Я давно регулярно читаю Хабр и заметил, что здесь довольно мало внятных статей о локализации ПО, ориентированных на разработчиков. По своему опыту управления проектами локализации я могу сказать, что локализация — это не только перевод строк и адаптация приложения к контексту той или иной страны, но и постоянное противоборство (в идеальных случаях — равноправное взаимодействие) с разработчиками.
В этой статье я постараюсь на примере показать, как можно создать так называемый localization-friendly code, то есть, организовать ресурсы таким образом, чтобы существенно облегчить локализацию приложения, снизив избыточные временные и финансовые затраты.
Сразу же оговорюсь, что речь пойдёт в первую очередь об интернационализации, то есть, об учёте всех лингвистических особенностей на этапе разработки. Если же ресурсы вашего проекта изначально не подразумевали локализацию, а впоследствии вы решились на неё, то их «затачивание» под локализацию может выйти намного дороже, чем доход от неё.

В большинстве случаев вопрос о кодировке UTF-8 (или UTF-16) встаёт при планировании локализации на азиатские языки, где количество символов может достигать нескольких тысяч. Даже если в данный момент локализация на корейский или китайский языки не планируется, стоит позаботиться об универсальной кодировке заранее. Если стратегия локализации вашего продукта изменится, то перескакивать на ходу на другую кодировку будет намного сложнее. Совет: для всех ресурсов используйте Unicode по умолчанию, даже если проект пока только на русском/английском/любом другом языке.
Кстати, например, спецификации JSON и YAML (эти форматы нередко используются для хранения локализуемых ресурсов) предписывают использование Unicode.
Эта, вроде бы мелочь, часто является критичным фактором, тормозящим локализацию. Убедитесь, что используемые вами шрифты имеют символы для языков локализации (в первую очередь, опять же, азиатские языки, а также иврит, арабский и диакритика европейских языков).
Помните, что
ä, à или ą ≠ a
также как и в русском «е» не всегда равно «ё».
В моей практике был случай, когда разработчики сами нарисовали шрифт, содержащий набор букв только для английского языка. Когда дело дошло до локализации на немецкий и польский языки, им пришлось дорисовывать буквы с диакритическими знаками.
Помимо шрифтов перевод текстов приложения готовит ещё один подводный камень для вёрстки.
Сравните, как может переводиться один пункт меню на разные языки
ru: Сохранить как
en: Save as
fi: Tallenna nimellä
zh: 另存为
Если для китайского языка нам потребуется всего 3 символа, то для финского уже целых 16! Кроме того, помимо количества символов важны также особенности того или иного шрифта.

Сравним финскую и китайскую строку по длине (шрифт для обоих языков Arial Unicode MS, 12 кегль) — финский текст (114 пикселей) в 2,5 раза длиннее китайского (45 пикселей).
Поэтому в элементах интерфейса очень важно иметь место про запас, чтобы исключить обрезание отображаемого текста. Если в определённых случаях места не хватает, можно использовать автоматическую подгонку текста по размеру. Однако это решение приведёт к тому, что в разных элементах интерфейса с большой вероятностью будет отображаться текст разного размера.
Увидеть проблемные места до начала перевода поможет такой приём как псевдолокализация. Она является одним из методов тестирования приложений для проверки их готовности к локализации. Суть её заключается в том, что вместо перевода в ресурсы подставляется текст на псевдоязыке, созданный по специальному алгоритму (зависит от используемого программного обеспечения). Самый примитивный пример: вместо английского текста подставляется транслитерация/транскрипция кириллическими буквами:
Save as -> Саве ас
Save as -> Сэйв аз
Такой метод позволяет проверить следующие моменты:
При псевдолокализации нередко используют машинный перевод на нужный язык. С одной стороны, это простое решение в случае отсутствия специальных средств для генерации псевдоперевода. С другой стороны, я уже не раз видел, как разработчики путали локализованные ресурсы с псевдолокализованными и даже по недосмотру заменяли нормальный перевод машинным в репозиториях. Кроме того, машинный перевод не всегда позволяет оценить отображение всех символов языка (например, буква œ не так часто встречается в текстах, но её отображение тоже необходимо протестировать).
Например, так выглядит интерфейс плагина псевдоперевода в программе memoQ:
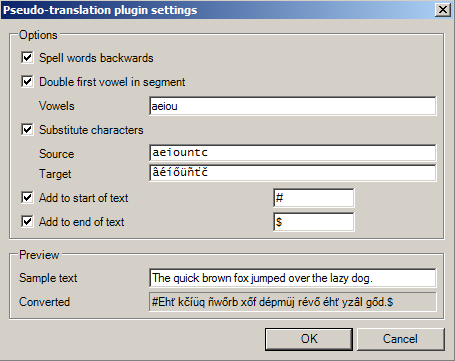
А вот так выглядит результат с этими настройками:

Для того, чтобы иметь полный обзор локализуемых материалов, необходимо отделить все ресурсы от кода. Мультимедийную информацию, содержащую текст (чаще всего это изображения, а также видео и аудио, например, в играх), следует также хранить отдельно, с сортировкой по локалям. Во-первых, это существенно упростит работу создателям контента, им не нужно будет копаться в коде, чтобы исправить какое-нибудь системное сообщение. Во-вторых, это позволит менеджеру по локализации точно рассчитать сроки и бюджет для каждого языка. В-третьих, это позволит быть несравнимо гибкими в работе с многоязычным контентом.
Наиболее популярными форматами для обмена локализуемыми данными являются XLIFF и .po-файлы. Так или иначе современные системы автоматизированного перевода в состоянии преобразовывать любые файлы в понятные переводчикам форматы.
Google и Apple тоже настоятельно советуют разработчикам извлекать все ресурсы для локализации во вне: рекомендации для разработчиков под Android, рекомендации Apple по интернационализации.
В продолжение предыдущего пункта стоить рассказать о важном моменте. Локализация подразумевает не только перевод слов, но и адаптацию чисел, единиц измерения, форматов даты и времени, а также знаков препинания к локальным стандартам.
Многие разработчики любят «зашивать» знаки препинания в код, думая, что точки и вопросительные знаки-то уж точно во всех языках одинаковые. Но сравните:
ru:
en:
fr:
es:
ar:
Во французском языке вопросительный знак отделяется пробелом (кстати говоря, Хабр пробел перед знаком вопроса упорно убирал, пришлось колдовать с тегами). В испанском вопросительный знак состоит из перевёрнутого в начале и обычного в конце фразы, а в арабском он вообще стоит слева и обращён в другую сторону. Если вопросительный знак будет подставляться из кода, то не всем пользователям будет комфортно читать такое сообщение (разве что в коде не будет прописана зависимость от локали, но зачем такие извращения?).
Помимо знаков препинания, нужно быть осторожными с пробелами, доверяя коду их принудительную вставку. Ведь есть языки, где пробелы между словами не используются — например, японский.
Говорят, что локализация японских или китайских приложений на европейские языки может стать сущим адом, если разработчики не учли нюанс, что другие языки разделяют слова пробелами.
Итак, пунктуация является частью текста и её следует выносить во внешние ресурсы.
Числа, как и слова, тоже нуждаются в переводе. Многие разработчики забывают об этом, отображая числовые переменные в привычных для себя форматах. Давайте сравним:
ru: 18 765,22
en: 18,765.22
de: 18.765,22
he: 18,765.22
el: 18.765,22
fa: 18٫765.22
Обратите внимание, какой символ используется в качестве тысячных и дробных разделителей. В английском языке и иврите точка и запятая стоят совсем иначе, чем в немецком и греческом языках. А в русском языке в качестве тысячного разделителя для чисел >9999 используется пробел (неразрывный). А в фарси тысячи разделяются особым символом «моммайе» (U+066B), однако особого стандарта для этого языка нет, разделителям могут быть также и запятая, и пробел.
Можно, конечно, считать, что это мелочи и «кому надо, и в таком виде поймут». Однако такие мелочи иногда могут привести к серьёзным недопониманиям, особенно, когда речь идёт о ценах или важных инженерных расчётах.
Кстати, о ценах, давайте сравним:
ru: 2,25 €
en: €2.25
de-at: € 2,25
de-de: 2,25 €
lv: € 2,25
lt: 2,25 €
В разных языках знаки валюты располагаются по-разному, из чего следует вывод, что хардкодить эти символы тоже лучше не стоит. Причём, как вы видите, нормы различаются не только среди языков, но и среди языковых вариантов (в Австрии и Германии). Даже соседние Латвия и Литва имеют различные нормы.
Иногда приходится адаптировать к национальным стандартам не только внешний вид числа, но и само число. Речь идёт о единицах измерения. Если они используются в вашем проекте, то всегда следует узнать, какая система принята в той или иной стране, чтобы понятно сообщать пользователю о скорости, длине, массе, температуре и пр.
Сообщение «Вы движетесь со скоростью 62 мили в час» ни о чём не скажет водителю из Пскова. Также как сообщение «Вы движетесь со скоростью 100 километров в час» может привести в ступор водителя из Чикаго.
В таком случае недостаточно просто отдавать числовую переменную, следует копать глубже и изменять формулу расчёта в зависимости от локали. Правда, идеальным решением будет всё-таки предоставить выбор системы измерения пользователю в настройках приложения, сделав эту настройку независимой от локали. В любом случае, локальные единицы измерения учитывать обязательно стоит.
Некоторые разработчики при организации текстовых строк не учитывают грамматику других языков и разбивают текст в строке на несколько значений. В итоге, текстовые сообщения собираются из нескольких кусочков по правилам русского синтаксиса (или родного языка разработчика). Если в переводе на английский ещё и можно как-нибудь выкрутиться (что тоже нечасто удаётся), то, например, в немецком с его жёсткими правилами насчёт порядка слов, при сборке фрагментов в единое предложение получается полный бред. Ну а в арабском, где вообще всё пишется в другую сторону, такой вариант организации контента вообще неприемлем.
Довольно распространённый пример. Русскоязычный пользователь видит сообщение: «До окончания тестового периода осталось 5 дней. Пожалуйста, введите действительный ключ.». В ресурсах это сообщение выглядит следующим образом:
В принципе, можно изловчиться и перевести эти «лоскутки» текста на английский язык так, что перевод будет довольно корректным. С арабским языком, где направление текста другое, такой фокус не пройдёт. В немецком языке то и дело отделяемые приставки глаголов норовят убежать в конец предложения. Кстати, ещё раз сравните длительность этой фразы на разных языка — немецкий вариант на 30 % длиннее английского. Жирным шрифтом выделены глаголы. Как вы видите, в немецком языке они могут состоять из двух частей, одна из которых может находиться довольно далеко от другой.
en: Your trial period expires in 5 days. Please enter the valid key.
de: Ihre Testversion läuft in 5 Tagen ab. Bitte geben sie einen gültigen Produktschlüssel ein.
Другим недостатком является то, что при таком представлении переводчик не всегда может уловить логику предложения и добавить корректный перевод. Представьте, как легко можно запутаться в таких кусочках строк, когда их тысяч эдак 5.
Всё это говорит нам о том, что по возможности следует выводить в ресурсы всю строку, чтобы она не только имела наиболее универсальный формат, но и была понятной человеку, который будет её переводить.
Решение для описанной ситуации было бы следующее:
Оператор count (или как бы вы его ни назвали) подставляет нужное текстовое значение в зависимости от числовой переменной %n. При таком представлении проблем не будет и у арабского переводчика, пишущего справа налево — он просто переставит переменные местами.
Довольно частой проблемой является стремление разработчиков обеспечить нужное представление текста в интерфейсе с помощью принудительного разрыва строки. Сразу же приведу пример.
Пользователь видит текст вот так:
Этот текст такой большой,
а окно такое маленькое,
что мне придётся разбить
его по строкам.
В ресурсах это может выглядеть вот так:
На перевод такого безобразия переводчик потратит в несколько раз больше времени, думая, как адаптировать это под свой собственный язык. Если текст будет длиннее (немецкий или французский языки), то четырёх строчек может не хватить. Если текст будет короче (японский или китайский), то пара строк останется пустой. Не говоря уже о том, что если используется технология автоматизированного перевода (при которой перевод каждой строки добавляется в память переводов и используется в аналогичных или похожих строках повторно), то такое разбиение не поможет сделать локализацию эффективной.
Выхода здесь может быть два: либо использовать автоматическую подгонку текста под размеры окна; либо, если доверять переносы машине не хочется, использовать \n.
Тогда текст в ресурсах будет выглядеть так:
В таком случае перенос строки будет более гибким. Например, переводчику можно сообщить максимальное количество символов в строке и попросить расставить переносы наиболее логично.
Эту ошибку допускают слишком старательные контент-менеджеры. Особенно те, кто оптимизирует англоязычные тексты. В излишне оптимизированных ресурсах всё, что только можно (все ключевые слова, а порой и выражения) заменены на постоянные, которые при локализации могут подставляться без учёта падежа, артиклей и прочих особенностей грамматической системы языка перевода. Разумеется, это позволяет лучше контролировать последовательность использования терминологии, а также может существенно снизить расходы на перевод. Но любая оптимизация должна быть разумной. Давайте рассмотрим пример:
Пользователь видит следующий текст:
You can launch the application from the terminal. Press F2 to access the terminal.
В ресурсах он собирается из следующих кусочков:
Предположим, в интерфейсе много раз используется слова и фразы, которые контент-менеджер заменил на постоянные. Эти постоянные он использует в текстах, т.к. это удобно. Если однажды будет решено, что слово «terminal» неприемлемо, и нужно использовать «command line», либо терминал в системе заменят на, скажем, меню, то не нужно будет обрабатывать огромный массив текста. Достаточно будет просто заменить значение постоянной. Дополнительным плюсом будет снижение общего количества слов. Ведь стоимость перевода чаще всего рассчитывается по количеству слов (значительно реже по количеству строк), а значит общие затраты на локализацию можно будет снизить. Но не тут-то было. Помните, я уже писал, что не все языки работают по одним и тем же грамматическим правилам? Здесь это тоже очень важно.
Давайте посмотрим, как ресурсы в таком виде будут переведены на русский язык.
Пользователь увидит следующее:
«Вы можете запустить приложение из терминал. Нажмите F2 для открытия терминал».
Если заменить слово «приложение» на слово «программа», то станет ещё хуже, но нагляднее:
«Вы можете запустить программа из терминал. Нажмите F2 для открытия терминал».
Очевидно, что категория падежа в таком подходе не учитывается.
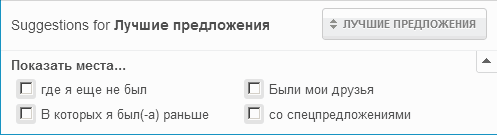
За подобными примерами далеко ходить не надо. Достаточно посмотреть на отвратительно локализованный Foursquare:

Или, взгляните на названия фильтров. Не все из них являются продолжением фразы «Показать места…». Вероятно, это константы, используемые и в других местах. Ну, или просто бездумный перевод и отсутствие тестирования локализации.
Facebook постоянно улучшает локализацию силами пользователей-волонтёров (не так давно они всё-таки опубликовали вакансию менеджера по локализации, надеюсь, скоро всё будет ещё лучше), но, например, эта строка пока выглядит не совсем по-русски, а построена по правилам исходного языка.

В русской версии всё-таки лучше будет написать «Место учёбы: %ВУЗ%».
Аналогичный пример из другого раздела:

Вывод: использование текстовых констант, несомненно, полезно, но они должны учитывать другие грамматики. Идеальный подход: использовать числовые постоянные, постоянные единиц измерения (с учётом грамматических особенностей для каждого языка, например, в русском языке 2 множественных числа: 1 уровень, 2 уровня, 5 уровней), имена собственные (названия программных продуктов), сочетания клавиш.
Традиционно локализация ПО была отделена от разработки, более того, многие продакт-менеджеры представляют себе локализацию как просто замену оригинального текста иностранным. В результате этого страдает продукт в целом, так как:
Даже если приложение написано для локального рынка, то и в этом случае локализация может быть необходима. Вполне возможно, что через пару лет в Москве будет большая потребность в «Яндекс.Картах» на таджикском языке.
Старайтесь разрабатывать приложения с учётом интернационализации и взаимодействуйте с вашим менеджером по локализации или переводческим агентством уже на этапе разработки, чтобы сэкономить себе время, ресурсы и деньги, а также обеспечить максимально высокое качество локальных версий ваших продуктов.
В этой статье я постараюсь на примере показать, как можно создать так называемый localization-friendly code, то есть, организовать ресурсы таким образом, чтобы существенно облегчить локализацию приложения, снизив избыточные временные и финансовые затраты.
Сразу же оговорюсь, что речь пойдёт в первую очередь об интернационализации, то есть, об учёте всех лингвистических особенностей на этапе разработки. Если же ресурсы вашего проекта изначально не подразумевали локализацию, а впоследствии вы решились на неё, то их «затачивание» под локализацию может выйти намного дороже, чем доход от неё.

Используйте Unicode
В большинстве случаев вопрос о кодировке UTF-8 (или UTF-16) встаёт при планировании локализации на азиатские языки, где количество символов может достигать нескольких тысяч. Даже если в данный момент локализация на корейский или китайский языки не планируется, стоит позаботиться об универсальной кодировке заранее. Если стратегия локализации вашего продукта изменится, то перескакивать на ходу на другую кодировку будет намного сложнее. Совет: для всех ресурсов используйте Unicode по умолчанию, даже если проект пока только на русском/английском/любом другом языке.
Кстати, например, спецификации JSON и YAML (эти форматы нередко используются для хранения локализуемых ресурсов) предписывают использование Unicode.
Позаботьтесь о шрифтах
Эта, вроде бы мелочь, часто является критичным фактором, тормозящим локализацию. Убедитесь, что используемые вами шрифты имеют символы для языков локализации (в первую очередь, опять же, азиатские языки, а также иврит, арабский и диакритика европейских языков).
Помните, что
ä, à или ą ≠ a
также как и в русском «е» не всегда равно «ё».
В моей практике был случай, когда разработчики сами нарисовали шрифт, содержащий набор букв только для английского языка. Когда дело дошло до локализации на немецкий и польский языки, им пришлось дорисовывать буквы с диакритическими знаками.
Оставляйте пространство для манёвра
Помимо шрифтов перевод текстов приложения готовит ещё один подводный камень для вёрстки.
Сравните, как может переводиться один пункт меню на разные языки
ru: Сохранить как
en: Save as
fi: Tallenna nimellä
zh: 另存为
Если для китайского языка нам потребуется всего 3 символа, то для финского уже целых 16! Кроме того, помимо количества символов важны также особенности того или иного шрифта.

Сравним финскую и китайскую строку по длине (шрифт для обоих языков Arial Unicode MS, 12 кегль) — финский текст (114 пикселей) в 2,5 раза длиннее китайского (45 пикселей).
Поэтому в элементах интерфейса очень важно иметь место про запас, чтобы исключить обрезание отображаемого текста. Если в определённых случаях места не хватает, можно использовать автоматическую подгонку текста по размеру. Однако это решение приведёт к тому, что в разных элементах интерфейса с большой вероятностью будет отображаться текст разного размера.
Псевдолокализация
Увидеть проблемные места до начала перевода поможет такой приём как псевдолокализация. Она является одним из методов тестирования приложений для проверки их готовности к локализации. Суть её заключается в том, что вместо перевода в ресурсы подставляется текст на псевдоязыке, созданный по специальному алгоритму (зависит от используемого программного обеспечения). Самый примитивный пример: вместо английского текста подставляется транслитерация/транскрипция кириллическими буквами:
Save as -> Саве ас
Save as -> Сэйв аз
Такой метод позволяет проверить следующие моменты:
- корректно ли отображаются диакритические знаки (например, немецкий, польский);
- корректно ли отображаются языки с другими шрифтами (например, китайский, русский);
- есть ли проблемы с отображением элементов интерфейса для языков с направлением текста справа налево (например, арабский);
- есть ли проблемы с отображением нестандартных символов (например, в именах пользователей);
- все ли локализуемые ресурсы извлечены в отдельные файлы (использование текста прямо в коде несёт в себе массу проблем, см. ниже про хардкодинг).
При псевдолокализации нередко используют машинный перевод на нужный язык. С одной стороны, это простое решение в случае отсутствия специальных средств для генерации псевдоперевода. С другой стороны, я уже не раз видел, как разработчики путали локализованные ресурсы с псевдолокализованными и даже по недосмотру заменяли нормальный перевод машинным в репозиториях. Кроме того, машинный перевод не всегда позволяет оценить отображение всех символов языка (например, буква œ не так часто встречается в текстах, но её отображение тоже необходимо протестировать).
Например, так выглядит интерфейс плагина псевдоперевода в программе memoQ:

А вот так выглядит результат с этими настройками:

Внешние ресурсы
Для того, чтобы иметь полный обзор локализуемых материалов, необходимо отделить все ресурсы от кода. Мультимедийную информацию, содержащую текст (чаще всего это изображения, а также видео и аудио, например, в играх), следует также хранить отдельно, с сортировкой по локалям. Во-первых, это существенно упростит работу создателям контента, им не нужно будет копаться в коде, чтобы исправить какое-нибудь системное сообщение. Во-вторых, это позволит менеджеру по локализации точно рассчитать сроки и бюджет для каждого языка. В-третьих, это позволит быть несравнимо гибкими в работе с многоязычным контентом.
Наиболее популярными форматами для обмена локализуемыми данными являются XLIFF и .po-файлы. Так или иначе современные системы автоматизированного перевода в состоянии преобразовывать любые файлы в понятные переводчикам форматы.
Google и Apple тоже настоятельно советуют разработчикам извлекать все ресурсы для локализации во вне: рекомендации для разработчиков под Android, рекомендации Apple по интернационализации.
Хардкодинг в интернационализации
В продолжение предыдущего пункта стоить рассказать о важном моменте. Локализация подразумевает не только перевод слов, но и адаптацию чисел, единиц измерения, форматов даты и времени, а также знаков препинания к локальным стандартам.
Знаки препинания
Многие разработчики любят «зашивать» знаки препинания в код, думая, что точки и вопросительные знаки-то уж точно во всех языках одинаковые. Но сравните:
ru:
Вы уверены?
en:
Are you sure?
fr:
Êtes-vous sûr ?
es:
¿Está seguro?
ar:
هل أنت متأكد؟
Во французском языке вопросительный знак отделяется пробелом (кстати говоря, Хабр пробел перед знаком вопроса упорно убирал, пришлось колдовать с тегами). В испанском вопросительный знак состоит из перевёрнутого в начале и обычного в конце фразы, а в арабском он вообще стоит слева и обращён в другую сторону. Если вопросительный знак будет подставляться из кода, то не всем пользователям будет комфортно читать такое сообщение (разве что в коде не будет прописана зависимость от локали, но зачем такие извращения?).
Помимо знаков препинания, нужно быть осторожными с пробелами, доверяя коду их принудительную вставку. Ведь есть языки, где пробелы между словами не используются — например, японский.
Говорят, что локализация японских или китайских приложений на европейские языки может стать сущим адом, если разработчики не учли нюанс, что другие языки разделяют слова пробелами.
Итак, пунктуация является частью текста и её следует выносить во внешние ресурсы.
Числа
Числа, как и слова, тоже нуждаются в переводе. Многие разработчики забывают об этом, отображая числовые переменные в привычных для себя форматах. Давайте сравним:
ru: 18 765,22
en: 18,765.22
de: 18.765,22
he: 18,765.22
el: 18.765,22
fa: 18٫765.22
Обратите внимание, какой символ используется в качестве тысячных и дробных разделителей. В английском языке и иврите точка и запятая стоят совсем иначе, чем в немецком и греческом языках. А в русском языке в качестве тысячного разделителя для чисел >9999 используется пробел (неразрывный). А в фарси тысячи разделяются особым символом «моммайе» (U+066B), однако особого стандарта для этого языка нет, разделителям могут быть также и запятая, и пробел.
Можно, конечно, считать, что это мелочи и «кому надо, и в таком виде поймут». Однако такие мелочи иногда могут привести к серьёзным недопониманиям, особенно, когда речь идёт о ценах или важных инженерных расчётах.
Кстати, о ценах, давайте сравним:
ru: 2,25 €
en: €2.25
de-at: € 2,25
de-de: 2,25 €
lv: € 2,25
lt: 2,25 €
В разных языках знаки валюты располагаются по-разному, из чего следует вывод, что хардкодить эти символы тоже лучше не стоит. Причём, как вы видите, нормы различаются не только среди языков, но и среди языковых вариантов (в Австрии и Германии). Даже соседние Латвия и Литва имеют различные нормы.
Единицы измерения
Иногда приходится адаптировать к национальным стандартам не только внешний вид числа, но и само число. Речь идёт о единицах измерения. Если они используются в вашем проекте, то всегда следует узнать, какая система принята в той или иной стране, чтобы понятно сообщать пользователю о скорости, длине, массе, температуре и пр.
Сообщение «Вы движетесь со скоростью 62 мили в час» ни о чём не скажет водителю из Пскова. Также как сообщение «Вы движетесь со скоростью 100 километров в час» может привести в ступор водителя из Чикаго.
В таком случае недостаточно просто отдавать числовую переменную, следует копать глубже и изменять формулу расчёта в зависимости от локали. Правда, идеальным решением будет всё-таки предоставить выбор системы измерения пользователю в настройках приложения, сделав эту настройку независимой от локали. В любом случае, локальные единицы измерения учитывать обязательно стоит.
Не все языки имеют одинаковые грамматики
Принудительное разбиение строк на части
Некоторые разработчики при организации текстовых строк не учитывают грамматику других языков и разбивают текст в строке на несколько значений. В итоге, текстовые сообщения собираются из нескольких кусочков по правилам русского синтаксиса (или родного языка разработчика). Если в переводе на английский ещё и можно как-нибудь выкрутиться (что тоже нечасто удаётся), то, например, в немецком с его жёсткими правилами насчёт порядка слов, при сборке фрагментов в единое предложение получается полный бред. Ну а в арабском, где вообще всё пишется в другую сторону, такой вариант организации контента вообще неприемлем.
Довольно распространённый пример. Русскоязычный пользователь видит сообщение: «До окончания тестового периода осталось 5 дней. Пожалуйста, введите действительный ключ.». В ресурсах это сообщение выглядит следующим образом:
'trialexpires_1': "До окончания тестового периода " 'trialexpires_2sg': "остался " 'trialexpires_2pl': "осталось " 'trialexpires_4sg': " день." 'trialexpires_4pl2': " дня." 'trialexpires_4pl3': " дней." 'enterkey': "Пожалуйста, введите действительный ключ."
В принципе, можно изловчиться и перевести эти «лоскутки» текста на английский язык так, что перевод будет довольно корректным. С арабским языком, где направление текста другое, такой фокус не пройдёт. В немецком языке то и дело отделяемые приставки глаголов норовят убежать в конец предложения. Кстати, ещё раз сравните длительность этой фразы на разных языка — немецкий вариант на 30 % длиннее английского. Жирным шрифтом выделены глаголы. Как вы видите, в немецком языке они могут состоять из двух частей, одна из которых может находиться довольно далеко от другой.
en: Your trial period expires in 5 days. Please enter the valid key.
de: Ihre Testversion läuft in 5 Tagen ab. Bitte geben sie einen gültigen Produktschlüssel ein.
Другим недостатком является то, что при таком представлении переводчик не всегда может уловить логику предложения и добавить корректный перевод. Представьте, как легко можно запутаться в таких кусочках строк, когда их тысяч эдак 5.
Всё это говорит нам о том, что по возможности следует выводить в ресурсы всю строку, чтобы она не только имела наиболее универсальный формат, но и была понятной человеку, который будет её переводить.
Решение для описанной ситуации было бы следующее:
'trialexpires': "До окончания тестового периода [count:остался|осталось] {%n} [count:день|дня|дней]."
'enterkey': "Пожалуйста, введите действительный ключ."
Оператор count (или как бы вы его ни назвали) подставляет нужное текстовое значение в зависимости от числовой переменной %n. При таком представлении проблем не будет и у арабского переводчика, пишущего справа налево — он просто переставит переменные местами.
Вёрстка с помощью принудительного разрыва строки
Довольно частой проблемой является стремление разработчиков обеспечить нужное представление текста в интерфейсе с помощью принудительного разрыва строки. Сразу же приведу пример.
Пользователь видит текст вот так:
Этот текст такой большой,
а окно такое маленькое,
что мне придётся разбить
его по строкам.
В ресурсах это может выглядеть вот так:
'menubox_string1': "Этот текст такой большой," 'menubox_string2': "а окно такое маленькое," 'menubox_string3': "что мне придётся разбить" 'menubox_string4': "его по строкам."
На перевод такого безобразия переводчик потратит в несколько раз больше времени, думая, как адаптировать это под свой собственный язык. Если текст будет длиннее (немецкий или французский языки), то четырёх строчек может не хватить. Если текст будет короче (японский или китайский), то пара строк останется пустой. Не говоря уже о том, что если используется технология автоматизированного перевода (при которой перевод каждой строки добавляется в память переводов и используется в аналогичных или похожих строках повторно), то такое разбиение не поможет сделать локализацию эффективной.
Выхода здесь может быть два: либо использовать автоматическую подгонку текста под размеры окна; либо, если доверять переносы машине не хочется, использовать \n.
Тогда текст в ресурсах будет выглядеть так:
'menubox': "Этот текст такой большой,\nа окно такое маленькое,\nчто мне придётся разбить\nего по строкам."
В таком случае перенос строки будет более гибким. Например, переводчику можно сообщить максимальное количество символов в строке и попросить расставить переносы наиболее логично.
Избыточная оптимизация
Эту ошибку допускают слишком старательные контент-менеджеры. Особенно те, кто оптимизирует англоязычные тексты. В излишне оптимизированных ресурсах всё, что только можно (все ключевые слова, а порой и выражения) заменены на постоянные, которые при локализации могут подставляться без учёта падежа, артиклей и прочих особенностей грамматической системы языка перевода. Разумеется, это позволяет лучше контролировать последовательность использования терминологии, а также может существенно снизить расходы на перевод. Но любая оптимизация должна быть разумной. Давайте рассмотрим пример:
Пользователь видит следующий текст:
You can launch the application from the terminal. Press F2 to access the terminal.
В ресурсах он собирается из следующих кусочков:
'cmd': "the terminal"
'app': "the application"
'act_42': "Press F2"
'run_from_terminal': "You can launch {app} from {cmd}. {act_42} to access {cmd}."
Предположим, в интерфейсе много раз используется слова и фразы, которые контент-менеджер заменил на постоянные. Эти постоянные он использует в текстах, т.к. это удобно. Если однажды будет решено, что слово «terminal» неприемлемо, и нужно использовать «command line», либо терминал в системе заменят на, скажем, меню, то не нужно будет обрабатывать огромный массив текста. Достаточно будет просто заменить значение постоянной. Дополнительным плюсом будет снижение общего количества слов. Ведь стоимость перевода чаще всего рассчитывается по количеству слов (значительно реже по количеству строк), а значит общие затраты на локализацию можно будет снизить. Но не тут-то было. Помните, я уже писал, что не все языки работают по одним и тем же грамматическим правилам? Здесь это тоже очень важно.
Давайте посмотрим, как ресурсы в таком виде будут переведены на русский язык.
'cmd': "терминал"
'app': "приложение"
'act_42': "Нажмите F2"
'run_from_terminal': "Вы можете запустить {app} из {cmd}. {act_42} для открытия {cmd}."
Пользователь увидит следующее:
«Вы можете запустить приложение из терминал. Нажмите F2 для открытия терминал».
Если заменить слово «приложение» на слово «программа», то станет ещё хуже, но нагляднее:
«Вы можете запустить программа из терминал. Нажмите F2 для открытия терминал».
Очевидно, что категория падежа в таком подходе не учитывается.
За подобными примерами далеко ходить не надо. Достаточно посмотреть на отвратительно локализованный Foursquare:

Или, взгляните на названия фильтров. Не все из них являются продолжением фразы «Показать места…». Вероятно, это константы, используемые и в других местах. Ну, или просто бездумный перевод и отсутствие тестирования локализации.

Facebook постоянно улучшает локализацию силами пользователей-волонтёров (не так давно они всё-таки опубликовали вакансию менеджера по локализации, надеюсь, скоро всё будет ещё лучше), но, например, эта строка пока выглядит не совсем по-русски, а построена по правилам исходного языка.

В русской версии всё-таки лучше будет написать «Место учёбы: %ВУЗ%».
Аналогичный пример из другого раздела:

Вывод: использование текстовых констант, несомненно, полезно, но они должны учитывать другие грамматики. Идеальный подход: использовать числовые постоянные, постоянные единиц измерения (с учётом грамматических особенностей для каждого языка, например, в русском языке 2 множественных числа: 1 уровень, 2 уровня, 5 уровней), имена собственные (названия программных продуктов), сочетания клавиш.
Заключение
Традиционно локализация ПО была отделена от разработки, более того, многие продакт-менеджеры представляют себе локализацию как просто замену оригинального текста иностранным. В результате этого страдает продукт в целом, так как:
- неоптимизированные ресурсы увеличивают трудозатраты на локализацию;
- баги, выявленные в процессе локализации увеличивают время выхода продукта на рынок и опять же увеличивают трудозатраты на их устранение;
- бюджет на локализацию постоянно растёт;
- «кривая» локализация влияет на количество покупок/загрузок приложения в том или ином регионе и даёт конкурентам лишний шанс. Лично моё мнение – плохо локализованный продукт гораздо хуже вообще нелокализованного.
Даже если приложение написано для локального рынка, то и в этом случае локализация может быть необходима. Вполне возможно, что через пару лет в Москве будет большая потребность в «Яндекс.Картах» на таджикском языке.
Старайтесь разрабатывать приложения с учётом интернационализации и взаимодействуйте с вашим менеджером по локализации или переводческим агентством уже на этапе разработки, чтобы сэкономить себе время, ресурсы и деньги, а также обеспечить максимально высокое качество локальных версий ваших продуктов.
