Введение
В данной статье кратко рассказывается о процессе взлома captcha используемой ранее при входе на сайт Хабрахабр.
Целью работы является применение знаний на практике и проверка сложности каптчи.
При разработке алгоритма использован Matlab.
Обзор задачи
Старая каптча Хабрахабр выглядела так:
 |
 |
 |
 |
 |
|---|
Основные трудности распознавания данной каптчи:
- Искаженные символы
- Шумы и размытость
- Размеры символов сильно отличаются
- Пересечение символов
Честно говоря, у меня не всегда получалось с первого раза правильно прочитать каптчу, поскольку часто символы А и 4, L и 4 были неразличимые.
Все же, несмотря на некоторые сложности, рассмотрим основные идеи по чтению данной каптчи.
Этап 1. Построение системы сегментации
Каждую систему распознавания символов можно представить следующим образом:

В нашем случае необходимо реализовать последние две подсистемы.
Детальный анализ исследуемой каптчи позволил выделить ее основные особенности:
- На каптче всегда присутствуют 6 символов
- Всегда используется схожий (скорее всего один и тот же) метод зашумления
- Случаи пересечения или наложения символов редкие
Исходя из этого, был построен следующий алгоритм сегментации:
- Убрать шумы
- Бинаризировать изображение
- Выделить 6 наибольших областей связности
Реализация сегментации в Matlab
function [ rects ] = segmentator( aImg, nRect, lightMode )
%find all symbols on habrahabr login captcha
%use: rects = segmentator( aImg, nRect )
%where:
% rects - rects coordinates
% aImg - resized image data
% nRect - count of rect to find
% lightMode - find all rects without imOpen
%Много кода, из которого большая часть предназначена для случая когда символы склеены.
if nargin < 4
fSRects = 0;
end
if nargin < 3
lightMode = 0;
end
minX = 8; if lightMode minX = 11; end %px
minY = 16; if lightMode minY = 18; end %px
%% Change color mode to 8-bit gray
if(size(size(aImg),2) > 2)
aImg = imadjust(rgb2gray(aImg));
end
%Save aImg
aImgCopy = aImg;
%structuring element for imopen
se = strel('disk', 2);
%Remove some noise
aImg(aImg > 0.92) = 1;
aImg = imopen(imadjust(aImg), se);
if lightMode
aImg = aImgCopy;
end
imBW3 = adaptivethreshold(aImg,50,0.2,0);
if ~lightMode
imBW3 = imopen(imBW3, se);
end
%% find rects
imBin = 1 - imBW3;
CC = bwconncomp(imBin);
numPixels = cellfun(@numel,CC.PixelIdxList);
[biggest, idx] = sort(numPixels, 'descend');
bb = regionprops(CC, 'BoundingBox');
if lightMode
imshow(aImgCopy);
end
%Primitive filter
%copy only good rects
bbCounter = 1;
for i = 1 : length(bb)
curRect = bb(i).BoundingBox;
if (curRect(3) < minX || curRect(4) < minY)
continue;
end
bbNew(bbCounter) = bb(i);
bbCounter = bbCounter + 1;
end
if bbCounter == 1
rects = {-1};
return;
end
if DEBUG_MODE
for i = 1:length(bbNew)
rectangle('Position', bbNew(i).BoundingBox, 'EdgeColor', 'r');
end
end
%analize count of rects
%1: if rectC == nrect -> all rects find
%2: else if rectC > nrect -> delete smallest
%3: else -> find subrects
if nRect == length(bbNew) || fSRects == 1
rects = {bbNew(1:end).BoundingBox};
elseif nRect < length(bbNew)
rects = deleteSmallest( bbNew, nRect )
else
for i = 1 : length(bbNew)
curRect = bbNew(i).BoundingBox;
rectArea(i) = curRect(3) .* curRect(4);
end
needRect = nRect - length(bbNew);
aImg = aImgCopy;
[biggest, idx] = sort(rectArea, 'descend');
switch(needRect) %@todo: Redesign (check constant)
case 1
subRects{1} = findSubRects( aImg, bbNew( idx(1)).BoundingBox, 2 );
subRectIdx = idx(1);
case 2
if( biggest(1) > 2 * biggest(2) )
subRects{1} = findSubRects( aImg, bbNew(idx(1)).BoundingBox, 3 );
subRectIdx = idx(1);
else
subRects{1} = findSubRects( aImg, bbNew(idx(1)).BoundingBox, 2 );
subRects{2} = findSubRects( aImg, bbNew(idx(2)).BoundingBox, 2 );
subRectIdx = idx(1:2);
end
case 3
if( biggest(1) > 3 * biggest(2) )
subRects{1} = findSubRects( aImg, bbNew(idx(1)).BoundingBox, 4 );
subRectIdx = idx(1);
elseif( biggest(1) > 1.5 * biggest(2) )
subRects{1} = findSubRects( aImg, bbNew(idx(1)).BoundingBox, 3 );
subRects{2} = findSubRects( aImg, bbNew(idx(2)).BoundingBox, 2 );
subRectIdx = idx(1:2);
else
subRects{1} = findSubRects( aImg, bbNew(idx(1)).BoundingBox, 2 );
subRects{2} = findSubRects( aImg, bbNew(idx(2)).BoundingBox, 2 );
subRects{3} = findSubRects( aImg, bbNew(idx(3)).BoundingBox, 2 );
subRectIdx = idx(1:3);
end
otherwise
display('Not supported now'); %@todo: add more mode
rects = {-1};
return;
end
%create return value
rC = 1;
for srC = 1:length(bbNew)
if(sum(srC == subRectIdx))
curIdx = find(subRectIdx == srC);
for srC2 = 1 : length(subRects{curIdx})
rects(rC) = subRects{curIdx}(srC2);
rC = rC + 1;
end
else
rects{rC} = bbNew(srC).BoundingBox;
rC = rC + 1;
end
end
end
end
function [ subRects ] = findSubRects( aImg, curRect, nSubRect )
coord{1} = [0]; pr(1) = 100;
coord{2} = [0 40]; pr(2) = 60;
coord{3} = [0 30 56]; pr(3) = 44;
coord{4} = [0 23 46 70]; pr(4) = 30;
MIN_AREA = 250;
if DEBUG_MODE
imshow(aImg);
end
wide = curRect(3);
for i = 1 : nSubRect
subRects{i}(1) = curRect(1) + coord{nSubRect}(i) * wide / 100;
subRects{i}(2) = curRect(2);
subRects{i}(3) = wide * pr(nSubRect) / 100;
subRects{i}(4) = curRect(4);
rect{i} = imcrop(aImg, subRects{i});
tmpRect = rect{i};
lvl = graythresh(tmpRect);
tmpRect = imadjust(tmpRect);
tmpRect(tmpRect > lvl + 0.3) = 1;imshow(tmpRect);
tmpRect(tmpRect < lvl - 0.3) = 0;imshow(tmpRect);
imbw3 = multiScaleBin(tmpRect, 0.22, 1.4, 30, 1);imshow(imbw3);
imbin = 1 - imbw3;
%imBin = binBlur(tmpRect, 13, 1); imshow(imBin); %other method of
%adaptive binarization
cc = bwconncomp(imbin);
numpixels = cellfun(@numel,cc.PixelIdxList);
[biggest, idx] = sort(numpixels, 'descend');
bb = regionprops(cc, 'Boundingbox');
imshow(rect{i});
%find biggest rect
clear rectArea;
for j = 1 : length(bb)
rectArea(j) = bb(j).BoundingBox(3) .* bb(j).BoundingBox(4);
end
[biggest, idx] = sort(rectArea, 'descend');
newRect = bb(idx(1)).BoundingBox;
rectangle('Position', newRect, 'EdgeColor', 'r');
if newRect(3) * newRect(4) > MIN_AREA
subRects{i}(1) = subRects{i}(1) + newRect(1) - 1;
subRects{i}(2) = subRects{i}(2) + newRect(2) - 1;
subRects{i}(3) = newRect(3);
subRects{i}(4) = newRect(4);
end
end
end
function [ retValue ] = deleteSmallest( bbRects, nRects )
%1: calc area
for i = 1 : length(bbRects)
curRect = bbRects(i).BoundingBox;
rectArea(i) = curRect(3) .* curRect(4);
end
%2: sort area
[~, idx] = sort(rectArea, 'descend');
idx = idx(1:nRects);
idx = sort(idx);
%copy biggest
retValue = {bbRects(idx).BoundingBox};
end
function [ imBIN ] = sauvola( X, k )
h = fspecial('average');
local_mean = imfilter(X, h, 'symmetric');
local_std = sqrt(imfilter(X .^ 2, h, 'symmetric'));
imBIN = X >= (local_mean + k * local_std);
end
Шумы убираем очень просто, для этого все пиксели изображения которые светлее некоторого уровня делаем белыми.
Пример обработки:
| Оригинальное изображение |
Изображение после обработки |
|---|---|
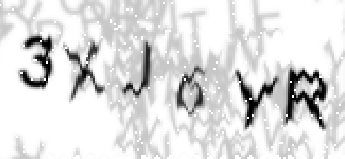 |
 |
Для бинаризации используем адаптивный алгоритм бинаризации, в котором для каждого пикселя (или областей пикселей) определяется свой порог бинаризации [ Адаптивная бинаризация].
Примеры бинаризации:
| Хороший пример сегментации (3XJ6YR) |
Пример склеенных и разорванных символов (4TAMMY) |
|---|---|
 |
 |
Для поиска символов на изображении решено использовать метод поиска связных областей, что в Matlab можно сделать с помощью функций:
CC = bwconncomp(imBin);
bb = regionprops(CC, 'BoundingBox');
После чего провести анализ полученных областей, выделить из них самые большие, при необходимости разбить на подобласти (в случае склеенных символов). Случай, когда в символах появляются разрывы не предусмотрен.
Примеры конечного результата сегментации:
 |
 |
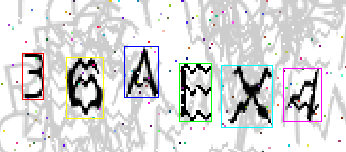 |
 |
 |
Качество сегментации удовлетворительное, переходим к следующему этапу.
Этап 2. Создание обучающей выборки
После сегментации мы получаем набор координат прямоугольников, которые предположительно содержат символы каптчи.
Поэтому, сначала распознаем вручную все капчти и переименуем их (в этот момент я чувствовал себя профессиональным распознавателем каптч, жаль что не платили 1 цент за каждую распознанную). После чего используем следующий скрипт, для формирования обучающей выборки:
Скрипт для создания обучающей выборки
%CreateTrainSet.m
clear; clc;
workDir = '.\captch';
fileList = dir([workDir '\*.png']);
N_SYMB = 6;
SYMB_W = 18; %px
SYMB_H = 28; %px
WIDTH = 166; %px
HIGH = 75; %px
SAVE_DIR = [workDir '\Alphabet'];
%process data
for CC = 1 : length(fileList)
imName = fileList(CC).name;
recognizedRes = imName(1:N_SYMB);
%open image
[cdata, map] = imread( [workDir '\' imName] );
%change color mode
if ~isempty( map )
cdata = ind2rgb( cdata, map );
end
%resize image
cdata = imresize(cdata, [HIGH WIDTH], 'lanczos3');
%find all symbols on image
rects = segmentator(cdata, N_SYMB, 1);
if rects{1} == -1
continue;
end
%imcrop and save
if length(rects) == N_SYMB
if ~exist(SAVE_DIR)
mkdir(SAVE_DIR);
end
for j = 1 : N_SYMB
if ~exist([SAVE_DIR '\' recognizedRes(j)])
mkdir([SAVE_DIR '\' recognizedRes(j)]);
end
imList = dir([SAVE_DIR '\' recognizedRes(j) '\*.jpg']);
newname = num2str(length(imList) + 1);
nameS = floor(log10(length(imList) + 1)) + 1;
for z = nameS : 4
newname = ['0' newname];
end
tim = imcrop(cdata, rects{j});
if ( size( size(tim), 2 ) > 2 )
tim = imadjust(rgb2gray(tim));
end
tim = imresize(tim, [SYMB_H SYMB_W], 'lanczos3');
imwrite(tim, [SAVE_DIR '\' recognizedRes(j) '\' newname '.jpg']);
end
end
end
После создания выборки нужно ее почистить от неправильных символов, которые появляются в связи с неточной сегментацией.
Интересным фактом стало то, что в каптче используется всего 23 символа латиницы.
Обучающая выборка присутствует в материалах приложенных к статье.
Этап 3. Обучение нейронной сети
Для обучения нейронной сети использовано Neural Network Toolbox.
Функция обучение описана ниже:
Создание и обучение нейронной сети
function [net, alphabet, inpD, tarD] = train_NN(alphabet_dir, IM_W, IM_H, neuronC)
%inputs:
% alphabet_dir - path to directory with alphabet
% IM_W - image width
% IM_H - image height
% neuronC - count of neuron in hidden layer
%outputs:
% net - trained net
% alphabet - net alphabet
% inpD - input data
% tarD - target data
%
% Vadym Drozd drozdvadym@gmail.com
dirList = dir([alphabet_dir '\']);
dir_name = {dirList([dirList(:).isdir]).name};
alphabetSize = length(dir_name) - 2;
try
a = load([alphabet_dir '\' 'trainData_' num2str(IM_W) 'x' num2str(IM_H) '_.dat'], '-mat');
catch
end
try
target = a.target;
inpData = a.inpData;
alphabet = a.alphabet;
catch
for i = 3 : length(dir_name)
alphabet(i - 2) = dir_name{i};
imgList = dir([alphabet_dir '\' alphabet(i - 2) '\*.jpg']);
t_tar = zeros(alphabetSize, length(imgList));
t_tar(i - 2,:) = 1;
for j = 1 : length(imgList)
im = imread([alphabet_dir '\' dir_name{i} '\' imgList(j).name]);
im = imresize(im, [IM_H IM_W], 'lanczos3'); %resize image
im = imadjust(im);
im = double(im) /255.0;
im = im(:);
if i == 3 && j == 1
inpData = im;
else
inpData = [inpData im];
end
end
if i == 3
target = t_tar;
else
target = [target t_tar ];
end
end
end
%create and train NN
toc
min_max = minmax(inpData);
habrNN = newff(min_max, [IM_H * IM_W neuronC 23], {'logsig', 'tansig','logsig'}, 'trainrp');
habrNN.trainParam.min_grad = 10E-12;
habrNN = train(habrNN, inpData, target);
display('Training time:');
timeE = toc;
display(timeE);
net = habrNN;
inpD = inpData;
tarD= target;
save([alphabet_dir '\' 'trainData_' num2str(IM_W) 'x' num2str(IM_H) '_.dat'], 'inpData', 'target', 'alphabet');
end
Избрана следующая архитектура нейронной сети:

Размер изображений поступающих на вход нейронной сети 10*12 пикселей. Как известно обучение нейронной сети дело непростое, поскольку неизвестно сразу какой должна быть архитектура сети, количество нейронов в каждом из слоев, а также не известно к какому из множества минимумов скатится обучение сети. Поэтому обучение проводилось несколько раз, после чего был выбран один из лучших результатов.
Этап 4. Тестирование алгоритма
Для тестирование алгоритма написан следующий скрипт:
Скрипт для распознавания каптчи
%% captchReader.m
clear; close all; clc;
cdir = './captch/';
fileList = dir([ cdir '\*.png']);
load('49_67_net.mat');
load('alphabet.mat');
N_SYMB = 6;
SYMB_W = 10;
SYMB_H = 12;
WIDTH = 166; %px
HIGH = 75; %px
SHOW_RECT = 1; %1 - show rects, else - don't show
correct = 0; %correct recognized results
correctSymbC = 0;
allSymbC = 0;
for CC = 1 : length(fileList)
imName = fileList(CC).name;
%open image
[cdata, map] = imread( [cdir '\' imName] );
%change color mode
if ~isempty( map )
cdata = ind2rgb( cdata, map );
end
%resize image
cdata = imresize(cdata, [HIGH WIDTH], 'lanczos3');
display(CC);
if ( size( size(cdata), 2 ) > 2 )
cdata = imadjust(rgb2gray(cdata));
end
rects = segmentator(cdata, N_SYMB, 0);
if SHOW_RECT
imshow(cdata);
for i = 1:length(rects)
colors = {'r', 'y', 'b', 'g', 'c', 'm'};
rectangle('Position', rects{i}, 'EdgeColor', colors{i});
end
end
if rects{1} == -1
continue;
end
%recognize
recognized = zeros(1, N_SYMB);
if length(rects) == N_SYMB
for j = 1 : N_SYMB
tim = imcrop(cdata, rects{j});
%resize image
tim = imadjust(imresize(tim, [SYMB_H SYMB_W], 'lanczos3'));
res = net(tim(:));
[sort_res, idx] = sort(res, 'descend');
recognized(j) = alphabet(idx(1));
end
end
correctSymbC = sum( (recognized - imName(1:6)) == 0);
allSymbC = allSymbC + N_SYMB;
if strcmp(recognized, imName(1:6))
correct = correct + 1;
end
if SHOW_RECT
title(['Recognize: ' recognized]);
end
end
fprintf('CAPTCH precision is: %2.2f %%', 100 * correct / length(fileList));
fprintf('Symbol precision: %2.2f %%', 100 * correctSymbC / allSymbC);
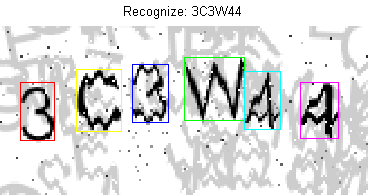
Примеры распознавания:
 |
 |
 |
 |
 |
 |
В результате получили следующие результаты:
Количество правильно распознанных каптч: 49.17 %
Количество правильно распознанных символов: 87.02 %
Выводы
Как оказалось каптча не очень сложная и легко поддается взлому. Для ее усложнения необходимо использовать больше пересечений символов, а также их разное количество.
Чтобы улучшить текущее качество распознавания можно сделать следующие улучшения:
- улучшить алгоритм сегментации (например используя гистограмму)
- увеличить обучающую выборку
Если статья понравилась, в следующей могу подробно рассказать о основных подходах к распознаванию человеческого лица.
Исходники с обучающей выборкой
Исходники. Дропбокс
Яндекс Народ
