 В мои руки попала отладочная плата мультиклета, и результатами его тестирования хочу поделится. Также расскажу и о нескольких подводных камнях, которые на первых порах могут несколько подпортить нервы тем, кто захочет лично потрогать Мультиклет.
В мои руки попала отладочная плата мультиклета, и результатами его тестирования хочу поделится. Также расскажу и о нескольких подводных камнях, которые на первых порах могут несколько подпортить нервы тем, кто захочет лично потрогать Мультиклет.Сразу стоит заметить, что я рассматриваю только разработку на C (а не на Ассемблере) т.к. нынче время работы программистов стоит дороже мегагерцев и памяти. У С-компилятора Мультиклета тяжелая судьба, и на _данный момент_ он находится в зачаточном состоянии (в частности, не реализованы какие-либо оптимизации). Ситуация обещает исправиться к середине/концу года.
Железо

Это отладочный комплект НW1-MCp04 (более старый и дорогой). Процессор тут работает на частоте 80Мгц. Разведены интерфейсы RS232, установлены контроллеры USB(1.1, Full-Speed, 12Mbit) и LAN (10/100 MBit). Какой-либо программной поддержки USB и LAN на данный момент нет.
«IDE»
IDE Мультиклета представляет собой PSPad с забиндеными горячими кнопками для компиляции и загрузки бинарника в отладочную плату. Такая IDE мне показалась бесполезной, но к счастью, собирать проект и заливать прошивку в плату можно и скриптами:Компиляция:
MultiClet\SDK\shell\MultiClet\build_project.cmd <директория с исходниками>Из коробки скрипт компиляции не заработал — т.к. внутри не был указан путь к платформо-зависимым инклудам, добавить его можно и самому:
rem Ключи запуска препроцессора компилятора Си
set CPP_KEYS=%CPP_KEYS% -Wp-I.. -Wp-I"%INCDIR%" -Wp-I"[..ваш путь..]\MultiClet\Projects\inc\c"Заливка прошивки в плату:
MultiClet\SDK\bin\mc-ploader <файл с собранным бинарником>Чтобы работала заливка прошивки — нужно установить драйверы для PicoTap. К сожалению, сами драйверы PicoTap не подписаны (!?!), соответственно загрузить их затруднительно. Если отключить в Windows проверку подписи драйверов — то Windows (8 x64) блокирует их загрузку из-за известной несовместимости.
Решение — руками выбрать для PicoTap драйвер FTDI, и проигнорировать предупреждение Windows что ей не кажеться что этот драйвер подойдет. Это заставляет надеяться что создание самодельного адаптора на FTDI-чипе вполне возможно.
Внутрисхемной отладки нет.
Пишем Hello World
Выводить сообщения будем через RS232. При соединении с компьютером в стандартном кабеле папа-мама нужно поменять местами пины RX и TX (2 и 3). Берем стандартный пример uart, перенастраиваем его на скорость работы 115200 бод:void uart_init(UART_TypeDef *UART)
{
int port, bitrate, control;
port = 0x00000300; //alternative port function for uart0
bitrate = 0x56;//115200 bps
control = 0x00000003; //rx, tx enable
GPIOB->BPS = port;
UART->BDR = bitrate;
UART->CR = control;
}Дописываем функцию вывода строки и вывода символа с проверкой на переполнение буфера UART:
void uart_send_with_delay(char byte, UART_TypeDef *UART)
{
while(uart_fifo_full(UART0) == 1);
uart_send_byte(byte, UART);
}
void uart_puts(char *msg, UART_TypeDef *UART)
{
while(*msg)uart_send_with_delay(*msg++, UART);
}
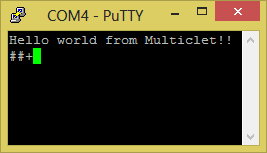
void main()
{
uart_init(UART0); //config uart0
uart_puts("Hello world from Multiclet!!\r\n", UART0);
}Практическая производительность
Возьмем простейшую программу для теста:float i,j,result;
for(i=0;i<1;i+=0.0002)
for(j=0;j<1;j+=0.0002)
{
result+=i*j;
}Тело внутреннего цикла выполняется 25 млн раз. На Мультиклете с частотой 80Мгц этот код работает 20.3 секунды с текущим компилятором. Посчитаем, какой производительности абстрактного классического процессора соответствуют эти цифры: 25млн циклов * ~5 операций за иттерацию цикла / 20.3 секунды — 6.1 млн операций в секунду.
Т.е. производительность на данный момент получается на уровне абстрактного не-суперскалярного процессора с частотой 5-10Мгц. Безусловно, производительность будет существенно улучшена по мере развития компилятора.
Если мы немного поможем компилятору, и руками развернем цикл:
for(i=0;i<1;i+=0.0002)//8 seconds
for(j=0;j<1;j+=0.0008)
{
result+=i*j+i*(j+0.0002)+i*(j+0.0004)+i*(j+0.0006);
}Теоретическая производительность
Наконец, стало окончательно ясно, какая теоретически-достижимая производительность у Мультиклета при идеальном распараллеливании на частоте 100Мгц:2.4 GFLOP: Если все 4 клетки выполняют только операцию комплексного умножения, и больше ничего.
800 MFLOP: Если все 4 клетки выполняют остальные арифметические операции в упакованном виде (т.е. одна и та же операция выполняется над обоими 32-х битными половинками).
400 MFLOP — Если у нас операции нужно делать только по одному разу, а не парами (как обычно это бывает на не-вычислительном коде).
Наконец, если у нас распараллеливание на все 4 клетки не получается — то рассчитывать можно будет только на 150-300 MFLOP.
Вручную оптимизированный на ассемблере код быстрого преобразования фурье с практически идеальным распараллеливанием, с вырезанными блоками сохранения-загрузки (разработчики уверяют что в будущем их удасться соптимизировать) дает ~1.2 GFLOP (меньше 2.4 получается именно потому что не все операции — комплексное умножение, нужны еще сложения/вычитания и другие).
Потребление энергии
При максимальной нагрузке:1.8V — 0.39A
3.3V — 7.2mA
Соответственно, потребляемая мощность — 0,725Вт на частоте 80Мгц (на 100Мгц будет выше).
При зажатом reset-е потребление падает до 0.3А по шине 1.8V, и 0.8ма по шине 3.3V.
Резюме
С текущим состоянием C-компилятора производительность фатально низкая (соответствующая 5-10Мгц абстрактного не-суперскалярного процессора) из-за не оптимизированного кода. Вся надежда на то, что разработчики компилятора за 2013 год его допилят, и Мультиклет тогда сможет конкурировать с другими отечественными разработками.PS. В противники Мультиклета меня записывать не стоит — я обоими руками за то, чтобы у него все работало отлично и он всех рвал, и также обоими руками за отечественную микроэлектронику.
PPS. Насчет вопроса о том, как должен работать удаленный доступ я вполне серьёзно — пока у меня нет идей кроме прошивать присланный бинарник и присылать обратно все, что вываливается из RS232.
Only registered users can participate in poll. Log in, please.
Стоит ли организовать публичный удаленный доступ к отладочной плате Мультиклета?
58.39% Да, интересно и самому поковырять (а в комментариях напишу, как это по моему мнению должно работать)160
41.61% Нет, мне и так все ясно.114
274 users voted. 172 users abstained.
