К сожалению, стандарт C++ не допускает применения операторов switch-case к строковым константам. Хотя в других языках, вроде C#, такая возможность имеется прямо «из коробки». Поэтому, понятное дело, многие C++ программисты пытались написать свою версию «switch для строк» — и я не исключение.
Для C++03 решения не отличались красотой и лишь усложняли код, дополнительно нагружая приложение в рантайме. Однако с появлением C++11 наконец-то появилась возможность реализовать такой код:
Реализация этой конструкции весьма проста. Она основана на constexpr-функциях из C++11, благодаря чему почти все вычисления производятся ещё на этапе компиляции. Если кого-то интересуют её детали, добро пожаловать под кат — благо на Хабре о «switch для строк» почему-то ничего не сказано.
Прежде всего — чтобы это был полноценный switch, а не его «эмуляция» путём скрытия if-операторов и функций для сравнения строк внутри макросов, поскольку сравнение строк в рантайме — дорогостоящая операция, и проводить её для каждой строки из CASE слишком расточительно. Поэтому такое решение нас не устроит — к тому же, в нём неизбежно появляются непонятные макросы типа END_STRING_SWITCH.
Кроме того, очень желательно по-максимуму задействовать компилятор. Например, что будет с «обычным» switch-case в случае, когда аргументы двух case окажутся одинаковыми? Правильно, компилятор тут же обругает нас: «duplicate case value», и прекратит компиляцию. А в примере по вышеуказанной ссылке, разумеется, ни один компилятор не сможет заметить эту ошибку.
Важен и итоговый синтаксис, простой и без лишних конструкций. Именно поэтому известный вариант "std::map со строковым ключом" нас тоже не устраивает: во-первых, аргументы case в нём не выглядят наглядными — а во-вторых, он требует обязательной инициализации используемого std::map в рантайме. Функция этой инициализации может находиться где угодно, постоянно глядеть в неё слишком утомительно.
Остаётся последний вариант: вычислять хэш строки в switch, и сравнивать его с хэшем каждой строки в case. То есть, всё сводится к сравнению двух целых чисел, для которых switch-case прекрасно работает. Однако стандарт C++ говорит, что аргумент каждого case должен быть известен ещё при компиляции — поэтому функция «вычисления хэша от строки» должна работать именно в compile-time. В C++03 её можно реализовать лишь с помощью шаблонов, наподобие вычисления CRC в этой статье. Но в C++11, к счастью, появились более понятные constexpr-функции, значения которых также могут вычисляться компилятором.
Итак, нам нужно написать constexpr-функцию, которая бы оперировала числовыми кодами char-символов. Как известно, тело такой функции представляет из себя "return <известное в compile-time выражение>". Попробуем реализовать самый «вырожденный» её вариант, а именно — функцию вычисления длины const char* строки. Но уже здесь нас поджидают первые трудности:
Компилятор не ругается, функция корректна. Однако у меня она почему-то вывела не «6 6», а «6 12». Отчего так? А всё дело в том, что я набрал этот исходный код под Windows в «линуксовой» кодировке UTF-8, а не в стандартной Win-1251 — и поэтому каждый «кириллический» символ воспринялся как два. Вот если сменить кодировку на стандартную, тогда действительно выведется «6 6». Что ж получается, наша задумка потерпела крах? Ведь это не дело, когда при разных кодировках получаются разные хэши…
Но зачем нам кириллица или азиатские иероглифы? В подавляющем большинстве случаев, для исходников достаточно лишь английских букв и стандартных знаков пунктуации — то есть символов, умещающихся в диапазоне от 0 до 127 в ASCII-таблице. А их char-коды при смене кодировки не изменятся — и поэтому хэш от строки, составленной лишь из них, всегда будет одинаков. Но как быть, если программист случайно всё же введёт один из таких символов? На помощь нам приходит следующая compile-time функция:
Она проверяет, содержит ли известная на стадии компиляции строка только символы из диапазона 0-127, и возвращает false в случае нахождения «запретного» символа. Зачем нужен принудительный каст к signed char? Дело в том, что в стандарте C++ не определено, чем же именно является тип char — он может быть как знаковым, так и беззнаковым. А вот его sizeof всегда будет равен 1, отчего мы смещаемся вправо на единицу. Таким образом, нужный нам макрос CASE будет иметь вид:
Тут используется ещё одна фича C++11 — assert при компиляции. То есть, если строка-аргумент макроса CASE будет содержать хотя бы один «запретный» символ — компиляция остановится со вполне понятной ошибкой. Иначе, будет вычислен хэш, значение которого подставится в case. Это решение избавит нас от проблем с кодировкой. Осталось лишь написать саму функцию str_hash(), которая и вычислит нужный хэш.
Выбрать хэш-функцию можно по-разному, и самый главный вопрос тут — это возможность коллизий. Если хэши двух различных строк совпадут, то программа может перепрыгнуть со switch на ложную case-ветку. И спутник упадёт в океан… Поэтому будем использовать хэш-функцию, не имеющую коллизий вообще. Так как уже установлено, что все символы строки расположены в диапазоне 0-127, то функция будет иметь вид: . Её реализация такова:
. Её реализация такова:
Здесь raise_128_to() — это compile-time функция возведения 128 в степень, а current_len — это длина текущей строки. Конечно, длину можно вычислять и на каждом шаге рекурсии, но это лишь замедлит компиляцию — лучше сосчитать её до первого запуска str_hash(), и затем всегда подставлять как дополнительный аргумент. При какой же максимальной длине строки эта функция не будет иметь коллизий? Очевидно, лишь тогда, когда полученное ею значение всегда уместится в диапазоне типа unsigned long long (также окончательно введённого в C++11), то есть если оно не превышает 264-1.
Можно подсчитать, что эта максимальная длина будет равна 9 (обозначим это число как MAX_LEN). А вот максимально возможное значение хэша составит ровно 263 для строки, все символы которой имеют код 127 (и являются нечитаемыми в ASCII, так что под CASE мы её всё равно не загоним). Но как быть, если под CASE будет стоять строка из 10 символов? Если мы действительно не хотим возникновения коллизий, то нужно запретить и такую возможность — то есть, расширить уже используемый нами static_assert:
Всё, с макросом CASE покончено. Он либо выдаст нам ошибку компиляции, либо вычислит уникальное значение хэша. Вот для подсчёта хэша в макросе SWITCH нам придётся сделать отдельную функцию, поскольку она будет работать уже в рантайме. А если её строка-аргумент будет иметь длину более 9 символов, то договоримся возвращать 264-1 (обозначим это число как N_HASH). Итак:
Собственно, вот и всё. В рантайме вычислится хэш для строки в SWITCH, и если одна строк в CASE имеет такой же хэш, исполнение пойдёт на неё. Если какая-то строка из CASE содержит «запретные» символы, или её длина больше 9 символов — мы получим надёжную ошибку компиляции. Нагрузки в рантайме почти нет (за исключением однократного вычисление хэша для SWITCH), читаемость кода не страдает. Осталось лишь перегрузить функцию str_hash_for_switch() для строк std::string, и заключить всё внутрь namespace.
Итоговый h-файл исходников лежит на Гитхабе. Он подойдёт для любого компилятора с поддержкой C++11. Для использования «switch для строк» просто сделайте инклуд str_switch.h куда хотите, и всё — макросы SWITCH, CASE и DEFAULT перед вами. Не забудьте про ограничение на длину строки в CASE (9 символов).
В общем — надеюсь, что кому-нибудь эта реализация пригодится ;)
P. S. Upd: в коде была обнаружена пара неточностей — поэтому сейчас он обновлён, вместе со статьёй. В комментариях также предлагалось использовать другую функцию для вычисления хэша — разумеется, каждый может написать свою её реализацию.
Для C++03 решения не отличались красотой и лишь усложняли код, дополнительно нагружая приложение в рантайме. Однако с появлением C++11 наконец-то появилась возможность реализовать такой код:
std::string month;
std::string days;
std::cout << "Enter month name: ";
std::cin >> month;
SWITCH (month)
{
CASE("february"):
days = "28 or 29";
break;
CASE("april"):
CASE("june"):
CASE("september"):
CASE("november"):
days = "30";
break;
CASE("january"):
CASE("march"):
CASE("may"):
CASE("july"):
CASE("august"):
CASE("october"):
CASE("december"):
days = "31";
break;
DEFAULT:
days = "?";
break;
}
std::cout << month << " has " << days << " days." << std::endl;
Реализация этой конструкции весьма проста. Она основана на constexpr-функциях из C++11, благодаря чему почти все вычисления производятся ещё на этапе компиляции. Если кого-то интересуют её детали, добро пожаловать под кат — благо на Хабре о «switch для строк» почему-то ничего не сказано.
Чего же мы хотим?
Прежде всего — чтобы это был полноценный switch, а не его «эмуляция» путём скрытия if-операторов и функций для сравнения строк внутри макросов, поскольку сравнение строк в рантайме — дорогостоящая операция, и проводить её для каждой строки из CASE слишком расточительно. Поэтому такое решение нас не устроит — к тому же, в нём неизбежно появляются непонятные макросы типа END_STRING_SWITCH.
Кроме того, очень желательно по-максимуму задействовать компилятор. Например, что будет с «обычным» switch-case в случае, когда аргументы двух case окажутся одинаковыми? Правильно, компилятор тут же обругает нас: «duplicate case value», и прекратит компиляцию. А в примере по вышеуказанной ссылке, разумеется, ни один компилятор не сможет заметить эту ошибку.
Важен и итоговый синтаксис, простой и без лишних конструкций. Именно поэтому известный вариант "std::map со строковым ключом" нас тоже не устраивает: во-первых, аргументы case в нём не выглядят наглядными — а во-вторых, он требует обязательной инициализации используемого std::map в рантайме. Функция этой инициализации может находиться где угодно, постоянно глядеть в неё слишком утомительно.
Начинаем вычислять хэш
Остаётся последний вариант: вычислять хэш строки в switch, и сравнивать его с хэшем каждой строки в case. То есть, всё сводится к сравнению двух целых чисел, для которых switch-case прекрасно работает. Однако стандарт C++ говорит, что аргумент каждого case должен быть известен ещё при компиляции — поэтому функция «вычисления хэша от строки» должна работать именно в compile-time. В C++03 её можно реализовать лишь с помощью шаблонов, наподобие вычисления CRC в этой статье. Но в C++11, к счастью, появились более понятные constexpr-функции, значения которых также могут вычисляться компилятором.
Итак, нам нужно написать constexpr-функцию, которая бы оперировала числовыми кодами char-символов. Как известно, тело такой функции представляет из себя "return <известное в compile-time выражение>". Попробуем реализовать самый «вырожденный» её вариант, а именно — функцию вычисления длины const char* строки. Но уже здесь нас поджидают первые трудности:
constexpr unsigned char str_len(const char* const str)
{
return *str ? (1 + str_len(str + 1)) : 0;
}
std::cout << (int) str_len("qwerty") << " " << (int) str_len("йцукен") << std::endl; // проверяем
Компилятор не ругается, функция корректна. Однако у меня она почему-то вывела не «6 6», а «6 12». Отчего так? А всё дело в том, что я набрал этот исходный код под Windows в «линуксовой» кодировке UTF-8, а не в стандартной Win-1251 — и поэтому каждый «кириллический» символ воспринялся как два. Вот если сменить кодировку на стандартную, тогда действительно выведется «6 6». Что ж получается, наша задумка потерпела крах? Ведь это не дело, когда при разных кодировках получаются разные хэши…
Проверяем содержимое строки
Но зачем нам кириллица или азиатские иероглифы? В подавляющем большинстве случаев, для исходников достаточно лишь английских букв и стандартных знаков пунктуации — то есть символов, умещающихся в диапазоне от 0 до 127 в ASCII-таблице. А их char-коды при смене кодировки не изменятся — и поэтому хэш от строки, составленной лишь из них, всегда будет одинаков. Но как быть, если программист случайно всё же введёт один из таких символов? На помощь нам приходит следующая compile-time функция:
constexpr bool str_is_correct(const char* const str)
{
return (static_cast<signed char>(*str) > 0) ? str_is_correct(str + 1) : (*str ? false : true);
}
Она проверяет, содержит ли известная на стадии компиляции строка только символы из диапазона 0-127, и возвращает false в случае нахождения «запретного» символа. Зачем нужен принудительный каст к signed char? Дело в том, что в стандарте C++ не определено, чем же именно является тип char — он может быть как знаковым, так и беззнаковым. А вот его sizeof всегда будет равен 1, отчего мы смещаемся вправо на единицу. Таким образом, нужный нам макрос CASE будет иметь вид:
#define CASE(str) static_assert(str_is_correct(str), "CASE string contains wrong characters");\
case str_hash(...)
Тут используется ещё одна фича C++11 — assert при компиляции. То есть, если строка-аргумент макроса CASE будет содержать хотя бы один «запретный» символ — компиляция остановится со вполне понятной ошибкой. Иначе, будет вычислен хэш, значение которого подставится в case. Это решение избавит нас от проблем с кодировкой. Осталось лишь написать саму функцию str_hash(), которая и вычислит нужный хэш.
Возвращаемся к вычислению хэша
Выбрать хэш-функцию можно по-разному, и самый главный вопрос тут — это возможность коллизий. Если хэши двух различных строк совпадут, то программа может перепрыгнуть со switch на ложную case-ветку. И спутник упадёт в океан… Поэтому будем использовать хэш-функцию, не имеющую коллизий вообще. Так как уже установлено, что все символы строки расположены в диапазоне 0-127, то функция будет иметь вид:
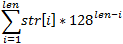 . Её реализация такова:
. Её реализация такова: typedef unsigned char uchar;
typedef unsigned long long ullong;
constexpr ullong str_hash(const char* const str, const uchar current_len)
{
return *str ? (raise_128_to(current_len - 1) * static_cast<uchar>(*str)
+ str_hash(str + 1, current_len - 1)) : 0;
}
Здесь raise_128_to() — это compile-time функция возведения 128 в степень, а current_len — это длина текущей строки. Конечно, длину можно вычислять и на каждом шаге рекурсии, но это лишь замедлит компиляцию — лучше сосчитать её до первого запуска str_hash(), и затем всегда подставлять как дополнительный аргумент. При какой же максимальной длине строки эта функция не будет иметь коллизий? Очевидно, лишь тогда, когда полученное ею значение всегда уместится в диапазоне типа unsigned long long (также окончательно введённого в C++11), то есть если оно не превышает 264-1.
Можно подсчитать, что эта максимальная длина будет равна 9 (обозначим это число как MAX_LEN). А вот максимально возможное значение хэша составит ровно 263 для строки, все символы которой имеют код 127 (и являются нечитаемыми в ASCII, так что под CASE мы её всё равно не загоним). Но как быть, если под CASE будет стоять строка из 10 символов? Если мы действительно не хотим возникновения коллизий, то нужно запретить и такую возможность — то есть, расширить уже используемый нами static_assert:
#define CASE(str) static_assert(str_is_correct(str) && (str_len(str) <= MAX_LEN),\
"CASE string contains wrong characters, or its length is greater than 9");\
case str_hash(str, str_len(str))
Производим финальные штрихи
Всё, с макросом CASE покончено. Он либо выдаст нам ошибку компиляции, либо вычислит уникальное значение хэша. Вот для подсчёта хэша в макросе SWITCH нам придётся сделать отдельную функцию, поскольку она будет работать уже в рантайме. А если её строка-аргумент будет иметь длину более 9 символов, то договоримся возвращать 264-1 (обозначим это число как N_HASH). Итак:
#define SWITCH(str) switch(str_hash_for_switch(str))
const ullong N_HASH = static_cast<ullong>(-1); // по аналогии с std::string::npos
inline ullong str_hash_for_switch(const char* const str)
{
return (str_is_correct(str) && (str_len(str) <= MAX_LEN)) ? str_hash(str, str_len(str)) : N_HASH;
}
Собственно, вот и всё. В рантайме вычислится хэш для строки в SWITCH, и если одна строк в CASE имеет такой же хэш, исполнение пойдёт на неё. Если какая-то строка из CASE содержит «запретные» символы, или её длина больше 9 символов — мы получим надёжную ошибку компиляции. Нагрузки в рантайме почти нет (за исключением однократного вычисление хэша для SWITCH), читаемость кода не страдает. Осталось лишь перегрузить функцию str_hash_for_switch() для строк std::string, и заключить всё внутрь namespace.
Итоговый h-файл исходников лежит на Гитхабе. Он подойдёт для любого компилятора с поддержкой C++11. Для использования «switch для строк» просто сделайте инклуд str_switch.h куда хотите, и всё — макросы SWITCH, CASE и DEFAULT перед вами. Не забудьте про ограничение на длину строки в CASE (9 символов).
В общем — надеюсь, что кому-нибудь эта реализация пригодится ;)
P. S. Upd: в коде была обнаружена пара неточностей — поэтому сейчас он обновлён, вместе со статьёй. В комментариях также предлагалось использовать другую функцию для вычисления хэша — разумеется, каждый может написать свою её реализацию.
