
Многие C++ программисты, пишущие под Windows часто путаются над этими странными идентификаторами как TCHAR, LPCTSTR. В этой статье я попытаюсь наилучшим способом расставить все точки над И. И рассеять туман сомнений.
В свое время я потратил много времени копаясь в исходниках и не понимал что значат эти загадочные TCHAR, WCHAR, LPSTR, LPWSTR,LPCTSTR.
Недавно нашел очень грамотную статью и представляю ее качественный перевод.
Статья рекомендуется тем кто бессонными ночами копошиться в кодах С++.
Вам интересно ??
Прошу под кат!!!
В общем, символ строки может быть представлен в виде 1-го байта и 2-х байтов.
Обычно одно-байтовый символ это символ кодировки ANSI- в этой кодировке представлены все английские символы. А 2-х байтовый символ это кодировка UNICODE, в которой могут быть представлены все остальные языки в мире.
Компилятор Visual C++ поддерживает char и wchar_t как встроенные типы данных для кодировок ANSI и UNICODE.Хотя есть более конкретное определение Юникода, но для понимания, ОС Windows использует именно 2-х байтовую кодировку для много языковой поддержки приложений.
Для представления 2-х байтовой кодировки Юникод Microsoft Windows использует UTF16-кодирование.
Microsoft стала одна из первых компаний которая начала внедрять поддержку Юникода в своих операционных системах (семейство Windows NT).
Что делать если вы хотите чтобы ваш С/С++ код был независимым от кодировок и использование разных режимов кодирования?
СОВЕТ. Используйте общие типы данных и имена для представления символов и строк.
Например, вместо того чтобы менять следующий код:
char cResponse; // 'Y' or 'N'
char sUsername[64];
// str* functions (с типом char работают функции который начинаются с префикса str*)
На этот!!!
wchar_t cResponse; // 'Y' or 'N'
wchar_t sUsername[64];
// wcs* functions (с типом wchar_t работают функции который начинаются с префикса wcs*)
В целях поддержки многоязычных приложений (например, Unicode), вы можете писать код в более общей манере.
#include<TCHAR.H> // Implicit or explicit include
TCHAR cResponse; // 'Y' or 'N'
TCHAR sUsername[64];
// _tcs* functions (с типом TCHAR работают функции который начинаются с префикса _tcs*)
В настройках проекта на вкладке GENERAL есть параметр CHARACTER SET который указывает в какой кодировке будет компилироваться программа:
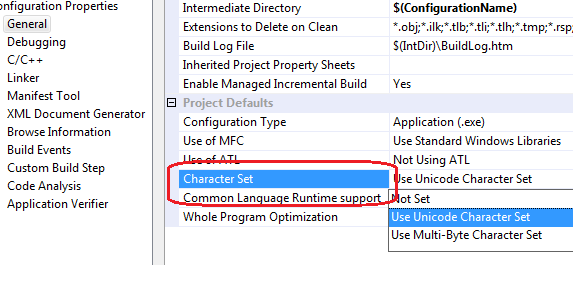
Если указан параметр «Use Unicode Character set», тип TCHAR будет транслироваться в тип wchar_t. Если указан параметр «Use Multi-byte character set» то тогда TCHAR будет транслироваться в тип char. Вы можете свободно использовать типы char и wchar_t, и настройки проекта никоим образом не повлияют на использование этих ключевых слов.
TCHAR определен так:
#ifdef _UNICODE
typedef wchar_t TCHAR;
#else
typedef char TCHAR;
#endif
Макрос _UNICODE будет включен если вы укажите «Use Unicode Character set» и тогда тип TCHAR будет определен как wchar_t. Когда же вы укажите «Use Multi-byte character set» TCHAR будет определен как char.
Помимо этого, для того что была поддержка нескольких наборов символов используя общий базовый код, и возможно поддержки много языковых приложений, используйте Специфические функции (то есть макросы).
Вместо того чтобы использовать strcpy, strlen, strcat (в том числе защищенные варианты функции с префиксом _s), или wcscpy, wcslen, wcscat (включая защищенные варианты), вам лучше использовать функции _tcscpy, _tcslen, _tcscat.
Как вы знаете функция strlen описана так:
size_t strlen(const char*);
И функция wcslen описана так:
size_t wcslen(const wchar_t* );
Вам лучше использовать _tcslen, который логически описан так:
size_t _tcslen(const TCHAR* );
WC это Wide Character (Большой символ). Поэтому, wcs функции будут для wide-character-string (то есть для большой-символьной-строки).Таким образом _tcs будет означать _T символьная строка. И как вы знаете строки с префиксом _T могут быть типа char или wchar_t.
Но в реальности _tcslen (и другие функции с префиксом _tcs) вовсе не функции, это макросы. Они просто описаны как:
#ifdef _UNICODE
#define _tcslen wcslen
#else
#define _tcslen strlen
#endif
Вы можете просмотреть заголовочный файл TCHAR.H и поискать там еще Макро описания похожее на вышеупомянутое.
Таким образом TCHAR оказывается вовсе не типом, а надстройкой над типами char и wchar_t. Позволяя тем самым выбирать мульти язычное приложение у нас будет или же все таки, одно язычное.
Вы спросите почему они описаны как макросы, а не как полноценная функция ??
Причина проста: Библиотека или DLL могут экспортировать простую функцию с тем же именем и прототипом (Исключая концепцию перегрузки в С++).
Для примера если вы экспортируете функцию:
void _TPrintChar(char);
Как должен вызывать ее клиент ?? Как:
void _TPrintChar(wchar_t);
_TPrintChar магическим образом может быть преобразована в функцию принимающая двух байтовый символ в качестве аргумента.
Для этого мы сделаем две различные функции:
void PrintCharA(char); // A = ANSI ( для однобайтового)
void PrintCharW(wchar_t); // W = Wide character (для двухбайтового)
И простой макрос скроет разницу между ними:
#ifdef _UNICODE
void _TPrintChar(wchar_t);
#else
void _TPrintChar(char);
#endif
Клиент просто вызовет функцию как
TCHAR cChar;
_TPrintChar(cChar);
Заметьте, что TCHAR и _TPrintChar теперь будут сопоставимы с UNICODE или ANSI, а переменная cChar и параметр функции будет сопоставим с типом данных char или wchar_t.
Макросы дают нам обойти эти сложности, и позволяют нам использовать ANSI или UNICODE функции для наших символов и строк. Множество функций Windows описаны именно таким образом, и для программиста есть только одна функция (то есть макрос) и это хорошо.
Приведу пример с SetWindowText:
// WinUser.H
#ifdef UNICODE
#define SetWindowText SetWindowTextW
#else
#define SetWindowText SetWindowTextA
#endif // !UNICODE
Есть только несколько функций у которых нету таких макросов, и они только с суффиксом W или A. Пример тому функция ReadDirectoryChangesW, которая не имеет эквивалента в кодировки ANSI.
Как вы знаете, мы используем двойные кавычки для представления строк. Строка представленная в этой манере это ANSI-строка, на каждый символ используется 1 байт. Приведу пример:
“Это ANSI строка. Каждый символ занимает 1 байт.”
Указанная верху строка не является строкой UNICODE, и не подходит для много языковой поддержки. Для того чтобы получить UNICODE строку вам надо использовать префикс L.
Приведу пример:
L”Это Unicode строка. Каждый символ которого занимает 2 байта, включая пробелы. ”
Поставьте спереди L и вы получите UNICODE строку. Все символы (Я повторяю все символы ) занимают 2 байта, включая Английские буквы, пробелы, цифры и символ null. Объем данных строки Unicode всегда будет кратен 2-м байтам. Строка Unicode длиной 7 символов будет занимать 14 байтов. Если строка Unicode занимает 15 байтов то это не правильная строка, и она не будет работать в любом контексте.
Также, строка будет кратна размеру sizeof(TCHAR) в байтах.
Когда Вам нужно жестко прописанный код, вы можете писать код так:
"строка ANSI"; // ANSI
L"строка Unicode"; // Unicode
_T("Или строка, зависящая от компиляции"); // ANSI или Unicode
// или используйте макрос TEXT, если вам нужна хорошая читаемость кода
Строки без префикса это ANSI строки, с префиксом L строки Unicode, и строки с префиксом _T и TEXT зависимые от компиляции. И опять же _T и TEXT это снова макросы. Они определены так:
// УПРОЩЕННАЯ
#ifdef _UNICODE
#define _T(c) L##c
#define TEXT(c) L##c
#else
#define _T(c) c
#define TEXT(c) c
#endif
Символ ## это ключ(token) вставки оператора, который превратит _T(«Unicode») в L«Unicode», где строка это аргумент для макроса- если конечно _UNICODE определен.
Если _UNICODE не определен то _T(«Unicode») превратит это в «Unicode». Ключ вставки оператора существовал даже в языке С, и это не специфическая вещь связанная с кодировкой строк в VC++.
К сведению, макросы могут применятся не только для строк но и для символов. Например _T('R') превратит это в L'R' ну или в просто 'R'. Тоесть либо в Unicode символ либо в ANSI символ.
Нет и еще раз нет, вы не можете использовать макрос чтобы конвертировать символ или строку в Unicode и не Unicode текст.
Следующий код будет неправильным:
char c = 'C';
char str[16] = "Habrahabr";
_T( c );
_T(str);
Строки _T( c); _T(str); отлично скомпилируются в режиме ANSI, _T(x) превратится в x, и _T( c) вместе с _T(str) превратятся просто в c и str.
Но когда вы будете собирать проект в режиме Unicode код не с компилируется:
error C2065: 'Lc' : undeclared identifier
error C2065: 'Lstr' : undeclared identifier
Я не хотел бы вызывать инсульт вашего интеллекта и объяснять почему это не работает.
Существует несколько функций для конвертирования Мульбайтовых строк в UNICODE, о которых я скоро расскажу.
Есть важное замечание, почти все функции которые принимает строку или символ, приоритетно в Windows API, имеют обобщенное название в MSDN и в других местах.
Функция SetWindowTextA/W будет классифицирована как:
BOOL SetWindowText(HWND, const TCHAR*);
Но как Вы знаете, SetWindowText это просто макрос, и в зависимости от настроек проекта будет рассматриваться как:
BOOL SetWindowTextA(HWND, const char*);
BOOL SetWindowTextW(HWND, const wchar_t*);
Так что не ломайте голову если не сможете получить адрес этой функции:
HMODULE hDLLHandle;
FARPROC pFuncPtr;
hDLLHandle = LoadLibrary(L"user32.dll");
pFuncPtr = GetProcAddress(hDLLHandle, "SetWindowText");
//значение pFuncPtr будет null, потому что фунций с названием SetWindowText даже не существовало
В библиотеке User32.DLL, имеются 2 функции SetWindowTextA и SetWindowTextW которые экспортируются, то есть тут нет имен с обобщенным названием.
Все функции которые имеют ANSI и UNICODE версию, вообще то имеют только UNICODE реализацию. Это значит, что когда Вы вызываете SetWindowTextA из своего кода, передавая параметр ANSI строку — она конвертирует ANSI в UNICODE вызывает SetWindowTextW.
Реальную работу (установку заголовка/названия/метки окна) делает только Unicode версия!
Возьмем другой пример, который будет получать текст окна, используя GetWindowText.
Вы вызываете GetWindowTextA передавая ему ANSI буфер как целевой буфер.
GetWindowTextA сначала вызовет GetWindowTextW, возможно выделяя память для Unicode строки (т.е массив wchar_t).
Затем он с конвертирует Unicode в ANSI строку для вас.
Эти ANSI в Unicode преобразования не ограничение только GUI функций, а так работает все подмножество Windows API функций, которое принимает строки и имеет два варианта.
Приведу еще пример таких функций:
- CreateProcess
- GetUserName
- OpenDesktop
- DeleteFile
- итд
Поэтому очень рекомендуется вызывать напрямую Unicode функции.
В свою очередь, это означает, что вы всегда должны быть нацелены на сборку Unicode версии, а не на сборку ANSI версии, учитывая тот факт, что вы привыкли использовать ANSI строки в течение многих лет.
Да вы можете сохранять и получать ANSI строки, например для записи в файл, или отправки сообщения чата в ваше программе-чата. Функции конвертации существуют для таких нужд.
Замечание: Есть еще одно описание типа: имя ему WCHAR – оно эквивалентно wchar_t.
TCHAR это макрос, для декларирования одного символа. Вы также можете декларировать массив TCHAR. А что если Вы например захотите описать указатель на символы или, константный указатель на символы.
Приведу пример:
// ANSI символы
foo_ansi(char*);
foo_ansi(const char*);
/*const*/ char* pString;
// Unicode/wide-string
foo_uni(WCHAR*);
wchar_t* foo_uni(const WCHAR*);
/*const*/ WCHAR* pString;
// Независимые
foo_char(TCHAR*);
foo_char(const TCHAR*);
/*const*/ TCHAR* pString;
После чтения фишек с TCHAR, вы наверное предпочтете использовать именно его. Существуют еще хорошие альтернативы для представления строк в вашем коде. Для этого надо просто включить Windows.h в проект.
Примечание: Если ваш проект включает windows.h (косвенным или прямым образом), вы не должны включать в проект TCHAR.H.
Для начала пересмотрим старую функцию, чтобы было легче понять. Пример функцию strlen.
size_t strlen(const char*);
Которая может быть представлена по другому.
size_t strlen(LPCSTR);
Где LPCSTR описан как:
// Simplified
typedef const char* LPCSTR;
LPCSTR понимается так.
• LP — Long Pointer (длинный указатель)
• C – Constant (константа)
• STR – String (строка)
По сути LPCSTR это (Длинный) указатель на строку.
Давайте изменим strcpy в соответствие с новым стилем имени типов:
LPSTR strcpy(LPSTR szTarget, LPCSTR szSource);
szTarget имеет тип LPSTR, без использования типов языка С. LPSTR определен так:
typedef char* LPSTR;
Заметьте что szSource имеет тип LPCSTR, так как функция strcpy не модифицирует исходный буфер, поэтому выставлен атрибут const. Возвращаемый тип данных не константная строка: LPSTR.
Итак, функции с префиксом str для манипуляции с ANSI строками. Но нам нужна еще для двух байтовых Unicode строк. Для тех же больших символов имеются эквивалентные функции.
Для примера, чтобы посчитать длину символов больших символов(Unicode строки), вы будете использовать wcslen:
size_t nLength;
nLength = wcslen(L"Unicode");
Прототип функции wcslen такой:
size_t wcslen(const wchar_t* szString); // Или WCHAR*
И код выше может быть представлен по другому:
size_t wcslen(LPCWSTR szString);
Где LPCWSTR описан так:
typedef const WCHAR* LPCWSTR;
// const wchar_t*
LPCWSTR можно понять так:
LP — Long Pointer (Длинный указатель)
C — Constant (константа)
WSTR — Wide character String (строка больших символов)
Аналогичным образом, strcpy эквивалент wcscpy, для Unicode строк:
wchar_t* wcscpy(wchar_t* szTarget, const wchar_t* szSource)
Который может быть представлен как:
LPWSTR wcscpy(LPWSTR szTarget, LPWCSTR szSource);
Где szTarget это не константная большая строка (LPWSTR), а szSource константная большая строка.
Существует ряд эквивалентных wcs-функций для str-функций. str-функции будут использоваться для простых ANSI строк, а wcs-функции для Unicode строк.
Хотя Я уже советовал что надо использовать native Unicode функции, а не только ANSI или только синтезированные TCHAR функции. Причина проста — ваше приложение должно быть только Unicode-ным, и вы не должны заботится о том что спортируются ли они для ANSI. Но для полноты картины я и упомянул эти общие отображения (проецирования)!!!
Чтобы вычислить длину строки, вы можете использовать _tcslen функцию (макро).
Который описан так:
size_t _tcslen(const TCHAR* szString);
Или так:
size_t _tcslen(LPCTSTR szString);
Где имя типа LPCTSTR можно понять так
LP — Long Pointer (Длинный указатель)
C — Constant (Константа)
T = TCHAR
STR = String (Строка)
В зависимости от настроек проекта, LPCTSTR будет проецироваться в LPCSTR (ANSI) или в LPCWSTR (Unicode).
Заметьте: функции strlen, wcslen или _tcslen будут возвращать количество символов в строке, а не количество байтов.
Обобщенная операция копирования строки _tcscpy описана так:
size_t _tcscpy(TCHAR* pTarget, const TCHAR* pSource);
Или в еще более обобщенной манере, как:
size_t _tcscpy(LPTSTR pTarget, LPCTSTR pSource);
Вы можете догадаться что значит LPTSTR ))
Примеры использования.
Во первых приведу пример нерабочего кода:
int main()
{
TCHAR name[] = "Saturn";
int nLen; // Or size_t
lLen = strlen(name);
}
На ANSI сборке, этот код успешно с компилируется потому что TCHAR будет типом char, и переменная name будет массивом char. Вызов strlen для name тоже будет прекрасно работать.
Итак. Давайте с компилируем тоже самое с включенными UNICODE/_UNICODE (в настройках проекта выберите «Use Unicode Character Set»).
Теперь компилятор будет выдавать такого рода ошибки:
error C2440: 'initializing' : cannot convert from 'const char [7]' to 'TCHAR []'
error C2664: 'strlen' : cannot convert parameter 1 from 'TCHAR []' to 'const char *'
И программисты начнут исправлять ошибку таким образом:
TCHAR name[] = (TCHAR*)"Saturn";
И это не усмирит компилятор, потому что конвертирование из TCHAR* в TCHAR[7] невозможно. Такая же ошибка будет возникать когда встроенные ANSI строки передаются Unicode функции:
nLen = wcslen("Saturn");
// error: cannot convert parameter 1 from 'const char [7]' to 'const wchar_t *'
// Ошибка: не могу с конвертировать параметр 1 из 'const char [7]' в 'const wchar_t *'
К сожалению (или к счастью), эта ошибка может быть неправильно исправлена простым приведением типов языка C.
nLen = wcslen((const wchar_t*)"Saturn");
И вы думаете что повысили уровень своего опыта при работе с указателями. ВЫ не правы -этот код будет давать неправильный результат, и в большинстве вы будете получать Access Violation (нарушение доступа). Приведение типов таким образом это как передача float-переменной когда ожидалось(логически) структура размером 80 байт.
Строка «Saturn» это последовательность 7 байт:
| 'S' (83) | 'a' (97) | 't' (116) | 'u' (117) | 'r' (114) | 'n' (110) | '\0' (0) |
Но когда вы передаете тот же набор байтов в wcslen, он рассматривает каждые 2 байта как один символ. Поэтому первые 2 байта [97,83] будут рассматриваться как один символ имеющий значение 24915(97<<8 | 83). Это Unicode символ ???.. И другие следующие символы рассматриваются как [117,116] и так далее.
Конечно вы не передавали эти Китайские символы, но приведение типов сделало это за Вас!!!
И поэтому очень важно знать что приведение типов не будет работать. Итак для инициализации первой строки вы должны сделать следующее:
TCHAR name[] = _T("Saturn");
Который будет транслировать в 7 или в 14 байт, в зависимости от компиляции.
Вызов wcslen должен быть таким:
wcslen(L"Saturn");
В примере кода программы, приведенные выше, я использовал strlen, что вызывает ошибки при сборке Unicode.
Приведу пример нерабочего решение с приведением типов языка C:
lLen = strlen ((const char*)name);
На сборках Unicode переменная name будет размером 14 байт (7 unicode символов, включая null). Так как строка
«Saturn» содержит только Английские символы, которые можно представить используя ASCII кодирование, Unicode символ 'S' будет представлен как [83, 0]. Следующие ASCII символы будут представлены как нули. Заметьте сейчас символ 'S' представлен как 2-х байтовое значение 83. Конец строки будет представлен как 2 байта имеющее значение 0.
Итак, когда вы передаете такую строку в strlen, первый символ (то есть первый байт) будет правильным ('S' в случае с 'Saturn'). Но следующий символ/байт будет идентифицирован как конец строки. Поэтому, strlen вернет неправильное значение 1.
Как Вы знаете, Unicode строка может содержать не только Английские символы, и результат strlen будет еще более неопределенным.
Короче говоря приведение типов не будет работать.
Вам придется, либо представлять строки в правильной форме, или использовать функции конвертирования ANSI в Unicode, и обратно.
Теперь, Я надеюсь Вы понимаете следующий код:
BOOL SetCurrentDirectory( LPCTSTR lpPathName );
DWORD GetCurrentDirectory(DWORD nBufferLength,LPTSTR lpBuffer);
Продолжая тему. Вы наверное видели некоторые функции/методы которым нужно передавать количество символов, или возвращающие количество символов. Впрочем есть GetCurrentDirectory, в которую надо передавать число символов, а не количество байт.
Пример:
TCHAR sCurrentDir[255];
// Передавайте 255 а не 255*2
GetCurrentDirectory(sCurrentDir, 255);
С другой стороны, если вам нужно выделять память для нужного количества символов, вы должны выделять надлежащее количество байт. В C + +, вы можете просто использовать оператор new:
LPTSTR pBuffer; // TCHAR*
pBuffer = new TCHAR[128]; // Выделяет 128 или 256 байт, в зависимости от компиляции.
Но если вы используете функции выделения памяти, такие как malloc, LocalAlloc, GlobalAlloc, и т.д., вы должны указывать количество байт!
pBuffer = (TCHAR*) malloc (128 * sizeof(TCHAR) );
Как вы знаете необходимо приведение типа возвращаемого значения. Выражение в аргументе malloc гарантирует, что оно выделяет необходимое количество байт — и выделяет места для нужного количества символов.
P.S.
Оригинал статьи
Всех с НГ!!!
