Грязный
Давайте вместе поразмыслим — что же такое чистый код, и что такое код грязный? Или, как говорят американцы – «hairy code», т.е. волосатый?
Чем чистый код отличается от грязного – или, как говорят в этих наших интернетах, от «говнокода»? Да и нужен ли он вообще, этот чистый код?
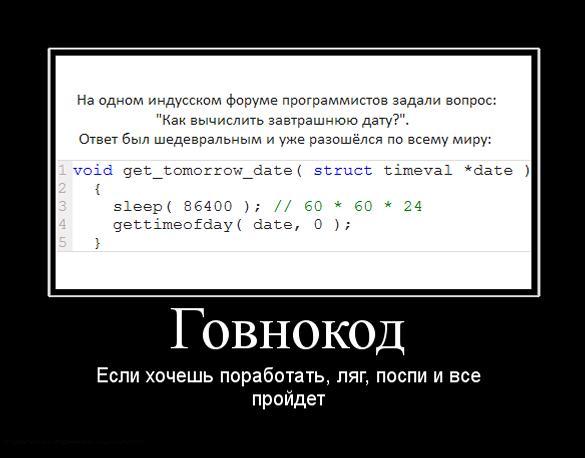
Давайте сначала разберёмся с определениями.
Мне кажется, что дать чёткого определения «чистому» коду просто невозможно. Отчасти это – как с красотой: смотришь на картину, или там скульптуру – и видишь: да, красива. Или, наоборот, уродлива.
Да, мы научились определять общие закономерности, скажем, в лицах, которые считаются красивыми. Но готовы ли мы дать чёткое определение красоте? Думаю, нет.
Эта аналогия не вполне корректна (как и большинство аналогий), но примерно передаёт ощущения, возникающие при работе с кодом. Неважно – чужим ли, своим ли, написанном пару месяцев назад и уже прочно забытым. Код либо нравится, либо нет. Он либо красив, чист и приятен – либо волосат, уродлив и дурно пахнет.
И, конечно же, у каждого есть свои критерии «красоты кода». Свой, так сказать, вкус.
Но, тем не менее, есть какие-то общие точки, о которых если и спорят, то вяло и соглашательски. Не о сути, а об обрамлении.
Давайте попробуем их перечислить.
| Легко читается и понимается | Запутан, неочевиден, трудно понимаем |
| Легко поддаётся изменениям | Закостенел в своих внутренних связях; изменить что-либо стоит неимоверных усилий и жертв |
| Может быть расширен, либо встроен куда-нибудь в виде отдельного модуля | Для расширения требует переписывания, для встраивания – обёрток |
| Поддаётся автоматизированному тестированию | Может быть протестирован, лишь как «чёрный ящик» |
Конечно, можно начать спор о «читабельности» или «понимабельности» кода. Это совсем не формализованные термины.
Но и они интуитивно понятны: если, например, кто-то станет доказывать окружающим, что он привык писать всю программу в виде одной-двух огромных функций, «которые делают всё», а решение тех же задач при помощи хотя бы разбиения на большое количество небольших процедур и функций для него непонятно – ему намекнут, что надо бы подтянуть азы.
А желательно – основательно поковырять ООП и стараться инкапсулировать логику в отдельных классах, чтобы не приходилось напрягать головной мозг ни разбором огромных «портянок» кода на десятки экранов, ни запутанными связями процедур и функций, которые к тому же (omg) оперируют кучей глобальных переменных.
Примерно так же дело обстоит и с остальным: конечно, даже среди приведённых 4х пунктов есть взаимоисключающие параграфы (легко читаемый код далеко не всегда будет легко изменяемым, лёгкость расширяемости может конфликтовать с автоматизацией тестирования и т.п.) – но в целом обстановка понятна.
В принципе, руководствуясь этими пунктами (усиливая или ослабляя каждый из них в зависимости от требований конкретных задач), можно легко отличить грязный код от чистого.
Хотя лучше всего, если это происходит само собой, без чересчур подробного анализа. Когда есть «нюх», позволяющий быстро понять, что код грязен и воняет.
Чистый
Теперь давайте всё-таки попробуем разобраться – зачем же он вообще нужен, этот чистый код? И так ли уж плох код грязный и волосатый?
Ну, для начала нужно сказать: it depends.
Бывают моменты, когда написать «быстро и грязно» куда важнее, чем «долго и чисто». Хотя нужно отметить, что «грязно» далеко не всегда означает «быстро». Бывает, что ровно наоборот.

В общем, давайте попробуем рассмотреть более-менее жизненные примеры и постараться понять в каждом случае – когда грязное кодирование бывает оправдано, а когда абсолютно недопустимо.
Например
На сервере что-то происходит, логи пишутся – но они огромны, и читать их некому. Нужно написать небольшую утилитку, которая прочитает логи, вытащит оттуда какие-то численные данные и представит их в виде таблицы. На входе – лог-файл, на выходе – текст с цифирями.
Такую задачу вполне можно написать как угодно грязно – лишь бы утилька работала, а написание не заняло много времени. Ведь мы решаем здесь одну сиюминутную задачу.
Решить же задачу долговременную куда как лучше, изменив систему регистрации ошибок (писать те же численные данные в базу, например).
То есть утилиту эту в идеале используют один-два раза, после чего выкинут. Чистота кода здесь совершенно не важна.
Другой пример
Сервер иногда падает, почему – никто не знает. Анализатор логов позволил понять, что падение вызывается большим количеством однотипных запросов, приходящих с вполне определёнными значениями параметров, и эту ситуацию необходимо срочно воспроизвести.
Нужно написать небольшую утилитку, которая будет в точности воспроизводить это поведение.
Казалось бы – всё один в один повторяет первый пример. Однако здесь возникает вопрос: раз процесс тестирования не предусматривает воспроизведение подобных ситуаций, то не возникнет ли необходимость дальнейшего развития этой утилиты в качестве инструмента тестирования? Не станет ли она самостоятельным приложением, которым пользуются регулярно?
Если ответ – «да» или хотя бы «возможно», то стоит уделить немного внимания тому, чтобы код был понятен хотя бы самому разработчику через месяц-другой, и в то же время позволял бы как-то себя расширять.
К примеру, добавлять другие последовательности запросов, конфигурировать адрес сервера и число запросов, значения ключевых параметров и т.д.
Это ненамного замедлит разработку утилиты «здесь и сейчас» — зато, когда вновь встанет вопрос о воспроизведении последовательности запросов на сервер – утилита будет тут как тут и потребует минимального допиливания; а главное – минимального времени на вспоминание, что там к чему.
Третий пример
Разработка программного модуля для основного программного продукта компании, уже несколько лет успешно развивающегося на рынке.
Казалось бы – модуль изолирован, интерфейсы взаимодействия с другими модулями определены. «Кручу-верчу, говнокод писать хочу». Но тут возникает серьёзное «НО».
Что будет с этим модулем через полгода? Год? Потребует ли он поддержки? Изменения? Расширения функционала? Возможно, в итоге разовьётся в отдельный продукт?
Если хотя бы на один вопрос можно дать хотя бы ответ «вероятно» — то говнокодить, увы и ах, строго не рекомендуется.
Но это не весь список вопросов. А кто будет работать с этим модулем через два-три года? Тот, кто его писал, или кто-то другой?
Если кто-то другой – то ведь ему придётся в этом коде разбираться.
И если это будет плохой, негодный код – то либо плакать и жевать кактус, проклиная создателя, либо выкинуть всё на помойку и переписать заново, получая при этом поджопники от начальства за срыв сроков.
Если же работать с этим кодом будет сам разработчик – то тем более. Да он через полгода уже не будет помнить: что, где и как работает! Ему придётся разбираться в этом коде так, как будто код совершенно чужой. Не враг же он самому себе?
Четвёртый пример
Разработка приложения (сайта, базы данных с простейшим интерфейсом – чего угодно) под заказ в сжатые сроки за небольшие деньги.
С одной стороны – code and forget, можно писать что угодно и как угодно, лишь бы работало.
С другой стороны – а что, если этот заказчик через месяц вернётся и попросит за дополнительные деньги что-то добавить или переделать? Будем плакать, колоться, но жевать кактус? Откажемся от заказа?
А что, если он обратится к другому разработчику (компании), получит негативный feedback о качестве исполнения проекта, и больше никогда не вернётся к «злым говнокодерам», да ещё своим друзьям отсоветует?
Я уже не говорю о таких вещах, как качество кармы и память потомков.
Пятый пример
Командная разработка.
Самый жёсткий случай абсолютного недопущения говнокодирования.
Мне сложно даже представить себе какие-либо аргументы в пользу осознанного выбора плохого кода в случае командной разработки.
Да что там говорить – один говнокодер способен принести вреда больше, чем вражеский агент в тылу врага!
Если команда не изолирует его, бросив на написание никому не вредящих, ни с чем не связанных, абсолютно левых утилит и мини-приложений – то его продуктивность в команде будет не то, что нулевой – она будет отрицательной!
Необходимость читать, вникать, исправлять, матерясь – а в итоге выкидывать и переписывать заново – мало того, что занимает больше времени, чем самостоятельная разработка хорошего кода, так ещё и портит общую атмосферу в команде и минусует мораль всех разработчиков, вынужденных сталкиваться с говнокодом не по своей вине.
А тестирование? Сопровождение? Расширение функционала??
Я мог бы написать ещё пару хулительных абзацев – но нет. Не могу.
Клавиатура выпадает из ослабевших пальцев при мысли о том, сколько вреда может принести говнокод в команде…
Это ужасно… ужасно…
Устремлённый
Итак, мы примерно понимаем, что такое грязный код и чем он плох. Мы всё ещё не вполне понимаем, что такое чистый код, но ощущаем его необходимость.
Почему же он всегда есть, этот грязный код, почему он всегда присутствует и портит жизнь всем – в том числе и своим авторам?
На мой взгляд, всё предельно просто: писать чистый код – это искусство, это сверхспособность, развить которую в себе может практически каждый; но далеко не каждый даже задумывается о необходимости её развития.
Не говоря уже о том, чтобы получать представление о сиём предмете в профильном университете или на профильных курсах – там дают лишь самые верхушки «нужных» технологий, платформ и языков – немногие вообще уделяют специальное внимание улучшению собственных навыков чистого кодирования.
Конечно, с течением времени, если у разработчика развит «нюх на грязый код», он неизбежно начинает писать всё чище и лучше.
Он читает на досуге интересные статьи, он изучает паттерны проектирования. Но бывает, что он делает это потому, что ему интересно – а не потому, что осознаёт необходимость развития своих навыков написания чистого кода.
И при этом, в идеале, он всегда ощущает, что его код всё ещё недостаточно хорош, что ему ещё далеко до совершенства. И пусть его сегодняшний «говнокод» на голову выше самого лучшего, что он писал два-три года назад – всё равно есть куда расти.
В связи с этим мне вспоминается один интереснейший разговор с моим коллегой, которому, как и мне, довелось провести не одно собеседование с кандидатами на должность разработчика – возможно, даже больше, чем собеседований в качестве такового кандидата.
Мы говорили о молодых программистах и о том, какие их качества более всего свидетельствуют о потенциале профессионального развития.
В итоге всё свелось к нескольким простейшим пунктам, в порядке важности:
1) Хорошо работающая голова (поэтому у нас всегда есть задачки на логику)
2) Высокий уровень самокритичности (поэтому всегда есть задачки на написание кода и поиск ошибок в нём)
3) Интерес к программированию (важен в меньшей степени, задачками не определяется в принципе)
То есть понятно, что если голова работает плохо – то разработчиком не станешь при всём желании и старании. Однако, если она даже золотая и светится от разумности – это ещё далеко не гарантия.
Частенько бывает, что молодой специалист, видя, как легко ему всё даётся (особенно – в сравнении с большинством своих одногруппников, сокурсников, просто ровесников) начинает искренне считать, что круче бывают только яйца.
И, хотя наверняка к этому есть некоторые основания, но ЧСВ зашкаливает настолько, что в итоге в один прекрасный момент он просто перестаёт развиваться, считая, что «я и так умный, а кто пытается это оспорить – тот дундук».
И хорошо, если при этом у него остаётся живой, острый интерес к своей работе. Если он продолжает читать статьи и книги «потому, что интересно». Тогда у него остаётся небольшой шанс не застыть, а продолжать развиваться.
И, наконец, бывает, что парень (или девушка – что встречается гораздо реже, уж извините меня за эту неполиткорректную реальность) и умный, и самокритичный – редко остаётся довольным своим кодом и вообще считает, что ему ещё расти и расти – в какой-то момент теряет (хорошо, если не полностью) интерес к профессии, начинает меньше читать, меньше экспериментировать.
Начинает чаще выполнять задачи «строго по спецификации», желательно – уже знакомые задачи, из знакомых сфер. Меньше уделять внимания новым языкам, платформам, концепциям.
И становится вполне хорошим, годным специалистом. Зачастую даже не очень узким, а относительно многопрофильным. Вполне себе уважаемым.
Но так и не достигает вершины своего изначального потенциала.
И лишь в очень редких случаях умный, способный, в высшей степени самокритичный молодой человек с горящими глазами растёт ежегодно, ежечасно – и в итоге становится звездой. Бывает, что очень быстро становится «локальным светилом» – но не застывает, не ограничивается этим, а продолжает расти, развиваться, совершенствоваться.
Ах, как прекрасна эта картина – так и хочется смахнуть несуществующую слезу! Как прекрасен он, этот устремлённый в бесконечность молодой человек, своим духовным порывом приподнимающий самые небеса, в которые нацелен его всепроникающий взгляд!
Как счастливы люди, окружающие его, когда они понимают, сколь величествен его путь, и делают, в свою очередь, хоть два-три шага рядом с ним. Приближаясь хоть на волос к той прекрасной бесконечности возможностей, куда летит он на всех парах!
Как хочется видеть побольше горящих глаз, светлых умов, обращённых в эту бесконечность. Как хочется хотя бы немного помочь этим атлантам на их пути, хоть на мгновение поддержать, подтолкнуть ввысь, приблизить их к этой недостижимой и прекрасной цели.
И остаться внизу, с щемящей радостью наблюдая, как пронизывают они пространство и время в своём стремлении.
И знать, что хотя бы немного, хотя бы чуть-чуть – помог, поддержал, а не стоял в стороне, застывший в своём упоении собственной важностью, не бросал презрительных взглядов – «пхе… молодёжь..»
