Привет, хабрахабр!
Решил я как-то скачать свою музыкальную коллекцию из vkontakte (а это без малого 1000 песен). Связываться с vk.api не хотелось, поэтому решил использовать python + библиотека request. Что из этого получилось — под катом!
Сначала посмотрим, что делает наш браузер, когда мы обращаемся к странице своих аудиозаписей вконтакте. Открываем инструменты разработчика (я использовал Chrome, F12) и заходим на vk.com/audio. Мы можем видеть все запросы, которые совершает браузер:
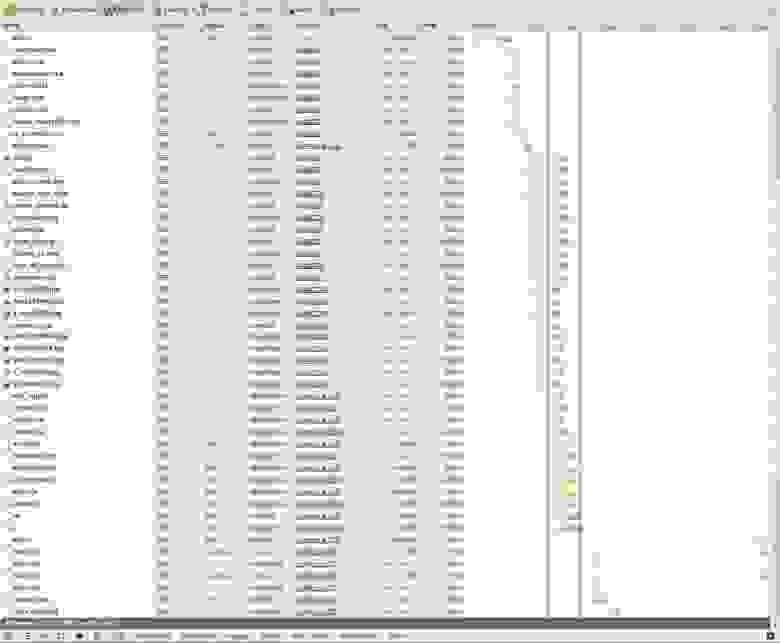
Смысл действий браузера таков:
Первая строчка — GET запрос, который мы посылаем к серверу при первом заходе на страницу. В ответе сервер отдает нам html код страницы.
Затем браузер начинает подгружать все необходимые ресурсы: css, js и изображения.
Ближе к концу списка видим нестандартную строчку: это запрос типа POST с именем audio. Скорее всего, этот запрос посылает javascript для получения списка аудиозаписей.
В ответе сервер нам возвращает строчку типа:
Бинго! Это именно то что нам и надо. В ответе сервер возвращает нам JSON-список всех наших композиций и для каждой передает следующие параметры:
Как же нам получить желанный список? Посмотрим, какие headers отправляет браузер в нашем запросе:
Попробуем сымитировать наш запрос:
Функция request.post создает POST запрос к url. Ей можно передать несколько параметров. Вот главные из них:
Функция нам выведет
Результат предсказуем — ведь мы никак не указали что мы авторизованный пользователь. Для этого надо передать серверу cookies. Исправим немного наш запрос:
Теперь получаем то что нужно.
Хорошо. Список мы получили. Теперь надо его отпарсить и скачать каждую песню по отдельности. Я решил не заморачиваться, и просто использовал регулярные выражения:
Основная функя здесь — OneDownload(). По сути, именно она скачивает песни. Делается это с помощью стандартной функции urllib.urlretrieve(url, file_path, ...). Эта функция скачивает данные, которые возвращает сервер при обращении к url и пишет в файл, который находится на пути file_path.
Все хорошо, все скачивается, но медленно!
Можем попробовать распараллелить наш алгоритм. Функции которые хотелось бы выполнять параллельно — это OneDownload. Создаем декоратор распараллеливания:
Декоратор в Python — это функция, которая принимает функцию в качестве аргумента и выполняет какие-то действия.
Данный декоратор просто запускает принятую функцию в отдельном потоке.
Добавляем глобальню переменную — число потоков. Напрямую из Thread-ов изменять эту переменную будет нельзя, поэтому добавляем функции
инкремента, и получения:
Теперь вносим изменения в код. Вот конечная версия программы:
Теперь все работает.
Исходники и компилированную версию можно скачать по этой ссылке:
VKmusic
#UPD
В компилированной версии был баг, качалась музыка только с моей страницы. Исправленная версия:
VKMusic
Решил я как-то скачать свою музыкальную коллекцию из vkontakte (а это без малого 1000 песен). Связываться с vk.api не хотелось, поэтому решил использовать python + библиотека request. Что из этого получилось — под катом!
Сначала посмотрим, что делает наш браузер, когда мы обращаемся к странице своих аудиозаписей вконтакте. Открываем инструменты разработчика (я использовал Chrome, F12) и заходим на vk.com/audio. Мы можем видеть все запросы, которые совершает браузер:
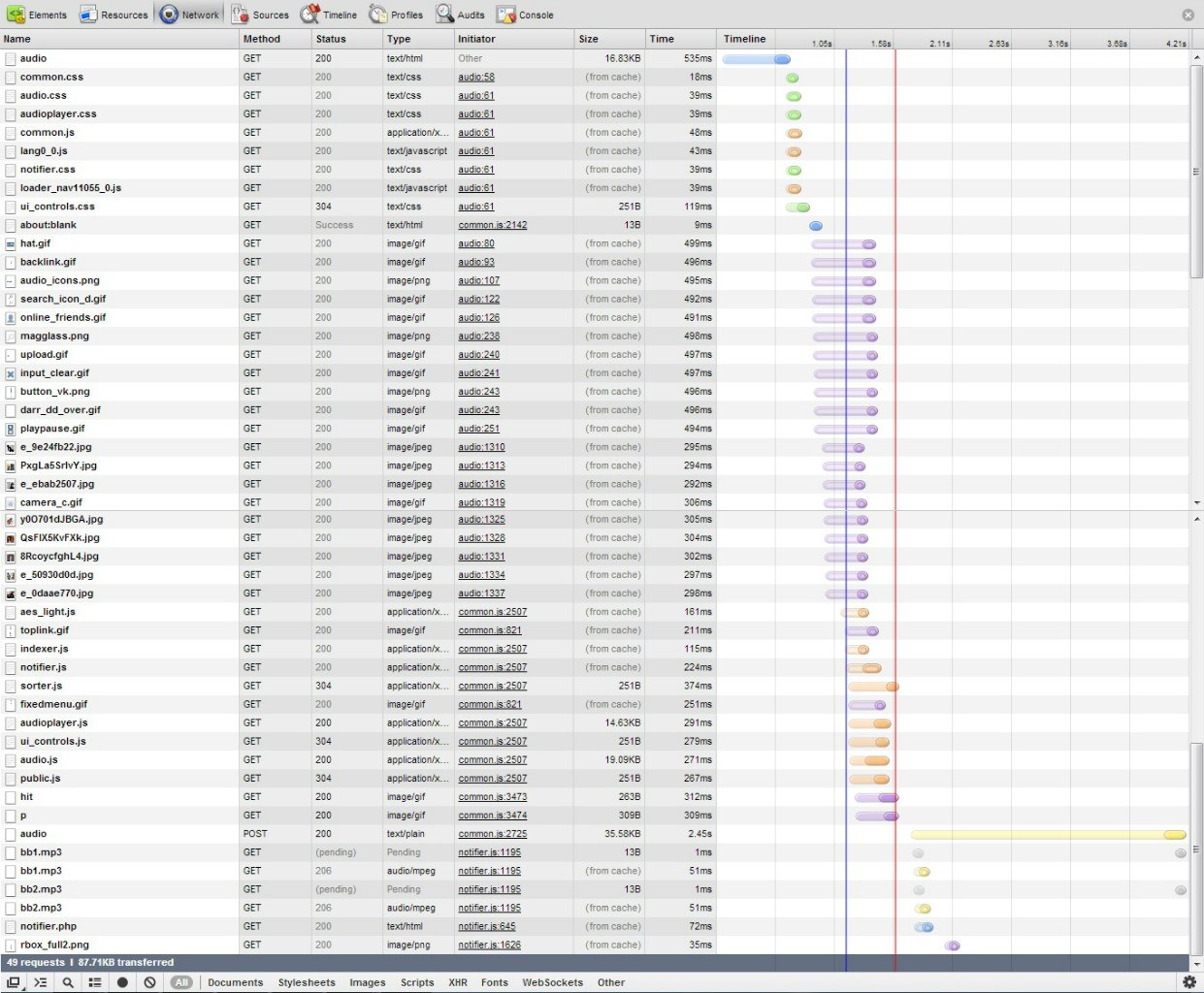
Смысл действий браузера таков:
Первая строчка — GET запрос, который мы посылаем к серверу при первом заходе на страницу. В ответе сервер отдает нам html код страницы.
Затем браузер начинает подгружать все необходимые ресурсы: css, js и изображения.
Ближе к концу списка видим нестандартную строчку: это запрос типа POST с именем audio. Скорее всего, этот запрос посылает javascript для получения списка аудиозаписей.
В ответе сервер нам возвращает строчку типа:
11055<!>audio.css,audio.js<!>0<!>6362<!>0<!>{"all":[
['17738938','173762121',
'http://cs1276.userapi.com/u1040081/audio/c0e97293c5e2.mp3','300','5:00',
'Louis Prima','Sing, Sing, Sing (With A Swing)','369754','0','0','','0','1'],
['17738938','173368012',
'http://cs4372.userapi.com/u9237008/audio/5f51ceac6ca1.mp3','326','5:26',
'Look at my horse','My horse is amazing','10324035','0','0','','0','1'], ...Бинго! Это именно то что нам и надо. В ответе сервер возвращает нам JSON-список всех наших композиций и для каждой передает следующие параметры:
- 0 — мой id
- 1 — id композиции
- 2 — ссылку на композицию
- 3 — битрейт?
- 4 — длительность
- 5 — автор
- 6 — название композиции
- 7 — размер в байтах?
- Остальные параметры непонятны.
Получаем список аудиозаписей
Как же нам получить желанный список? Посмотрим, какие headers отправляет браузер в нашем запросе:
Request Headers:
Accept:*/*
Accept-Charset:windows-1251,utf-8;q=0.7,*;q=0.3
Accept-Encoding:gzip,deflate,sdch
Accept-Language:ru-RU,ru;q=0.8,en-US;q=0.6,en;q=0.4
Connection:keep-alive
Content-Length:45
Content-Type:application/x-www-form-urlencoded
Cookie:remixlang=0; remixseenads=2; audio_vol=100; remixdt=0;remixsid=************; remixflash=11.4.31
Host:vk.com
Origin:http://vk.com
Referer:http://vk.com/audio
User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4
X-Requested-With:XMLHttpRequest
Form:
Dataview URL encoded
act:load_audios_silent
al:1
gid:0
id:17738938
Попробуем сымитировать наш запрос:
import requests as r
def getAudio():
response = r.post(url = "http://vk.com/audio",
data = {
"act":"load_audios_silent",
"al":"1",
"gid":"0",
"id":"17738938"
}
)
print response.content
getAudio()
Функция request.post создает POST запрос к url. Ей можно передать несколько параметров. Вот главные из них:
- headers — словарь хидеров, которые мы хотим отправиь серверу
- data — словарь данных, которые надо передать в запросе
Функция нам выведет
<!--11055<!>audio.css,audio.js<!>0<!>6362<!>3<!>230b860567731c4875Результат предсказуем — ведь мы никак не указали что мы авторизованный пользователь. Для этого надо передать серверу cookies. Исправим немного наш запрос:
import requests as r
def getAudio():
response = r.post(
"http://vk.com/audio",
data = {
'act':"load_audios_silent",
"al":"1",
"gid":"0",
"id":"17738938"
},
headers = {
"Cookie":"remixlang=0; remixseenads=2; remixdt=0; remixsid=**************; audio_vol=96; remixflash=11.4.31"
}
)
print response.content[0:1000]
getAudio()
Теперь получаем то что нужно.
Хорошо. Список мы получили. Теперь надо его отпарсить и скачать каждую песню по отдельности. Я решил не заморачиваться, и просто использовал регулярные выражения:
#-*-coding:cp1251-*-
import requests as r
import re
import random as ran
import os
import urllib as ur
#Разрешенные символы в названиях песен:
ALLOW_SYMBOLS = " qwertyuiopasdfghjklzxcvbnmйцукенгшщзхъэждлорпавыфячсмитьбюЙЦУКЕНГШЩЗХЪЭЖДЛОРПАВЫФЯЧСМИТЬБЮ.,-()"
COOKIE = "" #Здесь надо указать cookies, которые вы передаете контакту.
def getAllowName(string):
"""Возвращает для каждой строки подстроку, состоящую только из разрешенных символов
ALLOW_SYMBOLS"""
s=''
for x in string.lower():
if x in ALLOW_SYMBOLS:
s += x
return s
def getRandomElement(arr, delete = False):
"""Возвращает рандомный элемент массива arr. Если delete = True, то этот элемент удаляется из массива."""
index = ran.randrange(0, len(arr), 1)
value = arr[index]
if delete:
arr.remove(value)
return value
def getAudio():
"""С этой функцией мы уже сталкивались. Только тут она полученную строку
разбивает на массив элементов"""
response = r.post(
"http://vk.com/audio",
data = {
'act':"load_audios_silent",
"al":"1",
"gid":"0",
"id":"17738938"
},
headers = {
"Cookie":COOKIE
}
)
i=0
pat = re.compile(r"\[.+?\]") #соответствует всем подстрокам типа [.*]
return pat.findall(response.content) #тут и происходит разбиение
already_added = [] #тут будем хранить id композиций, которые уже скачаны.
pat = re.compile(r"\'(.+?)\'") #паттерн соответствует всем подстрокам вида '.*'
def OneDownload(x):
"""Делает ОДНУ закачку песни, описание которой (типа ['...', '...', '...', ...]) передается аргументом
"""
global already_added
try:
elements = pat.findall(x) #получаем свойства композиции
id, url, author, name = (elements[1], elements[2], elements[5], elements[6])
#нужные свойства - id, url, author, name
except:
return
if id not in already_added: #если мы не скачивали композицию
already_added.append(id) #добавляем ее в скачанные
file_path = "audio/"+getAllowName(author+" - "+name)+".mp3" #создаем путь, по которому будет храниться эта композиция
with open(file_path, "w"): #создаем пустой файл с указанным путем
pass
ur.urlretrieve(url, file_path) #и производим закачку
print name, "downloaded"
def getFirstNSongs(first=0, last = None):
"""Функция, получает номер первой песни, которую надо скачать и номер последней
и производит закачку"""
if not os.path.exists(os.path.join(os.getcwd(), 'audio')):
#если нет папки audio создаем ее
os.mkdir('audio')
songs = getAudio() #получаем описания песен
#обрезаем массив песен, в соответствии с указанными first и last:
if last!=None:
songs = songs[first:last+1]
else:
songs = songs[first:]
for x in songs: #для каждой нужной песни
OneDownload(x) #скачиваем ее
getFirstNSongs(last = 10)
Основная функя здесь — OneDownload(). По сути, именно она скачивает песни. Делается это с помощью стандартной функции urllib.urlretrieve(url, file_path, ...). Эта функция скачивает данные, которые возвращает сервер при обращении к url и пишет в файл, который находится на пути file_path.
Все хорошо, все скачивается, но медленно!
Можем попробовать распараллелить наш алгоритм. Функции которые хотелось бы выполнять параллельно — это OneDownload. Создаем декоратор распараллеливания:
def Thread(f):
def _inside(*a, **k):
thr = threading.Thread(target = f, args = a, kwargs = k)
thr.start()
return _inside
Декоратор в Python — это функция, которая принимает функцию в качестве аргумента и выполняет какие-то действия.
Данный декоратор просто запускает принятую функцию в отдельном потоке.
Добавляем глобальню переменную — число потоков. Напрямую из Thread-ов изменять эту переменную будет нельзя, поэтому добавляем функции
инкремента, и получения:
alive_threads = 0
def inc(x):
#изменяет переменую
global alive_threads
alive_threads+=x
return alive_threads
def get():
#возвращает значение
global alive_threads
return alive_threads
Теперь вносим изменения в код. Вот конечная версия программы:
#-*-coding:cp1251-*-
import requests as r
import re
import threading
import time
import random as ran
import os
import urllib as ur
THREADS_COUNT = 10
ALLOW_SYMBOLS = " qwertyuiopasdfghjklzxcvbnmйцукенгшщзхъэждлорпавыфячсмитьбюЙЦУКЕНГШЩЗХЪЭЖДЛОРПАВЫФЯЧСМИТЬБЮ.,-()"
COOKIE = "" #Здесь ваш cookies
def getAllowName(string):
s=''
print string.lower()
for x in string.lower():
if x in ALLOW_SYMBOLS:
s += x
return s
def getRandomElement(arr, delete = False):
index = ran.randrange(0, len(arr), 1)
value = arr[index]
if delete:
arr.remove(value)
return value
alive_threads = 0
def inc(x):
global alive_threads
alive_threads+=x
return alive_threads
def get():
global alive_threads
return alive_threads
def Thread(f):
def _inside(*a, **k):
thr = threading.Thread(target = f, args = a, kwargs = k)
thr.start()
return _inside
def getAudio():
response = r.post(
"http://vk.com/audio",
data = {
'act':"load_audios_silent",
"al":"1",
"gid":"0",
"id":"17738938"
},
headers = {
"Cookie":COOKIE
}
)
i=0
pat = re.compile(r"\[.+?\]")
return pat.findall(response.content)
already_added = [] #тут будем хранить id композиций, которые уже скачаны.
pat = re.compile(r"\'(.+?)\'") #паттерн соответствует всем подстрокам вида '.*'
count = 0
@Thread
def OneDownload(x):
global already_added
inc(1) #когда запустился новый тред - инкрементируем число тредов
try:
elements = pat.findall(x)
id, url, author, name = (elements[1], elements[2], elements[5], elements[6])
except:
return
if id not in already_added:
already_added.append(id)
file_path = "audio/"+getAllowName(author+" - "+name)+".mp3"
with open(file_path, "w"):
pass
ur.urlretrieve(url, file_path)
inc(-1) #тред закончился - декрементируем
def getFirstNSongs(a=0, N = None):
if not os.path.exists(os.path.join(os.getcwd(), 'audio')):
os.mkdir('audio')
songs = getAudio()
if N!=None:
songs = songs[a:N]
else:
songs = songs[a:]
previous = 0 #тут будем хранить число еще не скачанных песен
cc=10
while (len(songs)>0 and len(songs)!=previous) or (len(songs) == previous and cc>0):
#пока число песен непусто, или количество оставшихся песен не изменялось в менее чем 10 циклах
if previous != len(songs):
previous = len(songs) #смотрим, изменилось ли число песен. Если да - присваиваем
cc=10 #число шагов - 10
else:
cc-=1 #если не изменилось, уменьшаем число шагов на 1. Если кол-во песен не изменится за 10 шагов мы выйдем из цикла
print "Осталось скачать", len(songs), "Число нитей", alive_threads
while alive_threads<THREADS_COUNT: #пока можем создавать новые треды
x = getRandomElement(songs, delete = True) #получаем рандомную песню, которую надо скачать
try:
OneDownload(x) #пытаемся скачать
except:
songs.append(x) #если не получилось - возвращаем назад.
while alive_threads>=THREADS_COUNT:
time.sleep(10) #если не можем добавлять новые треды - спим 10 секунд.
getFirstNSongs(N=3) #скачиваем, например, первые 3 песни
Теперь все работает.
Исходники и компилированную версию можно скачать по этой ссылке:
VKmusic
#UPD
В компилированной версии был баг, качалась музыка только с моей страницы. Исправленная версия:
VKMusic
