В статье я расскажу небольшую историю про маленькую техническую задачку и о том, как её решали разные люди вокруг. Быть может этот рассказ поможет читателю вынести несколько уроков о том, какие временами встречаются ошибки.
Немножко матана инклудэд.

Идея распознавать людей по радужной оболочке появилась в далёком 1987 у доктора Джона Доугмана и была запатентована в 1989. Примерно тогда же появился прототип. На тот момент это была вершина технологии. Пару лет до первой коммерческой цифровой камеры + алгоритм обработки изображения на компьютерах уровня i386/i486. До сих пор я не представляю, как можно получать на таком оборудовании стабильный результат.
Задачка о которой я хочу рассказать появилась на свет где-то в 2006-2009 годах. Процессоры к этому времени несколько ускорились, появились хорошие камеры, патент 1989 года истёк и системы распознавания по глазам теперь получил право делать каждый. Люди, которые решили сделать клон системы захотели использовать современные технологии и улучшить алгоритм. Самое первое, что бросалось в глаза — старый алгоритм сравнения глаз использовал изображение глаза в близком ИК диапазоне. То, что глаза бывают цветными не учитывалось.
Статья, которую вы читаете, 2013 года. Сейчас, когда я пишу этот приквел — уже 2021. С 2013 изменилось очень-очень многое. Радужка глаза уже не самая перспективная биометрия. Технологии поменялись, рынок устаканился, и.т.д., и.т.п…
Чем закончилась наша эпопея с радужкой я год назад делал длинное видео, навнерное, после прочтения статьи его будет интересно посмотреть:
А так, я часто пишу на своем канале (vk, telegram) про более новые методы/подходы.
Радужная оболочка глаза является уникальной характеристикой человека. Рисунок радужки формируется на восьмом месяце внутриутробного развития, окончательно стабилизируется в возрасте около двух лет и практически не изменяется в течение жизни, кроме как в результате сильных травм или резких патологий. Метод является одним из наиболее точных среди биометрических методов.
Классический алгоритм распознавания для чёрно-белых глаз, состоит из двух частей — сегментация и сравнение.
Сегментация это выделение самого глаза на фотографии или в видеопотоке. Алгоритм сегментации сильно зависит от используемого оборудования и оптической конфигурации. В отличие от сравнения, которое является математически строгой задачей, сегментация это задача со слишком большим количеством переменных. Всегда приходится что-то выдумывать и настраивать. Доугман в своём патенте предлагал при сегментации искать глаз как окружность для которой градиент максимален:
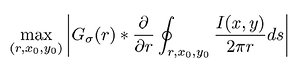
Здесь G — оператор гауссовского размытия изображения, а I(x,y) — само изображение. При этом количество гипотез, которые нужно перебирать примерно равно W∙H∙(Rmax-Rmin), где W — ширина изображения, H — его высота, Rmaxи Rmin максимальные и минимальные радиусы соответственно. Алгоритм Доугмана это вывернутое наизнанку преобразование Хафа для окружностей. В чистом виде он неприменим. Преобразование Хафа само по себе нестабильно к тому же на современных процессорах Intel i7 эта операция для 1.3 мегапиксельного изображения без предварительной оптимизации составляет порядка нескольких секунд. Существует много хитростей и уловок, чтобы добиться работы в реальном времени.
Одна из самых красивых — использовать освещение, которое даёт характерный блик на зрачке и искать этот блик. Такие блики хорошо видны вот здесь:
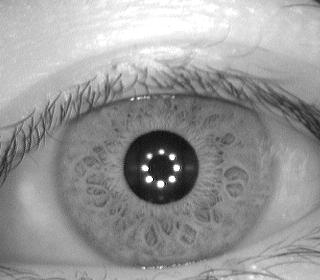
Задача поиска блика вычислительно значительно проще, чем задача поиска глаза. А глаз ищется потом в окрестности блика.
В результате сегментации детектируется зрачок и радужка. На радужке отмечаются области, интересные для дальнейшего использования. Получается сегментированная область:

Вторая часто это сравнение. После выделения радужки её нужно нормализовать для удобного сравнения с другими радужками. Радужка разворачивается из полярных координат в прямоугольник и фильтруется. В качестве фильтра Доугман предлагал использовать фильтр Габора, который позволяет подчеркнуть характеристические области и понизить высокочастотные шумы:
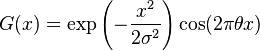
Хотя, конечно, используемый фильтр настраивается в зависимости от оборудования. Преобразованную радужку принято называть Iris Code. Выглядят такие радужки как-то так:
 -Развёрнутая цветная радужка.
-Развёрнутая цветная радужка.
__________________________________________________________________________
 -Развёрнутая чёрно-белая радужка с маской поверх.
-Развёрнутая чёрно-белая радужка с маской поверх.
__________________________________________________________________________
 — Чистый Iris Code.
— Чистый Iris Code.
Для того, чтобы сравнить две радужки, для полученных Iris Code строят дистанцию Хемминга, которая в данном случае является мерой корреляции объектов. Чем меньше дистанция Хэмминга между двумя кодами, тем ближе друг к другу они расположены. Если мы сравним достаточно большую базу картинок друг с другом, вычислим для неё дистанцию Хэмминга и построим полученную гистограмму, то получится такое распределение:
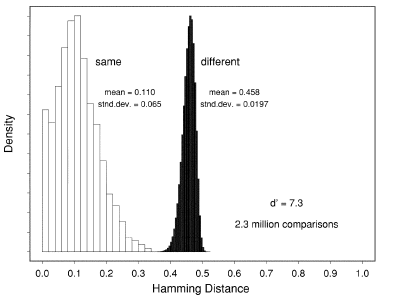
Левый горб, нарисованный белым, будут формировать сравнения одинаковых глаз с одинаковыми. Правый горб, нарисованный чёрным, будут формировать сравнения разных глаз между собой. Из этого графика берётся число, которое хорошо разделяет два горба. Обычно его выбирают ближе к левому горбу: не допустить человека лучше, чем пропустить шпиона. Для данного графика это что-то типа 0.32.
В дальнейшем система принимает решение, что человека можно пропускать, если код его глаза имеет дистанцию меньше чем 0.32 с каким-либо другим кодом из базы.
Тематикой распознавания по глазам я и ещё двое друзей (один — Vasyutka, второй — Strepetarh) начали заниматься на 4ом курсе МФТИ. Нам нужно было сделать курсовой проект по безопасности информации. Тогда мы сделали простенькую систему распознавания по глазам при помощи веб-камеры, корпуса от колонки, брелка от ключей и прищепки. Увидев насколько она хорошо работает (выиграли институтский конкурс и заимели много положительных отзывов) мы решили её допилить в полноценную систему. За следующий год неспешного программирования мы довели системы до вполне рабочего продукта. Тут-то и пришли инвесторы. Но они хотели странного.
В то же время, когда мы занялись глазами наши будущие инвесторы натолкнулись на то, что идея того, чтобы распознавать глаза не по чёрно-белой картинке, а по цветной — ещё нигде и никогда не была запатентована. А будучи людьми, достаточно технически подкованными и обладающими коммерческой жилкой они решили получить патент. Правда, программировать они не умели, а уж тем более не разбирались в присущей делу математике.
Вернёмся к нашим баранам. Сначала инвесторы пришли не к нам, а в единственную фирму, которая в России занималась распознаванием по глазам и имела законченный продукт (готовый сканер + алгоритмы). Инвесторы заказали исследование на тему того, как распознавание по цветному изображению улучшит статистику. Подход к задаче у фирмы был ужасно технический. Они построили код Iris Code для каждого канала RGB отдельно и сравнивали для одного и того же человека три элемента. По сути взяли уже имеющуюся технологию и вложили в неё новые данные.
Посмотрим, что они сделали в реальности. Разложим изображение на каналы:
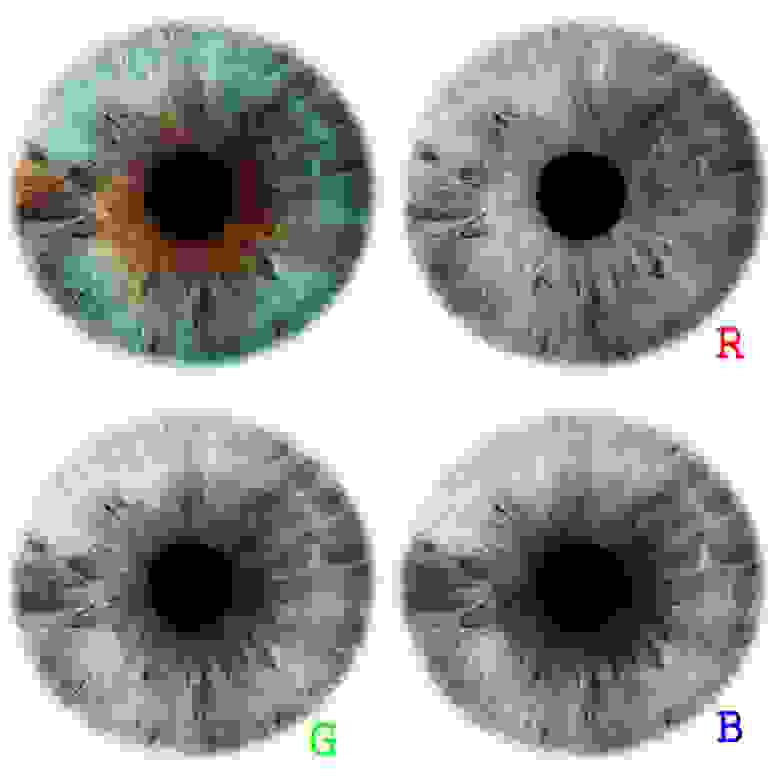
Как было упомянуто выше, для подчёркивания текстуры изображения принято использовать фильтр Габора или какой-нибудь другой фильтр средних частот, подчёркивающий границы. Эти картинки он превращает в:
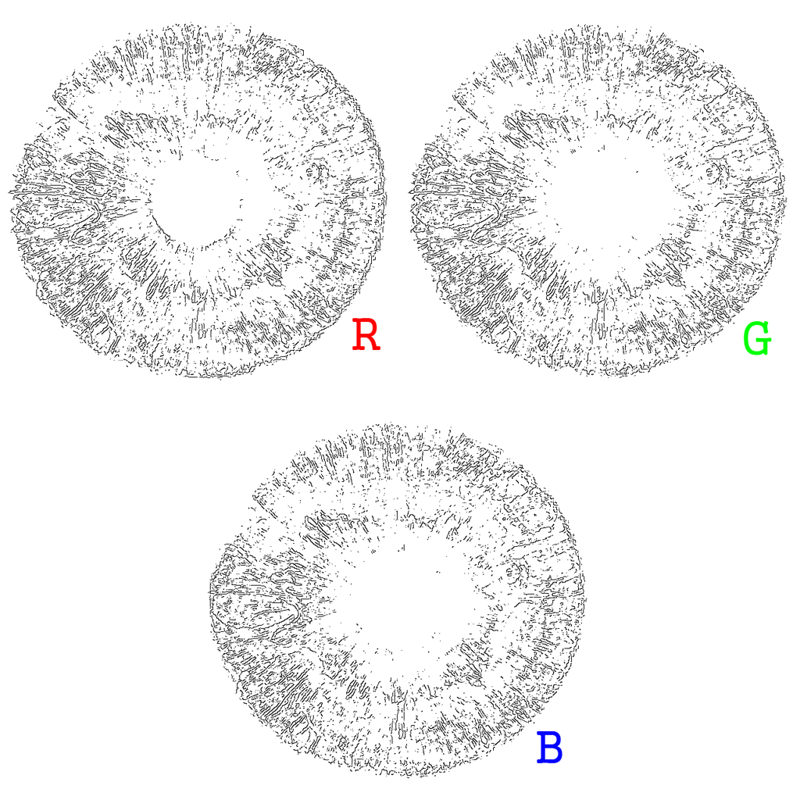
Как видно, структура для всех цветов получается практически идентичной. Результаты сравнения глаз по разным цветам будут практически всегда совпадать. В отчёте, написанном той фирмой, сей вывод был блестяще подтверждён. Более того, статистика при таком распознавании значительно ухудшается. Как-никак цветная камера использует фильтр Байера:
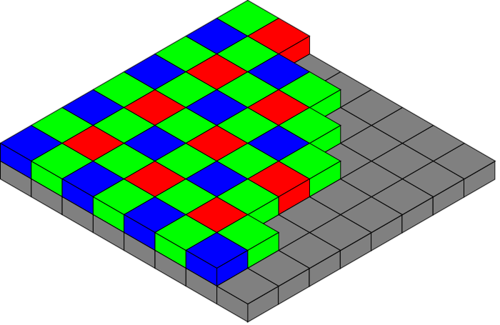
А значит для того, чтобы иметь цветное изображение такого же разрешения как и чёрно-белое нужно использовать в четыре раза более мелкие пиксели, которые из-за фильтра будут собирать в три раза меньше света. Что значительно понижает отношение сигнал/шум.
Вторая проблема при таком подходе — чёрные глаза. Для того, чтобы в них что-то увидеть при белом освещении, там нужно выжечь всё.

В общем, исходя из сказанного ребята заявили, что распознавание по цветным глазам невозможно.
Мысль 1. Хорошо зарекомендовавшие себя методы далеко не всегда будут работать в новых условиях. Если перед вами стоит исследовательская задачка и известные методы не сработали — это не значит, что задачка не решается.
Если следовать сюжету, то тут должен был бы быть раздел о том, как появились мы и всё быстро разрешили. Не люблю линейное повествование. Расскажу лучше сначала о том, как к этой проблеме подходили в остальном мире в различных институтах. На эти исследования мы натолкнулись уже после того, как сделали работающий алгоритм распознавания по цвету. И с интересом разглядывали в какие дебри людей сумел завести их научный подход.
То, что при использовании цвета как RGB информация дублируется в каждом слое — пришло в голову многим. Логично было бы использовать такое цветовое пространство, где информация о яркости была бы независима от цветовой. Это возможно, если цвет каждого пикселя рассматривать как некую одномерную характеристику, чтобы два пикселя можно было сравнить. Думаю, что почти все читатели знакомы с цветовым пространством HSL (HSV). В нём координаты цвета задаются через яркость, насыщенность и тон (аналог длинны волны).
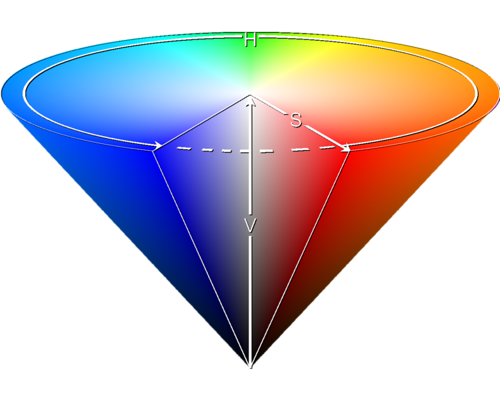
Первая работа на эту тему, думаю, была вот эта. После неё была целая серия исследований, проводимых в португальском институте. Исследователи экспериментировали с переводом в различные цветовые пространства и сравнением изображений в них. Они честно проверили все стандартные цветовые пространства: Lab, CMYK, HSV и.т.д… Выделили радужки и коррелировали их друг с другом. Построили распределение FAR и FRR для всех цветов, а также их статистическую зависимость друг от друга. Нарисовали много красивых табличек. Расписали преимущества и недостатки различных цветовых пространств. И оказалось, что длинна волны слишком нестабильный признак. Слишком много шумов в нём по сравнению с остальными. И ведь правда! Если посмотреть на то как приведённый выше глаз выглядит в пространстве HSL, можно заметить, что в H канале ужасные шумы.

При попытке сравнения двух изображений глаза корреляция будет куда хуже, чем в остальных каналах. В результате исследования показали, что единственная статистически независимая от яркости характеристика это цвет глаза. После чего они радостно отмели её, как слишком зашумлённую и недостоверную.
Мысль 2. Если новая исследовательская задача похожа на старую, то при её решении в первую очередь стоит сфокусироваться на различиях. Если различия несущественны, то разве имеет новая задача смысл?
Нужно признать, что хорошую статистику со своим подходом они всё же получили. Например вот в этой статье. Правда к реальности оно уже не имеет никакого отношения. В отличие от предыдущего исследования использовалась не реальная база глаз, а база полученная примерно таким образом:

При съёмке такой базы фиксируется голова и в глаз бьёт сильная вспышка. Получено разрешение в несколько раз лучше, чем в любом из существующих нормальных сканеров.
В реальности разрешения используемых сканеров глаз позволяют захватывать глаза с радиусом радужки в 70-100 пикселей. Это обуславливается силой допустимого освещения и глубиной резкости системы.
Мысль 3. Решая реальную задачку следует отталкиваться в первую очередь от характеристик используемого оборудования, а не от красивой математической модели.
После того, как разработчики из первой компании, куда обратился инвестор, объяснили, что распознавание по цвету хуже, чем распознавание по ЧБ, инвестор забеспокоился. Патент стоит не дешево и требовал дополнительных вливаний средств на его поддержание. Нас инвестор нашёл за три дня до того, как им требовалось принять решение, оставить ли проект, или слить его. И уже за эти три дня нами было найдено первое решение, позволяющее улучшить статистику. Как всегда в таких ситуациях реализуется подход: «Что бы быстрее придумать, чтобы оно работало». Надо сравнивать цветные глаза? Так давайте сравним ЧБ и добавим сравнение по среднему цвету глаза. Оказалось, вероятность того, что цвет вашего глаза совпадает с произвольно взятым глазом где-то 10% при 90% совпадения с самим собой.
Этого оказалось достаточно, чтобы улучшить статистику в 3 раза, чего не добивалось ни одно вышеописанное исследование.
Удовлетворив инвестора и подтолкнув его к тому, что он остался в теме и заключил с нами договор мы начали реальное исследование. И уже с первого шага мы пошли другим путём, чем все вышеупомянутые работы. Вместо решения математической задачи сравнения цветных глаз мы начали с решения чисто технической задачи: «Как цветные камеры снимают глаза и сколько освещения при этом требуется». Уже после первого азиата с практически чёрной радужкой мы поняли, что отказываться от инфракрасного спектра нельзя. Для этого нам пришлось использовать цветную камеру со снятым ИК фильтром и с двумя системами подсветки: инфракрасной и цветной. Инфракрасная часть должна была обеспечить классическое сравнение, а цветная часть должна была добавить дополнительную составляющую, которая бы делала систему «сильнее» всех существующих.
Получив достаточную базу изображений глаз мы стали пробовать вытянуть дополнительную информацию из цветных глаз. Конечно, мы опробовали сравнение в RGB спектре, убедившись почти сразу, что оно ничего не даёт. И сразу после этого мы пришли к сравнению в HSL спектре. Кстати, глаз, разложенный в HSL пространство выше был получен «хорошим» методом фотографирования. Реальные глаза, получаемые камерой выглядят следующим образом:
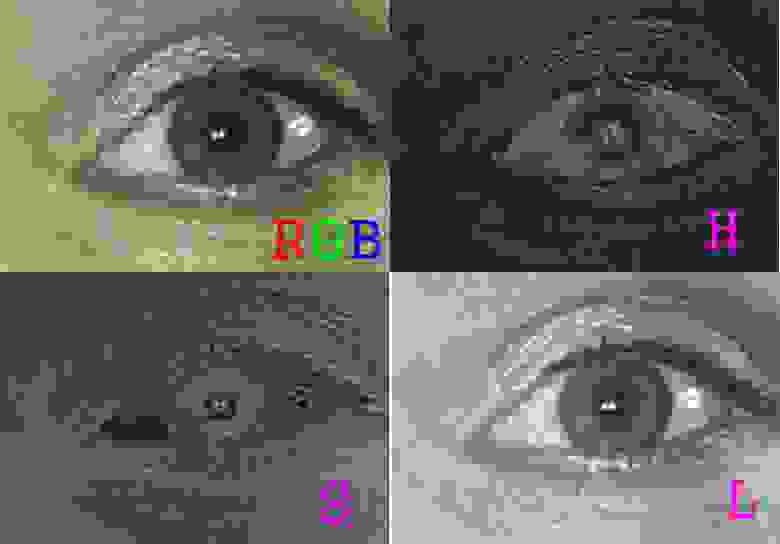
Над похожими картинками мы тупили несколько дней. Ведь, с одной стороны, в H и S канале содержится новая информация. Но с другой стороны — она сильно зашумлена, и слегка пространственно коррелированна с ЧБ глазами. Решение оказалось простым и изящным. Если нам нужна информация только о цвете, то надо забить на пространственную информацию. Построить гистограмму распределения цветов для глаза. Такая гистограмма выровняет шумы, усреднив по ним. По таким гистограммам можно быстро сравнивать, а что самое главное, результат распознавания по таким гистограммам для H и S каналов не коррелируют друг с другом и не коррелируют с классическим методом распознавания ЧБ глаз:

Всего двадцать точек гистограммы H дают пересечение кривой ложного допуска и ложного недопуска на уровне 6 процентов. Ещё примерно 10% даёт S гистограмма. Конечно, такие проценты не складываются, их надо учитывать более хитрым способом. Например SVM.
На всё это исследование нам понадобилось где-то 15 дней и полтора человека. Что очень забавно сравнивать с научной деятельностью, которую в течении нескольких лет вокруг этой тематики развели в вышеприведённых статьях.
У этого рассказа было две цели. Первый — рассказать историю с небольшим количеством матана, и убить ваши десять минут на её чтение. Вторая — обратить внимание на несколько проблем в разработке алгоритмов, которые часто встречаются вокруг и в которые я сам регулярно влипаю.
Первая проблема это чрезмерное увлечение существующими паттернами. Часто при решении новой задачи её пытаются свести к уже имеющимся алгоритмам. И ведь не скажешь, что это плохо. Но желание пойти по проторенной дорожке часто обесценивает всю работу. Самый феерический пример, это однажды встреченная мне в каком-то отчёте фраза: «Эту задачу нельзя решить методами OpenCV, значит она неразрешима».
Вторая проблема — чрезмерный перфекционизм. Когда задача мало-мальски научная, она порождает целое дерево ветвящихся возможностей для её разработки. Далеко не в каждой вершине находится что-то полезное. Очень часто сложно, почти невозможно, сосредоточиться на той цели, которая лежит в сути задачи. Начинаются бесконечные исследования пустых мест. И ведь самое ужасное, что современное научное сообщество поощряет такой подход. И если в математике или теоретической физике оно хоть немного имеет смысл, то в технических науках он порождает всё больше и больше «британских учёных». Индекс Хирша тому свидетель. Ощущение, что это уже какой-то симулякр, где даже Поппер со своим бубном бессилен…
Вот так и идёшь между Сциллой и Харибдой, решая очередную задачу. И повторяться нельзя и закапываться. А что в таких случаях делаете вы?
Немножко матана инклудэд.
Идея распознавать людей по радужной оболочке появилась в далёком 1987 у доктора Джона Доугмана и была запатентована в 1989. Примерно тогда же появился прототип. На тот момент это была вершина технологии. Пару лет до первой коммерческой цифровой камеры + алгоритм обработки изображения на компьютерах уровня i386/i486. До сих пор я не представляю, как можно получать на таком оборудовании стабильный результат.
Задачка о которой я хочу рассказать появилась на свет где-то в 2006-2009 годах. Процессоры к этому времени несколько ускорились, появились хорошие камеры, патент 1989 года истёк и системы распознавания по глазам теперь получил право делать каждый. Люди, которые решили сделать клон системы захотели использовать современные технологии и улучшить алгоритм. Самое первое, что бросалось в глаза — старый алгоритм сравнения глаз использовал изображение глаза в близком ИК диапазоне. То, что глаза бывают цветными не учитывалось.
NB!
Статья, которую вы читаете, 2013 года. Сейчас, когда я пишу этот приквел — уже 2021. С 2013 изменилось очень-очень многое. Радужка глаза уже не самая перспективная биометрия. Технологии поменялись, рынок устаканился, и.т.д., и.т.п…
Чем закончилась наша эпопея с радужкой я год назад делал длинное видео, навнерное, после прочтения статьи его будет интересно посмотреть:
А так, я часто пишу на своем канале (vk, telegram) про более новые методы/подходы.
Немножко теории
Радужная оболочка глаза является уникальной характеристикой человека. Рисунок радужки формируется на восьмом месяце внутриутробного развития, окончательно стабилизируется в возрасте около двух лет и практически не изменяется в течение жизни, кроме как в результате сильных травм или резких патологий. Метод является одним из наиболее точных среди биометрических методов.
Классический алгоритм распознавания для чёрно-белых глаз, состоит из двух частей — сегментация и сравнение.
Сегментация это выделение самого глаза на фотографии или в видеопотоке. Алгоритм сегментации сильно зависит от используемого оборудования и оптической конфигурации. В отличие от сравнения, которое является математически строгой задачей, сегментация это задача со слишком большим количеством переменных. Всегда приходится что-то выдумывать и настраивать. Доугман в своём патенте предлагал при сегментации искать глаз как окружность для которой градиент максимален:

Здесь G — оператор гауссовского размытия изображения, а I(x,y) — само изображение. При этом количество гипотез, которые нужно перебирать примерно равно W∙H∙(Rmax-Rmin), где W — ширина изображения, H — его высота, Rmaxи Rmin максимальные и минимальные радиусы соответственно. Алгоритм Доугмана это вывернутое наизнанку преобразование Хафа для окружностей. В чистом виде он неприменим. Преобразование Хафа само по себе нестабильно к тому же на современных процессорах Intel i7 эта операция для 1.3 мегапиксельного изображения без предварительной оптимизации составляет порядка нескольких секунд. Существует много хитростей и уловок, чтобы добиться работы в реальном времени.
Одна из самых красивых — использовать освещение, которое даёт характерный блик на зрачке и искать этот блик. Такие блики хорошо видны вот здесь:

Задача поиска блика вычислительно значительно проще, чем задача поиска глаза. А глаз ищется потом в окрестности блика.
В результате сегментации детектируется зрачок и радужка. На радужке отмечаются области, интересные для дальнейшего использования. Получается сегментированная область:

Вторая часто это сравнение. После выделения радужки её нужно нормализовать для удобного сравнения с другими радужками. Радужка разворачивается из полярных координат в прямоугольник и фильтруется. В качестве фильтра Доугман предлагал использовать фильтр Габора, который позволяет подчеркнуть характеристические области и понизить высокочастотные шумы:

Хотя, конечно, используемый фильтр настраивается в зависимости от оборудования. Преобразованную радужку принято называть Iris Code. Выглядят такие радужки как-то так:
 -Развёрнутая цветная радужка.
-Развёрнутая цветная радужка.__________________________________________________________________________
 -Развёрнутая чёрно-белая радужка с маской поверх.
-Развёрнутая чёрно-белая радужка с маской поверх.__________________________________________________________________________
 — Чистый Iris Code.
— Чистый Iris Code.Для того, чтобы сравнить две радужки, для полученных Iris Code строят дистанцию Хемминга, которая в данном случае является мерой корреляции объектов. Чем меньше дистанция Хэмминга между двумя кодами, тем ближе друг к другу они расположены. Если мы сравним достаточно большую базу картинок друг с другом, вычислим для неё дистанцию Хэмминга и построим полученную гистограмму, то получится такое распределение:

Левый горб, нарисованный белым, будут формировать сравнения одинаковых глаз с одинаковыми. Правый горб, нарисованный чёрным, будут формировать сравнения разных глаз между собой. Из этого графика берётся число, которое хорошо разделяет два горба. Обычно его выбирают ближе к левому горбу: не допустить человека лучше, чем пропустить шпиона. Для данного графика это что-то типа 0.32.
В дальнейшем система принимает решение, что человека можно пропускать, если код его глаза имеет дистанцию меньше чем 0.32 с каким-либо другим кодом из базы.
Предыстория
Тематикой распознавания по глазам я и ещё двое друзей (один — Vasyutka, второй — Strepetarh) начали заниматься на 4ом курсе МФТИ. Нам нужно было сделать курсовой проект по безопасности информации. Тогда мы сделали простенькую систему распознавания по глазам при помощи веб-камеры, корпуса от колонки, брелка от ключей и прищепки. Увидев насколько она хорошо работает (выиграли институтский конкурс и заимели много положительных отзывов) мы решили её допилить в полноценную систему. За следующий год неспешного программирования мы довели системы до вполне рабочего продукта. Тут-то и пришли инвесторы. Но они хотели странного.
В то же время, когда мы занялись глазами наши будущие инвесторы натолкнулись на то, что идея того, чтобы распознавать глаза не по чёрно-белой картинке, а по цветной — ещё нигде и никогда не была запатентована. А будучи людьми, достаточно технически подкованными и обладающими коммерческой жилкой они решили получить патент. Правда, программировать они не умели, а уж тем более не разбирались в присущей делу математике.
Первый заход к задачке
Вернёмся к нашим баранам. Сначала инвесторы пришли не к нам, а в единственную фирму, которая в России занималась распознаванием по глазам и имела законченный продукт (готовый сканер + алгоритмы). Инвесторы заказали исследование на тему того, как распознавание по цветному изображению улучшит статистику. Подход к задаче у фирмы был ужасно технический. Они построили код Iris Code для каждого канала RGB отдельно и сравнивали для одного и того же человека три элемента. По сути взяли уже имеющуюся технологию и вложили в неё новые данные.
Посмотрим, что они сделали в реальности. Разложим изображение на каналы:

Как было упомянуто выше, для подчёркивания текстуры изображения принято использовать фильтр Габора или какой-нибудь другой фильтр средних частот, подчёркивающий границы. Эти картинки он превращает в:

Как видно, структура для всех цветов получается практически идентичной. Результаты сравнения глаз по разным цветам будут практически всегда совпадать. В отчёте, написанном той фирмой, сей вывод был блестяще подтверждён. Более того, статистика при таком распознавании значительно ухудшается. Как-никак цветная камера использует фильтр Байера:

А значит для того, чтобы иметь цветное изображение такого же разрешения как и чёрно-белое нужно использовать в четыре раза более мелкие пиксели, которые из-за фильтра будут собирать в три раза меньше света. Что значительно понижает отношение сигнал/шум.
Вторая проблема при таком подходе — чёрные глаза. Для того, чтобы в них что-то увидеть при белом освещении, там нужно выжечь всё.

В общем, исходя из сказанного ребята заявили, что распознавание по цветным глазам невозможно.
Мысль 1. Хорошо зарекомендовавшие себя методы далеко не всегда будут работать в новых условиях. Если перед вами стоит исследовательская задачка и известные методы не сработали — это не значит, что задачка не решается.
Исследовательский подход, aka подход британских учёных
Если следовать сюжету, то тут должен был бы быть раздел о том, как появились мы и всё быстро разрешили. Не люблю линейное повествование. Расскажу лучше сначала о том, как к этой проблеме подходили в остальном мире в различных институтах. На эти исследования мы натолкнулись уже после того, как сделали работающий алгоритм распознавания по цвету. И с интересом разглядывали в какие дебри людей сумел завести их научный подход.
То, что при использовании цвета как RGB информация дублируется в каждом слое — пришло в голову многим. Логично было бы использовать такое цветовое пространство, где информация о яркости была бы независима от цветовой. Это возможно, если цвет каждого пикселя рассматривать как некую одномерную характеристику, чтобы два пикселя можно было сравнить. Думаю, что почти все читатели знакомы с цветовым пространством HSL (HSV). В нём координаты цвета задаются через яркость, насыщенность и тон (аналог длинны волны).

Первая работа на эту тему, думаю, была вот эта. После неё была целая серия исследований, проводимых в португальском институте. Исследователи экспериментировали с переводом в различные цветовые пространства и сравнением изображений в них. Они честно проверили все стандартные цветовые пространства: Lab, CMYK, HSV и.т.д… Выделили радужки и коррелировали их друг с другом. Построили распределение FAR и FRR для всех цветов, а также их статистическую зависимость друг от друга. Нарисовали много красивых табличек. Расписали преимущества и недостатки различных цветовых пространств. И оказалось, что длинна волны слишком нестабильный признак. Слишком много шумов в нём по сравнению с остальными. И ведь правда! Если посмотреть на то как приведённый выше глаз выглядит в пространстве HSL, можно заметить, что в H канале ужасные шумы.

При попытке сравнения двух изображений глаза корреляция будет куда хуже, чем в остальных каналах. В результате исследования показали, что единственная статистически независимая от яркости характеристика это цвет глаза. После чего они радостно отмели её, как слишком зашумлённую и недостоверную.
Мысль 2. Если новая исследовательская задача похожа на старую, то при её решении в первую очередь стоит сфокусироваться на различиях. Если различия несущественны, то разве имеет новая задача смысл?
Нужно признать, что хорошую статистику со своим подходом они всё же получили. Например вот в этой статье. Правда к реальности оно уже не имеет никакого отношения. В отличие от предыдущего исследования использовалась не реальная база глаз, а база полученная примерно таким образом:

При съёмке такой базы фиксируется голова и в глаз бьёт сильная вспышка. Получено разрешение в несколько раз лучше, чем в любом из существующих нормальных сканеров.
В реальности разрешения используемых сканеров глаз позволяют захватывать глаза с радиусом радужки в 70-100 пикселей. Это обуславливается силой допустимого освещения и глубиной резкости системы.
Мысль 3. Решая реальную задачку следует отталкиваться в первую очередь от характеристик используемого оборудования, а не от красивой математической модели.
Наше появление
После того, как разработчики из первой компании, куда обратился инвестор, объяснили, что распознавание по цвету хуже, чем распознавание по ЧБ, инвестор забеспокоился. Патент стоит не дешево и требовал дополнительных вливаний средств на его поддержание. Нас инвестор нашёл за три дня до того, как им требовалось принять решение, оставить ли проект, или слить его. И уже за эти три дня нами было найдено первое решение, позволяющее улучшить статистику. Как всегда в таких ситуациях реализуется подход: «Что бы быстрее придумать, чтобы оно работало». Надо сравнивать цветные глаза? Так давайте сравним ЧБ и добавим сравнение по среднему цвету глаза. Оказалось, вероятность того, что цвет вашего глаза совпадает с произвольно взятым глазом где-то 10% при 90% совпадения с самим собой.
Этого оказалось достаточно, чтобы улучшить статистику в 3 раза, чего не добивалось ни одно вышеописанное исследование.
Удовлетворив инвестора и подтолкнув его к тому, что он остался в теме и заключил с нами договор мы начали реальное исследование. И уже с первого шага мы пошли другим путём, чем все вышеупомянутые работы. Вместо решения математической задачи сравнения цветных глаз мы начали с решения чисто технической задачи: «Как цветные камеры снимают глаза и сколько освещения при этом требуется». Уже после первого азиата с практически чёрной радужкой мы поняли, что отказываться от инфракрасного спектра нельзя. Для этого нам пришлось использовать цветную камеру со снятым ИК фильтром и с двумя системами подсветки: инфракрасной и цветной. Инфракрасная часть должна была обеспечить классическое сравнение, а цветная часть должна была добавить дополнительную составляющую, которая бы делала систему «сильнее» всех существующих.
Получив достаточную базу изображений глаз мы стали пробовать вытянуть дополнительную информацию из цветных глаз. Конечно, мы опробовали сравнение в RGB спектре, убедившись почти сразу, что оно ничего не даёт. И сразу после этого мы пришли к сравнению в HSL спектре. Кстати, глаз, разложенный в HSL пространство выше был получен «хорошим» методом фотографирования. Реальные глаза, получаемые камерой выглядят следующим образом:

Над похожими картинками мы тупили несколько дней. Ведь, с одной стороны, в H и S канале содержится новая информация. Но с другой стороны — она сильно зашумлена, и слегка пространственно коррелированна с ЧБ глазами. Решение оказалось простым и изящным. Если нам нужна информация только о цвете, то надо забить на пространственную информацию. Построить гистограмму распределения цветов для глаза. Такая гистограмма выровняет шумы, усреднив по ним. По таким гистограммам можно быстро сравнивать, а что самое главное, результат распознавания по таким гистограммам для H и S каналов не коррелируют друг с другом и не коррелируют с классическим методом распознавания ЧБ глаз:

Всего двадцать точек гистограммы H дают пересечение кривой ложного допуска и ложного недопуска на уровне 6 процентов. Ещё примерно 10% даёт S гистограмма. Конечно, такие проценты не складываются, их надо учитывать более хитрым способом. Например SVM.
На всё это исследование нам понадобилось где-то 15 дней и полтора человека. Что очень забавно сравнивать с научной деятельностью, которую в течении нескольких лет вокруг этой тематики развели в вышеприведённых статьях.
Послесловие
У этого рассказа было две цели. Первый — рассказать историю с небольшим количеством матана, и убить ваши десять минут на её чтение. Вторая — обратить внимание на несколько проблем в разработке алгоритмов, которые часто встречаются вокруг и в которые я сам регулярно влипаю.
Первая проблема это чрезмерное увлечение существующими паттернами. Часто при решении новой задачи её пытаются свести к уже имеющимся алгоритмам. И ведь не скажешь, что это плохо. Но желание пойти по проторенной дорожке часто обесценивает всю работу. Самый феерический пример, это однажды встреченная мне в каком-то отчёте фраза: «Эту задачу нельзя решить методами OpenCV, значит она неразрешима».
Вторая проблема — чрезмерный перфекционизм. Когда задача мало-мальски научная, она порождает целое дерево ветвящихся возможностей для её разработки. Далеко не в каждой вершине находится что-то полезное. Очень часто сложно, почти невозможно, сосредоточиться на той цели, которая лежит в сути задачи. Начинаются бесконечные исследования пустых мест. И ведь самое ужасное, что современное научное сообщество поощряет такой подход. И если в математике или теоретической физике оно хоть немного имеет смысл, то в технических науках он порождает всё больше и больше «британских учёных». Индекс Хирша тому свидетель. Ощущение, что это уже какой-то симулякр, где даже Поппер со своим бубном бессилен…
Вот так и идёшь между Сциллой и Харибдой, решая очередную задачу. И повторяться нельзя и закапываться. А что в таких случаях делаете вы?
Пара маленьких дополнений
- Когда-нибудь, я надеюсь, я запилю статью на тему сканеров радужной оболочки и процесса их разработки. Там будет много смешных монструозных картинок.
- Устройства с алгоритмами, которые мы разработали для инвестора, так и не были выпущены на рынок в виду множества причин. А алгоритмы по чб мы поддерживаем в более-менее живом состоянии.
- Разработчики, к которым инвестор пришёл первым, надо сказать, хоть и пытались решить задачу на редкость ломовым путём, но вынесли из работы весьма ценный материал. С тех самых пор в их сканерах стоит белая лампочка, которая заставляет зрачок сжиматься, увеличивая рабочее поле.
