)
• Кто-то начал выдумывать что-то типа KByte, MByte, GByte и т.д. подразумевая 1024x
• Иногда умудрялись смешивать всё даже в одной цифре: так при размере дискеты считалось, что 1MB=1000x1024 B
• … вариантов становилось всё больше
А в чём же проблема, спросите Вы?
Простой пример:
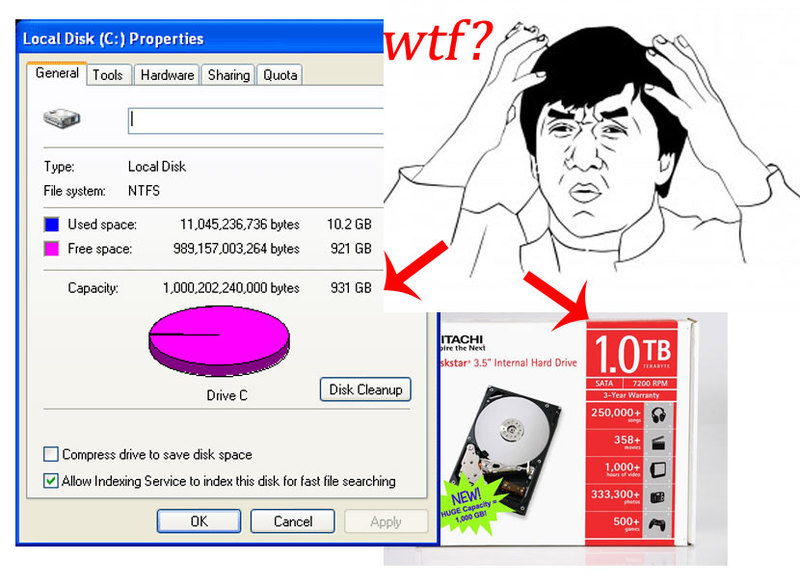
Вы покупаете жёсткий диск, на котором написано 2TB.
Приносите домой, подключаете к компьютеру с Windows, и, ещё даже не успев отформатировать, видите размер 1,82 TB.
«Накололи», — думаете Вы! Причем на целых 181 GB! А это ведь
Что делать? Кто наколол?
Если посмотреть объективно – наколол Вас Windows, точнее Microsoft (
Почему они это делают?
Я спрашивал у одного ведущего сотрудника Microsoft: «Зачем они скрывают в стандартной настройке расширения файлов?». На что получил ответ: «Это слишком сложно для пользователей и не нужно им».
Может в этом и причина путаницы?
Квазимонополисты Microsoft и Apple считают своих клиентов
Так посмотрим же на расчёт:
2TB = 2x1000x1000x1000x1000 B ~= 1,819x1024x1024x1024x1024 B = 1,819TiB
В этом расчёте видна зависимость величин и понятно откуда взялась цифра в Windows, хоть и с неправильной аббревиатурой, а внимательные (и кто знают об этом) заметили маленькую буковку i в TiB.
Так вот, мы наконец снова пришли к интернациональному стандарту IEC60027-2, который чтоб не разрушить
Составив их по схеме: SI-prefix binary (kilo binary, mega binary, giga binary etc), приходим к следующей таблице:
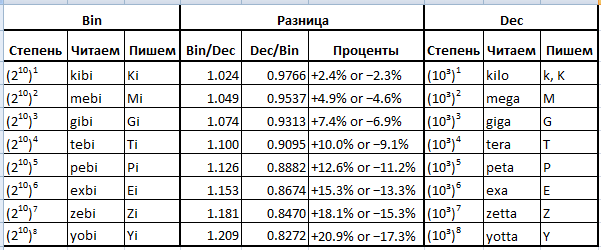
Ну как, вроде просто?
И даже если произношение кибибайт, мебибайт, гибибайт, тебибайт и т.д. слышится странно и неповоротливо, думаю для всех несложно применять KiB, MiB, GiB, TiB и т.д. в текстах!?
Всё кажется новым и неизвестным?
А ведь стандарту уже 13 лет!
(IPv6 кстати ещё старше, а его всё ещё так и не могут ввести нормально — такое ощущение, что из-за пагубного влияния больших фирм стандартам приходится лежать десяток лет и пылиться, пока не придёт какой-нибудь Apple, запатентует буковку i в KiB и MiB, и устроив многомиллионную рекламную компанию, продаст это как новую фичу)
Но несмотря на это, стандарт ведь давно используется в открытых продуктах!
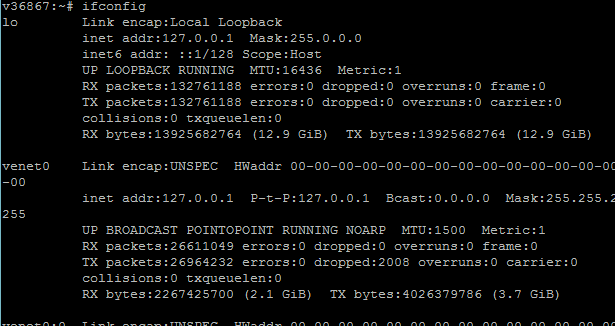
Например в Linux стандарт поддерживается самим кернелем.
А вот скрин с ifconfig‘a
А зачем оно мне надо, спросите Вы?
- Во-первых, ГОСТ 8.417—2002 заставляет работать по стандартам.
- Во-вторых, информатика — это точная наука, в которой всё должно быть логично и почти всё детерминично! И если вы действительно IT-профи, и не хотите казаться школьником в глазах коллег, то постарайтесь использовать в Ваших публикациях и программах стандарт, т.е. добавляйте i если указываете размеры данных по основанию 1024.
Примеры использования:

- В-третьих, неправильное использование величин, может привести к очень дорогим последствиям:
В этом случае NASA потеряла зонд Mars Orbiter стоимостью 125 MUSD (=119,2 MiUSD) в сентябре 1999 года именно из-за проблем в использовании правильных единиц измерения!
- Кроме того, — использование неправильного написания размеров данных «по традиции» или потому «что так прижилось или удобно», это всё равно, что сказать: «метр – это ерунда, я буду продолжать мерить расстояния локтями, ступнями, пальцами, языком и другими частями тела»
А под конец приведу всем знакомую шутку:
Нормальный человек думает, что в килобайте 1000 байтов, а программист уверен, что в килограмме 1024 грамма.
Поэтому хочу Вас, IT-профи, призвать:
П.С. а для тренировки (кто хочет) – небольшая и лёгкая задачка
(я вроде не видел, чтоб задачки на хабре давали, но для интерактивности с читателем, думаю, неплохо предложить что-нибудь такое несовсем сложное для разминки):
Вы купили себе новейший смартфон с поддержкой быстрых сетей LTE, который в идеальном случае развивает при скачивании скорости до 300 Mbit/s.
С мыслью: «Теперь мне будет чем заняться, сидя в пробке на работу», — Вы заключили безлимитный тариф для мобильного интернета.
В среду вечером, стоя в пробке, Вам прислали ссылку на новое видео про то, как Путин, притворившись тюленем-вожаком, вёл целую стаю тюленей на нерест, спасая по пути всю стаю от акул и отбиваясь от атак сомалийских пиратов.
«То, что мне нужно!» — подумали Вы и решили скачать видео.
Вопрос: сколько секунд будет закачиваться видео размером 60 MiB, если:
1. Ваш провайдер хоть и продал Вам LTE тариф, но в пробке развивается средняя скорость скачивания всего-лишь на уровне UMTS с HSDPA в размере 600 kB/s
2. при передаче каждого файла возникает overhead в размере 15% от размера файла
3. возможная компрессия в данной задаче не учитывается
UPD1
с версии MAC OS X 10.6 Snow Leopard показывает правильно в СИ-единицах, так что прошу за это Apple морду не бить
UPD2
так как поступает много вопросов по кбит и кибит, сделаю здесь небольшое резюмэ:
Я попытался объяснить в статье и несколько раз в комментариях, что kilo-, mega-, kibi-, mebi- (сокращённо k, M, Ki, Mi) и т.д. — это просто стандартизированные префиксы, которые приставляются к единицам измерения (граммы, биты, байты, пиксели и другое)
- kilo означает умножить на 1000, mega — на 1000*1000
- kibi означает умножить на 1024, mebi — на 1024*1024
поэтому например:
8 kbit = 8*1000 bit, но 8 Kibit = 8*1024 bit
13 MPixel = 13*1000*1000 Pixel
256 MB = 256*1000*1000 B, но 256 MiB = 256*1024*1024 B
Кроме того, есть предложение всем, кому не нравится «бибикать» в качестве альтернативы использовать короткую форму префикса при произношении, т.е. читать кибайт, мибайт, гибайт, тибайт и т.д.
В стандарте этого конечно нет, но если это распространится, то его скорее всего адаптируют.
