Доброго времени суток, Хабрасообщество!
Недавно задался целью сделать поиск на своем сайте, написанном на Kohana Framework. Решил использовать именно морфологический поиск, т.к. считаю его более правильным (относительно полнотекстового поиска с применением LIKE). Поиски готовых модулей для Kohana с требующимся функционалом не увенчались успехом, но я нашел отличную библиотеку: phpMorphy, которая замечательно подошла для решения моих задач.
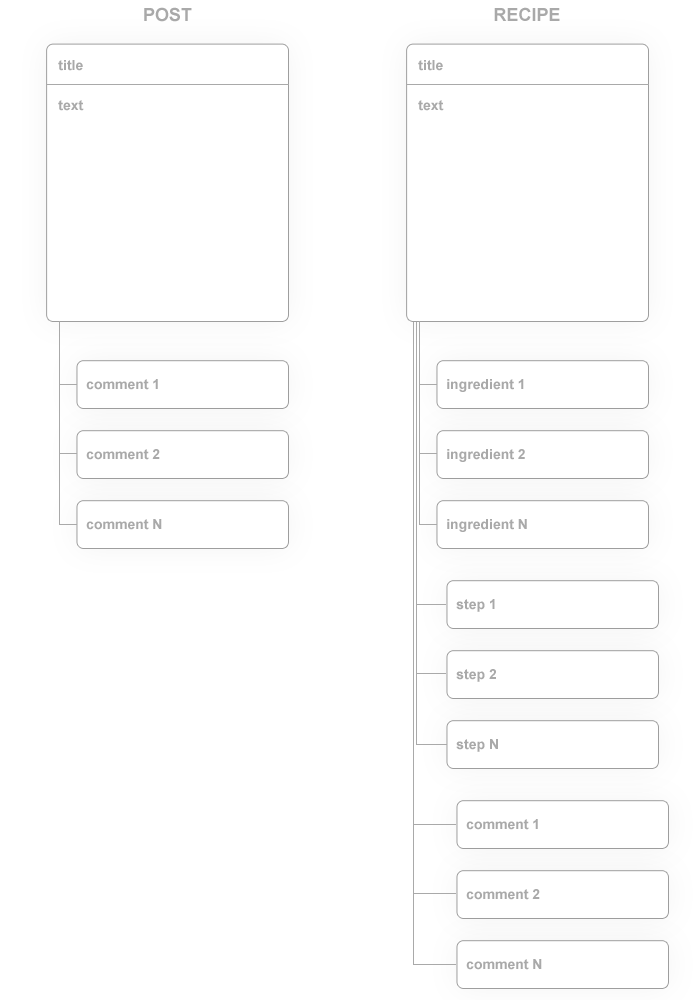
Как видно из прикрепленной схемы, на сайте присутствует контент 2-х типов:
Мы собираемся индексировать весь этот контент, причем в связи с тем, что комментарии могут появляться на протяжении всего времени существования контента — переиндексировать контент нужно на постоянной основе. С точки зрения логики, индексация контента выглядит следующим образом: Поочередно получаем весь контент, осуществляем поиск относящихся к контенту дополнительных материалов (комментарии, ингредиенты, шаги приготовления). Далее проводим такие операции:
После того, как стала понятна логическая составляющая вопроса — можно приступить к разбору кода.
Разработчики рекомендуют размещать файлы библиотеки таким образом, чтобы они не были доступны напрямую из web. Я не уточнял по каким причинам, поэтому предлагаю не злоупотреблять рекомендацией и залить файлы либо выше директории /www, либо (в случае, если будете заливать в какую либо директорию внутри /www) запрещать прямое обращение к папке из web. Это можно сделать, поместив в папку файл .htaccess:
Кроме этого, для удобства (я лично использую ORM) нужно создать модель:
Ну и, соответственно, таблицу 'searchindex', состоящую из полей:
Таблица должна иметь тип MyISAM
Поговорим подробнее о каждом из контроллеров.
Настраиваем в роутах возможность получения дополнительного параметра (т.к. операция тяжелая и хотелось бы разбить её на порции):
Ну, с роутами, я думаю, все поняли, что имеется в виду. Далее, в самом котроллере, в action_index() принимаем параметр offset, создаем экземпляр класса phpMorphy, и производим все операции, описанные в логической схеме:
Думаю, что не стоит приводить код реализации панели управления (учитывая, что и сейчас объем статьи не маленький). Там всё достаточно банально — кнопка, и jquery обработчик, обращающийся к вышеописанному контроллеру и соответствующим образом обрабатывающий получаемый ответ.
Ну, вывод информации, думаю, описывать смысла большого нет — тут всё как обычно. Листинги кода старался как можно больше сократить, чтобы не захламлять статью совсем простыми и банальными вещами (такими как получение информации из БД или обработка ошибок, все и так знают, как это делается...).
Надеюсь, моя статья будет полезна Хабрасообществу. Пример работы данной реализации поиска можете посмотреть тут.
Недавно задался целью сделать поиск на своем сайте, написанном на Kohana Framework. Решил использовать именно морфологический поиск, т.к. считаю его более правильным (относительно полнотекстового поиска с применением LIKE). Поиски готовых модулей для Kohana с требующимся функционалом не увенчались успехом, но я нашел отличную библиотеку: phpMorphy, которая замечательно подошла для решения моих задач.
Логика функционирования поиска включает в себя 2 блока:
- Индексация (и переиндексация) имеющегося контента
- Поиск по поисковому индексу
Индексация контента
На сайте мы имеем следующую структуру:
Как видно из прикрепленной схемы, на сайте присутствует контент 2-х типов:
- Посты (могут иметь комментарии — связь один ко многим)
- Рецепты (могут иметь ингредиенты (один ко многим), шаги приготовления (один ко многим), комментарии (аналогично))
Мы собираемся индексировать весь этот контент, причем в связи с тем, что комментарии могут появляться на протяжении всего времени существования контента — переиндексировать контент нужно на постоянной основе. С точки зрения логики, индексация контента выглядит следующим образом: Поочередно получаем весь контент, осуществляем поиск относящихся к контенту дополнительных материалов (комментарии, ингредиенты, шаги приготовления). Далее проводим такие операции:
- Очищаем контент от html-тегов;
- Разбиваем на отдельные слова;
- Приводим к единому регистру (я использовал верхний регистр);
- Заменяем букву Ё на Е (чтобы при индексации и присвоении каждому слову веса, не воспринимались как разные, такие слова, как например «зеленый» и «зелёный»);
- Исходя из положения слова в структуре и количества упоминания этого слова в посте проставляем вес (например: слово из title имеет вес 3, из поля text поста имеет вес 2, а слово из комментария имеет вес 1, при этом, если слово встречается несколько раз, веса суммируются);
- Сохраняем в базе данных полученный индекс (id поста, слово, вес).
Поиск по поисковому индексу
После того, как весь контент проиндексирован, остается самое простое — поиск по созданному поисковому индексу. Для этого мы действуем аналогичным образом:- Получаем и фильтруем запрос пользователя (обрезаем html-теги и прочие попытки xss);
- Разбиваем запрос на слова;
- Приводим каждое слово к верхнему регистру;
- Заменяем Ё на Е;
- Осуществляем поиск полученных слов по поисковому индексу;
- Группируем результаты по id поста, суммируем веса;
- Сортируем полученные результаты по итоговому весу (его уже можно назвать релевантностью);
- Поочередно выбираем из базы информацию по полученным id, формируем и выводим выдачу.
После того, как стала понятна логическая составляющая вопроса — можно приступить к разбору кода.
Пишем код
Начало
Для начала идем на страничку проекта на Sourceforge и скачиваем актуальную версию библиотеки, а также базы словарей (т.к. Kohana работает с utf-8 — скачиваем словари для этой кодировки).Разработчики рекомендуют размещать файлы библиотеки таким образом, чтобы они не были доступны напрямую из web. Я не уточнял по каким причинам, поэтому предлагаю не злоупотреблять рекомендацией и залить файлы либо выше директории /www, либо (в случае, если будете заливать в какую либо директорию внутри /www) запрещать прямое обращение к папке из web. Это можно сделать, поместив в папку файл .htaccess:
Options -Indexes
<Files ~ "\.(php|php3|php4|php5|pl|cgi|sh|bash)$">
Deny from all
</Files>
Инициализация библиотеки
Для использования функционала библиотеки нужно подключить необходимые файлы и создать экземпляр класса, с которым будут предприниматься дальнейшие действия:require_once('{путь до директории с библиотекой}/src/common.php');
$dir = '{путь до директории, в которую мы разархивировали словари}/dicts';
$lang = 'ru_RU';
$opts = array(
'storage' => PHPMORPHY_STORAGE_FILE,
);
try
{
$morphy = new phpMorphy($dir, $lang, $opts);
}
catch(phpMorphy_Exception $e)
{
die('Error occured while creating phpMorphy instance: ' . $e->getMessage());
}
Интегрируем библиотеку в Kohana
В предлагаемом мной решении используется 2 контроллера:- Админская часть — на его стороне происходит индексация/переиндексация контента;
- Контроллер поиска — отвечает за поиск по индексу и вывод контента пользователям.
Кроме этого, для удобства (я лично использую ORM) нужно создать модель:
class Model_Searchindex extends ORM {
protected $_table_name = 'searchindex';
}
Ну и, соответственно, таблицу 'searchindex', состоящую из полей:
- word — varchar(32) COLLATE utf8_bin NOT NULL — PRIMARY KEY
- post_id — int(100) NOT NULL — PRIMARY KEY
- weight — int(100) NOT NULL
Таблица должна иметь тип MyISAM
Поговорим подробнее о каждом из контроллеров.
Контроллер, отвечающий за индексацию
Данный контроллер в моем случае используется как обработчик, к которому я обращаюсь асинхронными запросами из панели управления сайтом (естественно, контроллер доступен только пользователю с правами администратора).Настраиваем в роутах возможность получения дополнительного параметра (т.к. операция тяжелая и хотелось бы разбить её на порции):
Route::set('index', 'updateindex(/<offset>)')
->defaults(array(
'directory' => 'admin',
'controller' => 'updateindex',
'action' => 'index',
));
Ну, с роутами, я думаю, все поняли, что имеется в виду. Далее, в самом котроллере, в action_index() принимаем параметр offset, создаем экземпляр класса phpMorphy, и производим все операции, описанные в логической схеме:
$offset = $this->request->param('offset');
// при переиндексации очищаем старую базу индексов
if ($offset == 1)
{
$index = DB::query(Database::DELETE, 'DELETE FROM `searchindex`');
$index->execute();
}
$data = array();
// Тут получаем список постов
$posts = ORM::factory('post')->where('delete', '=', 0)->offset(100*$offset)->limit(100)->find_all();
foreach ($posts as $post)
{
$words = array();
// Очищаем от html, заменяем Ё на Е и приводим к верхнему регистру
$title = mb_strtoupper(str_ireplace("ё", "е", strip_tags($post->title)), "UTF-8");
$comments = ORM::factory('comment')->where('post_id', '=', $post->id)->order_by('id', 'ASC')->find_all(); // Получаем комментарии, относящиеся к посту
$text = $post->text;
if ($post->type == 1)
{
// Тут проводим тоже самое, но с ингредиентами и шагами приготовления. Думаю, хабрасообществу это не так интересно...
}
foreach ($comments as $comment)
{
// Для сокращения объема примем, что текст поста и комментариев имеет одинаковый вес
$text = $text.' '.$comment->text;
}
$text = mb_strtoupper (str_ireplace("ё", "е", strip_tags($text)), "UTF-8");
preg_match_all ('/([a-zа-яё]+)/ui', $title, $word_title); // Разбиваем текст на слова
preg_match_all ('/([a-zа-яё]+)/ui', $text, $word_text);
// Получаем нормальную форму слова, например помидоров => помидор
$start_form_title = $morphy->lemmatize($word_title[1]);
$start_form_text = $morphy->lemmatize($word_text[1]);
foreach ($start_form_title as $k=>$w)
{
if (!$w)
{
// Если не получилось определить начальную форму слова, используем исходное слово
$w[0] = $k;
}
if (mb_strlen($w[0], "UTF-8") > 2) // Проверяем длину слова, не индексируем короткие слова
{
if (! isset ( $words[$w[0]]))$words[$w[0]] = 0;
$words[$w[0]]+= 3; // Устанавливаем вес для слова
}
}
foreach ($start_form_text as $k=>$w)
{
// Аналогично для основного текста
}
// Тут перебираем массив значений и заносим их в базу
foreach ($words as $word=>$weight)
{
$data['post_id'] = $post->id;
$data['word'] = $word;
$data['weight'] = $weight;
$addindex = ORM::factory('searchindex');
$addindex->values($data);
try
{
$addindex->save();
}
catch (ORM_Validation_Exception $e)
{
$errors = $e->errors('validation');
}
}
}
/* Тут формируем ответ в виде json, чтобы в панели управления вывести динамический блок, и показывать прогрессбар выполнения операции */
$pcount = ORM::factory('post')->where('delete', '=', 0)->count_all();
if (($pcount - (100*$offset)) > 0)
{
$complateu = ($offset) * 100;
$percent = ($complateu / $pcount) * 100;
$percent = round($percent, 0);
$json = array('status'=>'next', 'nextid'=>1+$offset, 'percent'=>$percent);
$this->response->body(json_encode($json));
}
else
{
$json = array('status'=>'finish', 'percent'=>100);
$this->response->body(json_encode($json));
}
Думаю, что не стоит приводить код реализации панели управления (учитывая, что и сейчас объем статьи не маленький). Там всё достаточно банально — кнопка, и jquery обработчик, обращающийся к вышеописанному контроллеру и соответствующим образом обрабатывающий получаемый ответ.
Контроллер, отвечающий за поиск на сайте
Для работы данного контроллера аналогичным образом создаем роут. Контроллер принимает поисковую фразу, введенную пользователем. Фраза передается методом GET. Так выглядит контроллер: public function action_search()
{
$data = null;
$request = null;
$errors = null;
if (!empty($_GET['text'])) // Получаем поисковый запрос
{
// Очищаем от html-тегов и прочего
$search = $this->_clear_var($_GET['text']);
$request = $search;
}
/* Создаем экземпляр phpMorphy */
if (!empty($search))
{
// Обрабатываем данные как и в прошлом контроллере
if (mb_strlen($search, "UTF-8") > 2)
{
preg_match_all('/([a-zа-яё]+)/ui', mb_strtoupper($search, "UTF-8"), $search_words);
$words = $morphy->lemmatize($search_words[1]);
$s_words = array();
$pre_result = array();
foreach ($words as $k => $w)
{
if (!$w)$w[0] = $k;
if (mb_strlen($w[0], "UTF-8") > 2)
{
$s_words[] = $w[0];
}
}
if (!count($s_words))
{
// Обрабатываем ошибку (нет ни одного слова длиннее 2 символов)
}
else
{
foreach($s_words as $s_word)
{
$search_index = ORM::factory('searchindex')->where('word', '=', $s_word)->find_all();
foreach ($search_index as $si)
{
if (!empty($pre_result[$si->post_id]))
{
$pre_result[$si->post_id] = (int) $si->weight + $pre_result[$si->post_id];
}
else
{
$pre_result[$si->post_id] = (int) $si->weight;
}
}
}
arsort($pre_result); // Сортируем массив по весу результатов
foreach ($pre_result as $id => $weight)
{
// Тут, соответственно, получаем данные о результатах и помещаем в массив
$data[] = $result;
}
}
}
else
{
// Обрабатываем ошибку - введен слишком короткий запрос
}
}
else
{
// Обрабатываем ошибку - пустой поисковый запрос
}
$this->template->content = View::factory('content/v_search')
->bind('data', $data)
->bind('errors', $errors)
->bind('request', $request)
}
Ну, вывод информации, думаю, описывать смысла большого нет — тут всё как обычно. Листинги кода старался как можно больше сократить, чтобы не захламлять статью совсем простыми и банальными вещами (такими как получение информации из БД или обработка ошибок, все и так знают, как это делается...).
Надеюсь, моя статья будет полезна Хабрасообществу. Пример работы данной реализации поиска можете посмотреть тут.
