Мне предстоит проект, модуль которого будет большую часть времени работать с другим сервером, отправляя ему GET запросы.
Я провел тесты чтобы определить каким способом получать страницу будет быстрее (в рамках предполагаемых технологий проекта).
Первые 3 теста: каждым из способов выполнялось по 50 запросов подряд к одному сайту.
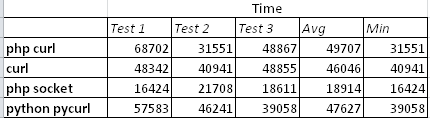
Поясню, что curl — то получение страницы консольной утилитой curl в Linux. Все тесты проводились в Linux.
Также был пятый тест — вызов curl из php через exec, но эту глупость я отбросил.
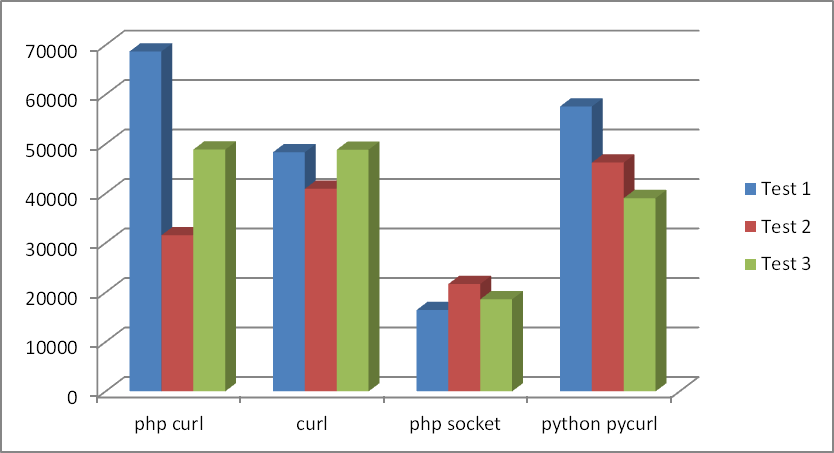
Если усреднить тесты, то получиться такой результат:
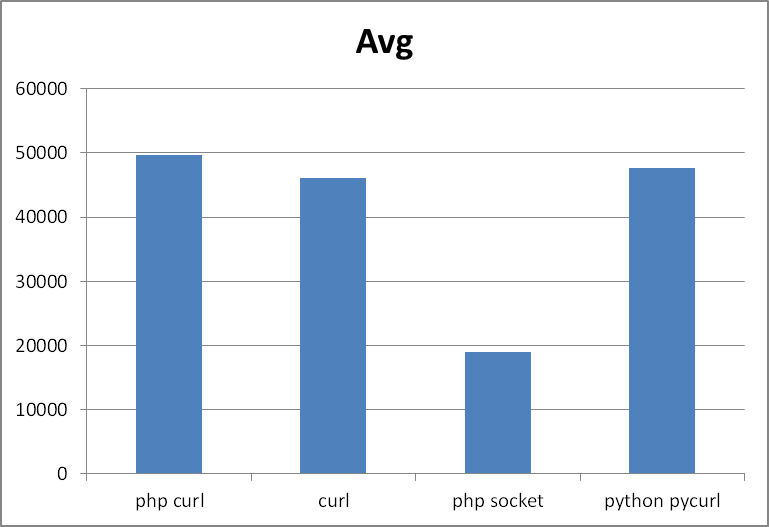
Места:
Если отталкиваться от нижнего значения, то результат меняется:
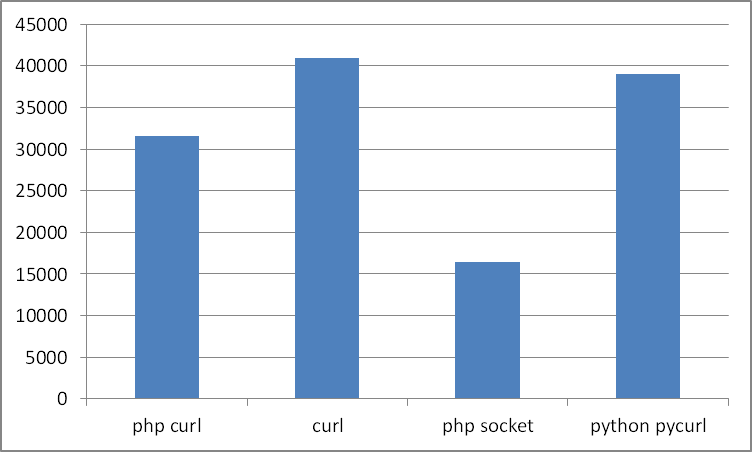
Консольный curl без ЯП меня уже не интересует после таких тестов, но кто же все таки быстрее php+curl или python+pycurl? Еще 4 теста, в которых участвовала только эта пара:

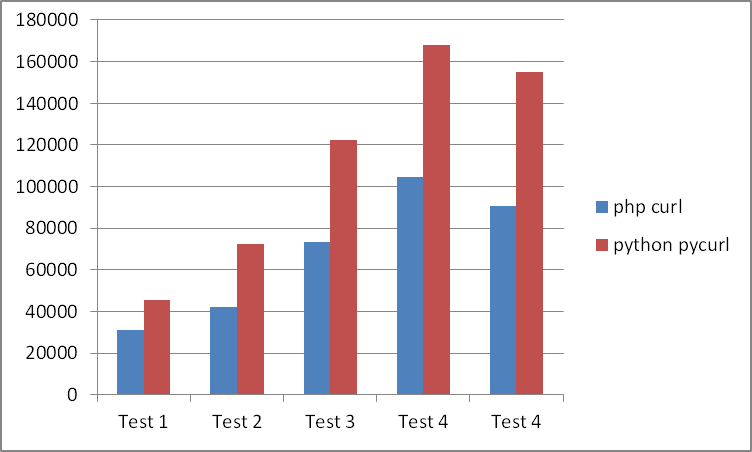
php честно отработал быстрее во всех 4 тестах.
Использовать библиотеку curl при простых GET запросах
— это снижение скорости выполнения почти в 2 раза по сравнению с работой через сокеты.
Кроме этого мы заметили, что питон с библиотекой pycurl справляется немного медленнее, чем php с curl.
Возможно тесты в чем то необъективны, если Вы считаете, что это так, обоснуйте в комментариях.
Запускает программу переданную в параметре и замеряет время ее работы в миллисекундах.
Самый быстрый вариант (сокеты)
Для запуска curl:
Для запуска всех тестов:
Я провел тесты чтобы определить каким способом получать страницу будет быстрее (в рамках предполагаемых технологий проекта).
Первые 3 теста: каждым из способов выполнялось по 50 запросов подряд к одному сайту.

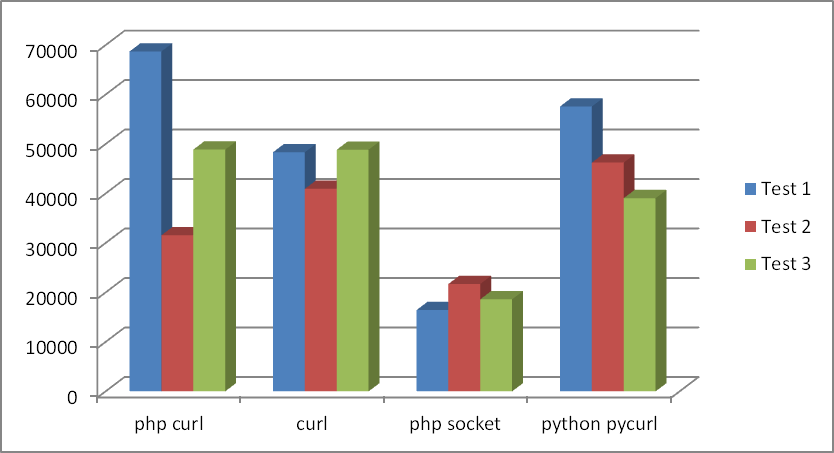
Поясню, что curl — то получение страницы консольной утилитой curl в Linux. Все тесты проводились в Linux.
Также был пятый тест — вызов curl из php через exec, но эту глупость я отбросил.
Если усреднить тесты, то получиться такой результат:
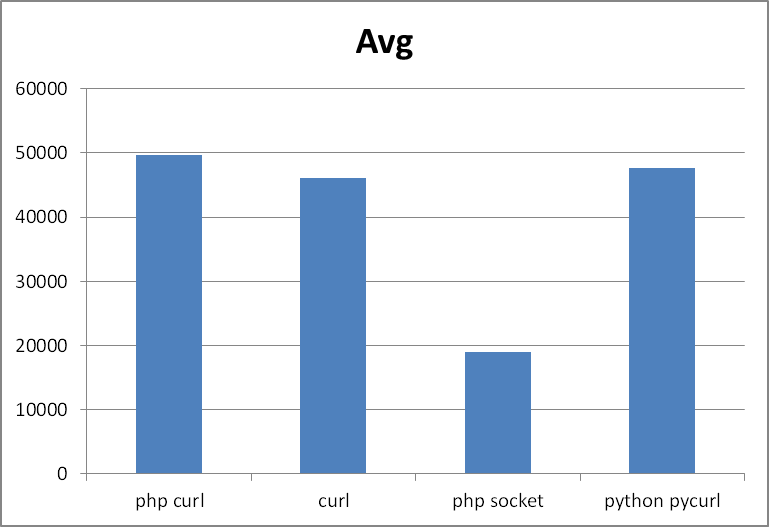
Места:
- php socket
- curl
- python pycurl
- php curl
Если отталкиваться от нижнего значения, то результат меняется:
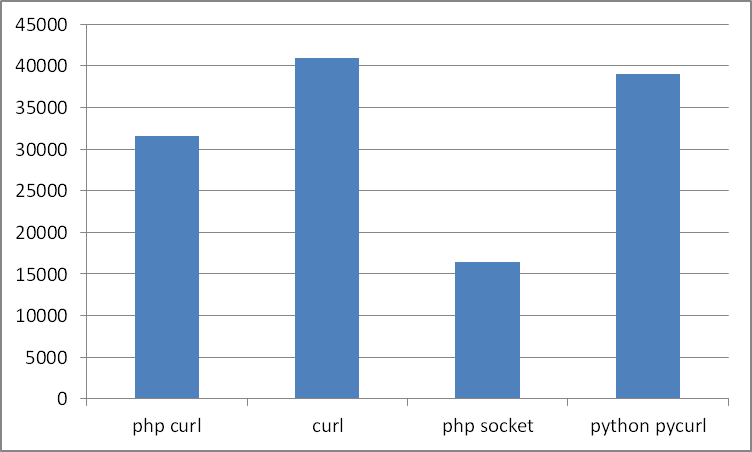
- php socket
- php curl
- python pycurl
- curl
Консольный curl без ЯП меня уже не интересует после таких тестов, но кто же все таки быстрее php+curl или python+pycurl? Еще 4 теста, в которых участвовала только эта пара:


php честно отработал быстрее во всех 4 тестах.
Итоги тестов
Использовать библиотеку curl при простых GET запросах
— это снижение скорости выполнения почти в 2 раза по сравнению с работой через сокеты.
Кроме этого мы заметили, что питон с библиотекой pycurl справляется немного медленнее, чем php с curl.
Возможно тесты в чем то необъективны, если Вы считаете, что это так, обоснуйте в комментариях.
Код для этих тестов
Небольшая программа на C
Запускает программу переданную в параметре и замеряет время ее работы в миллисекундах.
#include <sys/time.h>
#include <stdlib.h>
struct timeval tv1, tv2, dtv;
struct timezone tz;
//time_ functions from http://ccfit.nsu.ru/~kireev/lab1/lab1time.htm
void time_start()
{
gettimeofday(&tv1, &tz);
}
long time_stop()
{
gettimeofday(&tv2, &tz);
dtv.tv_sec= tv2.tv_sec -tv1.tv_sec;
dtv.tv_usec=tv2.tv_usec-tv1.tv_usec;
if(dtv.tv_usec < 0)
{
dtv.tv_sec--;
dtv.tv_usec += 1000000;
}
return dtv.tv_sec * 1000 + dtv.tv_usec / 1000;
}
int main(int argc, char **argv)
{
if(argc > 1)
{
time_start();
system(argv[1]);
printf("\nTime: %ld\n", time_stop());
}
else
printf("Usage:\n timer1 command\n");
return 0;
}
PHP
$t = 'http://www.2ip.ru/'; //target
for($i=0; $i < 50; $i++)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $t);
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLINFO_HEADER_OUT, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (X11; Linux x86_64; rv:17.0) Gecko/17.0 Firefox/17.0');
curl_setopt($ch, CURLOPT_ENCODING, 'utf-8');
curl_setopt($ch, CURLOPT_TIMEOUT, 200);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
$data = curl_exec($ch);
curl_close($ch);
}
Самый быстрый вариант (сокеты)
$t = 'http://www.2ip.ru/'; //target
for($i=0; $i < 50; $i++)
{
$service_port = 80;
$address = gethostbyname('www.2ip.ru');
$socket = socket_create(AF_INET, SOCK_STREAM, SOL_TCP);
if ($socket === false) {
echo "socket_create() failed: reason: " . socket_strerror(socket_last_error()) . "\n";
} else {
//echo "OK.\n";
}
$result = socket_connect($socket, $address, $service_port);
if ($result === false) {
echo "socket_connect() failed.\nReason: ($result) " . socket_strerror(socket_last_error($socket)) . "\n";
} else {
//echo "OK.\n";
}
$in = "GET / HTTP/1.1\r\n";
$in .= "Host: www.example.com\r\n";
$in .= "Connection: Close\r\n\r\n";
$out = '';
$r = '';
socket_write($socket, $in, strlen($in));
while ($out = socket_read($socket, 2048)) {
$r .= $out;
}
socket_close($socket);
//echo $r;
}
Python
import pycurl
import cStringIO
for i in range(50):
buf = cStringIO.StringIO()
c = pycurl.Curl()
c.setopt(c.URL, 'http://www.2ip.ru/')
c.setopt(c.WRITEFUNCTION, buf.write)
c.perform()
#print buf.getvalue()
buf.close()
Скрипты bash
Для запуска curl:
#!/bin/bash
testdir="/home/developer/Desktop/tests"
i=0
while [ $i -lt 50 ]
do
curl -s -o "$testdir/tmp_some_file" "http://www.2ip.ru/"
let i=i+1
done
Для запуска всех тестов:
#!/bin/bash
testdir="/home/developer/Desktop/tests"
echo "php curl"
"$testdir/timer1" "php $testdir/testCurl.php"
echo "curl to file"
"$testdir/timer1" "bash $testdir/curl2file.sh"
#echo "curl to file (php)"
#"$testdir/timer1" "php $testdir/testCurl2.php"
echo "php socket"
"$testdir/timer1" "php $testdir/testCurl3.php"
echo "python pycurl"
"$testdir/timer1" "python $testdir/1.py"
