В прошлой статье я рассказывал о переменных, теперь пойдет речь о массивах.
На уровне PHP, массив — это упорядоченный список скрещенный с мэпом. Грубо говоря, PHP смешивает эти два понятия, в итоге получается, с одной стороны, очень гибкая структура данных, с другой стороны, возможно, не самая оптимальная, точнее, как выразился Anthony Ferrara:

(на картине изображен HashTable с Bucket-ами, В. Васнецов)
А начнем вот с чего — попробуем замерить память и время, съедаемое на каждое вставляемое значение. Сделаем это с помощью таких скриптов:
Запускаем эти скрипты

(по оси X — кол-во эл-тов в массиве)
Как видно, на обоих графиках есть скачки и по потребляемой памяти и по использованному времени, и эти скачки происходят в одни и те же моменты.
Дело в том, что на уровне C (да и вообще на системном уровне), не бывает массивов, с нефиксированным размером. Каждый раз, когда вы создаете массив в C, вы должны указать его размер, чтобы система знала, сколько нужно памяти на него выделить.
Тогда как это реализовано в PHP и как объянить те скачки на графике?
Когда вы создаете пустой массив, PHP создает его с определенным размером. Если вы заполняете массив и в какой-то момент достигаете и превышаете этот размер, то создается новый массив с вдвое большим размером, все элементы копируются в него и старый массив уничтожается. Вообще, это стандартный подход.
На самом деле, для реализации массивов в PHP, используется вполне себе стандартная структура данных Hash Table, о деталях реализации которой мы и поговорим.
Hash Table хранит в себе указатель на самое первое и последнее значения (нужно для упорядочивания массивов), указатель на текущее значение (используется для итерации по массиву, это то, что возвращает
Зачем
В Hash Table есть две главные сущности, первая — это собственно сам Hash Table, и вторая — это Bucket (далее ведро, чтобы не заскучали).
В ведрах хранятся сами значения, то есть на каждое значение — свое ведро. Но помимо этого в ведре хранится оригинал ключа, указатели на следующее и предыдущее ведра (они нужны для упорядочивания массива, ведь в PHP ключи могут идти в любом порядке, в каком вы захотите), и, опять же, еще кое-что.
Таким образом, когда вы добавляете новый элемент в массив, если такого ключа там еще нет, то под него создается новое ведро и добавляется в Hash Table.
Но что самое интересное — это как в Hash Table хранятся эти ведра.
Как было сказано выше, у HT есть некий массив указателей на ведра, при этом ведра доступны в этом массиве по некоему индексу, а этот индекс можно вычислить зная ключ ведра. Звучит немного сложно, но на самом деле, все гораздо проще чем кажется. Попробуем разобрать, как происходит получение элемента по ключу из HT:
Про маску: допустим массив указателей содержит 4 элемента, таким образом маска равна трем, то есть 11 в двоичной системе.
Теперь если в качестве ключа у нас получится число вроде 123 (1111011), то после наложения маски мы получим 3 (3 & 123), это число уже можно будет использовать как индекс.
После этого попробуем добавить в Hash Table, с маской 3, элементы с ключами 54 и 90. А оба этих ключа после наложения маски будут равны двойки.
У ведер оказывается есть еще пара карт в рукаве. Каждое ведро имеет также указатель на предыдущее и следующее ведро, у которых индексы (хеши от ключей) равны.
Таким образом, помимо основного двусвязного списка, который проходит между всеми ведрами, есть еще и мелкие двусвязные списки между теми ведрами, индексы которых равны. То есть получается примерно следующая картина:

Вернемся к нашему кейсу с ключами 54 и 90, и маской 3. После того, как вы добавите 54, структура HT будет выглядеть примерно так:
Теперь добавим элемент с ключом 90, теперь все будет выглядеть примерно так:
Теперь давайте добавим несколько элементов до переполнения nTableSize (напомню, что переполнение будет только тогда, когда nNumOfElements > nTableSize).
Добавим элементы с ключами 0, 1, 3 (такие, которых еще не было, и после наложения масок они останутся теми же), вот что будет:
То, что происходит после переполнения массива, называется rehash. По сути это итерирование по всем существующим ведрам (через pListNext), назначение их соседей (коллизий) и добавление ссылок на них в arBuckets.
А как же на самом деле происходит получение элемента по ключу? К предыдущему алгоритму добавится еще кое что:
Так до тех пор, пока либо не закончатся ведра в pNext (тогда будет выкинут Notice), либо пока не будет найдено совпадение.
Стоит отметить, что в PHP почти все посторено на одной этой структуре HashTable: все переменные, лежащие в каком-либо scope-е, на самом деле лежат в HT, все методы классов, все поля классов, даже сами дефинишины классов лежат в HT, это на самом деле очень гибкая структура. Помимо прочего, HT обеспечивает практически одинаковую скорость выборки/вставки/удаления и сложность всех троих является O(1), но с оговоркой на небольшой оверхед при коллизиях.
Кстати, здесь я реализовал Hash Table в самом PHP. Ну, то есть, имплементировал PHP-шные массивы в PHP =)
Что такое массивы на уровне PHP?
На уровне PHP, массив — это упорядоченный список скрещенный с мэпом. Грубо говоря, PHP смешивает эти два понятия, в итоге получается, с одной стороны, очень гибкая структура данных, с другой стороны, возможно, не самая оптимальная, точнее, как выразился Anthony Ferrara:
PHP arrays are a great one-size-fits-all data structure. But like all one-size-fits-all <anything>, jack-of-all-trades usually means master of none.
Ссылка на письмо

(на картине изображен HashTable с Bucket-ами, В. Васнецов)
А начнем вот с чего — попробуем замерить память и время, съедаемое на каждое вставляемое значение. Сделаем это с помощью таких скриптов:
// time.php
$ar = array();
$t = 0;
for ($i = 0; $i < 9000; ++$i) {
$t = microtime(1);
$ar[] = 1;
echo $i . ":" . (int)((microtime(1) - $t) * 100000000) . "\n";
}
// memory.php
$ar = array();
$m = 0;
for ($i = 0; $i < 9000; ++$i) {
$m = memory_get_usage();
$ar[] = 1;
echo $i . ":" . (memory_get_usage() - $m) . "\n";
}
Запускаем эти скрипты
php time.php > time и php memory.php > memory, и нарисуем графики по ним, ибо данных много и смотреть на цифры долго (данные по времени были собраны много раз и выровнены, чтобы избежать лишних скачков на графике).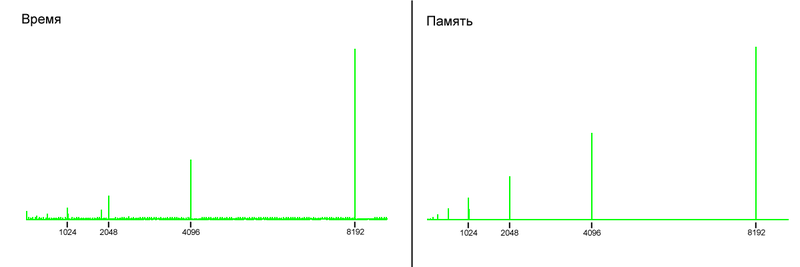
(по оси X — кол-во эл-тов в массиве)
Как видно, на обоих графиках есть скачки и по потребляемой памяти и по использованному времени, и эти скачки происходят в одни и те же моменты.
Дело в том, что на уровне C (да и вообще на системном уровне), не бывает массивов, с нефиксированным размером. Каждый раз, когда вы создаете массив в C, вы должны указать его размер, чтобы система знала, сколько нужно памяти на него выделить.
Тогда как это реализовано в PHP и как объянить те скачки на графике?
Когда вы создаете пустой массив, PHP создает его с определенным размером. Если вы заполняете массив и в какой-то момент достигаете и превышаете этот размер, то создается новый массив с вдвое большим размером, все элементы копируются в него и старый массив уничтожается. Вообще, это стандартный подход.
И как это реализовано?
На самом деле, для реализации массивов в PHP, используется вполне себе стандартная структура данных Hash Table, о деталях реализации которой мы и поговорим.
Hash Table хранит в себе указатель на самое первое и последнее значения (нужно для упорядочивания массивов), указатель на текущее значение (используется для итерации по массиву, это то, что возвращает
current()), кол-во элементов, представленых в массиве, массив указателей на Bucket-ы (о них далее), и еще кое-что.Зачем
нам
ведра нужны
и куда
нам
их ложить
В Hash Table есть две главные сущности, первая — это собственно сам Hash Table, и вторая — это Bucket (далее ведро, чтобы не заскучали).
В ведрах хранятся сами значения, то есть на каждое значение — свое ведро. Но помимо этого в ведре хранится оригинал ключа, указатели на следующее и предыдущее ведра (они нужны для упорядочивания массива, ведь в PHP ключи могут идти в любом порядке, в каком вы захотите), и, опять же, еще кое-что.
Таким образом, когда вы добавляете новый элемент в массив, если такого ключа там еще нет, то под него создается новое ведро и добавляется в Hash Table.
Но что самое интересное — это как в Hash Table хранятся эти ведра.
Как было сказано выше, у HT есть некий массив указателей на ведра, при этом ведра доступны в этом массиве по некоему индексу, а этот индекс можно вычислить зная ключ ведра. Звучит немного сложно, но на самом деле, все гораздо проще чем кажется. Попробуем разобрать, как происходит получение элемента по ключу из HT:
- Если ключ строковый — то происходит хеширование строки до integer-a (используется алгоритм хеширования DJBX33A):
- Первоначальное значение хеша взято за магические 5381
- На каждый символ ключа умножаем хеш на 33 и прибавляем номер символа по ASCII
- На полученый числовой ключ накладывается маска (bitwise and), которая всегда равна размеру массива (который с ведрами) минус 1
- В итоге этот ключ можно использовать как индекс, чтобы вытащить нужный указатель на Bucket из массива
Про маску: допустим массив указателей содержит 4 элемента, таким образом маска равна трем, то есть 11 в двоичной системе.
Теперь если в качестве ключа у нас получится число вроде 123 (1111011), то после наложения маски мы получим 3 (3 & 123), это число уже можно будет использовать как индекс.
После этого попробуем добавить в Hash Table, с маской 3, элементы с ключами 54 и 90. А оба этих ключа после наложения маски будут равны двойки.
Что делать с коллизиями?
У ведер оказывается есть еще пара карт в рукаве. Каждое ведро имеет также указатель на предыдущее и следующее ведро, у которых индексы (хеши от ключей) равны.
Таким образом, помимо основного двусвязного списка, который проходит между всеми ведрами, есть еще и мелкие двусвязные списки между теми ведрами, индексы которых равны. То есть получается примерно следующая картина:

Вернемся к нашему кейсу с ключами 54 и 90, и маской 3. После того, как вы добавите 54, структура HT будет выглядеть примерно так:
{
nTableSize: 4, // размер массива указателей на ведра
nTableMask: 3, // маска
nNumOfElements: 1, // число элементов в HT
nNextFreeElement: 55, // это будет использовано тогда, когда вы захотите добавить элемент в конец массива (без ключа)
...,
arBuckets: [
NULL,
NULL,
0xff0, // представим, что это указатель на Bucket, а сам он описан ниже
NULL
]
}
0xff0: {
h: 54, // числовой ключ
nKeyLength: 0, // это длина ключа, в случае когда он строковый
pData: 0xff1, // указатель на значение, в данном случае на структуру zval
...
}
Теперь добавим элемент с ключом 90, теперь все будет выглядеть примерно так:
{
nTableSize: 4,
nTableMask: 3,
nNumOfElements: 2,
nNextFreeElement: 91,
...,
arBuckets: [
NULL,
NULL,
0xff0, // здесь все так же всего один Bucket
NULL
]
}
0xff0: {
h: 54,
pListNext: 0xff2, // здесь хранится указатель на следующий Bucket по порядку (для итерирования)
pNext: 0xff2, // а сюда попал новый Bucket с таким же хешем
...
}
0xff2: {
h: 90,
pListLast: 0xff0, // это предыдущий элемент
pLast: 0xff0, // а это тот же предыдущий элемент
...
}
Теперь давайте добавим несколько элементов до переполнения nTableSize (напомню, что переполнение будет только тогда, когда nNumOfElements > nTableSize).
Добавим элементы с ключами 0, 1, 3 (такие, которых еще не было, и после наложения масок они останутся теми же), вот что будет:
{
nTableSize: 8, // теперь размер вдвое больше (прям как в той рекламе)
nTableMask: 7,
nNumOfElements: 5,
nNextFreeElement: 91, // это число осталось неизменным
...,
arBuckets: [ // теперь некоторые ведра переместились на новые места, с учетом новой маски и следовательного нового индекса
0xff3, // key = 0
0xff4, // key = 1
0xff2, // key = 90 - теперь здесь сидит ключ 90 (его индекс 90 & 7 = 2), а его бывший сосед съехал на 6-й индекс
0xff5, // key = 3
NULL,
NULL,
0xff0, // key = 54
NULL
]
}
0xff0: {
h: 54,
pListNext: 0xff2, // порядок остался тот же, поэтому это значение неизменно
pNext: NULL, // а здесь теперь ничего
...
}
0xff2: {
h: 90,
pListNext: 0xff3,
pListLast: 0xff0,
pLast: NULL,
...
}
0xff3: {
h: 0,
pListNext: 0xff4,
pListLast: 0xff2,
...
}
0xff4: {
h: 1,
pListNext: 0xff5,
pListLast: 0xff3,
...
}
0xff5: {
h: 3,
pListNext: NULL, // он был добавлен последним
pListLast: 0xff4,
...
}
То, что происходит после переполнения массива, называется rehash. По сути это итерирование по всем существующим ведрам (через pListNext), назначение их соседей (коллизий) и добавление ссылок на них в arBuckets.
А как же на самом деле происходит получение элемента по ключу? К предыдущему алгоритму добавится еще кое что:
- Если ключ строковый — то происходит хеширование строки до integer-a (используется алгоритм хеширования DJBX33A):
- Первоначальное значение хеша взято за магические 5381
- На каждый символ ключа умножаем хеш на 33 и прибавляем номер символа по ASCII
- На полученый числовой ключ накладывается маска (bitwise and), которая всегда равна размеру массива (который с ведрами) минус 1
- Вытаскиваем ведро по индексу
- Если ключ этого ведра равен искомому — поиск завершен, иначе:
- В цикле берем ведро из pNext (если существует) и смотрим равен ли ключ
Так до тех пор, пока либо не закончатся ведра в pNext (тогда будет выкинут Notice), либо пока не будет найдено совпадение.
Стоит отметить, что в PHP почти все посторено на одной этой структуре HashTable: все переменные, лежащие в каком-либо scope-е, на самом деле лежат в HT, все методы классов, все поля классов, даже сами дефинишины классов лежат в HT, это на самом деле очень гибкая структура. Помимо прочего, HT обеспечивает практически одинаковую скорость выборки/вставки/удаления и сложность всех троих является O(1), но с оговоркой на небольшой оверхед при коллизиях.
Кстати, здесь я реализовал Hash Table в самом PHP. Ну, то есть, имплементировал PHP-шные массивы в PHP =)
